







一、Alexnet是什么?
AlexNet是一种深度卷积神经网络,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年提出。发表在NIPS,论文名为《ImageNet Classification with Deep Convolutional Neural Networks》,论文见:http://www.cs.toronto.edu/~hinton/absps/imagenet.pdf .
它被广泛应用于计算机视觉领域的图像分类任务, 它是第一个在ImageNet大规模图像识别挑战赛上取得显著成功的深度学习模型。
二、Alexnet的结构
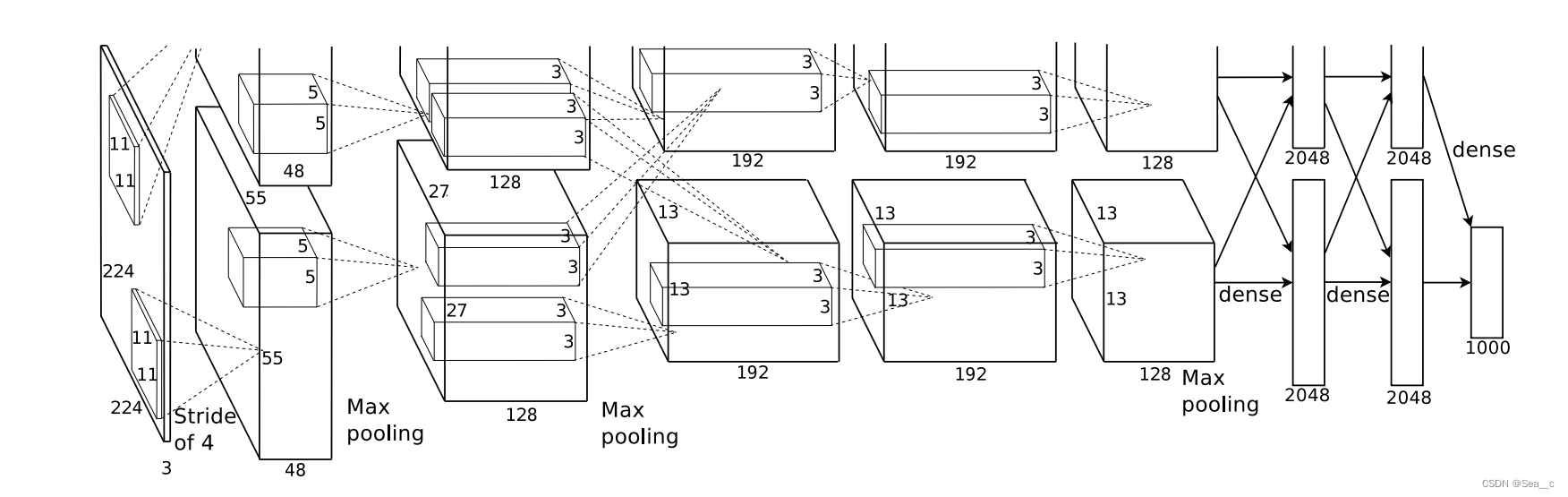
图中包含了GPU通信的部分。这是由当时GPU受限制引起的,作者使用两块GPU进行计算,因此分为上下两部分.
AlexNet是一种深度学习网络模型,用于图像分类任务。在该模型中,为了增加数据的多样性和丰富性,在输入网络之前,从256×256大小的图像中随机裁剪出227×227大小的图像作为输入。原本论文中提到的输入尺寸为224×224是一个错误,正确的输入尺寸应为227×227。
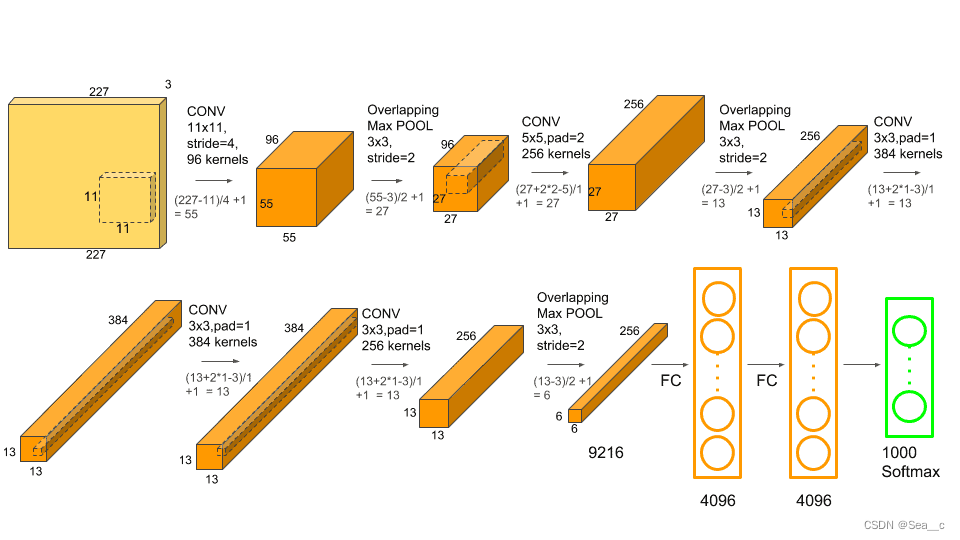
整体结构由5个卷积层(Convolution、ReLU、LRN、Pooling)+3个全连接层组成.
1. 输入层(Input):图像大小227*227*3.
2. 第一个卷积层C1: 使用96个11*11的filter,stride为4,padding为0,卷积层后跟ReLU,因此输出的尺寸为 (227-11)/4+1=55,因此其输出的每个特征图 为 55*55*96
训练参数为 (11*11*3*96)+96=34944 同时后面经过LRN层处理,尺寸不变.
3.最大池化层:filter为3*3,stride为2,padding为0,输出为27*27*96,96个feature maps
4.第二个卷积层C2 : 使用256个5*5的filter,stride为1,padding为2,输出为27*27*256,256个feature maps,训练参数(5*5*96*256)+256=614656。
5..最大池化层:filter为3*3,stride为2,padding为0,输出为13*13*256,256个feature maps。
6. 第三个卷积层C3+ReLU:使用384个3*3的filter,stride为1,padding为1,输出为13*13*384,384个feature maps,训练参数(3*3*256*384)+384=885120。
7. 第四个卷积层C4+ReLU:使用384个3*3的filter,strid
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









