






pytorch搭建CNN实现手写英文字母识别:
目录
更新 2024/2/19:
● 对代码的重构和一些细节上的调整
● 对并对功能类似的部分进行了模块化封装
Part1.数据集选取:
The Chars74K dataset:
http://www.ee.surrey.ac.uk/CVSSP/demos/chars74k/
resize后的The Chars74K EnglishImg部分数据集展示,尺寸为28*28:

EMNIST dataset:
https://rds.westernsydney.edu.au/Institutes/MARCS/BENS/EMNIST/emnist-gzip.zip
EMNIST数据集一共包含6个不同的数据类别,由于我们只会用到英文字母手写体,所以只需要emnist-letters part:

其中test表示测试集,train表示训练集,images表示测试集,labels表示标签。其中测试集共20800张,训练集共124800张,图像尺寸均为28*28。
由于网上下载的数据集统一封装为.idx3-ubyte格式,我的做法是将其解析为图片,再用解析的图片训练。
解析后的Emnist_letters部分数据集展示:

解析代码如下(转载自其他博客,时间久远,忘了网址TvT):
from PIL import Image
import struct
#图片:
def read_image(filename):
f = open(filename, 'rb')
index = 0
buf = f.read()
f.close()
magic, images, rows, columns = struct.unpack_from('>IIII' , buf , index)
index += struct.calcsize('>IIII')
for i in range(images):
#for i in range(2000):
image = Image.new('L', (columns, rows))
for x in range(rows):
for y in range(columns):
image.putpixel((y, x), int(struct.unpack_from('>B', buf, index)[0]))
index += struct.calcsize('>B')
#print ('save' + str(i) + 'image')
image1 = image.transpose(Image.FLIP_LEFT_RIGHT)
image2 = image1.rotate(90)
image2.save('train/' + str(i) + '.png')
#标签:
def read_label(filename, saveFilename):
f = open(filename, 'rb')
index = 0
buf = f.read()
f.close()
magic, labels = struct.unpack_from('>II' , buf , index)
index += struct.calcsize('>II')
labelArr = [0] * labels
#labelArr = [0] * 2000
for x in range(labels):
#for x in range(2000):
labelArr[x] = int(struct.unpack_from('>B', buf, index)[0])
index += struct.calcsize('>B')
save = open(saveFilename, 'w')
save.write(','.join(map(lambda x: str(x), labelArr)))
save.write('\n')
save.close()
#print ('save labels success')
if __name__ == '__main__':
imagePath = 'gzip/emnist-letters-train-images-idx3-ubyte'
labelPath = 'gzip/emnist-letters-train-labels-idx1-ubyte'
labelSavTransPath = 'train/label.txt'
#读取数据集:
read_image(imagePath)
#读取标签,并解析为txt文档:
read_label(labelPat, labelSavTransPath)
解析后的标签信息(1-26分别对应英文字母A-Z,不区分大小写):

同时,我们需要将解析后的数据集标签根据一并解析的txt文本里的标签信息进行一一标注,由于我采用的是pytorch里的ImageFolder类进行数据读取,这个类有一个方法能够根据数据所在的不同文件夹对数据进行分类,因此我们只需将不同的字母存放在不同的文件夹下就OK了:

分类代码如下:
import os
import cv2
labels = open("train_label.txt","r")
label = labels.read().split(',')
print(len(label))
#path = 'test/test/'
path = 'train/'
for cnt in range(124800):
image_path = (path+str(cnt)+'.png')
img = cv2.imread(image_path)
#根据图片对应的标签分类到对应的文件夹下:
cv2.imwrite('Train_png/'+label[cnt]+'/'+str(cnt)+'.png',img)
cnt += 1
最后,我采用的最终数据集是将EMnist和The Chars74K融合,多样的数据集能够使训练出的模型具有更好的泛化效果。
Part2.数据预处理:
首先定义超参数:
EPOCH = 2 #训练批次
BATCH_SIZE = 100 #训练的最小规模(一次反向传播更新权重)
LR = 1e-3 #学习率
使用torchvision.datasets下的ImageFolder类构造数据集:
(当然还可以通过重写data.Dataset自定义pytorch数据集类,其他博客也有相关教程)
#数据集要作为一整个文件夹读入:
#构造训练集:
train_data = ImageFolder(root="./Emnist_letters_png/Train_png", transform=transform)
#shuffle代表是否在构建批次时随机选取数据:
train_loader = torch.utils.data.DataLoader(dataset = train_data, batch_size=BATCH_SIZE, shuffle=True)
#构造数据集:
test_data = ImageFolder(root="./Emnist_letters_png/Test_png", transform=transform)
#之所以要将test_data转换为loader是因为网络不支持原始的ImageFolder类数据,到时候直接使用批训练,便是tensor类。因此batch_size为全部testdata(test_data.__len__())
test_loader = torch.utils.data.DataLoader(dataset = test_data, batch_size=test_data.__len__())
其中:
torch.utils.data.DataLoader是PyTorch中数据读取的一个重要接口,能够将自定义的Dataset封装成一个Batch Size大小的Tensor,用于后面的训练。
transform作为对数据集的自定义预处理函数:
# 数据预处理 转为tensor 以及 标准化:
transform = T.Compose([
#转为灰度图像:
T.Grayscale(num_output_channels=1),
#将图片转换为Tensor,归一化至(0,1):
T.ToTensor(),
#T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
Part3.网络搭建:
本次训练字母识别使用的网络类似于LeNet-5的结构:两层卷积网络(卷积+池化)+三层全连接层:
注:若损失函数选用交叉熵损失,就不需要添加Softmax层,因为交叉熵损失的计算过程就包含了计算Softmax(Softmax+负对数损失)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
#Sequential()把不同的函数组合成一个模块使用:
#定义网络框架:
self.Conv1 = nn.Sequential(
#卷积层1(卷积核=16)
nn.Conv2d(
in_channels = 1, #输入图像的通道数,即输入高度为1
out_channels = 16, #定义16个卷积核,,即输出高度为16
kernel_size = 5, #卷积核size为(5,5)
stride = 1, #步长
padding = 2, #边界填充为0 (如步长为1时,若要保证输出尺寸像和原尺寸一致,计算公式为:padding = (kernel_size-1)/2)
),
#激活函数层
nn.ReLU(),
#最大池化层
nn.MaxPool2d(kernel_size = 2)
)
self.Conv2 = nn.Sequential(
#卷积层2
nn.Conv2d(16, 32, 5, 1, 2),
nn.Dropout(p=0.2),
#激活函数层
nn.ReLU(),
#最大池化层
nn.MaxPool2d(kernel_size = 2)
)
#最后接上三层全连接(将图像变为1维)
#为什么是32*7*7:(1,28,28)->(16,28,28)(conv1)->(16,14,14)(pool1)->(32,14,14)(conv2)->(32,7,7)(pool2)->output
self.Linear = nn.Sequential(
nn.Linear(32*7*7,400),
#Dropout按概率p随机舍去部分神经元
nn.Dropout(p=0.2),
nn.ReLU(),
nn.Linear(400,80),
nn.ReLU(),
nn.Linear(80,label_num),
)
#前向传播:
def forward(self, input):
input = self.Conv1(input)
input = self.Conv2(input) #view可理解为resize
#input.size() = [100, 32, 7, 7], 100是每批次的数量,32是厚度,图片尺寸为7*7
#当某一维是-1时,会自动计算他的大小(原则是总数据量不变):
input = input.view(input.size(0), -1) #(batch=100, 1568), 最终效果便是将二维图片压缩为一维(数据量不变)
#最后接上一个全连接层,输出为10:[100,1568]*[1568,10]=[100,10]
output = self.Linear(input)
return output
cnn = CNN()
#print(cnn)
#定义优化器(Adam优化算法,能够计算自适应性学习率)
optimizer = torch.optim.Adam(cnn.parameters(), lr = LR)
#定义损失函数(因为是分类问题,所以使用交叉熵损失)
loss_func = nn.CrossEntropyLoss()
print(cnn)显示网络层结构:
CNN(
(Conv1): Sequential(
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(Conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): Dropout(p=0.2, inplace=False)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(Linear): Sequential(
(0): Linear(in_features=1568, out_features=400, bias=True)
(1): Dropout(p=0.2, inplace=False)
(2): ReLU()
(3): Linear(in_features=400, out_features=80, bias=True)
(4): ReLU()
(5): Linear(in_features=80, out_features=26, bias=True)
)
)
Part4.训练与模型保存:
在训练过程中,我们根据定义的Epoch进行循环,每次Epoch分为若干个step,一般step=Total/Epoch
#为了可视化网络在测试集上的效果,我们需要将测试集传入网络测试,但一直苦恼于网络不接受ImageFolder类只接受Tensor类数据,这里使用一个小技巧:将测试集也封装为DataLoader类,batch设置为整个测试集大小,遍历时将图像与标签分别读取就OK了。
for epoch in range(EPOCH):
#enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列。例:['A','B','C']->[(0,'A'),(1,'B'),(2,'C')],
#这里是为了将索引传给step输出
for step, (x, y) in enumerate(train_loader):
output = cnn(x)
loss = loss_func(output, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if step % 100 == 0:
#enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列。例:['A','B','C']->[(0,'A'),(1,'B'),(2,'C')]
for (test_x, test_y) in test_loader:
#print(test_y.size())
#在所有数据集上预测精度:
#预测结果 test_output.size() = [10000,10],其中每一列代表预测为每一个数的概率(softmax输出),而不是0或1
test_output = cnn(test_x)
#torch.max()则将预测结果转化对应的预测结果,即概率最大对应的数字:[10000,10]->[10000]
pred_y = torch.max(test_output,1)[1].squeeze() #squeeze()默认是将a中所有为1的维度删掉
#pred_size() = [10000]
accuracy = sum(pred_y == test_y) / test_data.__len__()
print('Eopch:', epoch, ' | train loss: %.6f' % loss.item(), ' | test accracy:%.5f' % accuracy, ' | step: %d' % step)
#为tensorboardX添加可视化日志:
#1.添加训练集损失
# SumWriter.add_scalar("train loss:",loss.item()/20, global_step = 20)
# #计算测试集精度
# test_output = cnn(test_x)
# pred_y = torch.max(test_output,1)[1].squeeze()
# accuracy = sum(pred_y == test_y) / test_data.__len__()
# #2.添加测试集精度
# SumWriter.add_scalar("test accuracy:",accuracy.item(),20)
# #预处理当前batch:
# b_x_im = utils.make_grid(x, nrow = 16)
# #3.添加一个batch图像的可视化
# SumWriter.add_image('train image sample:', b_x_im, 20)
# #4.添加直方图可视化网络参数分布:
# for name, param in cnn.named_parameters():
# SumWriter.add_histogram(name, param.data.numpy(), 20)
scheduler.step()
#仅保存训练好的参数
torch.save(cnn.state_dict(), 'EMNIST_CNN.pkl')
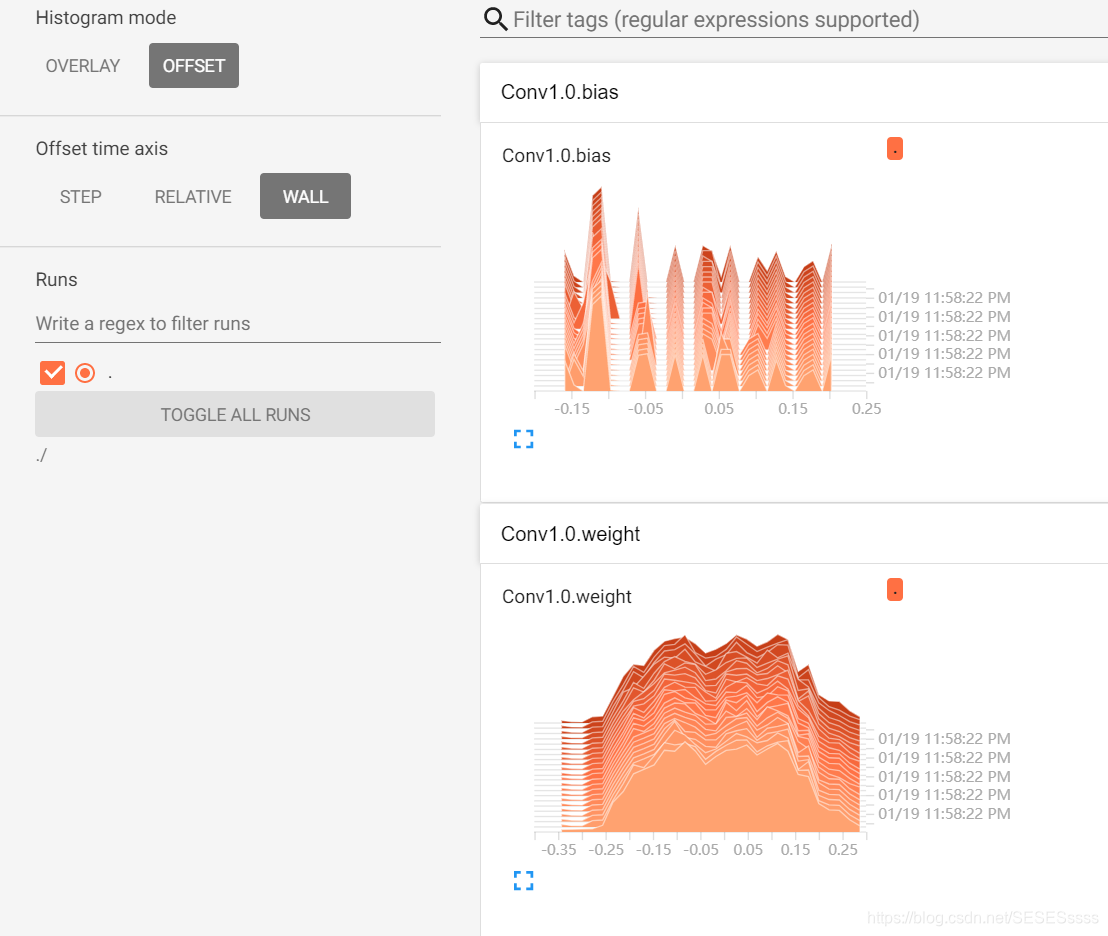
使用tensorboard可视化训练过程:
损失与测试集准确率:
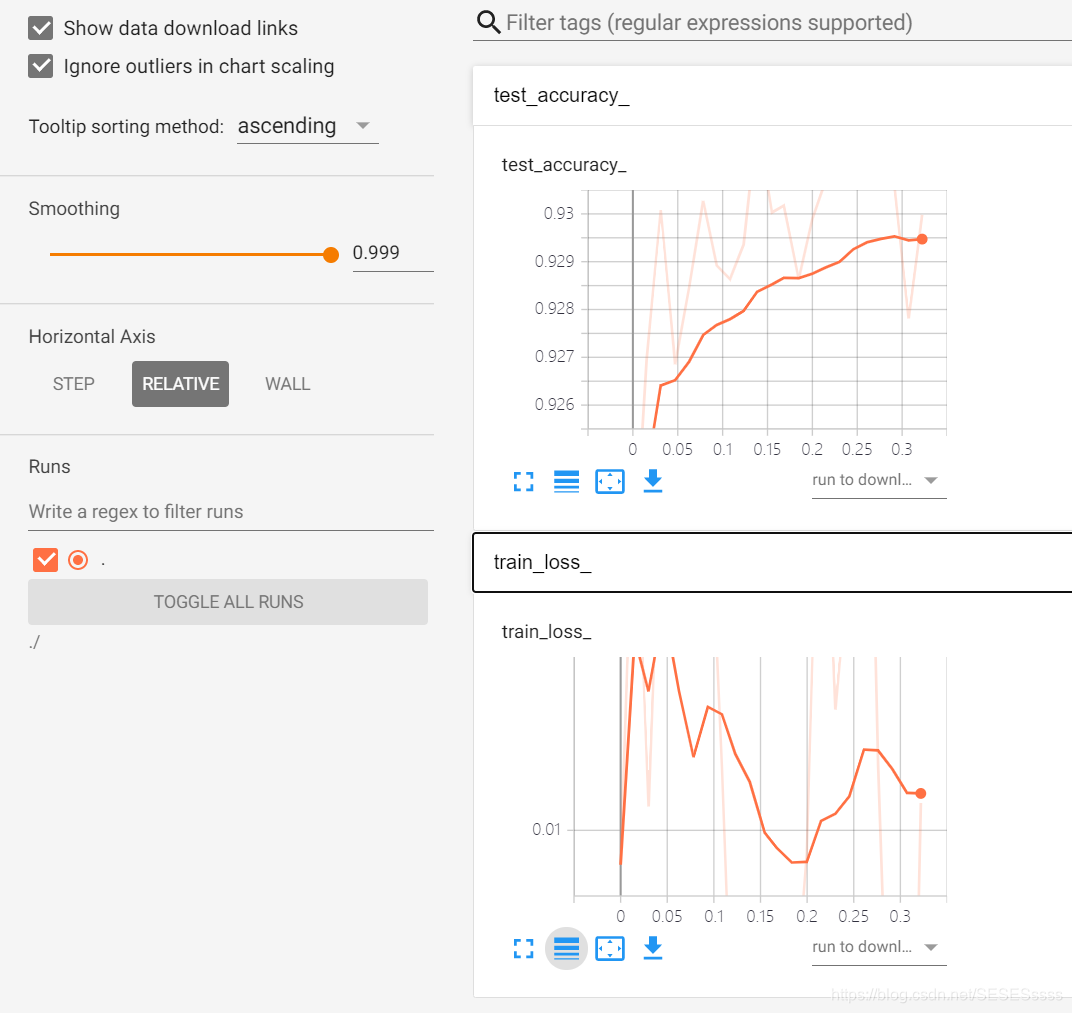
网络权重的直方图分布:
最终的训练精度达到了大约93%:
Eopch: 1 | train loss: 0.198971 | test accracy:0.93221 | step: 400
Eopch: 1 | train loss: 0.111288 | test accracy:0.93173 | step: 500
Eopch: 1 | train loss: 0.205008 | test accracy:0.93303 | step: 600
Eopch: 1 | train loss: 0.222448 | test accracy:0.93413 | step: 700
Eopch: 1 | train loss: 0.292033 | test accracy:0.93048 | step: 800
Eopch: 1 | train loss: 0.199204 | test accracy:0.93144 | step: 900
Eopch: 1 | train loss: 0.134805 | test accracy:0.93072 | step: 1000
[Finished in 874.9s]
Part5.模型读取并测试自己的数据:
读取权重,输入待预测图像:
#读取网络框架
cnn = CNN()
#读取权重:
cnn.load_state_dict(torch.load('EMNIST_CNN.pkl'))
#test_x:(10000行1列,每列元素为28*28矩阵)
# 提供自己的数据进行测试:
my_img = plt.imread("Emnist_letters_png/My_jpg/8.jpg")
my_img = my_img[:,:,0] #转换为单通道
my_img = cv2.resize(my_img,(28,28))#转换为28*28尺寸
my_img = torch.from_numpy(my_img)#转换为张量
my_img = torch.unsqueeze(my_img, dim = 0)#添加一个维度
my_img = torch.unsqueeze(my_img, dim = 0)/255. #再添加一个维度并把灰度映射在(0,1之间)
#print(my_img.size())#torch.Size([1, 1, 28, 28])卷积层需要4个维度的输入
可视化部分+输出预测结果:
#可视化部分:
#输入原图像:
plt.imshow(my_img.squeeze())
plt.show()
#Conv1:
cnt = 1
my_img = cnn.Conv1(my_img)
img = my_img.squeeze()
for i in img.squeeze():
plt.axis('off')
fig = plt.gcf()
fig.set_size_inches(5,5)#输出width*height像素
plt.margins(0,0)
plt.imshow(i.detach().numpy())
plt.subplot(4, 4, cnt)
plt.axis('off')
plt.imshow(i.detach().numpy())
cnt += 1
plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0)
plt.show()
#Conv2:
cnt = 1
my_img = cnn.Conv2(my_img)
img = my_img.squeeze()
for i in img.squeeze():
plt.axis('off')
fig = plt.gcf()
fig.set_size_inches(5,5)#输出width*height像素
plt.margins(0,0)
plt.imshow(i.detach().numpy())
plt.subplot(4, 8, cnt)
plt.axis('off')
plt.imshow(i.detach().numpy())
cnt += 1
#plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0)
plt.show()
#全连接层:
my_img = my_img.view(my_img.size(0), -1)
fig = plt.gcf()
fig.set_size_inches(10000,4)#输出width*height像素
plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0)
plt.margins(0,0)
my_img = cnn.Linear[0](my_img)
plt.subplot(3, 1, 1)
plt.imshow(my_img.detach().numpy())
my_img = cnn.Linear[1](my_img)
my_img = cnn.Linear[2](my_img)
my_img = cnn.Linear[3](my_img)
plt.subplot(3, 1, 2)
plt.imshow(my_img.detach().numpy())
my_img = cnn.Linear[4](my_img)
my_img = cnn.Linear[5](my_img)
plt.subplot(3, 1, 3)
plt.imshow(my_img.detach().numpy())
plt.show()
#输出预测结果:
pred_y = int(torch.max(my_img,1)[1])
#chr()将数字转为对应的的ASCAII字符
print('\npredict character: %c or %c' % (chr(pred_y+65),chr(pred_y+97)))
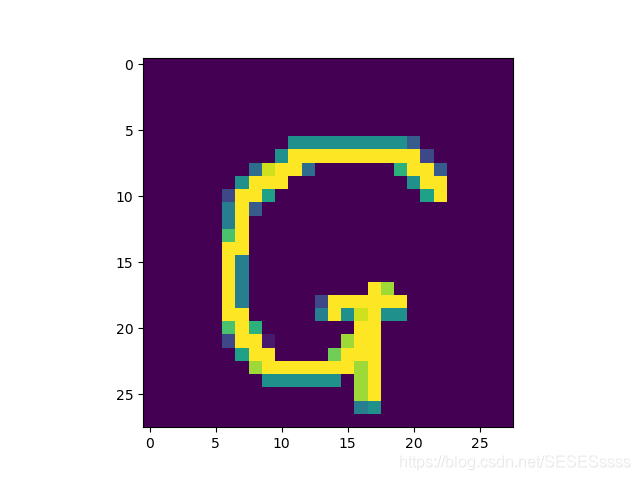
INPUT(我的手写体):
卷积层1:
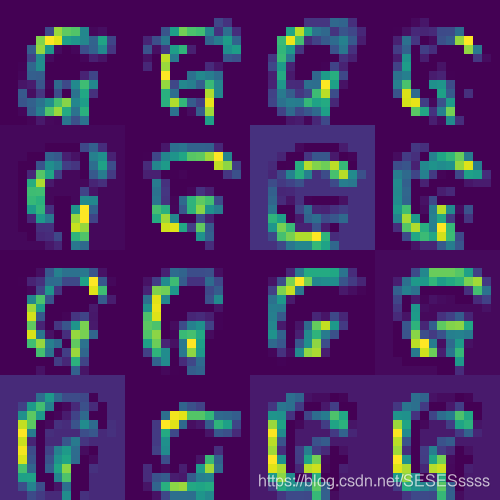
卷积层2:

全连接层:
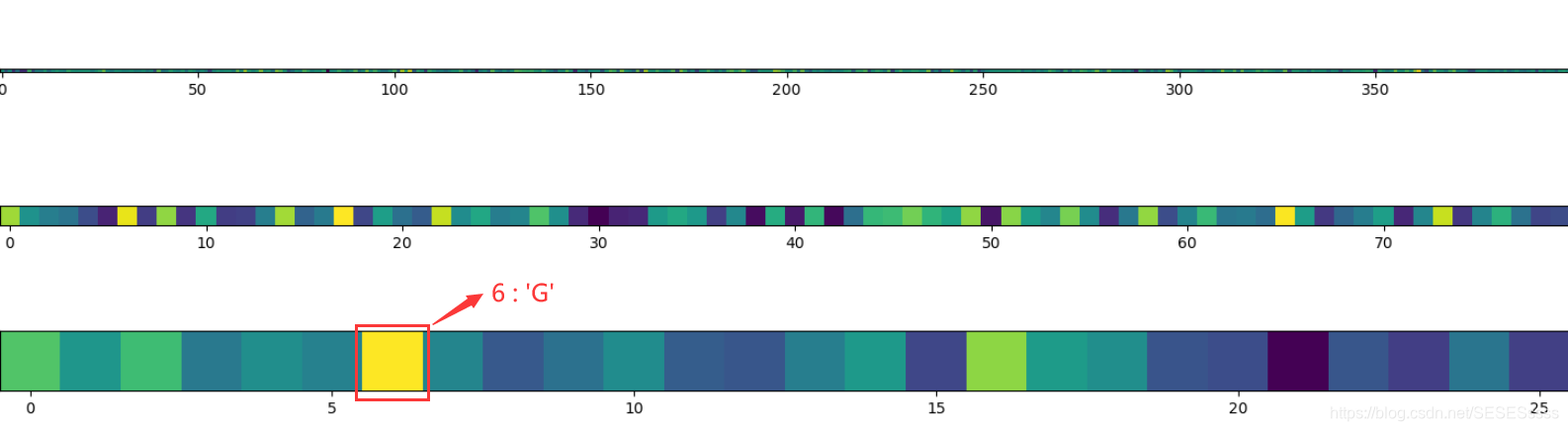
OUTPUT:
predict character: G or g
Part6.完整代码:
import torch
import torch.nn as nn
from torchvision.datasets import ImageFolder
import torchvision.models as models
from torchvision import utils
import torchvision.transforms as T
import torch.utils.data as Data
from PIL import Image
import numpy as np
import torch.optim as optim
import os
import matplotlib.pyplot as plt
#使用tensorboardX进行可视化
from tensorboardX import SummaryWriter
SumWriter = SummaryWriter(log_dir = "./EMNIST_log")
#print(torch.cuda.is_available())
EPOCH = 2
BATCH_SIZE = 128
LR = 1e-4
# 预处理 转为tensor 以及 标准化
transform = T.Compose([
#转为灰度图像:
T.Grayscale(num_output_channels=1),
#将图片转换为Tensor,归一化至(0,1):
T.ToTensor(),
#比如原来的tensor是三个维度的,值在0到1之间,经过以下变换之后就到了-1到1区间
#T.Normalize([0.5], [0.5])
])
#数据集要作为一个文件夹读入:
#读取训练集:
train_data = ImageFolder(root="./Emnist_letters_png/Train_png", transform=transform)
train_loader = torch.utils.data.DataLoader(dataset = train_data, batch_size=BATCH_SIZE, shuffle=True)
#读取测试集:
test_data = ImageFolder(root="./Emnist_letters_png/Test_png", transform=transform)
#之所以要将test_data转换为loader是因为网络不支持原始的ImageFolder类数据,到时候直接使用批训练,便是tensor类。
#batch_size为全部10000张testdata,在全测试集上测试精度
test_loader = torch.utils.data.DataLoader(dataset = test_data, batch_size=test_data.__len__())
label_num = len(train_data.class_to_idx)
#数据可视化:
to_img = T.ToPILImage()
a=to_img(test_data[0][0]) #size=[1, 28, 28]
plt.imshow(a)
plt.axis('off')
plt.show()
# 图片的标签对应其在哪个文件夹下
#print(train_data.class_to_idx)#打印所有标签
#print(test_data.imgs)#打印所有图片对应的路径及标签
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.Conv1 = nn.Sequential(
#卷积层1
nn.Conv2d(1, 16, 5, 1, 2),
nn.BatchNorm2d(16),
#激活函数层
nn.ReLU(inplace=True),
#最大池化层
nn.MaxPool2d(kernel_size = 2)
)
self.Conv2 = nn.Sequential(
#卷积层2
nn.Conv2d(16, 32, 5, 1, 2),
nn.BatchNorm2d(32),
#激活函数层
nn.ReLU(inplace=True),
#最大池化层
nn.MaxPool2d(kernel_size = 2)
)
#最后接上一个全连接层(将图像变为1维)
#为什么是32*7*7:(1,28,28)->(16,28,28)(conv1)->(16,14,14)(pool1)->(32,14,14)(conv2)->(32,7,7)(pool2)->output
self.Linear = nn.Sequential(
nn.Linear(32*7*7,800),
nn.Dropout(p = 0.5),
nn.ReLU(inplace=True),
nn.Linear(800,160),
nn.Dropout(p = 0.5),
nn.ReLU(inplace=True),
nn.Linear(160,label_num),
)
def forward(self, input):
input = self.Conv1(input)
input = self.Conv2(input) #view可理解为resize
#input.size() = [100, 32, 7, 7], 100是每批次的数量,32是厚度,图片尺寸为7*7
#当某一维是-1时,会自动计算他的大小(原则是总数据量不变):
input = input.view(input.size(0), -1) #(batch=100, 1568), 最终效果便是将二维图片压缩为一维(数据量不变)
#最后接上一个全连接层,输出为10:[100,1568]*[1568,10]=[100,10]
output = self.Linear(input)
return output
cnn = CNN()
cnn.load_state_dict(torch.load('EMNIST_CNN.pkl'))
cnn.train()
print(cnn)
#定义优化器
optimizer = torch.optim.Adam(cnn.parameters(), lr = LR)
#定义损失函数
loss_func = nn.CrossEntropyLoss()
#根据EPOCH自动更新学习率,2次EPOCH学习率减少为原来的一半:
#scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma = 0.6, last_epoch = -1)
for epoch in range(EPOCH):
#enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列。例:['A','B','C']->[(0,'A'),(1,'B'),(2,'C')],
#这里是为了将索引传给step输出
for step, (x, y) in enumerate(train_loader):
output = cnn(x)
loss = loss_func(output, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if step % 100 == 0:
#enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列。例:['A','B','C']->[(0,'A'),(1,'B'),(2,'C')]
for (test_x, test_y) in test_loader:
#print(test_y.size())
#在所有数据集上预测精度:
#预测结果 test_output.size() = [10000,10],其中每一列代表预测为每一个数的概率(softmax输出),而不是0或1
test_output = cnn(test_x)
#torch.max()则将预测结果转化对应的预测结果,即概率最大对应的数字:[10000,10]->[10000]
pred_y = torch.max(test_output,1)[1].squeeze() #squeeze()默认是将a中所有为1的维度删掉
#pred_size() = [10000]
accuracy = sum(pred_y == test_y) / test_data.__len__()
print('Eopch:', epoch, ' | train loss: %.6f' % loss.item(), ' | test accracy:%.5f' % accuracy, ' | step: %d' % step)
#为tensorboardX添加可视化日志:
#1.添加训练集损失
# SumWriter.add_scalar("train loss:",loss.item()/20, global_step = 20)
# #计算测试集精度
# test_output = cnn(test_x)
# pred_y = torch.max(test_output,1)[1].squeeze()
# accuracy = sum(pred_y == test_y) / test_data.__len__()
# #2.添加测试集精度
# SumWriter.add_scalar("test accuracy:",accuracy.item(),20)
# #预处理当前batch:
# b_x_im = utils.make_grid(x, nrow = 16)
# #3.添加一个batch图像的可视化
# SumWriter.add_image('train image sample:', b_x_im, 20)
# #4.添加直方图可视化网络参数分布:
# for name, param in cnn.named_parameters():
# SumWriter.add_histogram(name, param.data.numpy(), 20)
#scheduler.step()
#仅保存训练好的参数
torch.save(cnn.state_dict(), 'EMNIST_CNN.pkl')
可视化部分:
import torch
import torch.nn as nn
from torchvision.datasets import ImageFolder
import torchvision.models as models
from torchvision import utils
import torchvision.transforms as T
import torch.utils.data as Data
from PIL import Image
import numpy as np
import torch.optim as optim
import cv2
import matplotlib.pyplot as plt
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.Conv1 = nn.Sequential(
#卷积层1
nn.Conv2d(1, 16, 5, 1, 2),
#激活函数层
nn.ReLU(),
#最大池化层
nn.MaxPool2d(kernel_size = 2)
)
self.Conv2 = nn.Sequential(
#卷积层2
nn.Conv2d(16, 32, 5, 1, 2),
nn.Dropout(p=0.2),
#激活函数层
nn.ReLU(),
#最大池化层
nn.MaxPool2d(kernel_size = 2)
)
#最后接上一个全连接层(将图像变为1维)
#为什么是32*7*7:(1,28,28)->(16,28,28)(conv1)->(16,14,14)(pool1)->(32,14,14)(conv2)->(32,7,7)(pool2)->output
self.Linear = nn.Sequential(
nn.Linear(32*7*7,400),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.Linear(400,80),
nn.ReLU(),
nn.Linear(80,26),
)
def forward(self, input):
input = self.Conv1(input)
input = self.Conv2(input) #view可理解为resize
#input.size() = [100, 32, 7, 7], 100是每批次的数量,32是厚度,图片尺寸为7*7
#当某一维是-1时,会自动计算他的大小(原则是总数据量不变):
input = input.view(input.size(0), -1) #(batch=100, 1568), 最终效果便是将二维图片压缩为一维(数据量不变)
#最后接上一个全连接层,输出为10:[100,1568]*[1568,10]=[100,10]
output = self.Linear(input)
return output
#读取网络框架
cnn = CNN()
#读取权重:
cnn.load_state_dict(torch.load('EMNIST_CNN.pkl'))
#test_x:(10000行1列,每列元素为28*28矩阵)
# 提供自己的数据进行测试:
my_img = plt.imread("Emnist_letters_png/My_jpg/g.jpg")
my_img = my_img[:,:,0] #转换为单通道
my_img = cv2.resize(my_img,(28,28))#转换为28*28尺寸
my_img = torch.from_numpy(my_img)#转换为张量
my_img = torch.unsqueeze(my_img, dim = 0)#添加一个维度
my_img = torch.unsqueeze(my_img, dim = 0)/255. #再添加一个维度并把灰度映射在(0,1之间)
#print(my_img.size())#torch.Size([1, 1, 28, 28])卷积层需要4个维度的输入
#可视化部分:
#输入原图像:
plt.imshow(my_img.squeeze())
plt.show()
#Conv1:
cnt = 1
my_img = cnn.Conv1(my_img)
img = my_img.squeeze()
for i in img.squeeze():
plt.axis('off')
fig = plt.gcf()
fig.set_size_inches(5,5)#输出width*height像素
plt.margins(0,0)
plt.imshow(i.detach().numpy())
plt.subplot(4, 4, cnt)
plt.axis('off')
plt.imshow(i.detach().numpy())
cnt += 1
plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0)
plt.show()
#Conv2:
cnt = 1
my_img = cnn.Conv2(my_img)
img = my_img.squeeze()
for i in img.squeeze():
plt.axis('off')
fig = plt.gcf()
fig.set_size_inches(5,5)#输出width*height像素
plt.margins(0,0)
plt.imshow(i.detach().numpy())
plt.subplot(4, 8, cnt)
plt.axis('off')
plt.imshow(i.detach().numpy())
cnt += 1
#plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0)
plt.show()
#全连接层:
my_img = my_img.view(my_img.size(0), -1)
fig = plt.gcf()
fig.set_size_inches(10000,4)#输出width*height像素
plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0)
plt.margins(0,0)
my_img = cnn.Linear[0](my_img)
plt.subplot(3, 1, 1)
plt.imshow(my_img.detach().numpy())
my_img = cnn.Linear[1](my_img)
my_img = cnn.Linear[2](my_img)
my_img = cnn.Linear[3](my_img)
plt.subplot(3, 1, 2)
plt.imshow(my_img.detach().numpy())
my_img = cnn.Linear[4](my_img)
my_img = cnn.Linear[5](my_img)
plt.subplot(3, 1, 3)
plt.imshow(my_img.detach().numpy())
plt.show()
#输出预测结果:
pred_y = int(torch.max(my_img,1)[1])
#chr()将数字转为对应的的ASCAII字符
print('\npredict character: %c or %c' % (chr(pred_y+65),chr(pred_y+97)))
数据集地址
本篇博客用到的数据集(包含解析后的emnist和chars74k)均已上传至github,若对您有帮助,欢迎点个star:
https://github.com/Scienthusiasts/emnist-chars74k_datasets/tree/master


















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









