






文章目录
一、VAE
之前讲过VAE:

为什么需要VAE?
原因1
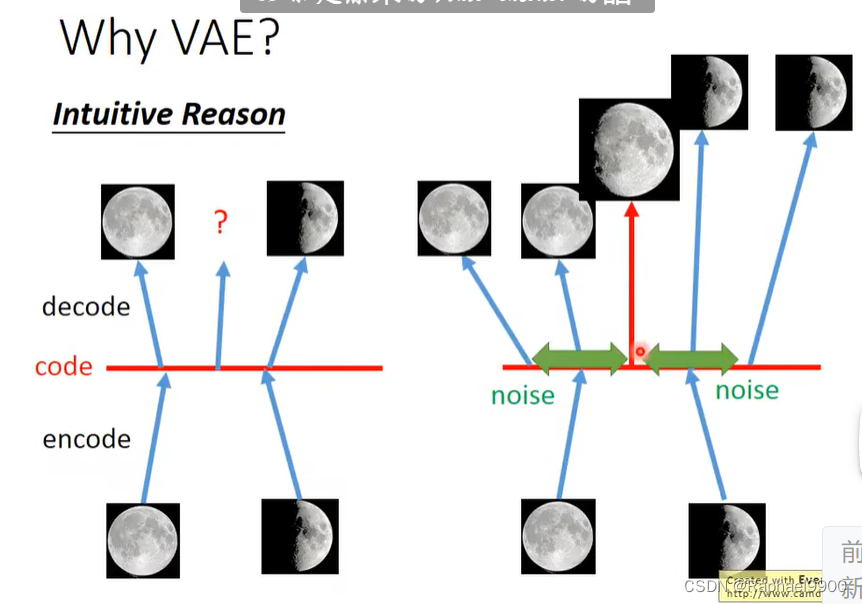
原来的auto-encoder把一张图片经过encode变成一个code,然后code经过decode变回image。VAE会在code上面加上noise,解码之后还是相似的图片。如果是从VAE的code space里面取样得到的图片可能比较好,如果是随便取样code,得到的可能不像一张真实图片。
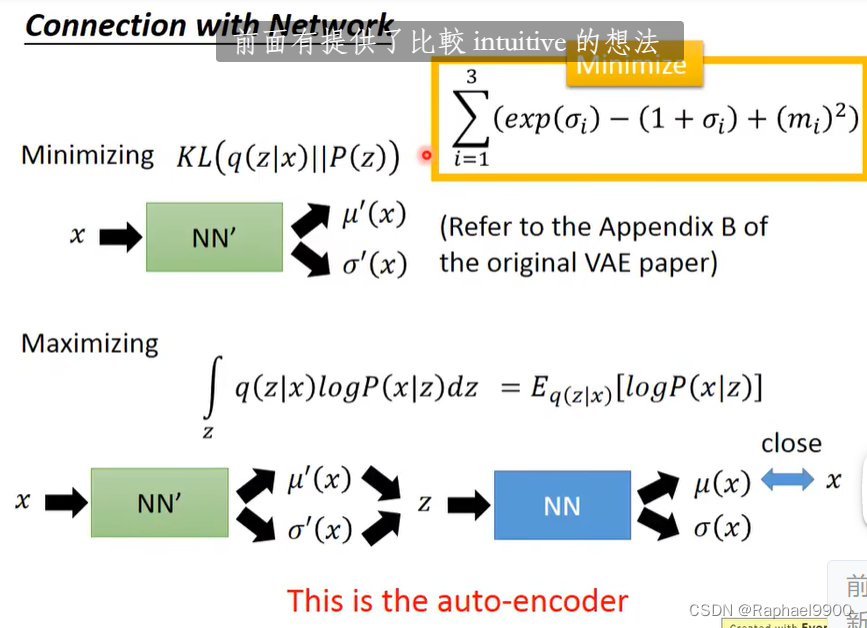
如图是VAE,m是原来原始code,o是用来控制noise的(variance,取exp确保是正的),e是noise(e是从正太分布里面取出来的,它的大小是固定的)。如果用机器学习决定o,那可能是0.所以我们要对他产生的o进行限制。
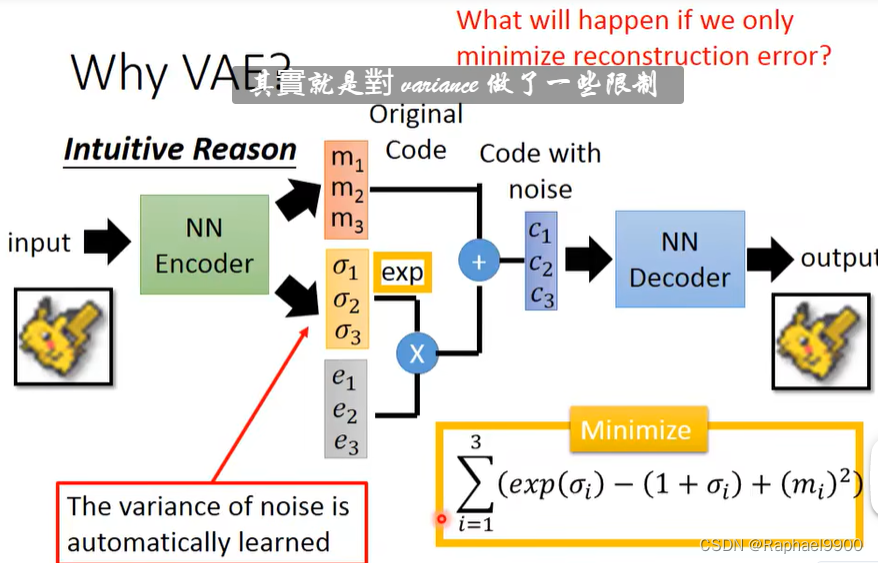
当o=1的时候,loss最低。加上(mi)2项(L2正则化),确保不那么容易overfit。

原因2
对于每个位于高维空间中的点,我们取一个曲线P(x)来表示他们的分布。那么我们怎么估计出一个可能分布呢?
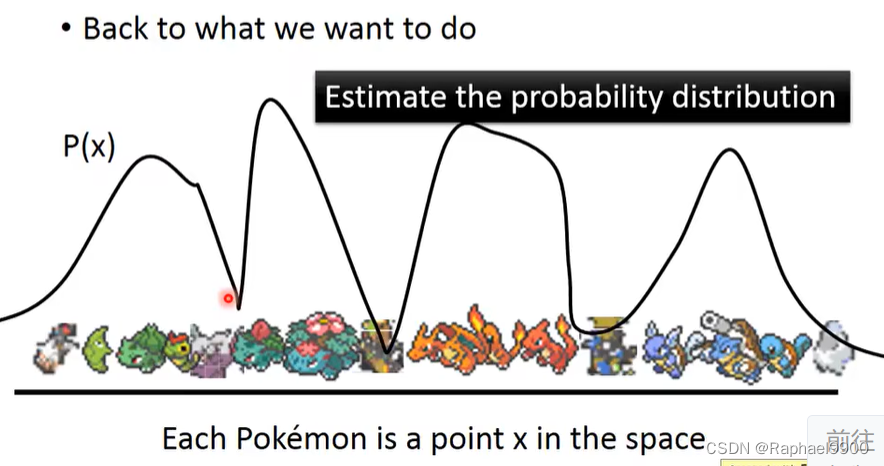
我们可以用gaussian mixture model(高斯混合模型)。下图黑色的是一个复杂的分布,蓝色的分布是高斯分布,黑色的分布是由不同权重的高斯分布叠加起来的。如何取样?假设m是一个整数,代表我们想要决定从哪个高斯分布里取样。P(m)是一个多项式,代表了每个高斯分布的可能性。N是每个高斯分布的weight,有均值和方差。根据m我们选择一个高斯分布,从里面取样得到x,从某个高斯分布里面取样x的概率的P(x|m)。

当我们知道了这些高斯分布的权重之后,我们可以用EM算法很容易得出这个估计分布。之前说:把数据分类,做clustering其实是不够的。更好的是要分布式表示(distributed representation)。就是说每个x并不是属于某个聚类,而是有一个向量来描述不同的面向的属性(attribute)。VAE其实就是高斯混合模型的分布式表示版本。

z是一个正态分布的向量,每一个维度都表示z的特性。取出的z可以决定高斯分布的均值和方差。怎么得到高斯分布呢?假设这个高斯分布的均值和方差都来自一个方程,把z带进去得到方程和均值。z每个点都对应到一个高斯分布。这种对应关系是由上面的函数决定的,方程可以是NN。z也可以不是高斯分布,可以是很多种。虽然z是正态分布,但是P(x)可以很复杂。

我们知道了z之后,就能决定x是从什么样的高斯分布里面取样出来的。我们怎么从z知道均值和方差呢?它的标准就是要达到Maximizing Likelihood,一组x,取P(x)的值取log求和得到L。就假设我们的方程是NN,那我们要调整NN的参数(每个神经元的权重和偏差)去让这个L的可能性最大化。我们有另外一个分布q(z|x),输入x之后能决定高斯。可以看出来上面的nn就是VAE的decoder,下面的nn就是encoder。

经过公式推导:因为KL散度是大于等于0的,得到最后的式子是一个下届Lb。

从Lb可以看出来,我们已知P(z)的分布,需要找的项是P(x|z)和q(z|x),让logP(x)可能性最大化。 当我们提高上界的时候,可能会减少可能性。当我们调整q(z|x)的时候,Lb可能会上升,logP(x)可能性不变。q(z|x)最终将是p(z|x)的近似值,KL散度接近0。

我们可以找到p(x|z)和q(z|x)让Lb越大越好,那也就是说log p(x)越大。
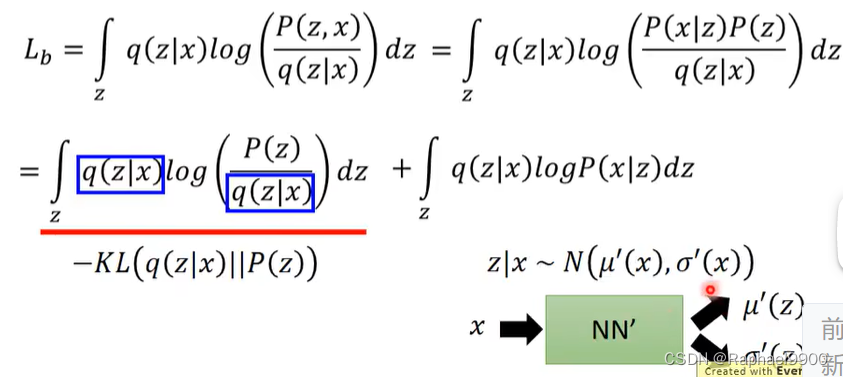 我们希望kl(q(z|X)||p(z))最小化。,也就是q(z|X)跟正态分布越接近越好。 接下来最大化右边那一项,我们就可以最大化Lb。这一项经过推导之后类似于auto- encoder: 输入x到NN’里面生成两个向量,分别是均值和方差,我们从里面取样作为z。然后z放入另一个NN里面,得到均值和方差,我们希望得到的这个输出越接近x越好。 我们一般不看方差,而是看均值,也就是μ(x), 我们希望均值越接近x越好。因为这个是高斯分布,而高斯分布在均值的地方概率是最高的。所以如果我们要均值越接近x越好,那我们右边这一项的值就是最大的。这两项合起来就是VAE。
我们希望kl(q(z|X)||p(z))最小化。,也就是q(z|X)跟正态分布越接近越好。 接下来最大化右边那一项,我们就可以最大化Lb。这一项经过推导之后类似于auto- encoder: 输入x到NN’里面生成两个向量,分别是均值和方差,我们从里面取样作为z。然后z放入另一个NN里面,得到均值和方差,我们希望得到的这个输出越接近x越好。 我们一般不看方差,而是看均值,也就是μ(x), 我们希望均值越接近x越好。因为这个是高斯分布,而高斯分布在均值的地方概率是最高的。所以如果我们要均值越接近x越好,那我们右边这一项的值就是最大的。这两项合起来就是VAE。
conditional VAE
假如我们让VAE产生手写的数字, 给VAE一个手写的数字,VAE提取特性,我们在放进encode的时候,给他输入特性也告诉它那是什么数字,我们就可以生成一排跟他很像的数字。


VAE的问题
VAE生成的是跟输入很像的输出,它从来没有想过要生成一个以假乱真的输出。所以说VAE产生出来的图片往往都是数据库里面的图片的
线性组合而已。他没有尝试过产生新的图片,而是做的模仿。

所以它没有很聪明。更好的generative network就是GAN,他能产生图片。
二、flow-based
flow-based是另一个generative model,这是第四种generative model。

generative models的生成顺序是什么样的呢? Component by component模型生成的时候是一个一个生成的在语音识别里面,一秒钟会有成千上万个输入。如果一秒一秒生成那也需要很长的时间。这个就是component by component模型生成的问题。
VAE的优化对象是一个下界,并不是去最大化可能性。我们并不知道这个下界跟我们真正想要最大化的可能性的之间差距有多大,这是VAE的问题。而flow based model是直接最优化probability。而今天人们用的最多的是GAN,GAN能产生质量很高的输出。flow based生成的结果并不能打败GAN,GAN还是最强的。但是GAN还是很难训练的,因为他在训练的时候的discriminator和generator的目标是不一样的,很容易训坏。flow based会有别的问题。

一个generator G是一个网络,这个网络定义 了一个概率分布PG。我们通常假设他是一个很简单的分布,比如正态分布,z是从里面取样出来的。我们每次取样出一个z,我们就把这个丢到G里面,这个generator产生一个对应的x,虽然z是从一个简单的分布里面提取出来的,但是通过G以后可能会形成一个非常复杂的分布PG(x)。我们希望这个复杂的分布与真实数据Pdata(x)越接近越好。怎么让他们接近越好呢?常见的做法是,从Pdata里面取样m笔资料,我们希望这m笔数据产生出来的可能性越大越好,要找到一个G让这个目标方程(logPG(xi))越大越好。这个就是maximum likelihood。
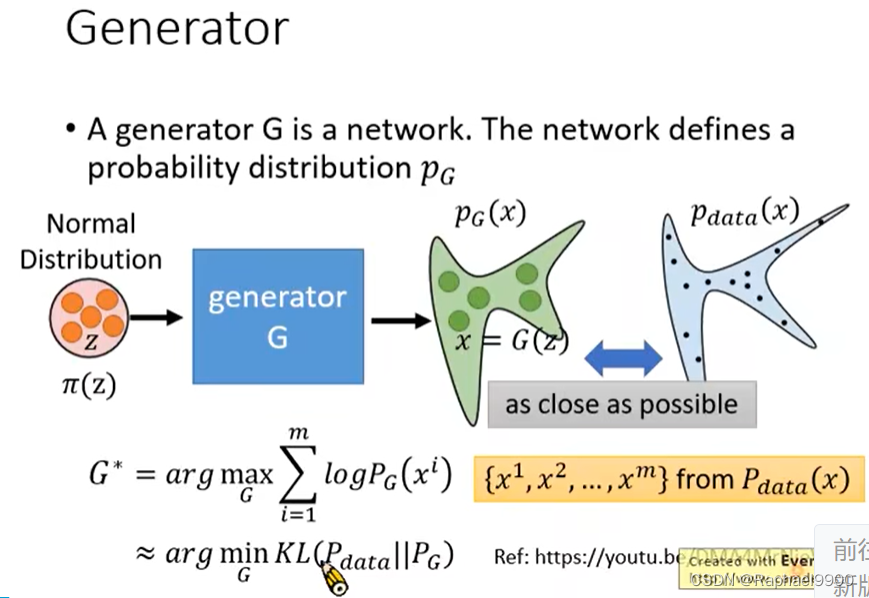
因为G是复杂的NN网络,所以我们不知道G是什么。但是flow based 模型有自己的方法直接得出G!
数学背景
jacobian matrix

determinant
方阵的行列式是提供矩阵信息的标量。


变量变化定理
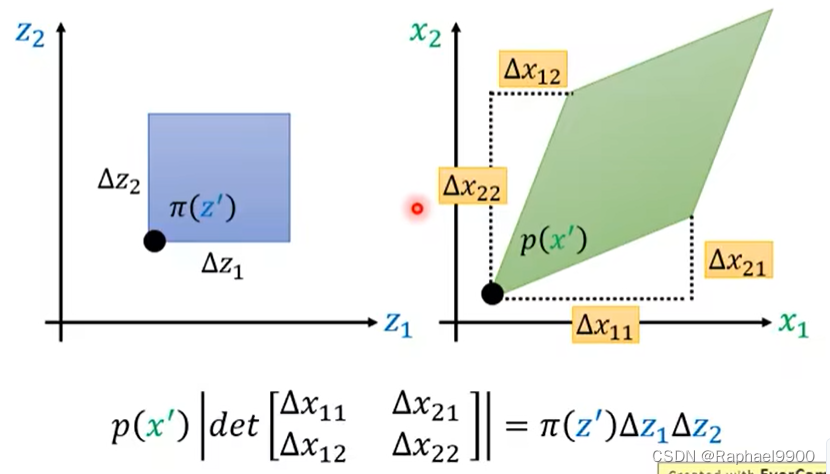
设我们π(z)是正态分布,我们把z放入一个方程f里面得到x。我们现在想知道p(x)与π(z)中间有什么样的关系。


未知:p(x)与π(z)
如果我们知道中间的方程是什么,就能写出p(x)与π(z)的关系。


flow-based model
前提:可以计算det(JG)、知道G-1。
一般z和x的维度是一样的,那么G才是可逆的。但是我们在做GAN或者VAE的时候,输入一个低维向量,输出一个高维向量。但是flow-based模型的输入和输出是同维度的。

因为这些限制,flow-based模型的能力是有限的。那可以有多个G吗?

在第一项里,我们希望输出最大的值,那么就是让zi变成0向量,但是这样会有问题。如果zi是0,那么JG-1会变成0矩阵,那么第二项就会变成负无穷大!我们必须同时考虑两项,让第一项接近0,第二项限制
它不要把所有的z都变成0向量。

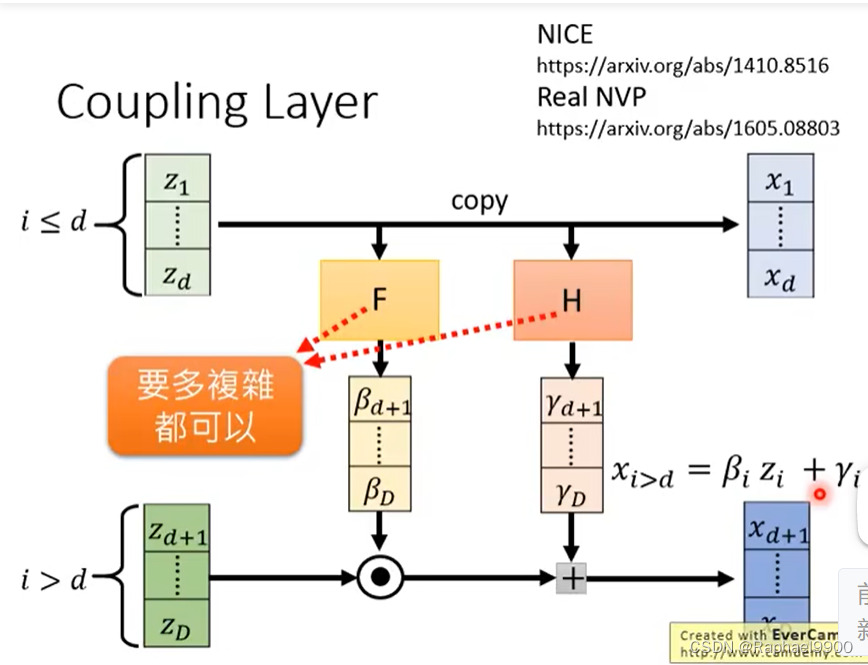
coupling layer
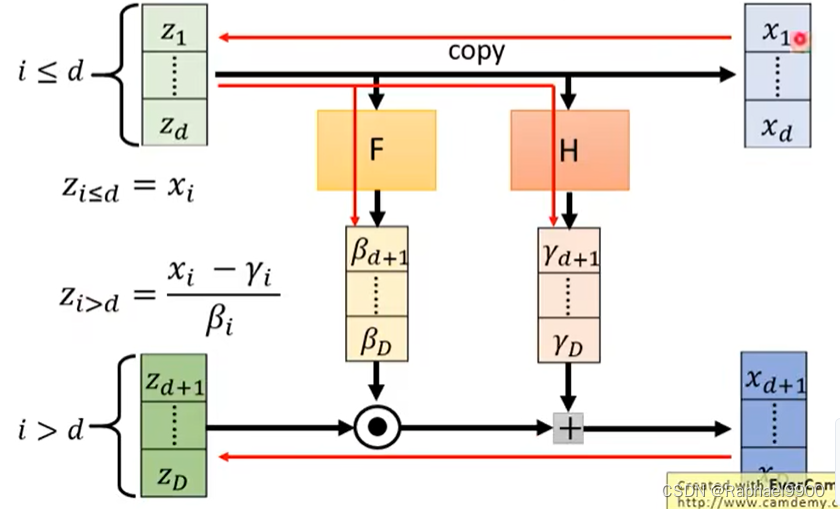
加入我们有输入z和输出x,把输入的前d维z直接复制到x的前d维x,同时输入的前d维也通过一个函数F得到β,通过另外一个函数H得到γ。F和H可以是任何方程,也可以很复杂。然后把剩下的z与β点积得到一个向量,这个向量加上γ向量得到xd+1~xD。
inverse
求反方向的:①从x1-xd算出z1-zd,②从z1-zd经过F和H得到γ和β,③xd+1-xD分别减去γ再除以β就得到zd+1-zD。
jacobian determinant行列式
因为z1-zd和x1-xd是复制的,他们是一模一样的,所以不同维度之间是没有关系的,所以它的JG是一个单位矩阵,只有对角线是1,其他是0.而改变zd+1-zD的值不会影响x1-xd,所以是0矩阵。从运算上看,右下角的一块是diagonal的,他们同一纬度之间才有关系,所以整个矩阵的JG 行列式就是右下角的矩阵的行列式(因为左上角是单位矩阵,乘起来都是1,那就由右下角的决定了).

coupling layer -stacking
对于前d个输入来说,如果一直复制到最后一层,那会把高斯噪声也复制过去,那就没有什么意义了。所以我们在做的时候需要做一些变动
(间隔复制上下):
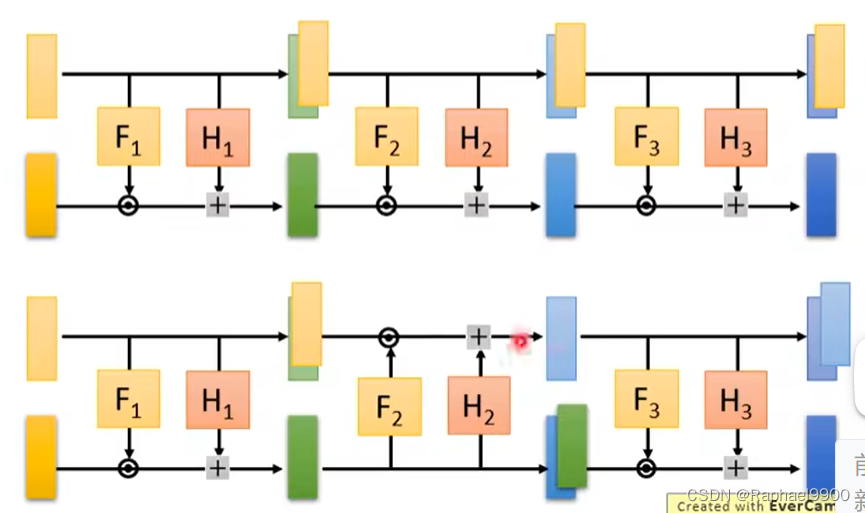
在图像识别上面,我们怎么分为两个呢?偶数复制(像素或者是索引),技术transform。

三、GLOW
flow很早就被提出来了,但是最近因为glow而重新提及。
glow不用GAN生成的图片也很清晰。
它里面加入了11 convolution,它把每个像素里面的三个值乘上一个33的矩阵,得到对应输出的像素的三个值。这个矩阵W是学习出来的,它可以打乱channel,把不同的通道之间的关系对调。W也必须是可逆的。

虽然W是学习出来的可逆矩阵,但是它生成的一定是可逆的吗。随机生成一个矩阵有很大可能是不可逆的。原文没有解释。


可以看到JG就是橙色框里面的式子,他是很容易算的。

glow目前主要用于语音合成。
















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









