






Carla简单入门-3 传感器
本文写于2023年7月,文中所展示的版本为Ubuntu20.04以及Carla0.9.14,不同版本可能有一定的不同,欢迎各位伙伴们把遇到的问题和解决办法与其他人分享。
上篇文档中,我们详细了解了Carla中的同步与异步的区别,适用环境以及应用上的细节,在同步模式下解决了我们摄像头卡顿丢帧的问题。现在我们可以根据我们的需求尽情添加摄像头来读取信息而不用担心丢失信息或者影响模拟精度的问题了,所以这期文章我们将深入了解Carla的各种传感器。
1. 传感器综述
Carla对于传感器的定义是可以从周围环境中获取信息的actor,所以我们不难猜到所有传感器也遵循其他actor(类似vehicle)的操作逻辑,也即先获取蓝图设定属性,然后生成。中间的部分细微差别将在下面的部分详细说明。根据Carla的官方文档,Carla中的传感器可以大致分为3类,分别为Camera,detector,other,下面会对每个种类做大致说明:
a. camera
camera会在每次模拟环境更新 world.tick() 时以自身视角对模拟环境拍照进行记录,大部分camera会输出一个 图像carla.Image,用户可以通过helper class carla.ColorConverter来对返回的图像进行后处理。
| 传感器 | 输出 | 概述 |
|---|---|---|
| Depth | carla.Image | 深度相机,将与物体的距离以灰阶形式存储 |
| RGB | carla.Image | 普通相机,输出一张清晰的与肉眼所见相似的图像 |
| Optical Flow | carla.Image | 将画面中每个图像的移动渲染出来 |
| Semantic segmentation | carla.Image | 语义分割相机,将不同种类物体以不同颜色显示 |
| Instance segmentation | carla.Image | 实例分割相机,将不同tag和不同id的物体以不同颜色显示 |
| DVS | carla.DVSEventArray | 动态视觉传感器,作为事件流异步测量亮度强度的变化 |
camera类型的传感器除了DVS传感器外都会直接同步输出图像,而DVS所输出的carla.DVSEventArray也可以通过调用内置方法来转变成为图像。
b. detector
与camera不同,detector不会在每一次模拟环境更新时输出信息,detector只在它所绑定的actor(一般为ehicle)触发特定事件时才会获取信息。
| 传感器 | 输出 | 概述 |
|---|---|---|
| Collision | carla.CollisionEvent | 碰撞检测,当所绑定车辆与其他物体发生碰撞时获取信息 |
| Lane invasion | carla.LaneInvasionEvent | 压线检测,当所绑定车辆压线或者越线时获取信息 |
| Obstacle | carla.ObstacleDetectionEvent | 障碍检测,检测所绑定车辆前方可能会碰撞的障碍物 |
c. other
other类的传感器提供了其他各种各样子不同的功能,例如导航、物理特性测量和场景的2D/3D点云图。other类的传感器和camera类类似,也是在每次模拟环境更新时获取信息。
| Sensor | Output | Overview |
|---|---|---|
| GNSS | carla.GNSSMeasurement | 获取当前车辆的高精度地理位置 |
| IMU | carla.IMUMeasurement | 惯性传感器,测量车辆加速度,陀螺仪等数据 |
| LIDAR | carla.LidarMeasurement | 激光雷达,旋转并生成具有每个点的坐标的4D点云,来对周围环境进行建模. |
| Radar | carla.RadarMeasurement | 雷达,生成2D点云记录视角中的元素和它们的相对运动 |
| RSS | carla.RssResponse | 责任敏感安全传感器,基于安全检查对于车辆控制器进行修改,这个传感器的工作原理与其他的都不一样,可以在链接文档中查阅。 |
| Semantic LIDAR | carla.SemanticLidarMeasurement | 语义分割激光雷达,旋转并生成具有每个点的坐标的3D点云,来对周围环境进行建模,同时提供了对于周边建模的语义分割信息 |
现在Carla所提供的所有传感器类型已经简略介绍完了,接下来我们会对于其中的部分常用传感器进行细致说明。
2. Camera传感器
首先自然是Camera类,这是最直观也是最为常用的传感器类型,下来我们就看一下其中的各个传感器的属性以及设置。
a. RGB Camera
蓝图:sensor.camera.rgb
首先我们来看RGB相机的各种属性设定,Carla提供了非常多的可以设置的属性供我们自定义我们想要的相机效果,我们可以通过调整各种属性来模拟现实中相机在各个不同环境条件下的反应,例如视角,快门速度等。官方文档链接在这里:RGB camera
Carla中RGB相机有着如下的基本设定,一般情况下我们对于基本设定进行调整就能够满足我们对于传感器的自定义要求,注意进行属性设定需要对于生成所用蓝图进行设定,设定属性需要在生成之前,生成后就无法更改属性了。
| 蓝图属性 | 数据类型 | 默认值 | 描述 |
|---|---|---|---|
| bloom_intensity | float | 0.675 | 镜头炫光强度,设置为0.0可以关闭 |
| fov | float | 90.0 | 水平视角,单位:度 |
| fstop | float | 1.4 | 光圈大小,fstop值越小光圈越大,景深越浅,一般情况下最大光圈(即最小fstop值)为1.2 |
| image_size_x | int | 800 | 图像宽度,单位:像素 |
| image_size_y | int | 600 | 图像高度,单位:像素 |
| iso | float | 100.0 | 感光度 |
| gamma | float | 2.2 | 相机目标gamma值 |
| lens_flare_intensity | float | 0.1 | 镜头鬼影强度,设置为0.0可以关闭 |
| sensor_tick | float | 0.0 | 图像采集间隔,单位:tick |
| shutter_speed | float | 200.0 | 快门速度,单位 1/shutter_speed 秒 |
通过在生成RGB相机之前调整相机蓝图中的这些属性,我们可以大致自定义出我们所需要的相机效果,当然,如果有更细节的要求,Carla也提供了高级属性供我们设定:
| 高级蓝图属性 | 数据类型 | 默认值 | 描述 |
|---|---|---|---|
min_fstop | float | 1.2 | 镜头最大光圈 |
blade_count | int | 5 | 光圈叶片数量 |
exposure_mode | str | histogram | 曝光模式,有 manual 和 histogram两种模式,详见 UE4 docs. |
exposure_compensation | float | Linux: +0.75 Windows: 0.0 | 曝光补偿,基于默认曝光亮度进行调整 0没有调整, 负数为更暗,正数为更亮 |
exposure_min_bright | float | 10.0 | 在曝光模式 exposure_mode: "histogram"中使用。设定自动曝光的最小亮度。需要大于0并且小于等于 exposure_max_bright |
exposure_max_bright | float | 12.0 | 在曝光模式 exposure_mode: "histogram"中使用。设定自动曝光的最大亮度。需要大于0并且大于等于 exposure_min_bright |
exposure_speed_up | float | 3.0 | 在曝光模式 exposure_mode: "histogram"中,从暗场景切换到亮场景时自动曝光数值的调整速度 |
exposure_speed_down | float | 1.0 | 在曝光模式 exposure_mode: "histogram"中,从亮场景切换到暗场景时自动曝光数值的调整速度 |
calibration_constant | float | 16.0 | 18% 反射率的校准常数 |
focal_distance | float | 1000.0 | 景深,焦点前后景物清晰的范围,单位:cm (UE units) |
blur_amount | float | 1.0 | 模糊强度 |
blur_radius | float | 0.0 | 1080p分辨率下的模糊半径(单位:像素),根据与相机的距离模拟大气散射 |
motion_blur_intensity | float | 0.45 | 运动模糊强度,范围: [0,1] |
motion_blur_max_distortion | float | 0.35 | 最大扭曲度,因为运动所产生的图像扭曲,单位:屏幕宽度百分比 |
motion_blur_min_object_screen_size | float | 0.1 | 运动模糊应用大小限制,屏幕宽度占比超过设定值的物体将被应用运动模糊 |
slope | float | 0.88 | S曲线斜率,控制影调对比度,更大的斜率增加对比度,也使整体亮度变暗, 范围: [0.0, 1.0] |
toe | float | 0.55 | 黑色调整,范围: [0.0, 1.0] |
shoulder | float | 0.26 | 白色调整: [0.0, 1.0] |
black_clip | float | 0.0 | 黑色上限,不应调整, 范围: [0.0, 1.0] |
white_clip | float | 0.04 | 白色上限,不应调整, 范围: [0.0, 1.0] |
temp | float | 6500.0 | 白平衡调整, 白色: 白平衡设置与环境光一致时 暖色: 当白平衡设置比环境光线高时,整体颜色偏黄 冷色: 当白平衡设置比环境光线低时,整体颜色偏蓝 |
tint | float | 0.0 | 色温调整,调整青色和品红色范围。应该与白平衡Temp属性一起使用,以获得准确的颜色,使相机图像看起来更自然。 |
chromatic_aberration_intensity | float | 0.0 | 色差强度 |
chromatic_aberration_offset | float | 0.0 | 色差偏移,从色差处到画面中心的距离 |
enable_postprocess_effects | bool | True | 后处理效果开启选项 |
以上就是RGB相机的全部属性了,下面我们看一下如何实操:
为了方便演示,我们创建两个RGB相机并且放到同一位置进行对比
# 从蓝图库中寻找rgb相机蓝图
camera_bp_record = world.get_blueprint_library().find('sensor.camera.rgb')
camera_bp_record_1 = world.get_blueprint_library().find('sensor.camera.rgb')
# 设置相机蓝图属性,另一个相机蓝图属性保持默认
camera_bp_record.set_attribute('bloom_intensity','1')
camera_bp_record.set_attribute('fov','120')
camera_bp_record.set_attribute('slope','0.5')
# 设置rgb相机的方位信息
camera_transform_record = carla.Transform(carla.Location(x=0, z=2.4), carla.Rotation(yaw=+00))
# 生成rgb相机并绑定到主车上
camera_record = world.spawn_actor(camera_bp_record, camera_transform_record, attach_to=ego_vehicle)
camera_record_1 = world.spawn_actor(camera_bp_record_1, camera_transform_record, attach_to=ego_vehicle)
# 设定存储摄像头数据的队列
image_queue = queue.Queue()
image_queue_1 = queue.Queue()
# 设定传感器每读取一帧数据后存储到队列中(同步模式)
camera_record.listen(image_queue.put)
camera_record_1.listen(image_queue_1.put)
# 设定数据的存储路径
output_path = os.path.join("/home/ziyu/data/carla_pic", '%06d.png')
output_path_1 = os.path.join("/home/ziyu/data/carla_pic/pic_1", '%06d.png')
while True:
# 从world中获取观察者视角,并将观察者视角的方位信息设置为相机的对应方位信息
world.get_spectator().set_transform(camera.get_transform())
# 如果为同步模式设定
if traffic_manager.synchronous_mode:
# 更新模拟世界
world.tick()
# 从队列中读取传感器图像
image = image_queue.get()
image_1 = image_queue_1.get()
# 将图像存储到本地路径(同步模式)
image.save_to_disk(output_path % image.frame)
image_1.save_to_disk(output_path_1 % image.frame)
# 如果为异步模式设定
else:
# 更新模拟世界
world.wait_for_tick()
大致的相机读取信息并存储的代码如上,下来我们看一下对比演示图:


我们可以很直观的看到无论是视角还是色彩都有了很大的改变,后面伙伴们也可以自己尝试各个不同的属性参数。
b. depth Camera
蓝图:sensor.camera.depth
下来我们直接来看深度相机, 深度相机输出的图像是传感器所捕捉的原始数据,由每个像素到相机的距离编码形成的 (also known as depth buffer or z-buffer) 深度图。深度图编码过程使用R,G,B三个通道来编码每个像素的深度值,从低到高的有效字节:R->G->B, 具体计算公式如下:
normalized = (R + G * 256 + B * 256 * 256) / (256 * 256 * 256 - 1)
in_meters = 1000 * normalized
输出的carla.Image需要使用carla.colorConverter来转换后存储,过程中将RGB通道中的距离转换为代表距离的[0,1]浮点值,最后将其转换为灰度。carla.colorConverter中提供两个深度视图选项: Depth 和 Logaritmic depth。两者的精度都是毫米级的,但对数方法对距离较近的物体效果更好。

深度相机也提供了部分属性供我们调整,这里我直接将所有属性的表格列出来,就不多赘述了。
基本属性:
| 蓝图属性 | 数据类型 | 默认值 | 描述 |
|---|---|---|---|
| image_size_x | int | 800 | 图像宽度,单位:像素 |
| image_size_y | int | 600 | 图像高度,单位:像素 |
| fov | float | 90.0 | 水平视角,单位:度 |
| sensor_tick | float | 0.0 | 图像采集间隔,单位:tick |
镜头畸变属性:
| 蓝图属性 | 数据类型 | 默认值 | 描述 |
|---|---|---|---|
| lens_circle_falloff | float | 5.0 | 范围: [0.0, 10.0] |
| lens_circle_multiplier | float | 0.0 | 范围: [0.0, 10.0] |
| lens_k | float | -1.0 | 范围: [-inf, inf] |
| lens_kcube | float | 0.0 | 范围: [-inf, inf] |
| lens_x_size | float | 0.08 | 范围: [0.0, 1.0] |
| lens_y_size | float | 0.08 | 范围: [0.0, 1.0] |
输出属性:(注意这个为输出数据carla.image的属性,而非传感器属性)
| 传感器数据属性 | 数据类型 | 描述 |
|---|---|---|
frame | int | 传感器获取数据时的帧编号(第几帧时捕捉的画面) |
timestamp | double | 从开始模拟到数据捕捉的模拟时间 |
transform | carla.Transform | 传感器在模拟环境下的位置以及角度 |
width | int | 图像宽度,单位:像素 |
height | int | 图像高度,单位:像素 |
fov | float | 水平视角,单位:度 |
raw_data | bytes | 32位BGRA像素数组 |
以上就是深度相机的全部属性了,下面我们看一下如何实操:
同样为了方便演示,我们创建两个深度相机并且放到同一位置进行对比
# 从蓝图库中寻找深度相机
camera_bp_depth = world.get_blueprint_library().find('sensor.camera.depth')
camera_bp_depth_1 = world.get_blueprint_library().find('sensor.camera.depth')
# 设置深度相机蓝图属性
camera_bp_depth_1.set_attribute('lens_x_size','0.8')
camera_bp_depth_1.set_attribute('lens_y_size','0.8')
camera_bp_depth_1.set_attribute('fov','120')
# 设置相机的方位角
camera_transform_record = carla.Transform(carla.Location(x=0, z=2.4), carla.Rotation(yaw=+00))
# 生成深度相机并绑定到主车上
camera_depth = world.spawn_actor(camera_bp_depth, camera_transform_record, attach_to=ego_vehicle)
camera_depth_1 = world.spawn_actor(camera_bp_depth_1, camera_transform_record, attach_to=ego_vehicle)
# 设定存储摄像头数据的队列
image_queue = queue.Queue()
image_queue_1 = queue.Queue()
# 设定color_converter用于将深度原始数据转成深度图
depth_color_converter = carla.ColorConverter.LogarithmicDepth
# 设定传感器每读取一帧数据后存储到队列中(同步模式)
camera_depth.listen(image_queue.put)
camera_depth_1.listen(image_queue_1.put)
# 设定数据的存储路径
output_path = os.path.join("/home/ziyu/data/carla_pic", '%06d.png')
output_path_1 = os.path.join("/home/ziyu/data/carla_pic/pic_1", '%06d.png')
while True:
# 从world中获取观察者视角,并将观察者视角的方位信息设置为相机的对应方位信息
world.get_spectator().set_transform(camera.get_transform())
# 如果为同步模式设定
if traffic_manager.synchronous_mode:
# 更新模拟世界
world.tick()
# 从队列中读取传感器图像
image = image_queue.get()
image_1 = image_queue_1.get()
# 将图像通过color_converter转化后存储到本地路径(同步模式)
image.save_to_disk(output_path % image.frame, depth_color_converter)
image_1.save_to_disk(output_path_1 % image.frame, depth_color_converter)
# 如果为异步模式设定
else:
# 更新模拟世界
world.wait_for_tick()
可以看到,设置深度相机的流程和设置普通的RGB相机的流程上基本没有差异,主要是相对于普通RGB相机输出可以直接使用或存储的RGB图,深度相机在使用或者存储前需要用color_converter进行转化。
同样,下面附上两种不同相机属性设定的效果对比图:


c. semantic segmentation Camera
蓝图:sensor.camera.semantic_segmentation
在每次模拟开始生成actor时,每个actor会根据所在文件夹的路径获得一个tag,例如通过 Unreal/CarlaUE4/Content/Static/Pedestrians 所生成的actor会获得Pedestrian的tag。之后在模拟运行时,semantic_segmentation相机会根据每个actor的tag来进行分类,每个不同的类会用不同的颜色表示。

Carla的语义分割相机会将tag信息编码到RGB图像的R通道当中,像素的R值就代表了它的tag,这样的图片我们不能直接使用,所以要将语义分割相机的原始数据通过carla.ColorConverter.CityScapesPalette来转换成为常用的语义分割图像
下面附上所有可用tag以及对应颜色的RGB值:
| 编号 | Tag | 转换后对应颜色 | 描述 |
|---|---|---|---|
0 | Unlabeled | (0, 0, 0) | 所有未被分类的元素 |
1 | Building | (70, 70, 70) | 房屋,摩天大楼等建筑以及其附属物品 例如 空调外机等 |
2 | Fence | (100, 40, 40) | 围栏,篱笆等 |
3 | Other | (55, 90, 80) | 其他 |
4 | Pedestrian | (220, 20, 60) | 行人,包括使用交通工具的人 例如 骑自行车,滑板车,马,坐轮椅的人等 |
5 | Pole | (153, 153, 153) | 杆,大多数竖直的小型物体都会被分到这个tag下, 例如交通标志杆,交通信号灯杆 |
6 | RoadLine | (157, 234, 50) | 道路标线 |
7 | Road | (128, 64, 128) | 道路 |
8 | SideWalk | (244, 35, 232) | 人行道,包括路口行人等待区域等 |
9 | Vegetation | (107, 142, 35) | 所有高于地面的植物,如树,灌木等,地表高度的植物一般被分为Terrain类别下 |
10 | Vehicles | (0, 0, 142) | 车辆, 包括轿车, 面包车, 卡车, 摩托车, 自行车, 公交车, 火车等 |
11 | Wall | (102, 102, 156) | 独立的墙,不属于建筑物一部分的墙 |
12 | TrafficSign | (220, 220, 0) | 交通标志牌,与所连接的交通标志杆不为同一物体, 例如,停车标识,方向标识等 |
13 | Sky | (70, 130, 180) | 天空 |
14 | Ground | (81, 0, 81) | 所有处于水平地面上的无法被归于其他类别的物体,例如人行道和车道的交汇区域等 |
15 | Bridge | (150, 100, 100) | 桥,只有桥本身会被归于这个类别,桥上的人车以及护栏等都会被归于自己的类 |
16 | RailTrack | (230, 150, 140) | 铁道,例如 地铁轨道,火车轨道 |
17 | GuardRail | (180, 165, 180) | 任意种类的防撞措施,例如道路护栏等 |
18 | TrafficLight | (250, 170, 30) | 交通信号灯,注意交通信号灯与交通信号灯杆分属两个不同的类别 |
19 | Static | (110, 190, 160) | 无法移动的物体, 例如 消防栓, 公交站, 固定长椅, 公交站等 |
20 | Dynamic | (170, 120, 50) | 可能移动的物体, 例如可移动垃圾桶, 婴儿车, 轮椅,动物等 |
21 | Water | (45, 60, 150) | 水面 |
22 | Terrain | (145, 170, 100) | 沙,土,草地等不能驾驶车辆通过的水平地面 |
除了官方提供好的常用的语义分割种类和tag之外,用户也可以自定义自己的tag,过程比较复杂,受篇幅限制这里就不展开了,感兴趣的可以看官方文档:create semantic tags
语义分割相机所有可以自定义的属性和深度相机也是完全一致的,这里也就不再放了。
语义分割相机在使用上和深度相机也基本一致,只需要将使用carla.ColorConverter转化的步骤稍作调整即可这里就不赘述了,只放图像转化的代码:
# 官方提供的转化代码,在使用时将存储路径改为自己的存储路径即可
raw_image.save_to_disk("path/to/save/converted/image",carla.ColorConverter.cityScapesPalette)
最后我们简单看一下效果对比图:


d. instance segmentation Camera
蓝图:sensor.camera.instance_segmentation
实例分割相机和语义分割相机的工作原理十分相似都是在模拟开始的时候将元素的信息初始化,之后在传感器每次读取信息时将这些物体,元素的信息编码到图像的RGB值中并输出。例如有某个像素的RGB值为 [10, 20, 55],我们就可以判断出这个像素属于一个id为20-55的vehicle(vehicle的tag编号为10)。当然,用户也可以根据自己的需求来选择是否对原始数据进行图像转换,如果不转换,那么就能得到根据元素的unique_id所分割的图像,如果进行转换,我们就会得到一个普通的语义分割图片。
实例分割相机有着和语义分割相机完全相同的属性选项,并且最终通过carla.ColorConverter所转换出的图像的颜色对应tag也是相同的,当然,两者的使用方式也是基本一致的,所以这里直接跳过,来看一下实例分割相机所输出的原始数据图像和转化后的图像的对比,注意原始图像数据中不仅包含元素的tag种类信息,还包含unique_id信息,所以两个相同种类的物体可能会有不同的颜色。


以上是Carla所提供的部分camera传感器的详细深入解析,下来我们进入other类传感器的Lidar部分。这部分内容会相对较少,因为Lidar所输出的数据不能很直观的看到,所以我们的实例程序中不会大量使用Lidar传感器,感兴趣的伙伴们可以下来自行探索,现在我们进入正题。
3. Lidar传感器
作为carla官方划分的other类下的一个重要子集,lidar传感器也有着许多强大的功能,同时Lidar传感器的输出数据类型也与camera完全不同。Lidar大类传感器下有两种传感器,分别是ray_cast和ray_cast_semantic,下面就对两个不同的传感器进行详细介绍:
a. LIDAR sensor
Lidar sensor通过UE4引擎中的ray-casting模拟了一个旋转的激光雷达,传感器会根据设定的通道数(channel)为每个通道添加一条射线并且计算每条射线的旋转角度来模拟出旋转的激光雷达,通过每一次步都对每个射线进行ray-cast计算,最后传感器会得到一份点云图。
Lidar传感器会每步输出一个 carla.LidarMeasurement数据,这个数据中包含一个存储了在1/FPS秒钟所有生成的点的信息的包,我们也可以将这个包含点的信息的包以list形式输出出来:
for location in lidar_measurement:
print(location)
前文提到,Lidar传感器会输出一个4D点云图,其中的前3D自然是x,y,z坐标,而第四个属性是激光密度,强度(intensity),这个属性值由下面的公式计算得来:

其中
a:为衰减系数。这可能取决于激光雷达的激光波长和大气条件。它可以使用激光雷达属性atmosphere_attention_re_rate进行修改。
d:为从传感器到点的距离。
为了模拟更加真实的激光雷达传感器,点云中的点会丢失,减少(drop off)以模拟现实中的外部扰动,点的drop off总共由两部分组成,一部分是基础 General drop off,另一种是基于intensity的 Instensity-based drop-off。
General drop off可以通过设定 dropoff_general_rate 来更改drop off比例,Instensity-based drop-off 可以通过更改上下限: dropoff_zero_intensity 和 dropoff_intensity_limit 来更改drop off的比例。
除此之外,激光雷达还可以向输出结果中加入噪声来模拟真实的场景以使模拟仿真更加接近现实。
下面我们看看激光雷达所提供的各种属性:
激光雷达属性
| 蓝图属性 | 数据类型 | 默认值 | 描述 |
|---|---|---|---|
channels | int | 32 | 激光射线数量 |
range | float | 10.0 | 激光雷达最大探测距离,单位:米 (CARLA 0.9.6或更早版本单位为厘米). |
points_per_second | int | 56000 | 每秒所有激光所产生的点的数量 |
rotation_frequency | float | 10.0 | 激光雷达转动速率 |
upper_fov | float | 10.0 | 最上方激光的角度,单位:度 |
lower_fov | float | -30.0 | 最下方激光的角度,单位:度 |
horizontal_fov | float | 360.0 | 水平范围激光雷达检测范围,单位:度 |
atmosphere_attenuation_rate | float | 0.004 | 激光雷达衰减常数,控制每米的intensity loss |
dropoff_general_rate | float | 0.45 | 基础drop off率 |
dropoff_intensity_limit | float | 0.8 | Instensity-based drop-off 上限 |
dropoff_zero_intensity | float | 0.4 | Instensity-based drop-off 下限 |
sensor_tick | float | 0.0 | 传感器更新速率, 单位:ticks |
noise_stddev | float | 0.0 | 噪声添加标准差 |
输出数据属性
| 传感器数据属性 | 数据类型 | 描述 |
|---|---|---|
| frame | int | 传感器获取数据时的帧编号(第几帧时捕捉的画面) |
| timestamp | double | 从开始模拟到数据捕捉的模拟时间 |
| transform | carla.Transform | 传感器在模拟环境下的位置以及角度 |
| width | int | 图像宽度,单位:像素 |
| height | int | 图像高度,单位:像素 |
| fov | float | 水平视角,单位:度 |
| raw_data | bytes | 32位BGRA像素数组 |
| 传感器数据属性 | 数据类型 | 描述 |
|---|---|---|
frame | int | 传感器获取数据时的帧编号(第几帧时捕捉的画面) |
timestamp | double | 从开始模拟到数据捕捉的模拟时间 |
transform | carla.Transform | 传感器在模拟环境下的位置以及角度 |
horizontal_angle | float | 当前帧激光雷达所在平面角度 |
channels | int | 通道数,激光数 |
get_point_count(channel) | int | 当前帧输入通道中点的数量 |
raw_data | bytes | 32bits 浮点数,存储每个点的X,Y,Z值等 |
激光雷达传感器所输出的数据是.ply文件,可以直接导入到meshlab中进行查看。在Ubuntu上进行meshlab的安装也很简单:
sudo apt-get install meshlab
之后我们就可以打开存储到本地的点云图查看了:
meshlab XXX.ply

了解完大致流程之后我们来看下实战代码,当然Lidar传感器在生成的大致流程上和其他的传感器没有什么区别,具体的细节区别就详见代码吧:
# 从蓝图库中寻找Lidar的蓝图
lidar_bp = world.get_blueprint_library().find('sensor.lidar.ray_cast')
lidar_bp_1 = world.get_blueprint_library().find('sensor.lidar.ray_cast')
# 设置Lidar蓝图属性
lidar_bp_1.set_attribute('channels', '64')
lidar_bp_1.set_attribute('points_per_second', '560000')
lidar_bp_1.set_attribute('upper_fov', '30')
lidar_bp_1.set_attribute('dropoff_general_rate', '0.3')
# 设置相机的方位角
camera_transform_record = carla.Transform(carla.Location(x=0, z=2.4), carla.Rotation(yaw=+00))
# 生成lidar并绑定到主车上
lidar = world.spawn_actor(lidar_bp, camera_transform_record, attach_to=ego_vehicle)
lidar_1 = world.spawn_actor(lidar_bp_1, camera_transform_record, attach_to=ego_vehicle)
# 设定传感器每读取一步数据后存储到队列中(同步模式)
lidar.listen(lidar_measurement_queue.put)
lidar_1.listen(lidar_measurement_queue_1.put)
# 设定数据的存储路径
output_path_lidar = os.path.join("/home/ziyu/data/carla_pic", '%06d.ply')
output_path_lidar_1 = os.path.join("/home/ziyu/data/carla_pic/pic_1", '%06d.ply')
while True:
# 从world中获取观察者视角,并将观察者视角的方位信息设置为相机的对应方位信息
world.get_spectator().set_transform(camera.get_transform())
# 如果为同步模式设定
if traffic_manager.synchronous_mode:
# 更新模拟世界
world.tick()
# 从队列中读取激光雷达数据
measurement = lidar_measurement_queue.get()
measurement_1 = lidar_measurement_queue_1.get()
# 将激光雷达数据存储到本地路径(同步模式)
measurement.save_to_disk(output_path_lidar % measurement.frame)
measurement_1.save_to_disk(output_path_lidar_1 % measurement_1.frame)
# 如果为异步模式设定
else:
# 更新模拟世界
world.wait_for_tick()
下面展示一下调整属性过后与默认属性的点云差别:图一为调整属性后的点云
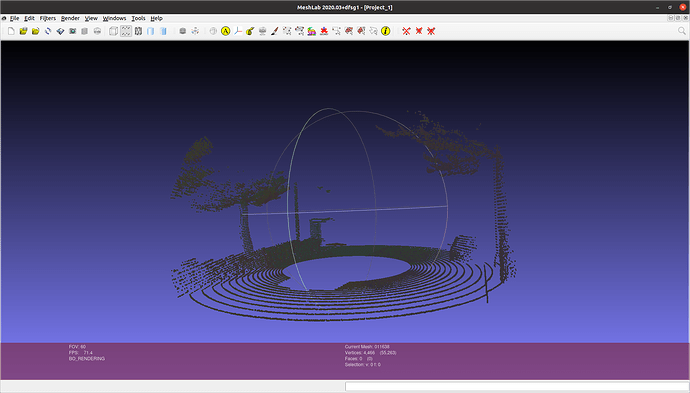
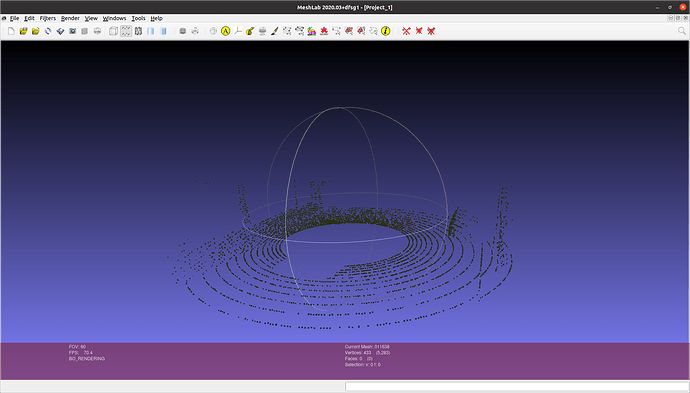
b. Semantic LIDAR sensor
最后我们来简单看一下Semantic LIDAR sensor,正如这个传感器的名字一样,这个传感器和普通的激光雷达相比就是增加了语义分割的信息,减少了模拟现实部分的点的drop off和噪声设置,Semantic LIDAR sensor的属性简单如图:
| 蓝图属性 | 数据类型 | 默认值 | 描述 |
|---|---|---|---|
| channels | int | 32 | 激光射线数量 |
| range | float | 10.0 | 激光雷达最大探测距离,单位:米 (CARLA 0.9.6或更早版本单位为厘米). |
| points_per_second | int | 56000 | 每秒所有激光所产生的点的数量 |
| rotation_frequency | float | 10.0 | 激光雷达转动速率 |
| upper_fov | float | 10.0 | 最上方激光的角度,单位:度 |
| lower_fov | float | -30.0 | 最下方激光的角度,单位:度 |
| horizontal_fov | float | 360.0 | 水平范围激光雷达检测范围,单位:度 |
| sensor_tick | float | 0.0 | 传感器更新速率, 单位:ticks |
同样,Semantic LIDAR sensor的代码和普通激光雷达没有区别,这里也就不多赘述了。
4.后话:
受篇幅限制,传感器部分就先讲到这里,因为这次传感器介绍的代码都有很强的独立性,这里就不放完整代码了,需要伙伴们在上文代码块中代码的基础上自行修改尝试。
参考文档:
Carla的官方文档写的非常详细和完善,英语能力强的伙伴们一定要活用Cltr+f,很多问题都能在其中找到答案。另外,笔者也在积极学习Carla当中,如果文章有错处希望大家指出,有好的观点以及Carla的经验也都十分欢迎分享,让我们一起共同学习进步,共勉!















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









