









理论原理:
在机器学习中,有多种分类算法,每一种分类算法都有各自的优缺点。
为了提高模型的准确度,我们可以将多个分类器组合起来,进行更好的预测,这种组合结果被称为:集成方法或元算法
使用集成方法时有多种形式:可以是不同算法的集成,也可以是同一算法在不同设置下的集成,还可以是数据集不同部分分配给不同分类器之后的集成。
而AdaBoost元算法,就是基于第2种集成形式:同一算法在不同设置下的集成。
AdaBoost元算法是通过集中关注被已有分类器错分的那些数据来获得新的分类器
在AdaBoost元算法中,最重要的就是引入了一个错误代价权重向量D
D为每一个样本分配一个权重值,如Di = 0.5,则表示若第i个样本被错分,那么它的代价就为0.5
我们希望分类器分错的样本的权重值之和最小。
AdaBoost元算法的精妙之处在于,它组合若干个弱分类器(分类效果较差),使其变为一个强分类器(分类效果很好)。
在这里,AdaBoost元算法使用的若分类器为单层决策树,即只能按照某一个属性的某一个阈值,将数据分为两类。
例如下面这个线性不可分的数据集:只沿着坐标轴垂直方向画一条线,是不可能将数据完成正确分开的。接下来,我们就来看看AdaBoost元算法是如何利用弱分类器的组合,将其完美划分的。
AdaBoost元算法为每一个分类器分配了一个权重值alpha:置信度。置信度的值取决于该分类器的错误率:

alpha的计算公式为:
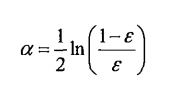
由计算公式可知:
当错误率趋近为0时,alpha趋近与正无穷
当错误率趋近为1时,alpha趋近与负无穷
说明分类越准确,该分类器的结果越重要,置信度越高。
AdaBoost元算法的整体思想是:
1:初始状态时,每个样本的错误代价权重值Di相同
2:根据当前分类器的结果,为了使分错的样本被分对,我们增加错误样本的错误代价权重值,减少正确样本错误代价的权重值,使得后面的分类器更加重视之前被错分的样本。按照下面公式更新D:

3:对于每一个D,我们找出弱分类器的最佳决策方案,并根据错误率计算出该分类器的置信度alpha
4:最后每个样本的分类结果,由各个弱分类器结果乘上alpha的加权值的符号决定,>0分类为类别1,<0分类为类别-1
5:不断的更新D,增加弱分类器的数目,直到整体错误率为0,或到达最大分类器个数上限。
如下图所示:


代码实现:
from numpy import *
#加载数据
def loadSimpleData():
datMat = matrix([[1,2.1],
[2,1.1],
[1.3,1],
[1,1],
[2,1]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat, classLabels
#对于给定的决策属性dimen,根据阈值和大小方向,将数据划分为两内
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
retArr = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArr[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArr[dataMatrix[:,dimen] > threshVal] = -1.0
return retArr
#对于给定的错误权重D,使用单层决策树做决策,
#遍历每一个属性,各个属性给定步长的各个阈值,以及两个大小方向的所以情况进行决策
#记录下错误权重之和最小的决策情况
def buildStump(dataArr, classLabels, D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}
bestClasEst = mat(zeros((m,1)))
minError = inf
for i in range(n): #对于每一个属性
rangeMin = dataMatrix[:,i].min() #该属性的最小值
rangeMax = dataMatrix[:,i].max() #该属性的最大值
stepSize = (rangeMax - rangeMin) / numSteps #阈值改变步长
for j in range(-1,int(numSteps)+1): #对于每一个阈值
for inequal in ['lt', 'gt']: #对于每一个决策方向,左-1有1或左1右-1
threshVal = (rangeMin + float(j)*stepSize) #当前阈值
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal) #对当前的属性,阈值和方向,返回决策结果
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightError = D.T * errArr
print('split: dim {0}, thresh {1}, thesh ineqal {2}, the weighted error is {3}'.format(i,threshVal,inequal,weightError))
#更新,记录对于某一给定的D,最佳的决策方案
if weightError < minError:
minError = weightError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
#训练数据,根据D,找出若干弱分类器,使得累计误差为0
def adaBoostTrainDS(dataArr, classLabels, numIt=40):
weakClassArr = [] #弱分类器数组
m = shape(dataArr)[0]
D = mat(ones((m,1)))/m
aggClassEst = mat(zeros((m,1))) #累计的预测值
for i in range(numIt):
#对于当前的D,找到最佳的决策
bestStump, error, classEst = buildStump(dataArr,classLabels,D)
print('D:{}'.format(D.T))
#求出当前弱分类器的自信度
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
#记录当前弱分类器的自信度
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print('classEst:{0}'.format(classEst.T))
#按照规则,更新D
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon))
D = D / D.sum()
#更新累计预测值
aggClassEst += alpha * classEst
print('aggClassEst:{0}'.format(aggClassEst.T))
#累计预测的错误
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T, ones((m,1)))
errorRate = aggErrors.sum() / m
print('total error:{0}'.format(errorRate))
#若累计错误为0,则退出
if errorRate == 0.0: break
return weakClassArr
def adaClassify(datToClass, classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
print(aggClassEst)
return sign(aggClassEst)
测试:
import AdaBoost
from numpy import *
datMat, classLabels = AdaBoost.loadSimpleData()
D = mat(ones((5,1))/5)
bestStump, minError, bestClasEst=AdaBoost.buildStump(datMat, classLabels, D)
print('minErr:{0}, dim:{1}, thresh:{2}, ineq:{3}'.format(minError,bestStump['dim'],bestStump['thresh'],bestStump['ineq']))
print('bestClasEst:{0}'.format(bestClasEst))
classifierArr = AdaBoost.adaBoostTrainDS(datMat, classLabels, 9)
print('test:')
AdaBoost.adaClassify([0,0], classifierArr)















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









