







LFFD: A Light and Fast Face Detector for Edge Devices论文地址
总体思路
LFFD是由中科院提出的新型单目标检测模型,适用于人脸、行人、车辆等单目标检测,速度快模型小效果好,可以在RTX2070下使用TensorRT跑2k图片90fps。
论文研究了感受野(RF)与有效感受野(ERF)的关联与重要性,使用感受野替代Anchors,即Anchor-free的方法。在一个基础模型结构上分别抽取8路特征图对从小到大的人脸进行检测,检测模块分为类别二分类与边界回归。
主要优势:
-
通过添加更多CNN层,可以覆盖更大尺度的目标(比如典型的自拍场景人脸),而增加的延迟有限;
-
检测小目标能力突出,在极高分辨率(比如8K或更大)画面,可以检测其间10个像素大小的目标;
-
使用的网络结构是常见的,可以部署到主流端侧设备。
基于Anchors的方法存在的问题
- anchor box不能完全覆盖所有尺寸的人脸。
- anchor box匹配使用IOU进行评价,其阈值的设定靠经验,很难进行研究。
- 设定anchor box的数量和尺寸全靠经验,会导致样本不平衡和冗余计算。
感受野与有效感受野
- 感受野(RF):是输入图像上的一块区域,目标如果在感受野内更容易被检测。
- 有效感受野(ERF):以感受野中心位置呈高斯分布的区域的像素对结构影响较大,越远越小。

很小的人脸往往难以确认检测,需要更多的上下文信息例如脖子和肩膀等来辅助检测。如下图所示:

感受野策略
- 人脸小目标需要充足的上下文信息。(ERF最好能尽可能覆盖context information)
- 中等大小的人脸需要少量的上下文信息。(ERF只需要覆盖一部分context information)
- 人脸大目标直接使用感受野。(ERF甚至不需要覆盖其他额外的context information)
模型结构

模型主要由四部分组成:tiny part、small part、medium part、large part。
模型中并没有采用BN层,因为BN层会减慢17%的推理速度。
尽可能快的进行下采样而保持100%的人脸覆盖。
感受野=天然的Anchors
- 可以在一定感受野下预测不同尺寸的人脸。
- 只有当人脸的真实中心位置在感受野内才进行匹配。
- 模型定义后,所有感受野就是均匀的固定的分布再输入图像上,无需再手动设计。
- 理论上感受野能覆盖所有尺寸的人脸。
作者认为RF就是天然的anchor,由于人脸目标一般是方的,所以不需要考虑各种比例的box。在box匹配的时候,作者认为rf中心落在ground truth内的box为正样本,同时落在多个ground truth中的box忽略掉、其他没有落在任何ground truth中的box为负样本。
100 pixels的RF的有效感受野为20-40pixels,所以作者就分了四个part,tiny part的c8 RF SIZE为55,去检测10-15pixels的人脸,c10检测15-20,以此类推。

损失函数
论文中Loss是由regression loss和classification loss的加权和。
分类损失:
交叉熵损失。
回归损失:
L2损失函数。

gray scale:
box匹配的时候定义了gray scale,认为处于gray scale的box所在的branch是不反传这些对应的loss的。
对c13出的box而言,其检测的人脸像素为20-40pixels,认为[18,20]以及[40,44]像素的人脸不被c13预测,这是因为这些人脸属于hard目标,网络往往只能看到局部特征,很难判别,所以c13这个brach不预测他,让别的branch预测,对训练有好处。
训练细节
- 数据增强:颜色抖动(color distort)、随机水平翻转(Randomly horizontal flip)、对各尺寸人脸随机采样(Random sampling for each scale)。
- 对于一个感受野多于两个人脸的区域被舍弃。
- 损失函数。
- 难分负样本挖掘:对负样本损失值排序后选择最高的几个,保证正负样本比例为1: 10。
- 训练参数:Xavier初始化;输入图片标准化= (img-127.5)/127.5;weight decay为0(参数少);初始学习率0.1,之后以0.1倍数减小;1080ti训练了5天。
LFFD实验结果
在WIDER FACE 验证集上的精度比较:
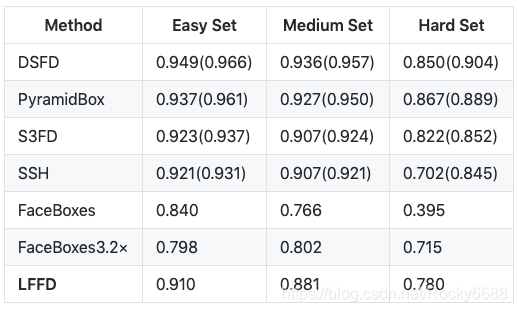
在WIDER FACE 测试集上的精度比较:
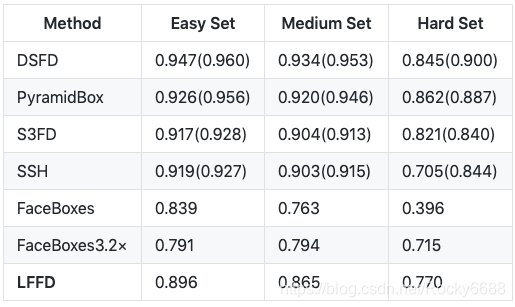
在FDDB 数据集上的精度比较:
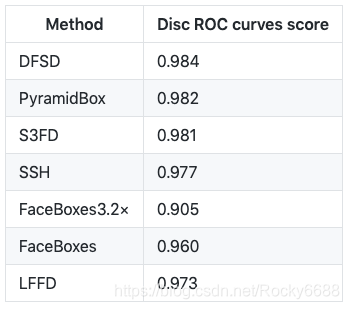
在NVIDIA GTX TITAN Xp (MXNet+CUDA 9.0+CUDNN7.1)配置下的推断速度:
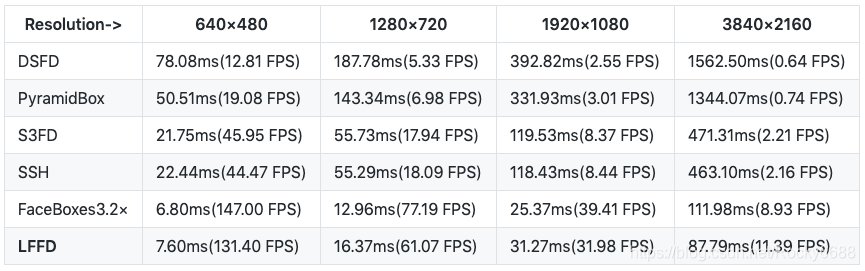
在NVIDIA TX2 (MXNet+CUDA 9.0+CUDNN7.1)配置下的推断速度:

在树莓派 3 Model B+ (ncnn) 配置下的推断速度:

虽然精度并不是最高水平的,但其模型大小仅9M,推断速度更是其亮点。
值得一提的是,上述评测是在Python下做的,转成C++代码应该能获得更高的速度。
作者指出,LFFD不仅仅适用于人脸检测,实则是通用的一类目标检测器,也同样可扩展到行人检测、人头检测、车辆检测等。


















 4722
4722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











