







作者:
Teng Xi
论文总结:总结
Code: https://github.com/PaddlePaddle/VIMER/tree/main/UFO
摘要:
本文提出了一种新的统一特征优化(Unified Feature Optimization, UFO)范式,用于在现实世界和大规模场景下训练和部署深度模型,这需要多种人工智能功能的集合。UFO旨在通过对所有任务进行大规模的预训练,使每个任务受益。与现有的基础模型相比,UFO有两个重点,即模型尺寸相对较小和NO适应成本:1)UFO以多任务学习的方式将广泛的任务挤压成一个有调节的统一模型,并在转移到下游任务时进一步裁剪模型尺寸。2) UFO不强调转移到新奇的任务。相反,它的目标是使修剪的模型专门用于一个或多个已经看到的任务。为此,直接选择统一模型中的部分模块,完全不需要任何适配成本。有了这两个特点,UFO在保持大规模预训练优势的同时,为灵活部署提供了极大的便利。UFO的一个关键优点是,裁剪过程不仅减少了模型尺寸和推理消耗,而且甚至提高了某些任务的准确性。具体来说,UFO考虑了多任务训练,给统一模型带来了双重影响:一些密切相关的任务相互受益,而一些任务相互冲突。UFO通过一种新颖的网络架构搜索(NAS)方法来减少冲突并保持双方的利益。在广泛的深度表征学习任务(如人脸识别、人再识别、车辆再识别和产品检索)上的实验表明,从UFO中裁剪的模型比单任务训练的模型具有更高的准确性,但模型尺寸更小,验证了UFO的概念。此外,UFO还支持发布170亿参数的计算机视觉(CV)基础模型,这是业内最大的CV模型。
1简介
训练和部署是基于深度学习的人工智能(AI)应用的两个重要步骤。一个现实的AI系统通常包含多个任务。简单的训练和部署策略是针对每个单独的子任务训练各自的深度模型。假设一些子任务实际上是相关的,这种幼稚的策略浪费了它们的共同利益。基础模型是利用大规模多任务数据使单个任务受益的一种可行方法。根据[3],在本文中,我们将基础模型称为“在大规模的数据上训练的模型,可以适应广泛的下游任务”。但是,基础模型的部署有一定的负担,例如,它维持了庞大的基础模型规模,并且在转移到下游任务时需要额外的适应成本。
本文提出了一种新的训练与部署模式,即统一特征优化(UFO),以帮助下游任务进行大规模的多任务预训练。与foundation模型相比,UFO有两个不同的侧重点,即模型尺寸相对较小和NO适应成本。1)模型尺寸小。UFO并不使用巨大的网络。相反,它将广泛的任务压缩到一个中等大小的统一模型中,并进一步为下游应用程序削减模型大小,从而使推理更加有效。2)没有适应成本。UFO不强调转移到新奇的任务。相反,它的目标是使修剪模型专用于已经看到的子任务。无需微调或基于提示的学习,UFO直接从已经学习的统一模型中选择部分组件,因此完全不需要适应成本。
UFO具有模型尺寸小、适应成本低的优点,在保持大规模预训练优势的同时,为灵活部署提供了极大的便利。虽然没有适应成本的优势局限于已经看到的子任务,但它确实损害了现实的人工智能发展的巨大利益。例如,在智能城市原型中,如基于视觉的智能城市,系统需要人脸、车身和汽车的协同,以提供对城市状态的全面了解。此外,虽然UFO不强调转移到新颖的下游任务的模式,但它通过现有的基础模型技术与该模式兼容,这不是本文主要关注的问题。由于它们的正交优势,我们相信UFO和基础模型可以很好的合作,带来另一波的发展。
作为早期的探索,本文提出了UFO的概念,重点关注深度表示学习,如图1所示。深度表示学习是许多人工智能应用的基础,如人脸识别[2,24,7]、人/车再识别[19,19,18,22,17]和细粒度图像检索[26]。我们的UFO基于视觉转换器(ViT)[10]架构。UFO首先以多任务学习的方式对各种深度表示任务训练一个统一模型(即超级网络)。之后,UFO学会修剪超级网络,以获得一个专门的子任务子网。给予ViT骨干,修剪对象可以是变压器、注意头和FFN通道从粗粒度到细粒度的子块,如图1所示。此外,UFO在FFN路径层面整合了另一种修剪策略。在[12]之后,UFO在训练超级网络时并行使用多个FFN路径,并允许为下游任务修剪一些FFN路径。虽然这些裁剪策略很流行,但UFO是第一个将它们集成在一起的,因此提供了很大的裁剪灵活性。
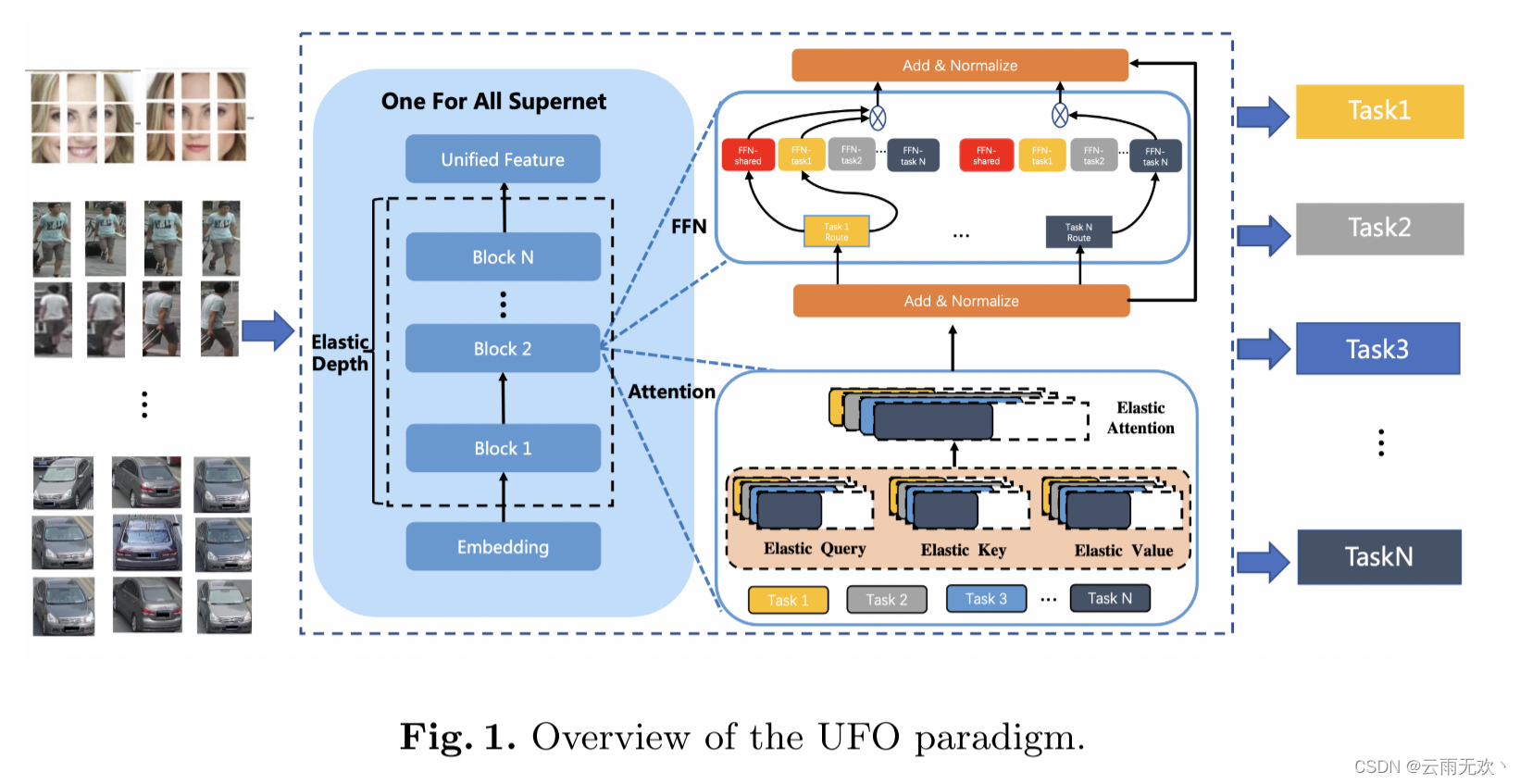
UFO的一个重要优点是,裁剪过程不仅减少了模型尺寸和推理消耗,而且提高了对其专用子任务的精度。这是非常重要的,因为修剪模型(没有进一步的微调)通常会降低精度。为此,UFO认为多任务训练给超级网络带来了双重影响。一方面,有些任务相互联系紧密,互惠互利。另一方面,一些任务存在较大分歧,相互冲突。在裁剪过程中,UFO通过一种新颖的网络架构搜索(NAS)方法来减少冲突并保持双方的利益。具体来说,我们为UFO设计了一个搜索空间,它首先引入了FFN路径和超级网络。因此,我们提出了一种端到端的UFO训练策略,不同于以往的多阶段方法[4,20]。同时,我们还提出了一种新的UFO评估指标,该指标可以灵活地适应实际应用的任何要求。在广泛的深度表征学习任务上的实验表明,与单任务训练的对象相比,UFO在较小裁剪模型下获得更高的精度。它证实,虽然UFO获得了灵活部署的额外优势,但它保持了大规模预训练的好处。
本文的贡献归纳如下:
- 我们提出了一种新的训练-部署模式,称为统一特征优化(UFO),以使下游任务受益与大规模的前训练。UFO强调了模型尺寸小和无适应成本的优势,这大大促进了灵活部署。
- 我们提出了一种新颖的UFO裁剪过程,致力于通过NAS方法保持多任务统一模型的互利和消除相互冲突。
- 提出了一种新的评价指标来衡量任务之间的相关性,为裁减过程提供了基础和有效的分析。
- 我们在人脸、人、车辆和产品等10多个基准上进行实验。全面的分析和广泛的实验清楚地表明我们的UFO的有效性。
2 相关工作
智慧城市的发展对多个目标的优化提出了重要的要求,以提供各种现实世界问题的综合解决方案。随着模型和任务数量的整体增加,为特定的任务部署特定的模型需要大量的计算和推理成本,特别是部署在计算和功率资源可能有限的嵌入式传感器或设备上。解决这个问题的一种方法是开发基础模型,这是指从大规模的数据中训练出来的模型,能够适应广泛的下游任务。现有的作品试图从以下两个方面来克服这些挑战。
2.1训练策略
调整不同任务损失的权重是一种有效的方法。Kendall等人提出了一种原则性方法,通过考虑每个任务的同方差不确定性来调整多个损失函数的权值。动态任务优先级[14]通过自适应调整任务损失目标的混合权重,自动对难度较大的任务进行优先级排序。其他作品则采用基于梯度的方法来应对这一挑战。GradNorm[6]通过动态调整梯度大小,自动平衡深层多任务模型中不同任务损失的训练。Sener等人[37]明确地将多任务学习转化为基于梯度的多目标优化,总体目标是寻找Pareto最优解,以最小化所有任务损失。Suteu et al.[40]观察到,任务梯度之间角度的方差越小,模型的性能越好,因此,Suteu et al.[40]提出了一种改进近正交梯度的新型梯度正则化方法。为了避免不同损耗的梯度干扰,PCGrad[43]将一个任务的梯度投影到有冲突梯度的其他任务的梯度的法平面上。
与这些方法相比,我们的方法设计了一种新的模型结构,自适应地指定所有任务之间的关联或冲突,即使使用普通的训练策略也能获得竞争结果。
2.2模型结构
部分文献[11,34,29,13]采用了软参数共享的方式。它们允许每个任务有单独的模型和参数,但强制每个模型可以通过正则化器[11,34]或NAS search结构[13]访问其他模型中的信息。
其他研究[31,33,39,30]使用骨干参数的共享部分与特定任务模块,称为硬参数共享。深度关系网络[31]方法共享前5个卷积层,并为每个任务使用特定于任务的全连接层。Lu等人的[33]从一个瘦网络开始,并在训练阶段通过为任务创建新的分支来动态增长它。除了计算机视觉领域外,[39,30]在多个NLP任务中,对任务特定层使用共享编码器。
在这两种学习方式的基础上,Task-MOE[25]提出了一种将共享模块和特定于任务的模块相结合的多任务学习体系结构。具体来说,它共享自注意模块,并基于任务级路由器选择特定于任务的FFN模块。
所有这些工作都考虑通过鼓励单个任务之间的信息交互来增加组件,或者引入特定于任务的模块,但都没有减少模块的想法。相比之下,我们通过减少不兼容权值和保持互补权值从超网络中提取子网。与Task-MOE相似,我们的方法也采用任务级路由器来选择特定的ffn。然而,我们的方法为每个任务提取最合适的自我注意子权重,而task - moe在所有任务中共享完成的子权重。
3研究方法
UFO由两个步骤组成,即训练一个多任务超级网络,以及提取一个用于下游任务部署的专用子网络。在这种新的训练和部署模式下,UFO的目标是保持多任务训练前的互惠互利,消除不同任务之间的相互冲突。为此,我们采用了一种神经结构搜索(NAS)方法从超级网络中搜索子网。具体来说,我们在3.1节中介绍了UFO超级网的架构及其搜索空间。我们注意到,与针对单个任务的搜索空间不同,UFO搜索空间是为各种下游任务容纳多个子网络。考虑到UFO超级网的架构,章节3.2解释了如何以多任务学习的方式训练超级网在所有任务上。最后,3.3节详细介绍了学习基于NAS的子网络提取。它允许UFO通过架构预测直接提取相应的子网络,给定所需的下游任务(以及模型大小和推理速度)。
3.1 UFO超级网络的架构和搜索空间
如图1所示,我们将UFO超级网建立在视觉转换器(ViT)的基础上。由于子网络从超级网络中选择部分模块并继承在部署过程中相应的参数,超级网络为搜索和提取子网提供了较大的空间是很重要的。
现有的基于变压器的NAS通常提供三个搜索方向,即前馈网络(FFN)的弹性深度、弹性注意头和弹性扩展比[25]。在这些常用的搜索方向的基础上,我们引入了一种新的搜索方向,即灵活的FFN路径。也就是说,UFO结合了三个常用的搜索方向和一个新颖的搜索方向,提供了很大的搜索空间。因此,子网络可以减少视觉转换器的FFN路径、FFN权值、注意权值甚至整个子块。我们将在下面详细解释这些搜索方向。

3.2 UFO超级网的多任务训练
在本小节中,我们将描述如何训练多任务超级网络。如3.1小节所示,UFO中的超级网与其他单任务超级网有很大的不同。因此,UFO的训练策略在子网络采样和数据采样两个方面也有所不同。
子网络抽样。 子网络抽样涉及到(ml, hl, dl, gl)的抽样。类似于权值纠缠机制[5],对于ml和gl的采样,arch a的公共部分的权值与超级网的权值共享。然而,由于超级网在现有的训练策略中没有ffnpath[5,20,41],因此共享的注意权值之间存在着严重的竞争。因此,他们的超级网络必须循序渐进地训练。在UFO中,ffn路径缓解了共同关注的竞争。因此,UFO可以以端到端的方式进行训练。

数据采样 [1]中现有的数据采样策略有五种。累积梯度策略是其中最有前途的一种策略。它在一个优化步骤中积累所有任务数据的梯度,可以在不同任务之间实现比其他方法更好的优化权衡,例如逐个任务和交替方法。受此思想的启发,我们提出了一种相似但又不同的批处理策略,称为异质批处理类型。具体来说,我们从T的所有任务中抽取一些数据,形成一个小批处理,其权重分别大致与任务数据集的大小成正比。然后,这些迷你批处理被连接成批处理数据,这些数据被提供给主干。然后,将获得的特征进行分离并送入|T|任务特定的头部网络,每个头部网络负责任务的输出。最后,计算共享变换骨干网的|T|任务的损耗,并将其累加起来,完成一个后退步得到梯度,用于更新共享参数。
3.3提取部署下游任务的子网络
在本小节中,我们将介绍如何根据实际应用的需要从超级网络中选择最优的专用模型。我们的目标是在flops和参数约束下找到a的最优架构a,使平均性能最大化。

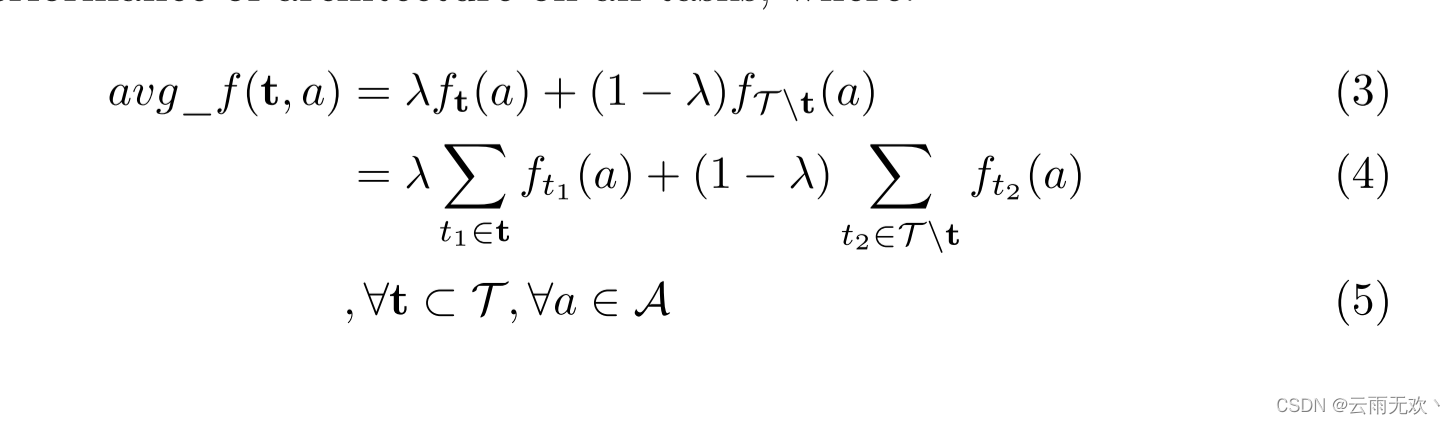


















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











