







项目所需临时接触qt和cuda编程,仅为个人纪录
典型cuda执行流程
1.分配host内存,并进行数据初始化;
2.分配device内存,并从host将数据拷贝到device上;
3.调用CUDA的核函数在device上完成指定的运算;
4.将device上的运算结果拷贝到host上;
5.释放device和host上分配的内存。
第三步核函数最为重要,kernel是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
例如:

global,host,device的区分
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
device:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
grid,block
kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程。
因此,一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置。如下图:
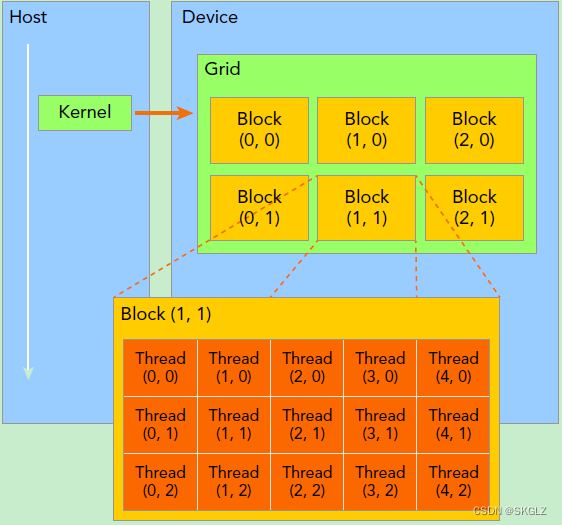
此图中线程Thread(1,1)满足:
threadIdx.x = 1, threadIdx.y = 1
blockIdx.x = 1, blockIdx.y = 1
示例:
// Kernel定义
global void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
…
// Kernel 线程配置
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// kernel调用
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
…
}
CUDA内存模型
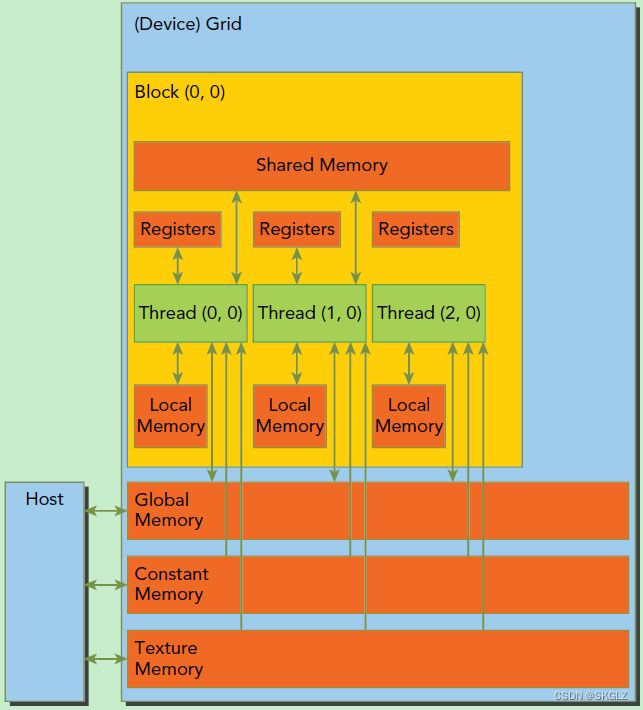
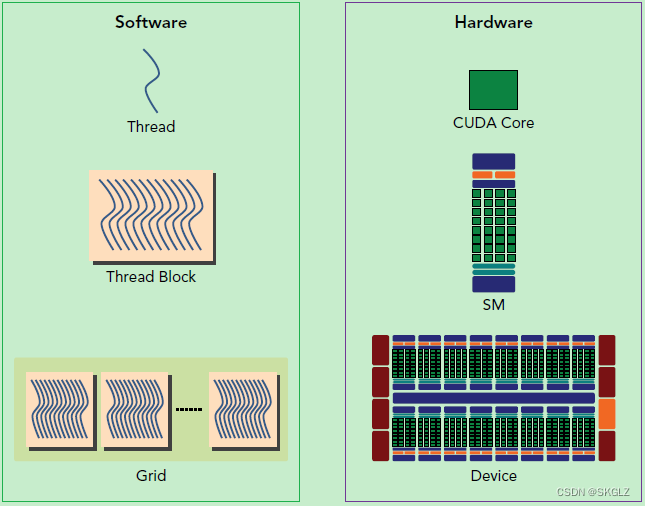
SM(Streaming Multiprocessor)流式多处理器
一个线程块上的线程是放在同一个流式多处理器(SM)上的,但是单个SM的资源有限,这导致线程块中的线程数是有限制的,现代GPUs的线程块可支持的线程数可达1024个。有时候,我们要知道一个线程在blcok中的全局ID,此时就必须还要知道block的组织结构,这是通过线程的内置变量blockDim来获得。
SM的核心组件包括CUDA核心,共享内存,寄存器等,SM可以并发地执行数百个线程,并发能力就取决于SM所拥有的资源数。当一个kernel被执行时,它的gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。SM一般可以调度多个线程块,这要看SM本身的能力。那么有可能一个kernel的各个线程块被分配多个SM,所以grid只是逻辑层,而SM才是执行的物理层。SM采用的是SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(warps),线程束包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。当线程块被划分到某个SM上时,它将进一步划分为多个线程束,因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。这是因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。总之,就是网格和线程块只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的。所以kernel的grid和block的配置不同,性能会出现差异,这点是要特别注意的。还有,由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。
检查GPU硬件配置:
int dev = 0;
cudaDeviceProp devProp;
CHECK(cudaGetDeviceProperties(&devProp, dev));
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "每个EM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个SM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
资料:
https://zhuanlan.zhihu.com/p/34587739
https://www.ssfiction.com/c-cyuyankaifa/560822.html
https://www.coder.work/article/3362342
https://codingchangeworld.com/Cplusplus/ry/detail_article/9761667998882















 3541
3541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









