






A题
1、对某列的数进行整体运算
df["返工案卷占比(%)"] = df["返工案卷占比(%)"] * 100
df["返工案卷占比(%)"] = df["返工案卷占比(%)"].round(3)2、对某列中的所有值进行排序
df = df.sort_values(by="返工案卷占比(%)", ascending=False)B题
1、两个dataframe通过特定的值进行结合与匹配
a=a.merge(b,on="Stkcd")
#将a,b中的Stkcd一列的值作为匹配条件进行一一对应,其他列中,若有重复的列,只保留一个,若b中有新的列,则添加在a的右侧
(结合excel的VLOOKUP函数理解)
注意:并不是简单拼接,而是一一对应补充:一一对应的merge函数
1)pd.merge
df = pd.merge(a,b,left_on=["列名称1"],right_on=["列名称2"])
df为a与b进行匹配后得到的新的dataframe,顺序按照列名称1在左,列名称2在右排列2).merge
df = df.merge(a,on=["列名称"])
此时,直接在df中进行匹配2、统计每一列中缺失值的个数
null_sum = a.isnull().sum() # 统计每列缺失值的个数若想依次统计所有列:
for i in a.columns: #先遍历所有列名
x=a[i].isnull().sum() #按照列名依次求值3、使列表中的元素不重复,唯一
e=list(set(e))
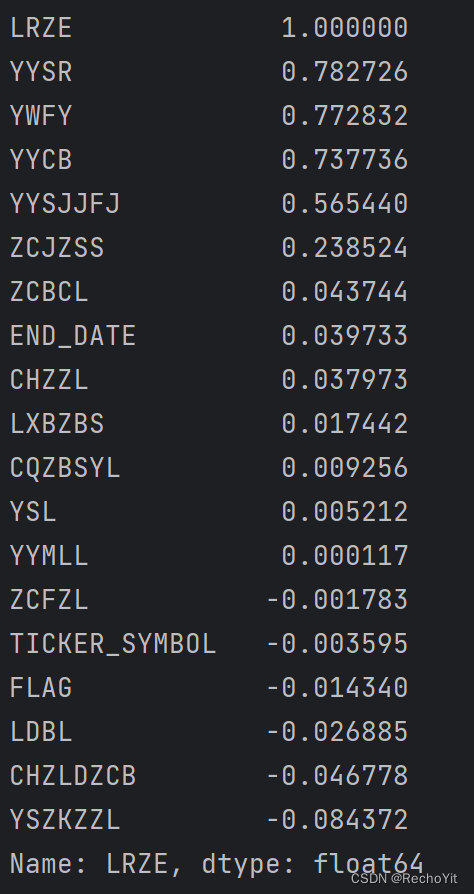
利用集合的特性:唯一性,先将其转化为集合再换回列表即可完成去重4、计算相关性并降序输出
column_name = 'LRZE' #提取该列
correlation = a.corr()[column_name] #计算其他列与该列的相关性
correlation_2 = correlation.sort_values(ascending=False) #将每列与目标列相关性按照降序输出
输出结果如下:
5、线性回归模型的建立
为了更直观的得到所有列中数据之间的关系,可以通过选定一个目标变量,多个特征(都是对应的列),创建线性回归模型,得到之间的关系,并可以通过该模型对目标值进行预测(前提是应传入其他所有特征参数)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 选择特征和目标变量
features = ['YYSR', 'YWFY', 'YYCB', 'YYSJJFJ', 'ZCJZSS'] #传入对应的列
target = 'LRZE'
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(a[features], a[target], test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# print("均方误差 (MSE):", mse)
# print("决定系数 (R^2):", r2)进行预测:
prediction = model.predict(df) #df只包含特征列若想用dataframe输出,可以将预测值放入列表中,用字典先建立,再用pd.Dataframe()转化为dataframe形式
通性问题
@@读入与导出
a1=pd.read_excel(r"D:\python\泰迪杯\2023 泰迪杯数据分析\A题-档案数字化加工流程数据分析\data2.xlsx")
a1=pd.read_csv(r"D:\python\泰迪杯\2023 泰迪杯数据分析\A题-档案数字化加工流程数据分析\data2.csv")out_path = "D:\python\.idea\python study\泰迪杯\LR_new.csv"
a.to_csv(out_path, encoding='utf-8', index=False)
out_path = "D:\python\.idea\python study\泰迪杯\LR_new.excel"
a.to_excel(out_path, index=False)
a.to_excel("LR_new.excel",index=False) #默认保存在当前文件夹下
#index=False表示导出文件中不显示索引列1、想要提取出某一列中包含某个字符或者某个数字的一整行
a1 = a[a["列名称"].str.contains("某个字符")] #提取一列中包含某字符的一整行
a2 = a[a["列名称"].eq(某个数字)] #提取一列中包含某数字的一整行2、想要提取出几个特定的列
a1 = a[["列名称1","列名称2","列名称3","列名称4"]]3、对某一列中的数据去重
a2=a1.drop_duplicates("列名称")4、使时间能够正常显示并运算
from datetime import datetime
a1["dUPDATE_TIME"] = pd.to_datetime(a1["有时间一列的列名称"])5、选择满足某个条件的行
a1 = a[a["列名称"]=="筛选条件"]6、选择满足某个条件的行,但只需该行的几列数据
a = a1[a1['筛选条件所在列名称'] == 5][['显示列1', '显示列2', '显示列3']]7、将某列数据全部放入一个列表
ls_1=list(a4["iUSER_ID"])8、定位到dataframe中的某个(些)值
m = a2.loc[a2["sARCH_ID"] == 5, "dNODE_TIME"].values
#m为a2中sARCH_ID一列中为5的所有行中dNODE_TIME列的值9、想要删除某一列中含有空值的一整行(dropna)
b=a['dNODE_TIME'].dropna()
#删除dNODE_TIME列中含有空值的行10、转换
pd中所有and变为&,or变为|,翻转中若是对值(values)进行改变顺序,用ascending,若是列表排序仍是reverse
思路问题
1、可视化数据的传入
问题:
在进行可视化的过程中,需要传入不同的量(自变量,因变量),一般传入的方式为列表。但处理的数据中我们想要放入列表中作为变量的值通常会重复出现,并且难以将其与后续运算结果,即因变量,在两个列表中的索引值进行一一对应
解决方法:
1、先用drop_duplicates进行去重,将去重的值放入一个列表ls1中,作为自变量
2、用for循环遍历ls1列表,在for循环下进行运算,并将其放入新列表ls2中,则每次运算的结果可以与自变量列表ls1的值在索引上一一对应,ls2作为因变量传入
*3、若遇到需要将因变量ls2列表进行排序,又不想使ls1与ls2对应改变,可以用zip将两个列表捆绑起来
2、判断某个dataframe中哪个值出现错误
问题:
譬如b题中让我们判断哪个公司财务报表造假,也就是判断哪一行中某个值与其他列的关系与其他行不一样,需要筛选出不一样的。
解决方法:
1、先通过绝对准确的数据建立一个线性回归模型(具体步骤见b题第5项)
2、(1)通过建立的模型计算出一个新的值,作为预测值,该预测值应该与准确的实际值相近。若出现实际值与预测值相差过大的,该行数据有误
3、(2)通过先前建立的回归模型,对数据进行拟合度评分,评分最低的则是有误的数据















 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









