







原网页引自:A Practical Introduction to Deep Learning with Caffe and Python
0.Introduction
这是一篇使用CNN进行分类的文章,数据集取自Kaggle-dog-cat。博客内容分为两部分:一、深度学习下的部分核心概念;二、实践教程。
实践教程也分为两部分:一、Section4部分,对数据从头学习CNN网络进行猫和狗的分类。二、Section5部分,我们将使用迁移学习,来训练神经网络。
看完这篇文章,你将会收获以下内容:一、理解卷积神经网络是怎么工作的。二、熟悉构建这些网络的步骤和代码。这项实践的代码将给在github上。
1.问题
数据集取自Kaggle,其中有25000张猫和狗的照片,我们的目标是实现一个机器学习算法能够识别一张图片中的正确的动物(猫还是狗)。

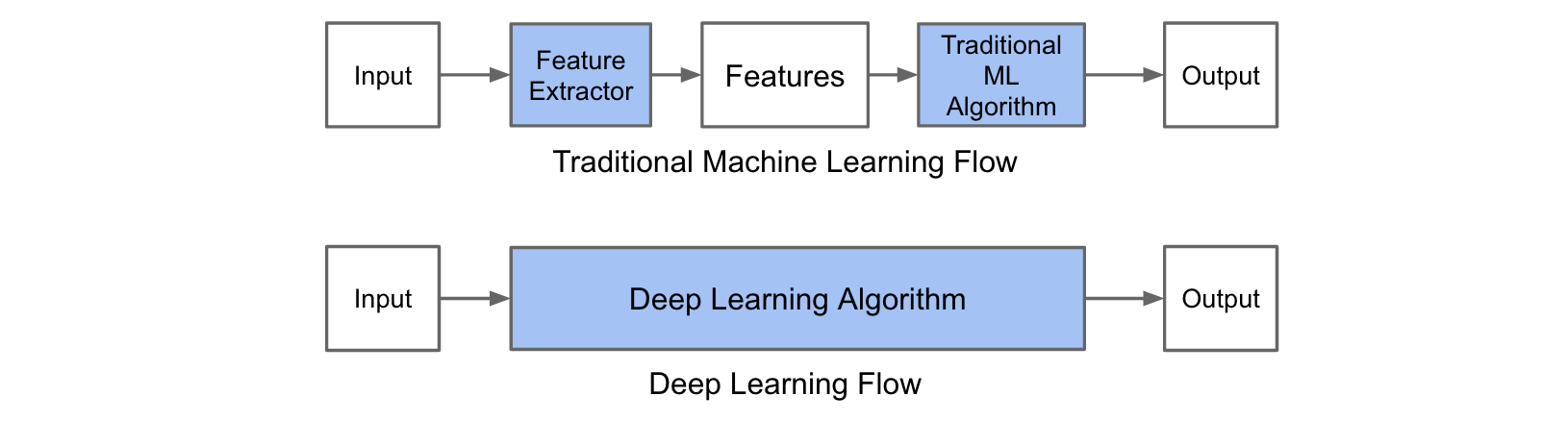
2.传统机器学习算法和深度学习在分类问题上的区别
机器学习算法进行分类有两个步骤:
1.训练阶段。使用一个数据集,包括大量照片及其对应的类别标签。
2.预测阶段。用没使用过的图片检验我们训练出来的模型。
在第一个训练阶段,对于图像分类包括两个过程:
(1)特征提取。这个过程需要我们用领域相关的知识,提取出机器学习算法所需要的特征。HOG和SIFT是两个图像分类领域常用的特征。
(2)模型训练。用上一过程提取出来的特征加上其对应的标签,训练出模型。
在第二个预测阶段,我们用上一阶段得出的特征提取器处理新图片,再把特征传给模型获取最终的预测结果。

传统机器学习算法和深度学习算法的区别在于特征提取这个过程。在传统的机器学习算法中,我们需要事先人为地定义一些特征,而在深度学习中,特征是由算法本身得到的。特征的定义并不容易,需要专家知识,又耗时间,所以相比之下,深度学习算法就有优势。
3.深度学习的简要教程
深度学习是ANNs的一类,因为处理层数多,故称深度学习。ANN在很多年以前就出现了,但是直到Hinton之前一直没有能训练得很深。除了算法创新,GPU的运算能力以及大型数据集的出现也都是深度学习发展的重要因素。
3.1ANNs
人工神经网络是受生物学灵感而生的。
神经细胞是人脑中的重要组件。一个神经细胞由胞体,树突,轴突组成。通过发射电信号和其他神经细胞交互。每一个神经细胞从树突接收信息,然后从轴突发射信息。最后树突接收信号给到目标神经元的胞体时,它会进行总结,如果信号量超过阈值,这个神经细胞将会被激活。
人工神经网络受神经细胞的触动,形成了一个计算模型,有限个输入和权重,一个激活函数,神经元的输出是输入与权重经过激活函数加工后的结果。
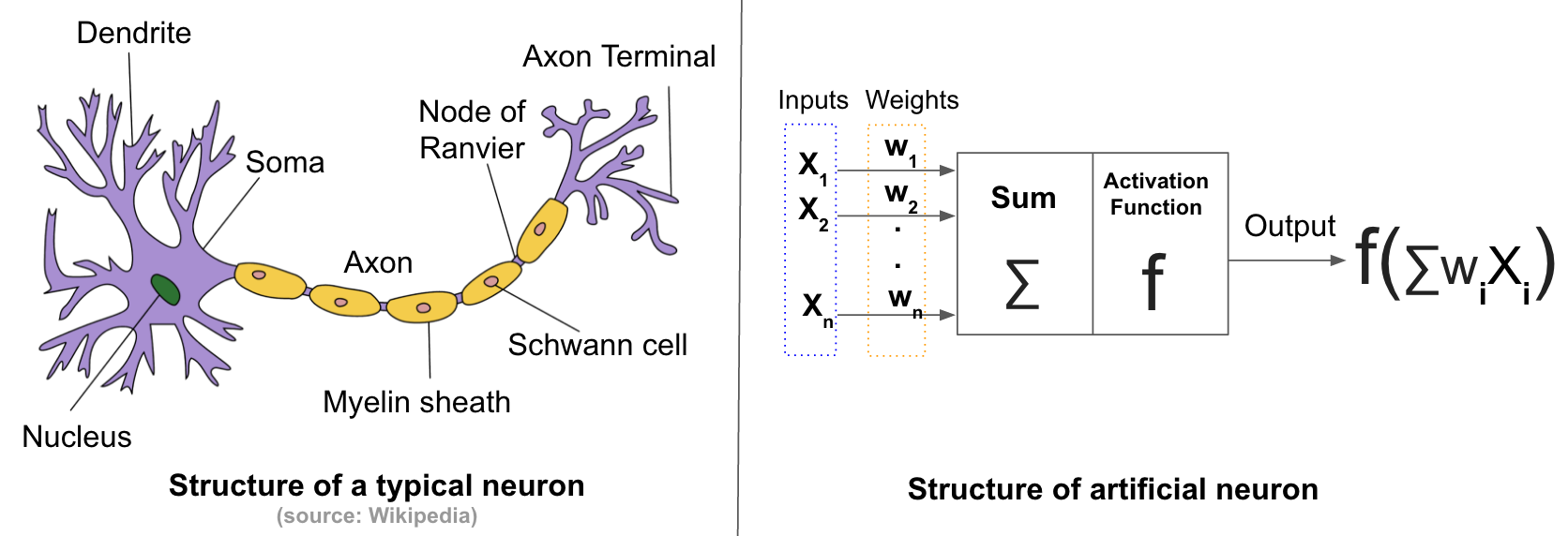
前馈神经网络
人工神经网络的最简单的一种形式。有三部分:输入层,隐藏层,输出层。全连接意味着每个节点都能和下一层的所有节点相连接。

激活函数
激活函数一般是非线性的,这样可以编码比较复杂的数据模式。最受欢迎的激活函数有Sigmoid,tanh,ReLU等。其中ReLU是最受欢迎的一个。

训练人工神经网络
训练阶段的目的是学习网络的权值。训练过程需要两个元素:
1. 训练数据。在图像分类领域,数据就是图片及其对应标签。
2. 损失函数。可以用来标识预测的不准确度。
然后,我们可以用反向传播算法加上梯度下降进行优化,就可以训练出一个人工神经网络了。
3.2 卷积神经网络
卷积神经网络是一种特别的前馈网络。它的作用是用来仿真人视觉皮层的动作。卷积神经网络表现很好,其中有卷积层和池化层允许网络能处理一些特定的图片属性。

卷积层
这一层由可学习的过滤器组成,我们滑动过滤器处理图像,计算过滤器和输入图像的点积。过滤器需要和输入的图像深度一致,如果输入一个彩色图像,有RGB三个通道,那么过滤器也要拥有三维深度。当过滤器遇到和其定义的结构相同的时候,将会激活。

池化层
池化就是一种非线性的下采样。目的是为了减少图像表示的规模,从而减少参数的数量以及网络中的计算复杂程度,从而得以控制过拟合程度。有几种不同的池化方法,比如最大池化,平均池化等,最大池化是最受欢迎的池化方式。池化过滤器通常使用2×2,跨幅为2的大小,分别应用在图像的每一个深度切片。刚刚提到的这种池化过滤器能把一个图片缩小至原图大小的1/4。

CNN架构
一种简单的架构包括,一连串的卷积层和池化层,最后加上全连接层。其中,卷积层后面通常会放一个ReLU激活函数。
卷积层,池化层以及ReLU激活函数可以看做机器学习的可学习特征提取器,而全连接层可以看成一个分类器。另外,神经网络结构的前几层可以看做图片的通用模式的编码器,而后几层可以看做图片的细节模式的编码器。
注意到卷积层和全连接层有权重属性,这是可以在训练阶段学习的。

4.使用CNN构建猫狗分类器
这一部分,我们将使用Caffe框架和部分python代码,通过Kaggle的数据集,实现一个猫狗分类器。
4.1 获取猫狗数据
从dataset获取猫狗数据,其中train.zip中包含图片及其对应标签,是用来训练的,test1.zip中只有图片没有标签,是用来进行预测的。在程序完成后,我们将在Kaggle上上传自己的成绩。
4.2 机器设置
首先,需要在Ubuntu系统上设置好Caffe和Anaconda,然后从github上下载仓库,其中包含Caffe的配置文件以及一些python代码。
git clone https://github.com/adilmoujahid/deeplearning-cats-dogs-tutorial.git接下来,我们新建一个input文件夹,存储训练图片与测试图片。
cd deeplearning-cats-dogs-tutorial
mkdir input4.3 Caffe概述
Caffe是一个深度学习框架。使用Caffe来构建一个CNN需要以下四步:
Step-1:准备数据。我们需要把图片转换成Caffe可以识别并使用的格式。
Step-2:模型定义。选择一个CNN架构,然后在一个后缀文件是 .prototxt . p r o t o t x t 的配置文件中定义Solver的参数。solver是Caffe的核心,用于协调模型的运作
Step-3:定义Solver。Solver负责模型优化。
Step-4:模型训练。在terminal中执行caffe命令来训练模型。训练完以后,我们得到后缀为 .caffemodel . c a f f e m o d e l 的模型文件。
训练完成后,我们用 .caffemodel . c a f f e m o d e l 的模型文件对新图片进行预测。
4.4 数据准备
把train.zip和test1.zip复制到input文件夹
unzip ~/deeplearning-cats-dogs-tutorial/input/train.zip
unzip ~/deeplearning-cats-dogs-tutorial/input/test1.zip
rm ~/deeplearning-cats-dogs-tutorial/input/*.zip然后运行create_lmdb.py
cd ~/deeplearning-cats-dogs-tutorial/code
python create_lmdb.pycreate_lmdb.py 做了这些事:
在训练的图片上使用直方图均衡化。直方图均衡化是一种调整图像对比度的技术
把所有图片调整为227×227的大小
把训练数据分成两个集合。5/6的训练集和1/6的验证集。训练集用来训练模型,验证集用来计算模型的准确程度。
把训练集合和测试集合存储为两个LMDB数据库,train_lmdb 用来训练模型,validation_lmbd 用来模型评估。

生成训练数据的平均图像
执行下面指令生成平均图。在有监督机器学习中,把每张input图减去平均图来确保特征像素的均值为0,是一种常见的预处理方式。
/home/ubuntu/caffe/build/tools/compute_image_mean -backend=lmdb /home/ubuntu/deeplearning-cats-dogs-tutorial/input/train_lmdb /home/ubuntu/deeplearning-cats-dogs-tutorial/input/mean.binaryproto
ps:有谁直到代码块怎么自动换行吗= =,请给我留言,谢谢啦4.4 模型定义
决定用哪个CNN架构以后,我们把它的参数写到
.prototxt
.
p
r
o
t
o
t
x
t
文件中。Caffe实现了很多受欢迎的CNN架构,比如AlexNet和GoogleNet。在这篇博客中,我们就用bvlc_reference_caffenet —这是一个AlexNet的实现,不过做了一些微小的改动。在deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/ 中有该
.prototxt
.
p
r
o
t
o
t
x
t
文件的copy。
我们现在需要对原始的prototxt文件进行一些改动:
在24,40,51行,分别把input数据和mean_image的路径需要改
在373行,需要把输出的1000类改成现在需要的2类。
通过下面的命令,打印出模型架构。模型架构会被存在 deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/caffe_model_1.png
python /home/ubuntu/caffe/python/draw_net.py /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/caffenet_train_val_1.prototxt /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/caffe_model_1.png
4.5 Solver定义
在deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/ 路径中,有solver_1.prototxt文件,我们在其中定义solver的参数。
solver每隔1000轮迭代用验证集计算当前模型的准确率。这个优化过程最多运行40000次迭代,每隔5000次就会对当前训练出的模型记录下来。
base_lr, lr_policy, gamma, momentum 和 weight_decay是我们为了使模型良好收敛而进行微调的超参数。
这里使用:lr_policy: “step” with stepsize: 2500, base_lr: 0.001 and gamma: 0.1.
这个配置中,学习率为0.001,然后每2500次迭代我们将把学习率下调为原来的1/10。
当然针对优化过程,有不同的策略。详细可以看Caffe的solver文档
4.6 模型训练
现在我们定义好了模型和solver,就要开始训练模型啦,命令如下:
/home/ubuntu/caffe/build/tools/caffe train --solver /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/solver_1.prototxt 2>&1 | tee /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/model_1_train.log训练的日志文件存在 deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/model_1_train.log.
绘制学习曲线
python /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/code/plot_learning_curve.py /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_models/caffe_model_1/model_1_train.log /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_models/caffe_model_1/caffe_model_1_learning_curve.png4.7 预测新数据
运行deeplearning-cats-dogs-tutorial/code/make_predictions_1.py,它需要四个文件:
测试文件:用test文件中的图片
平均图:mean_image,4.4节得到的
模型架构文件:deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/caffenet_deploy_1.prototxt,它在caffenet_train_val_1.prototxt文件的基础上做了一些小的改动。我们要删掉数据层,加上输入层,然后把最后一层的分类器从 SoftmaxWithLoss改成Softmax。
模型的权重:在训练阶段得到的,caffe_model_1_iter_10000.caffemodel
用这段命令执行训练:
cd /home/ubuntu/deeplearning-cats-dogs-tutorial/code
python make_predictions_1.py训练结果保存在deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/submission_model_1.csv
该py代码重点如下:
#Read mean image
mean_blob = caffe_pb2.BlobProto()
with open('/home/ubuntu/deeplearning-cats-dogs-tutorial/input/mean.binaryproto') as f:
mean_blob.ParseFromString(f.read())
mean_array = np.asarray(mean_blob.data, dtype=np.float32).reshape(
(mean_blob.channels, mean_blob.height, mean_blob.width))
#Read model architecture and trained model's weights
net = caffe.Net('/home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/caffenet_deploy_1.prototxt',
'/home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_1/caffe_model_1_iter_10000.caffemodel',
caffe.TEST)
#Define image transformers
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_mean('data', mean_array)
transformer.set_transpose('data', (2,0,1))其中,mean_array表示平均图,net 表示从deploy文件中读取的模型。
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = transform_img(img, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT)
net.blobs['data'].data[...] = transformer.preprocess('data', img)
out = net.forward()
pred_probas = out['prob']
print pred_probas.argmax()训练,计算每一类的概率,打印出概率最大的一类。
5.用迁移学习来构建分类器
迁移学习是一种偏实践而且非常有效地技术。
5.1 什么是迁移学习
如果每次都从头训练网络,会花费很长的时间,而且效果并不一定很好。迁移学习利用其它数据集训练出的模型,把它适应于我们所要解决的问题。
迁移学习有两种策略:
(1)把模型当做一个固定的特征提取器:我们只需要移掉最后一层,把前面的层中参数固定住,在前面层的输出训练一个分类器就够了。
(2)微调模型:我们用反向传播算法,在新的数据集上微调模型。我们可以选择微调整个网络,或者是固定住其中部分层。
迁移学习的细节可以看cs231n的相关笔记。
5.2 用迁移学习训练猫狗分类器
Caffe有一个仓库,会存放一些研究者训练出的模型,称为Model Zoo。
我们用一个在ImageNet数据集上训练过的模型进行微调,bvlc_reference_caffenet。
首先,得先下载模型文件
cd /home/ubuntu/caffe/models/bvlc_reference_caffenet
wget http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel它已经被放在了deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_2。然后我们需要对它改动一小部分。
在24,40,51行上需要改输入数据和平均图的存放路径
在360,363,387和397行上改动全连接层最后一层的名字,从fc8改成fc8-cats-dogs
把输出层从1000个改成2个。在373行
现在,如果不改层名的话,程序会从模型中读取权重信息。如果想固定某些层,需要把lr_mult参数设成0
ps:只有卷积层和全连接层有lr_mult参数
Solver定义
同4.5
迁移学习的模型训练
我们需要把权重参数传给模型,这要用一个参数:–weights
/home/ubuntu/caffe/build/tools/caffe train --solver=/home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_2/solver_2.prototxt --weights /home/ubuntu/caffe/models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel 2>&1 | tee /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_2/model_2_train.log画学习曲线
python /home/ubuntu/deeplearning-cats-dogs-tutorial/code/plot_learning_curve.py /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_2/model_2_train.log /home/ubuntu/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_2/caffe_model_2_learning_curve.png新数据上的预测
要用deeplearning-cats-dogs-tutorial/code/make_predictions_2.py
结论
这篇博客主要介绍了深度学习和卷积神经网络的概念,也学习了用caffe分别从头训练和迁移学习的过程。如果要进一步了解,见斯坦福课程cs231n。
纯手工翻译,若有不当之处欢迎指正,转载请注明出处。















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









