










概叙
科普文:Java基础之算法系列【文本相似度判定算法梳理】-CSDN博客
科普文:Java基础之算法系列【文本相似度判定算法:手搓Simhash局部敏感哈希算法】-CSDN博客
前面我们梳理了文本相似度判断算法、以及simhash局部敏感哈希。今天我们再看看 余弦相似度和TF-IDF词频逆文频率来判断文本相似。
-
TF-IDF(词频-逆文档频率):TF-IDF是一种常用的文本表示方法,用于衡量一个词在文档中的重要程度。结合向量空间模型,可以将文本表示为TF-IDF向量的集合,并通过计算向量之间的相似度来评估文本的相似程度。
-
余弦相似度(Cosine Similarity):余弦相似度是通过计算两个向量的夹角余弦值来评估它们的相似度。在文本相似度计算中,首先将文本转换为向量表示(如TF-IDF向量),然后计算这些向量之间的余弦值。余弦值越接近1,表示文本越相似。与余弦相似度相对应,通过计算两个向量之间的夹角余弦值的补值来表示距离。余弦距离越大,表示两个向量越不相似。
余弦相似度(Cosine Similarity)
余弦相似度是一种用于衡量两个向量在方向上的相似程度的指标。
余弦相似度是一种衡量两个向量之间夹角余弦值的相似度度量方法,广泛应用于文本挖掘、推荐系统等领域。
余弦相似度通过计算两个向量的夹角余弦值来评估它们的相似度。它的取值范围在-1到1之间,值越接近1表示两个向量越相似,越接近-1表示越不相似,0表示两个向量之间没有任何相似度。
余弦相似度原理
余弦相似度通过计算两个向量之间的夹角的余弦值,来表示它们在向量空间中的相似性。

余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。
从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。
两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。
这结果是与向量的长度无关的,仅仅与向量的指向方向相关。
余弦相似度通常用于正空间,因此给出的值为-1到1之间。
注意这上下界对任何维度的向量空间中都适用,而且余弦相似性最常用于高维正空间。例如在信息检索中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
余弦相似度的计算
对于两个向量A和B,余弦相似度定义为:
sim(A, B) = cos(θ) = (A · B) / (|A| * |B|)
其中,θ为向量A和B之间的夹角,(A · B)为两个向量的点积,|A|和|B|分别为向量A和B的模长。
数学上,两个向量的余弦相似度可以表示为:

对于二维空间中的向量A(x1, y1)和B(x2, y2),余弦相似度可以简化为:(x1x2 + y1y2) / (sqrt(x1^2 + y1^2) sqrt(x2^2 + y2^2))。
或者简化余弦相似度的计算公式为:cos(A, B) = (a1b1 + a2b2 + ... + anbn) / (sqrt(a1^2 + a2^2 + ... + an^2) sqrt(b1^2 + b2^2 + ... + bn^2)),其中a1, a2, ..., an和b1, b2, ..., bn分别是向量A和B的分量。
推广到多维空间,设A(x1, y1, z1, …)和B(x2, y2, z2, …),则余弦相似度为:(Σ(AiBi)) / (||A|| ||B||),其中Σ表示对所有分量的求和。

工作原理
给定两个向量 A 和 B,它们之间的余弦相似度 cos(θ) 可以通过下面的公式计算得出:
cos(θ) = (A · B) / (||A|| * ||B||)其中,(A · B) 表示 A 和 B 的点积,而 ||A|| 和 ||B|| 分别表示 A 和 B 的欧式范数(即向量的长度)。
点积 (A · B) 计算公式为:
A · B = Σ(ai * bi)向量的欧氏范数 ||A|| 计算公式为:
||A|| = sqrt(Σ(ai^2))其中,ai 和 bi 分别是向量 A 和 B 中的元素。
角相似性

举例说明
示例一:假设有两个用户对三部电影的评分向量,用户 X 的评分向量为 [4, 0, 5],代表用户 X 对第一部电影的评分为 4 分,对第二部电影未进行评分,对第三部电影的评分为 5 分。用户 Y 的评分向量为 [5, 1, 4],代表用户 Y 对第一部电影的评分为 5 分,对第二部电影的评分为 1 分,对第三部电影的评分为 4 分。
根据余弦相似度的公式,我们首先计算两个用户评分向量的点积:
A · B = (4 * 5) + (0 * 1) + (5 * 4) = 20 + 0 + 20 = 40接下来,计算两个向量的欧氏范数:
||A|| = sqrt((4^2) + (0^2) + (5^2)) = sqrt(16 + 0 + 25) = sqrt(41)
||B|| = sqrt((5^2) + (1^2) + (4^2)) = sqrt(25 + 1 + 16) = sqrt(42)然后,将点积的结果除以两个向量欧氏范数的乘积,得到余弦相似度:
cos(θ) = 40 / (sqrt(41) * sqrt(42)) ≈ 0.989这个结果表明,用户 X 和用户 Y 对电影的评分趋势非常相似,他们的兴趣和偏好可能相近。
示例二:

余弦相似度优缺点
优点:对向量的长度不敏感,只关注向量的方向,适用于高维稀疏数据;计算简单,适合大规模数据处理;结果直观,范围在-1到1之间,方便解释。
- 归一化度量:余弦相似度考虑的是向量间的夹角,而不是向量的大小,这意味着即使两个向量在长度上不同,它们的方向相似度依然可以被有效度量。
- 计算简便:相对于其他相似度度量方法,余弦相似度的计算相对简单,适合大规模数据处理。
- 对文本长度不敏感,即不受向量长度的影响,只关注向量的方向。
- 适用于高维数据和稀疏向量,在高维空间中表现良好。
缺点:忽略向量的长度信息,可能不合理;无法捕捉到语义上的细微差别;对噪声和异常值敏感;在处理非二进制数据时有效性和解释性下降。
- 不考虑向量中各元素的重要性,即所有元素在相似度计算中的权重相同。
- 对重复出现的单词敏感,可能导致相似度计算结果偏高。
- 无法捕捉变量之间的非线性关系。
余弦相似度适用场景
余弦相似度广泛应用于文本分析、自然语言处理(NLP)、推荐系统、聚类分析等领域。
具体来说:
- 在文本分析中,可以用于比较文档之间的相似度,从而进行文本分类、聚类等任务。
- 在推荐系统中,可以用于衡量用户之间的相似度或物品之间的相似度,从而进行个性化推荐。
- 在聚类分析中,可以用于评估集群内部的凝聚力,即集群内成员之间的相似程度。
- 信息检索:通过计算查询和文档之间的余弦相似度,找到与查询最相关的文档。
- 推荐系统:计算用户或物品特征向量之间的余弦相似度,实现个性化推荐。
- 文本挖掘:将文档表示为词频向量,计算文档之间的相似度。
- 图像处理:在高维特征向量表示的图像之间比较相似度。
余弦相似度注意事项
- 在使用余弦相似度时,需要确保数据已经被转换为向量形式。对于文本数据,这通常通过词袋模型或TF-IDF(词频-逆文档频率)等表示方法来实现。
- 余弦相似度的计算结果是一个介于-1和1之间的值。当两个向量完全相同时,余弦相似度为1;当两个向量完全相反时,余弦相似度为-1;当两个向量正交(即夹角为90度)时,余弦相似度为0。
- 在实际应用中,需要注意处理数据中的稀疏性和噪声,以避免对相似度计算结果产生负面影响。
TF-IDF(词频-逆文档频率)
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于评估一个词在文档集合中的重要性的统计方法。
TF-IDF(词频-逆文档频率)是一种在信息检索和文本挖掘中广泛使用的统计方法,用于评估一个词对于文档集或语料库中的其中一份文档的重要程度。
它由两部分组成:词频(TF)和逆文档频率(IDF)。
TF-IDF原理
-
词频(TF):衡量某个词在文档中出现的频率。词频越高,说明该词在文档中出现的次数越多,可能是文档的一个重要关键词。表示一个词在文档中出现的频率,计算公式通常为该词出现次数除以文档总词数。
TF的计算公式通常为:TF = 词在文档中出现的次数 / 文档的总词数。
-
逆文档频率(IDF):衡量某个词在整个文档集合中出现的稀有程度。若某个词在大部分文档中均出现,则其IDF值较低,反之则IDF值较高。反映一个词在整个文档集合中的稀有程度,计算公式为语料库的文档总数除以包含该词的文档数,通常取对数log。
IDF的计算公式涉及文档总数和包含该词的文档数量,并通常取对数形式:IDF=log(文档总数 / 包含该词的文档数量)。
-
TF-IDF值:是TF和IDF的乘积,用于评估一个词对某个文档的重要性。TF-IDF值越高,说明该词在文档中既频繁出现又在整个文档集合中相对稀有,因此具有较好的类别区分能力。
TF-IDF优缺点
- 优点:简单快速,能够有效提取文档中的关键词,广泛应用于搜索引擎优化和文本分类。
- 简单易懂:算法原理清晰,容易理解和实现。
- 有效性:在许多情况下,TF-IDF能够提供准确的词语重要性评估,有助于文本分类、信息检索等任务。
- 缺点:无法捕捉语义信息,忽略词序信息,可能受数据集偏斜影响。
- 不考虑语义和上下文:TF-IDF仅基于词频和文档频率进行计算,忽略了词语之间的语义关系和上下文信息。
- 对短文本效果不佳:由于短文本中词频的波动可能较大,TF-IDF在评估短文本时可能不够准确。
- IDF的局限性:IDF可能无法准确反映词条的类别区分能力,特别是在某些特定领域或文档集合中。
TF-IDF适用场景
TF-IDF被广泛应用于搜索引擎、文本分类、推荐系统、信息提取等任务中。
它适用于需要评估词语在文档中的重要性、进行文本特征提取或文本相似度计算的场景。例如,在搜索引擎中,TF-IDF可以帮助确定用户查询与文档之间的相关程度;在文本分类中,它可以作为特征选择的重要依据。
TF-IDF注意事项
- 数据预处理:在使用TF-IDF之前,需要对文本进行预处理,包括去除停用词、标点符号、数字等无关信息,并进行分词处理。
- 归一化处理:为了避免文档长度对词频计算的影响,通常需要对词频进行归一化处理。
- 结合其他方法:由于TF-IDF存在某些局限性,因此在实际应用中可以与其他方法(如语义分析、上下文建模等)相结合,以提高文本处理的准确性和效果。
- 适用场景:信息检索、文本分类、关键词提取、文档相似性计算等。
- 注意事项:处理停用词,考虑词频的归一化,对IDF进行平滑处理以避免分母为零的情况。
通过以上分析,我们可以看到TF-IDF算法在文本处理领域的广泛应用和实际价值。尽管存在一些局限性,但通过适当的调整和优化,可以进一步提高其应用效果。
余弦相似度实现

* 计算两个文本的余弦相似度通常涉及以下步骤: * * 1.文本预处理: * 对于中文文本,使用分词工具(如Jieba、Ansj、HanLP等)将文本分词。 * 对于英文文本,通常可以通过空格进行分词,但也可能需要去除标点符号、转换为小写、去除停用词等额外处理。 * * 2.构建词频向量: * 遍历分词后的文本,统计每个词出现的频率,构建词频向量。 * 可以使用Map<String, Integer>(在Java中)或类似的数据结构来存储词频。 * * 3.计算向量的点积和范数: * 点积(Dot Product):计算两个词频向量对应位置词频的乘积之和。 * 范数(Norm):计算每个词频向量的模长,即向量各分量平方和的平方根。 * * 4.计算余弦相似度: * 使用点积和范数来计算余弦相似度,公式为:cosine_similarity = dot_product / (norm_vector1 * norm_vector2)。
package com.zxx.study.algorithm.hash.hashplus;
import java.util.*;
/**
*
* 计算两个文本的余弦相似度通常涉及以下步骤:
*
* 1.文本预处理:
* 对于中文文本,使用分词工具(如Jieba、Ansj、HanLP等)将文本分词。
* 对于英文文本,通常可以通过空格进行分词,但也可能需要去除标点符号、转换为小写、去除停用词等额外处理。
*
* 2.构建词频向量:
* 遍历分词后的文本,统计每个词出现的频率,构建词频向量。
* 可以使用Map<String, Integer>(在Java中)或类似的数据结构来存储词频。
*
* 3.计算向量的点积和范数:
* 点积(Dot Product):计算两个词频向量对应位置词频的乘积之和。
* 范数(Norm):计算每个词频向量的模长,即向量各分量平方和的平方根。
*
* 4.计算余弦相似度:
* 使用点积和范数来计算余弦相似度,公式为:cosine_similarity = dot_product / (norm_vector1 * norm_vector2)。
*
* @author zhouxx
* @create 2025-01-04 12:25
*/
public class CosineSimilarity4 {
// 分词函数(示例,实际应使用适当的分词工具)
public static List<String> tokenize(String text) {
// 简单的空格分词,适用于英文或已预处理的中文
/**
*请注意,这个示例使用了非常简单的分词方法(仅通过空格分词),并且没有去除停用词或进行其他高级预处理。
* 在实际应用中,你应该使用适当的分词工具,并根据需要去除停用词、进行词干提取或词形还原等处理。
* 此外,对于中文文本,你还需要确保分词工具能够正确处理中文特有的分词问题。
* */
if(ChineseTokenizer.containsChinese(text)){
return ChineseTokenizer.JiebaTokenize(text);
}else {
return EnglishTokenizer.tokenize(text);
//return text.split("\\s+");
}
}
// 构建词频向量
public static Map<String, Double> buildWordFrequency(String text) {
Map<String, Double> wordFreq = new HashMap<>();
for (String word : tokenize(text)) {
wordFreq.put(word, wordFreq.getOrDefault(word, 0.0) + 1.0);
}
return wordFreq;
}
// 构建词频向量
public static Map<String, Double> buildWordFrequencyWithTF_IDF(String text) {
List<String> tokens =tokenize(text);
return calculateTFIDF(calculateTF(tokens),calculateIDF(tokens));
}
// 计算TF
public static Map<String, Integer> calculateTF(List<String> tokens) {
Map<String, Integer> tfMap = new HashMap<>();
for (String token : tokens) {
tfMap.put(token, tfMap.getOrDefault(token, 0) + 1);
}
return tfMap;
}
// 计算IDF
public static Map<String, Double> calculateIDF(List<String> tokens) {
Map<String, Integer> dfMap = new HashMap<>();
int totalDocuments = tokens.size();
Set<String> uniqueTokens = new HashSet<>(tokens);
for (String token : uniqueTokens) {
dfMap.put(token, dfMap.getOrDefault(token, 0) + 1);
}
Map<String, Double> idfMap = new HashMap<>();
for (Map.Entry<String, Integer> entry : dfMap.entrySet()) {
String token = entry.getKey();
int df = entry.getValue();
idfMap.put(token, Math.log(totalDocuments / (1.0 + df)));
}
return idfMap;
}
// 计算TF-IDF
public static Map<String, Double> calculateTFIDF(Map<String, Integer> tfMap, Map<String, Double> idfMap) {
Map<String, Double> tfidfMap = new HashMap<>();
for (Map.Entry<String, Integer> tfEntry : tfMap.entrySet()) {
String token = tfEntry.getKey();
int tf = tfEntry.getValue();
double idf = idfMap.getOrDefault(token, 0.0);
tfidfMap.put(token, tf * idf);
}
return tfidfMap;
}
// 计算余弦相似度
/**
* 余弦相似度是一种基于向量的相似度度量方法,它对于文本的长度和词汇的分布是敏感的。
* 因此,在计算相似度之前,确保文本已经过适当的预处理和向量化是非常重要的。
* */
public static double cosineSimilarity(Map<String, Double> vector1, Map<String, Double> vector2) {
double dotProduct = 0.0;
double normVector1 = 0.0;
double normVector2 = 0.0;
Set<String> allWords = new HashSet<>(vector1.keySet());
allWords.addAll(vector2.keySet());
for (String word : allWords) {
double freq1 = vector1.getOrDefault(word, 0.0);
double freq2 = vector2.getOrDefault(word, 0.0);
dotProduct += freq1 * freq2;
normVector1 += freq1 * freq1;
normVector2 += freq2 * freq2;
}
return dotProduct / (Math.sqrt(normVector1) * Math.sqrt(normVector2));
}
public static void main(String[] args) {
String text1 = "I like apples";
String text2 = "I enjoy eating apples";
double similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
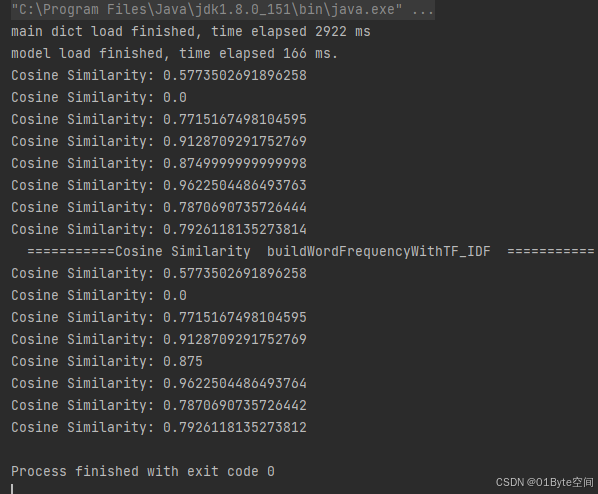
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.5773502691896258
text1 = "I like apples";
text2 = "我喜欢苹果";
similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.0
text1 = "比较这两个字符串:ABCBDAB";
text2 = "不要比较这两个字符串:BDCABC";
similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.7715167498104595
text1 = "这么说有意思吗?";
text2 = "你这么说有意思吗?";
similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.9128709291752769
text1 = "这么说就没意思了,朋友。";
text2 = "这么说就有意思了,朋友。";
similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.8749999999999998
text1 = "This is a simple Chinese text:我爱中国.";
text2 = "This is another simple Chinese text example:我爱中国.";
similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.9622504486493763
text1 = "昨天,我走进了一家新开的咖啡馆,点了一杯拿铁和一块提拉米苏。咖啡馆的装饰很有格调,音乐也很舒缓,让我感觉非常放松。我坐在窗边,享受着午后的阳光,一边品尝着美味的咖啡和甜点,一边思考着接下来的工作计划。";
text2 = "前天,我探访了一家新晋的咖啡店,挑选了一杯香浓的拿铁搭配一块提拉米苏。店内的装潢别具一格,播放着轻柔的音乐,营造出一种惬意的氛围。我找了个靠窗的位置坐下,沐浴在温暖的午后阳光下,一边细细品味着手中的咖啡和糕点,一边规划着未来的工作事项。";
similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.7870690735726444
text1 = "昨天,我走进了一家新开的咖啡馆,点了一杯拿铁和一块提拉米苏。咖啡馆的装饰很有格调,音乐也很舒缓,让我感觉非常放松。我坐在窗边,享受着午后的阳光,一边品尝着美味的咖啡和甜点,一边思考着接下来的工作计划。";
text2 = "昨天,我探访了一家新晋的咖啡店,挑选了一杯香浓的拿铁搭配一块提拉米苏。店内的装潢别具一格,播放着轻柔的音乐,营造出一种惬意的氛围。我找了个靠窗的位置坐下,沐浴在温暖的午后阳光下,一边细细品味着手中的咖啡和糕点,一边规划着未来的工作事项。";
similarity = cosineSimilarity(buildWordFrequency(text1), buildWordFrequency(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.7926118135273814
System.out.println(" ===========Cosine Similarity buildWordFrequencyWithTF_IDF =========== " );
text1 = "I like apples";
text2 = "I enjoy eating apples";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.5773502691896258
text1 = "I like apples";
text2 = "我喜欢苹果";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.0
text1 = "比较这两个字符串:ABCBDAB";
text2 = "不要比较这两个字符串:BDCABC";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.7715167498104595
text1 = "这么说有意思吗?";
text2 = "你这么说有意思吗?";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.9128709291752769
text1 = "这么说就没意思了,朋友。";
text2 = "这么说就有意思了,朋友。";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.875
text1 = "This is a simple Chinese text:我爱中国.";
text2 = "This is another simple Chinese text example:我爱中国.";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.9622504486493764
text1 = "昨天,我走进了一家新开的咖啡馆,点了一杯拿铁和一块提拉米苏。咖啡馆的装饰很有格调,音乐也很舒缓,让我感觉非常放松。我坐在窗边,享受着午后的阳光,一边品尝着美味的咖啡和甜点,一边思考着接下来的工作计划。";
text2 = "前天,我探访了一家新晋的咖啡店,挑选了一杯香浓的拿铁搭配一块提拉米苏。店内的装潢别具一格,播放着轻柔的音乐,营造出一种惬意的氛围。我找了个靠窗的位置坐下,沐浴在温暖的午后阳光下,一边细细品味着手中的咖啡和糕点,一边规划着未来的工作事项。";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.7870690735726442
text1 = "昨天,我走进了一家新开的咖啡馆,点了一杯拿铁和一块提拉米苏。咖啡馆的装饰很有格调,音乐也很舒缓,让我感觉非常放松。我坐在窗边,享受着午后的阳光,一边品尝着美味的咖啡和甜点,一边思考着接下来的工作计划。";
text2 = "昨天,我探访了一家新晋的咖啡店,挑选了一杯香浓的拿铁搭配一块提拉米苏。店内的装潢别具一格,播放着轻柔的音乐,营造出一种惬意的氛围。我找了个靠窗的位置坐下,沐浴在温暖的午后阳光下,一边细细品味着手中的咖啡和糕点,一边规划着未来的工作事项。";
similarity = cosineSimilarity(buildWordFrequencyWithTF_IDF(text1), buildWordFrequencyWithTF_IDF(text2));
System.out.println("Cosine Similarity: " + similarity);//Cosine Similarity: 0.7926118135273812
}
}
输出结果:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











