






多任务介绍
多任务的优势:充分利用CPU资源,提高程序执行效率
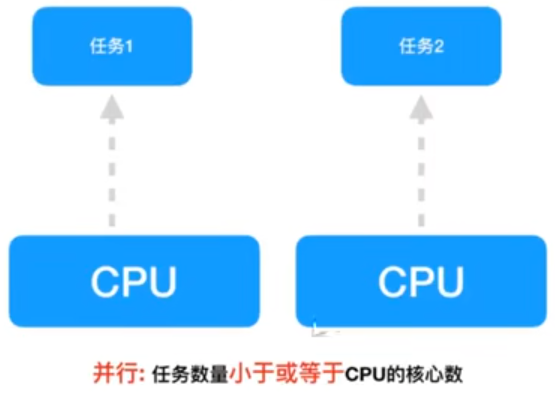
多任务的两种表现形式:并发 并行
并发:在一段时间内交替去执行多个任务
例子:对于单核cpu处理多任务,操作系统轮流让各个任务交替执行。

并行:
在一段时间内真正的同时一起执行多个任务。
例子:
对于多核cpu处理多任务,操作系统会给cpu的每个内核安排一个执行的任务, 多个内核是真正的一起同时执行多个任务。这里需要注意多核cpu是并行的执行多任务,始终有多个任务一起执行。
进程的介绍
进程的概念:
进程(Process) 是资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位,通俗理解: 一个正在运行的程序就是一个进程.例如:正在运行的qq ,微信等他们都是一个进程.
注意:一个程序运行至少有一个程序
进程创建的步骤
- 导入进程包
import multiprocessing - 通过进程类创建进程对象
进程对象=multiprocessing.Process(target=任务名) - 启动进程执行任务
进程对象.start()
通过进程类创建进程对象
进程对象=multiprocessing.Process(target=任务名)
| 参数名 | 说明 |
|---|---|
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 进程名,一般不用设置 |
| group | 进程组,目前只能使用None |
import time
import multiprocessing
def sing():
for i in range(3):
print('唱歌...')
time.sleep(0.5)
def dance():
for i in range(3):
print('跳舞...')
time.sleep(0.5)
if __name__ == '__main__':
sing_process=multiprocessing.Process(target=sing)
dance_process=multiprocessing.Process(target=dance)
sing_process.start()
dance_process.start()
进程执行带有参数的任务
| 参数名 | 说明 | 注意事项 |
|---|---|---|
| args | 以元组的方式给执行任务传参 | 元组的元素顺序就是任务的参数顺序 |
| kwargs | 以字典方式给执行任务传参 | key名就是参数的名字 |
import time
import multiprocessing
def sing(num,name):
for i in range(num):
print(name+'唱歌...')
time.sleep(0.5)
def dance(num,name):
for i in range(num):
print(name+'跳舞...')
time.sleep(0.5)
if __name__ == '__main__':
sing_process=multiprocessing.Process(target=sing,args=(3,"土拨鼠"))
dance_process=multiprocessing.Process(target=dance,kwargs={"num":2,"name":"渣渣猫"})
sing_process.start()
dance_process.start()
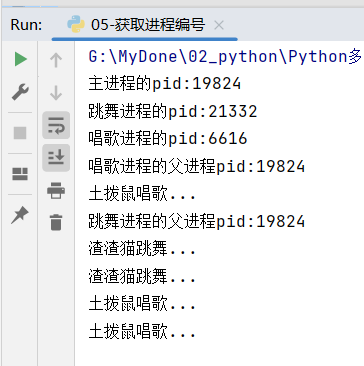
获取进程编号
获取进程编号的两种方式:
1、获取当前进程编号 os.getpid()
2、获取当前父进程编号 os.getppid()
import time
import multiprocessing
import os
def sing(num,name):
print(f"唱歌进程的pid:{os.getpid()}")
print(f"唱歌进程的父进程pid:{os.getppid()}")
for i in range(num):
print(name+'唱歌...')
time.sleep(0.5)
def dance(num,name):
print(f"跳舞进程的pid:{os.getpid()}")
print(f"跳舞进程的父进程pid:{os.getppid()}")
for i in range(num):
print(name+'跳舞...')
time.sleep(0.5)
if __name__ == '__main__':
print(f"主进程的pid:{os.getpid()}")
sing_process=multiprocessing.Process(target=sing,args=(3,"土拨鼠"))
dance_process=multiprocessing.Process(target=dance,kwargs={"num":2,"name":"渣渣猫"})
sing_process.start()
dance_process.start()
进程的注意点
1、主进程会等待所有子进程执行结束后再结束
import multiprocessing
import time
def dowork():
for i in range(10):
print(f'子进程{i}工作中....')
time.sleep(0.2)
if __name__ == '__main__':
work_process = multiprocessing.Process(target=dowork)
work_process.start()
time.sleep(1)
print('主进程执行完啦...')

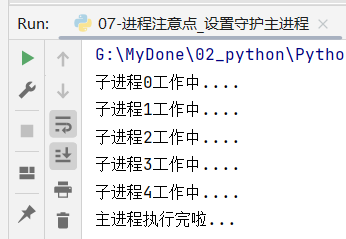
2、设置守护主进程
主进程退出后子进程直接销毁,不再执行子进程中的代码
import multiprocessing
import time
def dowork():
for i in range(10):
print(f'子进程{i}工作中....')
time.sleep(0.2)
if __name__ == '__main__':
work_process = multiprocessing.Process(target=dowork)
work_process.daemon = True # 设置守护主进程
work_process.start()
time.sleep(1)
print('主进程执行完啦...')
案例-文件夹高并发拷贝器
import multiprocessing
import os
def copy_file(file_name, source_dir, dest_dir):
# 1、拼接源文件路径和目标文件路径
source_path = os.path.join(source_dir,file_name)
dest_path=os.path.join(dest_dir,file_name)
# 2.打开源文件和目标文件
with open(source_path,'rb') as source_file:
with open(dest_path,'wb') as dest_file:
# 3.循环读取源文件到目标路径
while True:
data = source_file.read(1024)
if data:
dest_file.write(data)
else:
break
if __name__ == '__main__':
# 1.定义源文件夹和目标文件夹
source_dir = 'E:\\source_dir'
dest_dir = 'F:\\文档'
# 2、创建目标文件夹
try:
os.mkdir(dest_dir)
except:
print('目标文件夹已存在,未创建')
# 3.读取源文件夹的文件列表
file_list = os.listdir(source_dir)
# 4、遍历文件列表实现拷贝
for file_name in file_list:
# copy_file(file_name, source_dir, dest_dir)
# 5、使用多进程实现多任务
sub_process=multiprocessing.Process(target=copy_file,args=(file_name, source_dir, dest_dir))
sub_process.start()
线程的介绍
为什么使用多线程
进程是分配资源的最小单位, 一旦创建一个进程就会分配一-定的资源,就像跟两个人聊QQ就需要打开两个QQ软件一样是比较浪费资源的 .
线程是程序执行的最小单位,实际上进程只负责分配资源,而利用这些资源执行程序的是线程,也就说进程是线程的容器,一个进程中最少有一个线程来负责执行程序.同时线程自己不拥有系统资源,只需要一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程==共享进程所拥有的全部资源 ==。这就像通过一个QQ软件(一 个进程)打开两个窗口(两个线程)跟两个人聊天一样,实现多任务的同时也节省了资源.
线程的创建步骤
1、导入线程模块 import threading
2、通过线程类创建线程对象 线程对象=threading.Thread(target=任务名)
3、启动线程执行任务 线程对象.start()
通过线程类创建线程对象
线程对象=threading.Thread(target=任务名)
| 参数名 | 说明 |
|---|---|
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 线程名,一般不用设置 |
| group | 线程组,目前只能使用None |
import time
import threading
def sing():
for i in range(3):
print('唱歌...')
time.sleep(0.5)
def dance():
for i in range(3):
print('跳舞...')
time.sleep(0.5)
if __name__ == '__main__':
sing_process = threading.Thread(target=sing)
dance_process = threading.Thread(target=dance)
sing_process.start()
dance_process.start()
线程执行带有参数的任务
| 参数名 | 说明 | 注意事项 |
|---|---|---|
| args | 以元组的方式给执行任务传参 | 元组方式传参一定要和参数的顺序保持一致 |
| kwargs | 以字典方式给执行任务传参 | 字典方式传参字典中的Key一定要和参数名保持一致 |
import time
import threading
def sing(num,name):
for i in range(num):
print(name+'唱歌...')
time.sleep(0.5)
def dance(num,name):
for i in range(num):
print(name+'跳舞...')
time.sleep(0.5)
if __name__ == '__main__':
sing_process=threading.Thread(target=sing,args=(3,"土拨鼠"))
dance_process=threading.Thread(target=dance,kwargs={"num":2,"name":"渣渣猫"})
sing_process.start()
dance_process.start()
线程的注意点
1、主线程会等待所有子线程执行结束后再结束
import threading
import time
def dowork():
for i in range(10):
print(f'子线程{i}工作中....')
time.sleep(0.2)
if __name__ == '__main__':
work_thread = threading.Thread(target=dowork)
# work_process.daemon = True # 设置守护主进程
work_thread.start()
time.sleep(1)
print('主线程执行完啦...')

2、设置守护主线程
主线程退出后子线程直接销毁,不再执行子线程中的代码
import threading
import time
def dowork():
for i in range(10):
print(f'子线程{i}工作中....')
time.sleep(0.2)
def dostudy():
for i in range(10):
print(f'子线程{i}学习中....')
time.sleep(0.2)
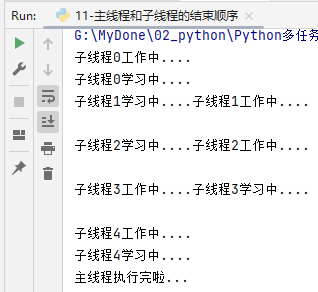
if __name__ == '__main__':
# 主线程结束不想等待子线程结束再结束,可以设置子线程守护主线程
# 方式一
work_thread = threading.Thread(target=dowork)
work_thread.setDaemon(True)
work_thread.start()
# 方式二
study_thread = threading.Thread(target=dostudy, daemon=True)
study_thread.start()
time.sleep(1)
print('主线程执行完啦...')
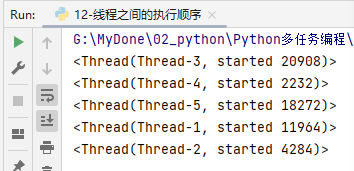
线程间的执行顺序
多线程之间执行是无序的,由CPU调度决定的
import threading
import time
def task():
time.sleep(1)
thread=threading.current_thread()
print(thread)
if __name__ == '__main__':
for i in range(5):
sub_thread=threading.Thread(target=task)
sub_thread.start()
参考:黑马程序员python多线程编程
感觉讲的特别浅显,一点都不懂可以看看















 3280
3280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









