







 超级会员免费看
超级会员免费看
简介
- 此前,无论是回归问题还是分类问题,本质上其实都属于有监督学习范畴:即算法的学习是在标签的监督下进行规律学习,也就是学习那些能够对标签分类或者数值预测起作用的规律
- 而无监督学习,则是在没有标签的数据集中进行规律挖掘,既然没有标签,自然也就没有了规律是否对预测结果有效一说,也就失去了对挖掘规律的“监督”过程,这也就是无监督算法的由来
- 而如果一个数据集没有标签,我们就只能围绕特征矩阵进行规律挖掘,更具体的来说,面对没有标签的数据集,我们只能去尽可能的探索特征矩阵中的数值分布规律,当然这些规律肯定是需要符合一定的业务场景、拥有一定的现实意义
- 而在所有的无监督学习算法中,最著名的两类算法就是聚类算法和关联规则算法
- 其中聚类算法是去探索特征矩阵中那些样本更加相似、更有可能是同一类(注意,不一定是距离更加接近),并据此对数据集中的样本进行分类(当然有时我们也会针对数据集的列进聚类)
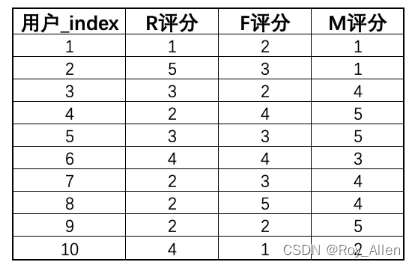
- 著名的如RFM用户价值划分,就是通过三个维度的评估对不同类型用户进行价值划分的聚类过程
- 而关联规则算法则更加聚焦于一个具体的业务场景——即针对一个购物篮数据进行频繁项的挖掘,并据此进一步探索不同数据之间是否存在一定的“关联性”,也就是所谓的关联规则,典型的如啤酒和尿布(尽管已经被证伪),就是在进行关联性的挖掘
- 著名的如RFM用户价值划分,就是通过三个维度的评估对不同类型用户进行价值划分的聚类过程

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











