







我们知道RAG很重要的一个环节就是解析PDF。
那么传统的PDF解析工具能否适应大模型时代的需求呢?
传统的PDF解析库相当地多,我们就不一一罗列和分析了。这里我们仅以目前最流行的大模型框架LangChain所支持的其中一个解析库PyPDF为例。
我们使用LangChain并选择PyPDFLoader来读取PDF文件“恒生电子:恒生电子股份有限公司2022年年度报告(修订版).PDF”(可以在巨潮资讯搜索下载这份PDF文件)
存在的问题
我们发现通过PyPDFLoader读取的结果存在很多问题,这里仅以PDF第6页和第7页的“七、近三年主要会计数据和财务指标”为例: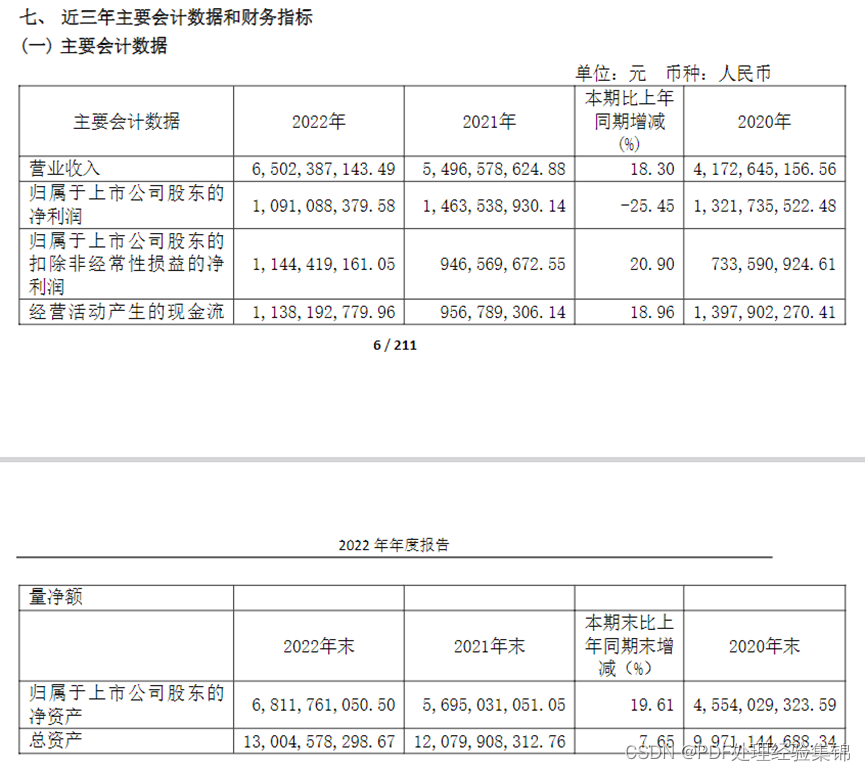
通过PyPDFLoader读取的结果如下(为节省篇幅,这里去除了所有空白换行符):
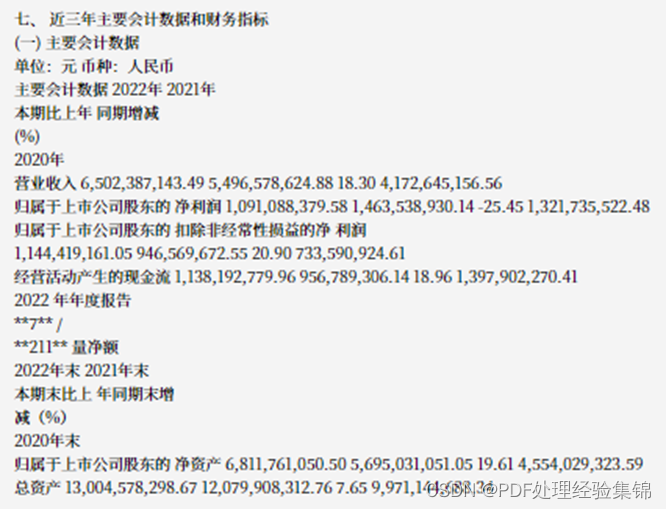
我们可以发现以下问题:
- PDF换页导致表格行头被断开:第四行的行头“经营活动产生的现金流量净额”生生被“1,138,192,779.96 956,789,306.14 18.96 1,397,902,270.41 2022 年年度报告 **7** /**211** ”一长串内容断成了两截。我们可以看到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2714
2714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









