







Efficientnet是通过使用深度(depth)、宽度(width)、输入图片分辨率(resolution)共同调节技术搜索得来的模型。
EfficientNet结构
模型构建方法:
- 使用强化学习算法实现的MnasNet模型生成基线模型EfficientNet-B0。(MnasNet模型是Google 团队提出的一种资源约束的终端 CNN 模型的自动神经结构搜索方法。该方法使用强化学习的思路进行实现。)
- 采用复合缩放的方法,在预先设定的内存和计算量大小的限制下,对EfficientNet-B0模型的深度、宽度(特征图的通道数)、图像大小这三个维度同时进行缩放,这三个维度的缩放比例由网络搜索得到。最终输出了EfficientNet模型。
下图是一些参数调节示意图:

MBConv卷积块
EfficientNet模型的内部是通过多个MBConv卷积块实现的,每个MBConv卷积块的具体结构如下:
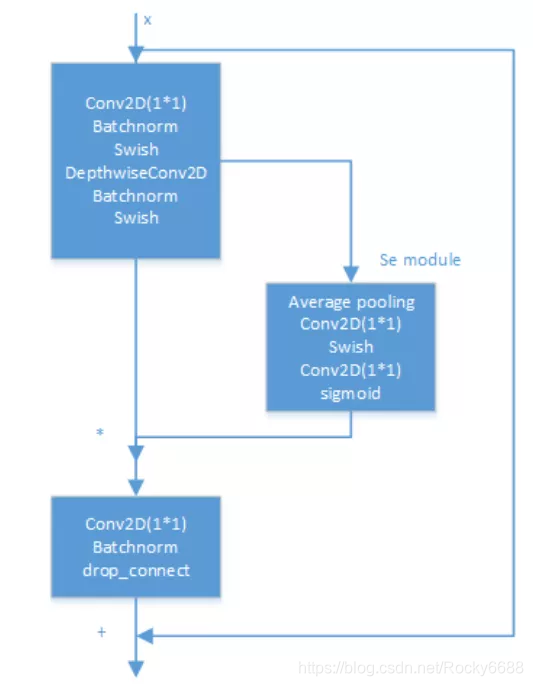
MBConv卷积块也使用了类似残差结构的结构,不同的是在短连接部分使用了SE层。另外使用了drop_connect方法来代替传统的drop方法。
DropConnect与Dropout不同的地方是在训练神经网络过程中,它不是对隐层节点的输出进行随机的丢弃,而是对隐层节点的输入进行随机的丢弃:
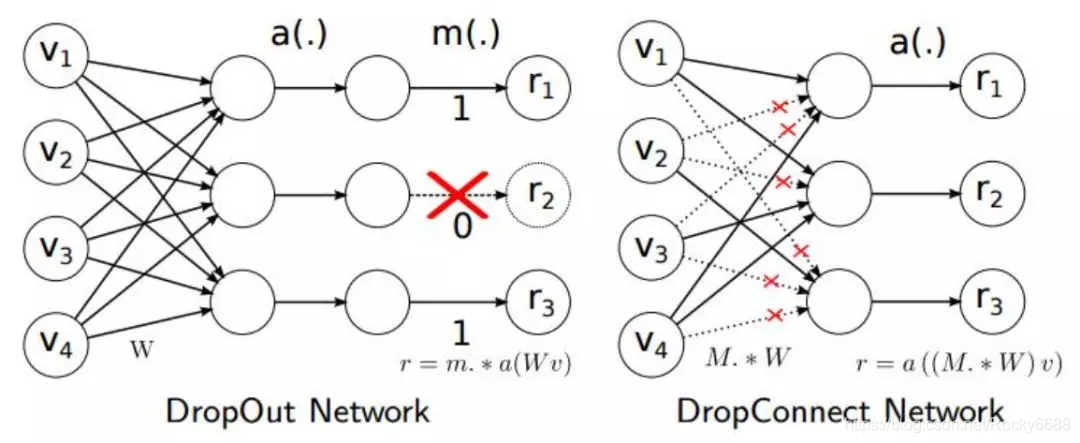
在深度神经网络中DropConnect与Dropout的作用都是防止模型产生过拟合的情况。相比之下DropConnect的效果会更好一些。
不同版本之间的区别
EfficientNet系列模型中从EfficientNet-B0到EfficientNet-L2版本,模型的精度越来越高,规模越来越大,同样,对内存的需求也会随之变大。
模型的规模主要是由宽度、深度、分辨率这三个维度的缩放参数决定的。这三个维度并不是相互独立的,对于输入的图片分辨率更高的情况,需要有更深的网络来获得更大的感受视野。同样的,对于更高分辨率的图片,需要有更多的通道来获取更精确的特征。在EfficientNet的论文中,也用公式介绍了三者之间的计算原则。
下面的表格展示了每个版本的缩放参数:
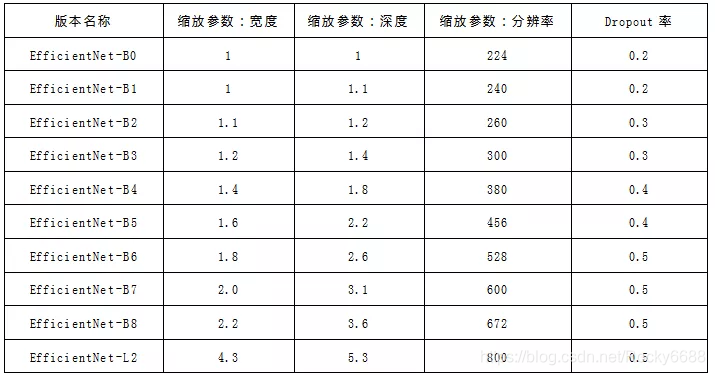
从上表中可以看到,随着模型缩放参数的逐渐变大,其dropout的丢弃率参数也在增大。这是因为模型中的参数越多,模型的拟合效果越强,也越容易产生过拟合。
模型性能
作者将EfficientNet系列网络与ImageNet 上其他现有的模型进行了比较。 一般来说,EfficientNet模型比现有的其他模型具有更高的精度和更高的效率,减少了参数大小和 FLOPS 数量级。 在高精度体系中, EfficientNet-B7在 imagenet 上的精度达到了最高水平的84.4% ,而在 CPU 使用方面比以前的 Gpipe 小8.4倍,快6.1倍。 与广泛使用的 ResNet-50相比,作者提出的 net-b4使用了类似的 FLOPS,同时将准确率从 ResNet-50的76.3% 提高到82.6% (+ 6.3%)。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











