







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
学习心得
在学习tensorflow的过程中,它与pytorch的相同点以及不同点十分突出。但是总的来说,在代码实现的过程中,最大的感受还是两者只是在代码格式上的区别,基本内核和核心的部分基本是一样的。不过tensorflow在使用时,对兼容性的要求非常高,很容易出现各种不兼容的报错。建议是在要用的时候再去下载对应的包,不然资源冗杂很容易出现不兼容的情况。还有就是在学习教案上的代码时,尽量做到将涉及的函数的含义和用法全部搞清楚,这样的学习比较系统和科学。
一、前期工作
1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
# 这段代码使用了TensorFlow库中的tf.config.list_physical_devices()函数来获取可用的物理设备列表。参数"GPU"表示我们只关心GPU设备,而不关心其他类型的设备(如CPU)。
if gpus:
gpu0 = gpus[0] #在多个GPU里只选择第0个gpu使用
# 将第一个GPU设备(gpu0)设置为内存增长模式。在这种模式下,TensorFlow会根据需要动态地分配和释放GPU内存,而不是一开始就占用所有可用的GPU内存。
tf.config.experimental.set_memory_growth(gpu0,True)
# 设置TensorFlow的可见设备。
tf.set_visible_devices([gpu0],"GPU")
2.导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels),(test_images, test_labels) = datasets.mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 [==============================] - 4s 0us/step
3.归一化
参考文章:K同学啊:归一化与标准化
归一化的作用是使不同量纲的特征处于同一个数量级,减少方差带来的影响,同时加快收敛速度。 特征值较大时,梯度值也较大。在模型反向传播时,梯度值更新与学习率一样。学习率小时会导致收敛缓慢,学习率过大又会导致模型不易收敛。因此将图像归一化可以将不同维度的特征调整到相近的区间内,就可以用统一的学习率加速模型的训练。
归一化:将数收敛到(0,1)之间;缩放仅与最大值最小值有关 标准化:将数据按比例缩放,使其落入特定的区间,与每个值都有关
标准化:与每个点都有关;将数据按比例缩放,使其落入一个特定区间
标准化将数值转化成均值为0,标准差为1的分布(不一定是正态分布)
# 对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。
train_images, test_images = train_images / 255.0, test_images / 255.0
train_images.shape, test_images.shape, train_labels.shape, test_labels.shape
((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
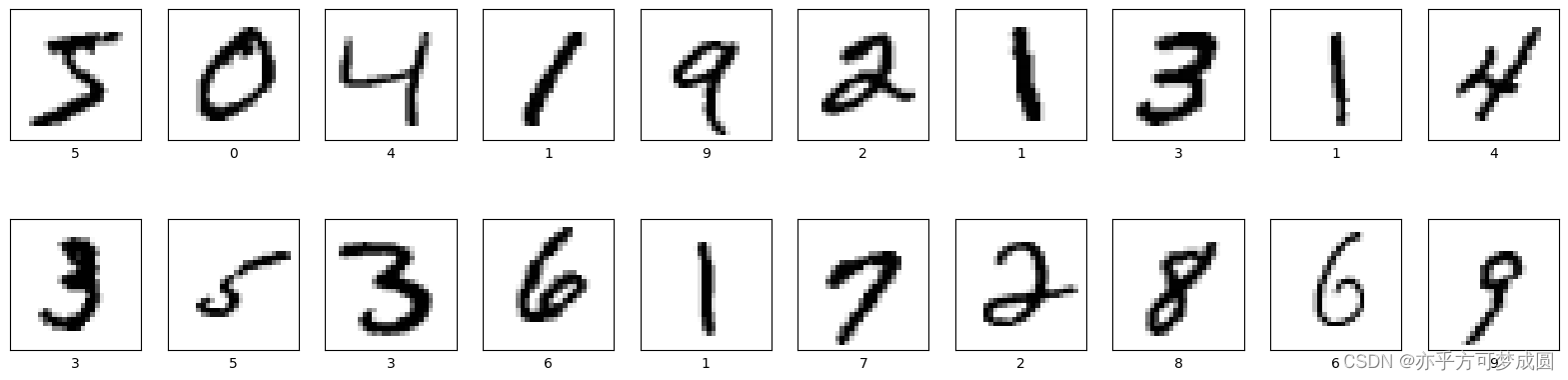
4.可视化图片图
plt.figure(figsize = (20,5))
for i in range(20):
plt.subplot(2,10,i+1) # subplot(子图行数,子图列数,子图索引(从1开始))
# 不显示轴刻度
plt.xticks([])
plt.yticks([])
# 不显示子图网格线
plt.grid(False)
# cmap为颜色图谱,“plt.cm.binary将像素值映射为黑色和白色。”
plt.imshow(train_images[i], cmap = plt.cm.binary)
# 设置x轴标签显示为对应的数字
plt.xlabel(train_labels[i])
plt.show()
5.调整图片格式
train_images = train_images.reshape((60000,28,28,1)) # 对灰度图像来说,通道数为1
test_images = test_images.reshape((10000,28,28,1))
test_images.shape,test_images.shape, train_labels.shape, test_labels.shape
((10000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
构建CNN网络模型
ReLU(整流线性单元)激活函数在神经网络中得到了广泛的应用,主要有以下原因:
缓解梯度消失问题:在深度神经网络中,ReLU可以帮助缓解梯度消失的问题。这是因为ReLU激活函数在输入值小于0时为0,大于0时保持原样,因此不存在梯度为0的情况,从而使得模型训练过程中的梯度求解变得容易。
计算简单且高效:ReLU激活函数的实现只需要一个max()函数,这使得模型的训练过程更加高效。
强大的非线性拟合能力:ReLU函数具有强大的非线性拟合能力,可以最大限度地发挥神经元的筛选能力。虽然从单看ReLU函数的左边或者右边,确实是线性的,整体来看,也确实是分段函数,说它是非线性函数也勉强说得过去。不会对模型的泛化准确度造成显著影响:ReLU激活函数在保持模型训练速度的同时,并不会对模型的泛化性能产生负面影响。
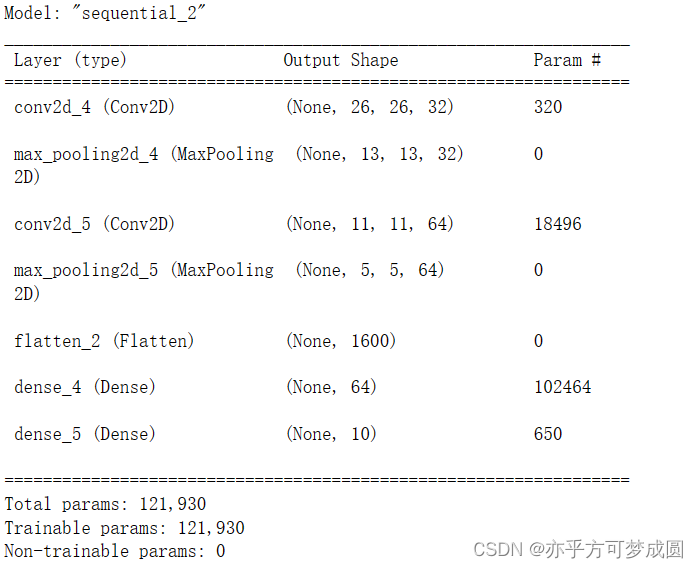
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape = (28, 28, 1)),
layers.MaxPool2D((2, 2)),
layers.Conv2D(64, (3, 3),activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
model.summary()
使用layers.Dense()的语法如下:
layers.Dense(units, activation=None, use_bias=True, kernel_initializer=‘glorot_uniform’, bias_initializer=‘zeros’, kernel_regularizer=null, bias_regularizer=null, activity_regularizer=null, kernel_constraint=null, bias_constraint=null)
units 参数表示输出空间的维度;
activation 参数用于指定激活函数,如 ‘relu’、'sigmoid’等;
use_bias 参数是一个布尔值,用于决定是否使用偏置项;
kernel_initializer、bias_initializer等参数用于设置权重和偏置项的初始化方法;
kernel_regularizer、bias_regularizer等参数用于设置权重和偏置项的正则化方法;
activity_regularizer 参数用于设置层的正则化方法;
kernel_constraint、bias_constraint等参数用于设置权重和偏置项的约束条件。
三、编译模型
model.compile()是Keras中用于配置模型的编译过程的方法。
model.compile(loss=None, optimizer=None, metrics=None, loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None)
参数的说明:
1.loss:损失函数,用于衡量模型预测结果与真实标签之间的差异。常用的损失函数有均方误差(MSE)、交叉熵(categorical_crossentropy)等。
2.optimizer:优化器,用于更新模型的权重以最小化损失函数。常用的优化器有随机梯度下降(SGD)、Adam等。
3.metrics:评估指标,用于衡量模型的性能。常用的评估指标有准确率(accuracy)、精确率(precision)、召回率(recall)等。可以传入一个列表,包含多个评估指标。
4.loss_weights:用于指定不同样本的损失权重。如果提供了这个参数,那么在计算总损失时,每个样本的损失将乘以相应的权重。
5.sample_weight_mode:指定样本权重的模式。可选的值有"temporal"(时间序列模式)和"class_weight"(类别权重模式)。
6.weighted_metrics:用于指定哪些评估指标需要使用权重进行加权平均。可以传入一个列表,包含需要加权的评估指标的名称。
7.target_tensors:用于指定目标张量。在某些情况下,如多输入模型或自定义输出层,可能需要手动指定目标张量。
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
SparseCategoricalCrossentropy()是Keras中用于计算稀疏类别交叉熵损失函数的方法。它适用于处理稀疏数据集,其中类别的数量相对较少。
四、训练模型
model.fit()是Keras中用于训练模型的方法。它接收一些参数,包括训练数据、验证数据、批次大小、迭代次数等,并使用这些参数来更新模型的权重以最小化损失函数。
它的一般用法为:
model.fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
参数说明:
x:训练数据的特征。可以是单个输入张量或包含多个输入张量的列表。
y:训练数据的目标值。可以是单个输出张量或包含多个输出张量的列表。
batch_size:每个批次的训练样本数量。
epochs:训练模型的总迭代次数。
verbose:日志显示级别。可选的值有0(不显示任何信息)、1(显示进度条)和2(显示详细计算信息)。
callbacks:一个回调函数列表,用于在训练过程中执行特定操作。常用的回调函数有ModelCheckpoint(保存模型)、EarlyStopping(提前停止训练)等。
validation_split:指定训练数据中用于验证的比例。例如,如果设置为0.2,则表示20%的数据将用于验证。
validation_data:验证数据的特征和目标值。可以是单个输入张量或包含多个输入张量的列表,以及单个输出张量或包含多个输出张量的列表。
shuffle:是否在每个批次之前对训练数据进行洗牌。默认为True。
class_weight:类别权重,用于处理不平衡数据集。可以是一个字典,将类别映射到相应的权重。
sample_weight:样本权重,用于对不同样本进行加权处理。可以是一个数组,与训练数据的形状相同。
initial_epoch:从哪个迭代次数开始训练。默认为0,即从第一个迭代开始。
history = model.fit(
train_images,
train_labels,
epochs = 10,
validation_data = (test_images, test_labels))
Epoch 1/10
1875/1875 - 23s 12ms/step - loss: 0.1465 - accuracy: 0.9550 - val_loss: 0.0578 - val_accuracy: 0.9806
Epoch 2/10
1875/1875 - 25s 13ms/step - loss: 0.0491 - accuracy: 0.9850 - val_loss: 0.0362 - val_accuracy: 0.9882
Epoch 3/10
1875/1875 - 21s 11ms/step - loss: 0.0334 - accuracy: 0.9895 - val_loss: 0.0451 - val_accuracy: 0.9866
Epoch 4/10
1875/1875 - 20s 11ms/step - loss: 0.0112 - accuracy: 0.9966 - val_loss: 0.0364 - val_accuracy: 0.9899
Epoch 8/10
1875/1875 - 23s 12ms/step - loss: 0.0104 - accuracy: 0.9967 - val_loss: 0.0366 - val_accuracy: 0.9899
Epoch 9/10
1875/1875 - 22s 11ms/step - loss: 0.0078 - accuracy: 0.9974 - val_loss: 0.0501 - val_accuracy: 0.9877
Epoch 10/10
1875/1875 - 22s 12ms/step - loss: 0.0065 - accuracy: 0.9977 - val_loss: 0.0412 - val_accuracy: 0.9905
五、预测
plt.imshow(test_images[1])
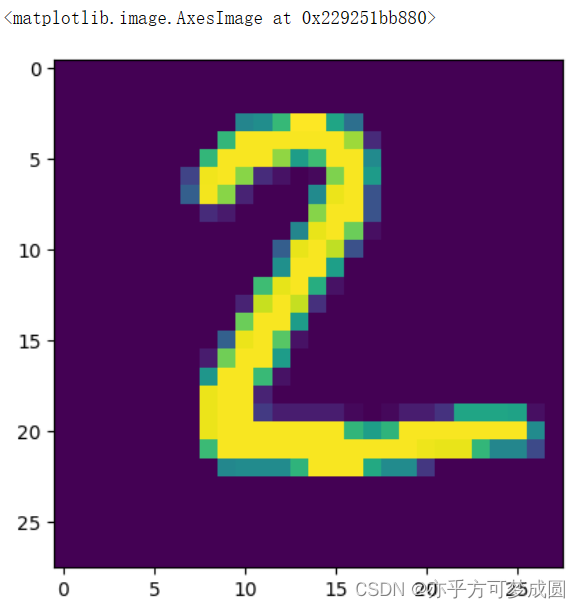
pre = model.predict(test_images)
pre[1]
313/313 [==============================] - 2s 6ms/step
array([ 1.8541143, -3.2595177, 29.620302 , -11.129237 , -4.489938 ,
-20.663198 , 2.7213254, -6.5041213, -1.9739916, -24.11983 ],
dtype=float32)















 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









