










常见时序算法集合
学习资料1:十大时序算法模型
十大时序算法模型
- Naïve, SNaïve
- Seasonal decomposition (+ any model)
- Exponential smoothing
- ARIMA, SARIMA
- GARCH
- Dynamic linear models
- TBATS
- Prophet
- NNETAR
- LSTM
学习资料2:Kats
【Kaggle竞赛宝典】FaceBook开源全网第一个时序王器–Kats
时间序列王器-Kats
FaceBook开源了Kats,它是第一个开发标准并连接时间序列分析各个领域的综合Python库,用户可以在这里探索其时间序列数据的基本特征,预测未来值,监视异常,并将其合并到ML模型和pipeline中。
在上个月,FaceBook开园了一款新的分析时间序列数据的library–Kats,Kats是一款:
- 轻量级的、易于使用的、通用的时间序列分析框架;
包括
- 预测、异常检测、多元分析和特征提取/嵌入。
据我们所知,Kats是第一个用于一般时间序列分析的综合Python库,它提供了经典和高级的时间序列数据建模技术。
1. Kats的优势
Kats是一个分析时间序列数据的工具箱,特点是:
- 轻量级;
- 易于使用;
- 通用;
- 可以用来执行时间序列分析。
2. Kats的功能
Kats的核心四大功能包括:
- 模型预测:Kats提供了一套完整的预测工具,包括10+个单独的预测模型、ensembling、自监督学习(meta-learning)模型、backtesting、超参数调整和经验预测区间。
- 检测:Kats支持检测时间序列数据的各种模式的功能,包括季节性、异常值、变化点和缓慢的趋势变化检测。
- 特征提取与嵌入:Kats中的时间序列特征(TSFeature)提取模块可以产生65个具有明确统计定义的特征,这些特征可以应用于大多数机器学习(ML)模型,如分类和回归。
- 使用的功能:Kats还提供了一组有用的实用程序,例如时间序列模拟器。
学习资料3:NeuralProphet
NeuralProphet
介绍一个最新的NeuralProphet时,从名字就可以看出,这个是神经网络和Prophet的结合,与传统的黑盒NN不同,本文我们就介绍的NeuralProphet模型集成了Prophet的所有优点,不仅具有不错的可解释性,还有优于Prophet的预测性能。
1. Prophet
Prophet如果认为是基本自回归的扩展(除了使用lagged的目标值,还对输入变量使用傅立叶变换,这使得我们可以通过调模型拿到更好的结果)。
- Prophet可以使用额外的信息,不仅仅是target的延迟值;
- 模型能融入节假日信息;
- 可以自动检测趋势的变化;
2. NeuralProphet
和许多黑盒子的NN不同,NeuralProphet保留了Prophet的所有优势,同时,通过引入改进的后端(Pytorch代替Stan)和使用自回归网络(AR网络),将神经网络的可扩展性与AR模型的可解释性结合起来,提高其准确性和可扩展性。
- AR网络——它是一个单层网络,经过训练可以模拟时间序列信号中的AR过程,但规模比传统模型大得多。
3. NeuralProphet VS Prophet
- NeuralProphet使用PyTorch的梯度下降进行优化,使得建模速度更快;
- 利用自回归网络对时间序列自相关进行建模;
- 滞后回归器使用单独的前馈神经网络建模;
- NeuralProphet具有可配置的前馈神经网络的非线性深层;
- 模型可调整到特定的预测范围(大于1);
- 提供自定义的损失函数和度量策略;
项目地址:https://aistudio.baidu.com/aistudio/projectdetail/525311?channelType=0&channel=0
参考资料:
[时间序列模型Prophet使用详细讲解]https://blog.csdn.net/anshuai_aw1/article/details/83412058
[初识Prophet模型(一)-- 理论篇]https://www.jianshu.com/p/218757bee516
学习资料4:Prophet
Prophet 简介
Prophet是Facebook开源的时间序列预测算法,可以有效处理节假日信息,并按周、月、年对时间序列数据的变化趋势进行拟合。根据官网介绍,Prophet对具有强烈周期性特征的历史数据拟合效果很好,不仅可以处理时间序列存在一些异常值的情况,也可以处理部分缺失值的情形。算法提供了基于Python和R的两种实现方式。
从论文上的描述来看,这个 prophet 算法是基于时间序列分解和机器学习的拟合来做的,其中在拟合模型的时候使用了 pyStan 这个开源工具,因此能够在较快的时间内得到需要预测的结果。
Prophet 适用场景
Prophet适用于具有明显的内在规律的商业行为数据,例如:有如下特征的业务问题:
- a.有至少几个月(最好是一年)的每小时、每天或每周观察的历史数据;
- b.有多种人类规模级别的较强的季节性趋势:每周的一些天和每年的一些时间;
- c.有事先知道的以不定期的间隔发生的重要节假日(比如国庆节);
- d.缺失的历史数据或较大的异常数据的数量在合理范围内;
- e.有历史趋势的变化(比如因为产品发布);
- f.对于数据中蕴含的非线性增长的趋势都有一个自然极限或饱和状态。
Prophet 算法的输入输出
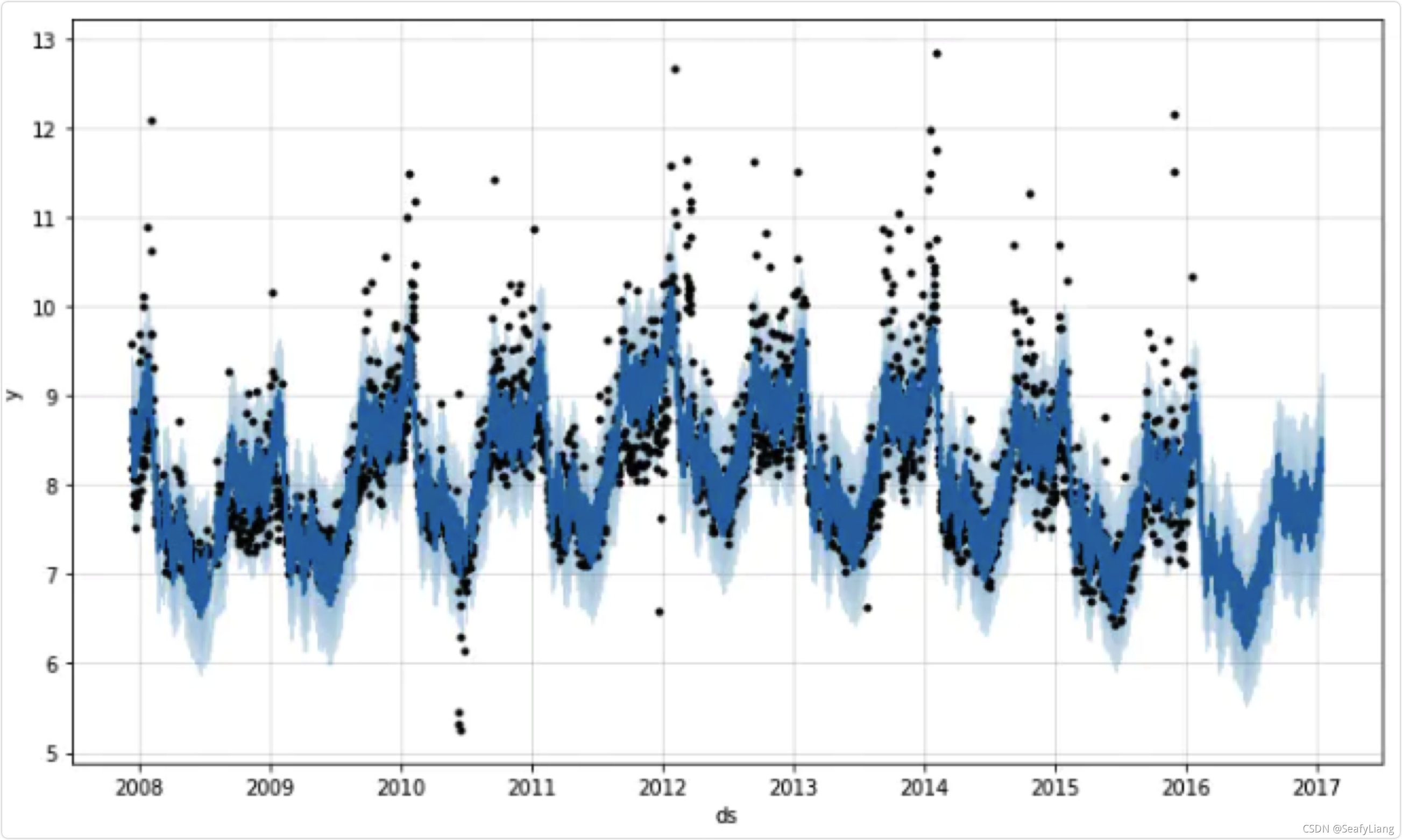
上图为一个时间序列场景:
-
黑色表示原始的时间序列离散点
-
深蓝色的线表示使用时间序列来拟合所得到的取值
-
浅蓝色的线表示时间序列的一个置信区间,也就是所谓的合理的上界和下界
-
prophet 所做的事情就是:
-
输入已知的时间序列的时间戳和相应的值;
-
输入需要预测的时间序列的长度;
-
输出未来的时间序列走势。
-
输出结果可以提供必要的统计指标,包括拟合曲线,上界和下界等。
-
传入prophet的数据分为两列 ds 和 y ,ds表示时间序列的时间戳,y表示时间序列的取值
其中:
-
ds是pandas的日期格式,样式类似与
YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS; -
y列必须是数值型,代表着我们希望预测的值。
通过 prophet 的计算,可以计算出:
-
yhat,表示时间序列的预测值
-
yhat_lower,表示预测值的下界
-
yhat_upper,表示预测值的上界
Prophet 算法原理
算法模型:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s22S4zN9-1630376859594)(https://cdn.nlark.com/yuque/0/2021/svg/2524844/1628747209413-9cdd789a-881a-4a4b-accc-50d53a4f8023.svg#align=left&display=inline&height=29&margin=%5Bobject%20Object%5D&originHeight=29&originWidth=270&size=0&status=done&style=none&width=270)]
模型整体由三部分组成:
- growth(增长趋势)
- seasonality(季节趋势)
- holidays(节假日对预测值的影响)
其中:
- g(t) 表示趋势项,它表示时间序列在非周期上面的变化趋势;
- s(t) 表示周期项,或者称为季节项,一般来说是以周或者年为单位;
- h(t) 表示节假日项,表示时间序列中那些潜在的具有非固定周期的节假日对预测值造成的影响;
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M3b3hqbX-1630376859597)(https://cdn.nlark.com/yuque/0/2021/svg/2524844/1628747209537-96ef69c6-6a2b-404b-9cef-a005c251b560.svg#align=left&display=inline&height=18&margin=%5Bobject%20Object%5D&originHeight=18&originWidth=16&size=0&status=done&style=none&width=16)]即误差项或者称为剩余项,表示模型未预测到的波动, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HDoLVdnY-1630376859600)(https://cdn.nlark.com/yuque/0/2021/svg/2524844/1628747209406-fb4a3f02-2c9e-4d43-b6d1-f8ba8e570db4.svg#align=left&display=inline&height=18&margin=%5Bobject%20Object%5D&originHeight=18&originWidth=16&size=0&status=done&style=none&width=16)]服从高斯分布;
Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
与机器学习算法的对比
与先进的机器学习算法如LGBM相比,Prophet作为一个时间序列的工具,优点就是不需要特征工程就可以得到趋势,季节因素和节假日因素,但是这同时也是它的缺点之一,它无法利用更多的信息,如在预测商品的销量时,无法利用商品的信息,门店的信息,促销的信息等。
因此,寻找一种融合的方法是一个迫切的需求。
代码
测试数据集
# 读入数据集
df = pd.read_csv('data/example_wp_log_peyton_manning.csv')
print(df.head())
# 拟合模型
m = Prophet()
m.fit(df)
# 构建待预测日期数据框,periods = 365 代表除历史数据的日期外再往后推 365 天
future = m.make_future_dataframe(periods=365)
future.tail()
# 预测数据集
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
# 展示预测结果
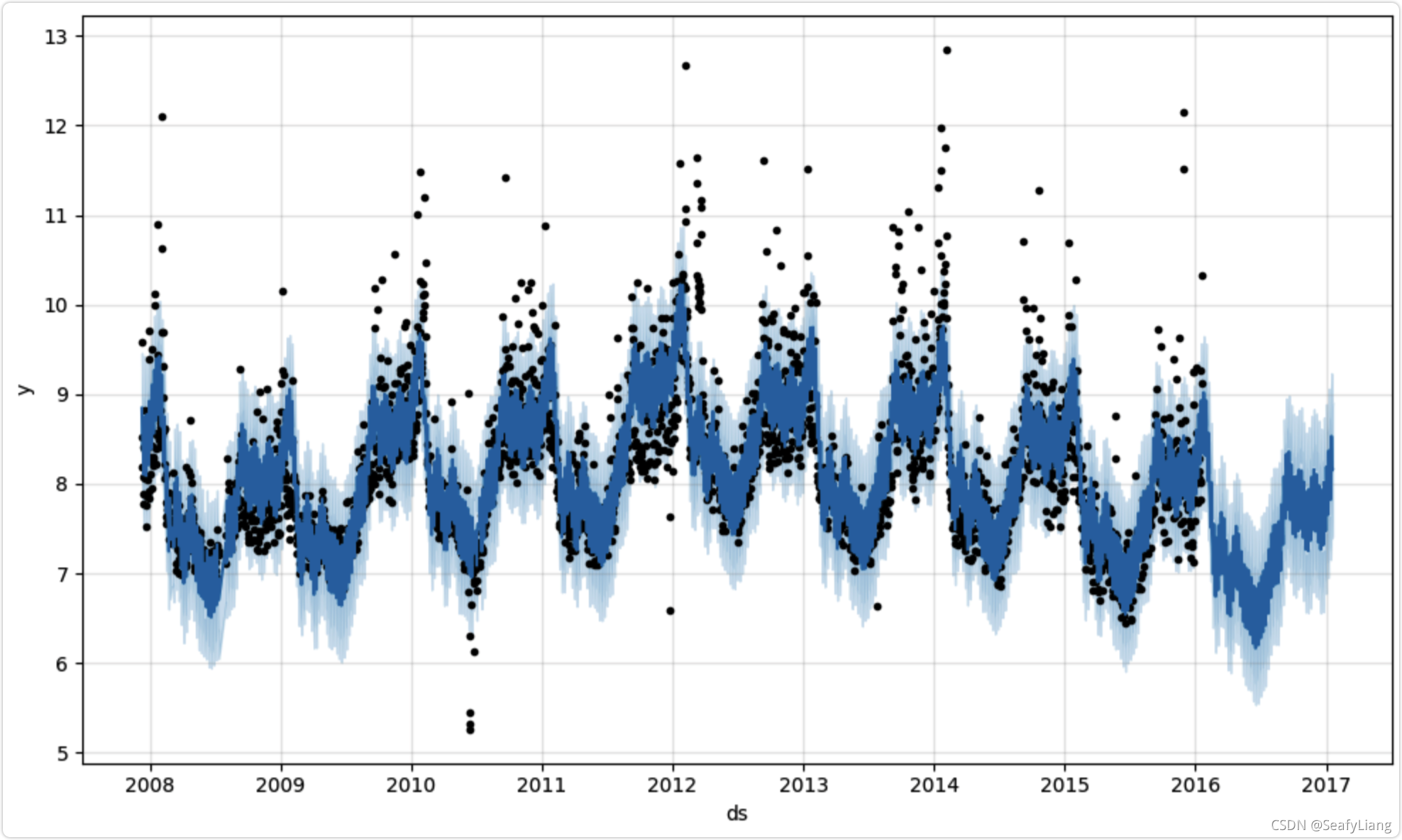
m.plot(forecast)
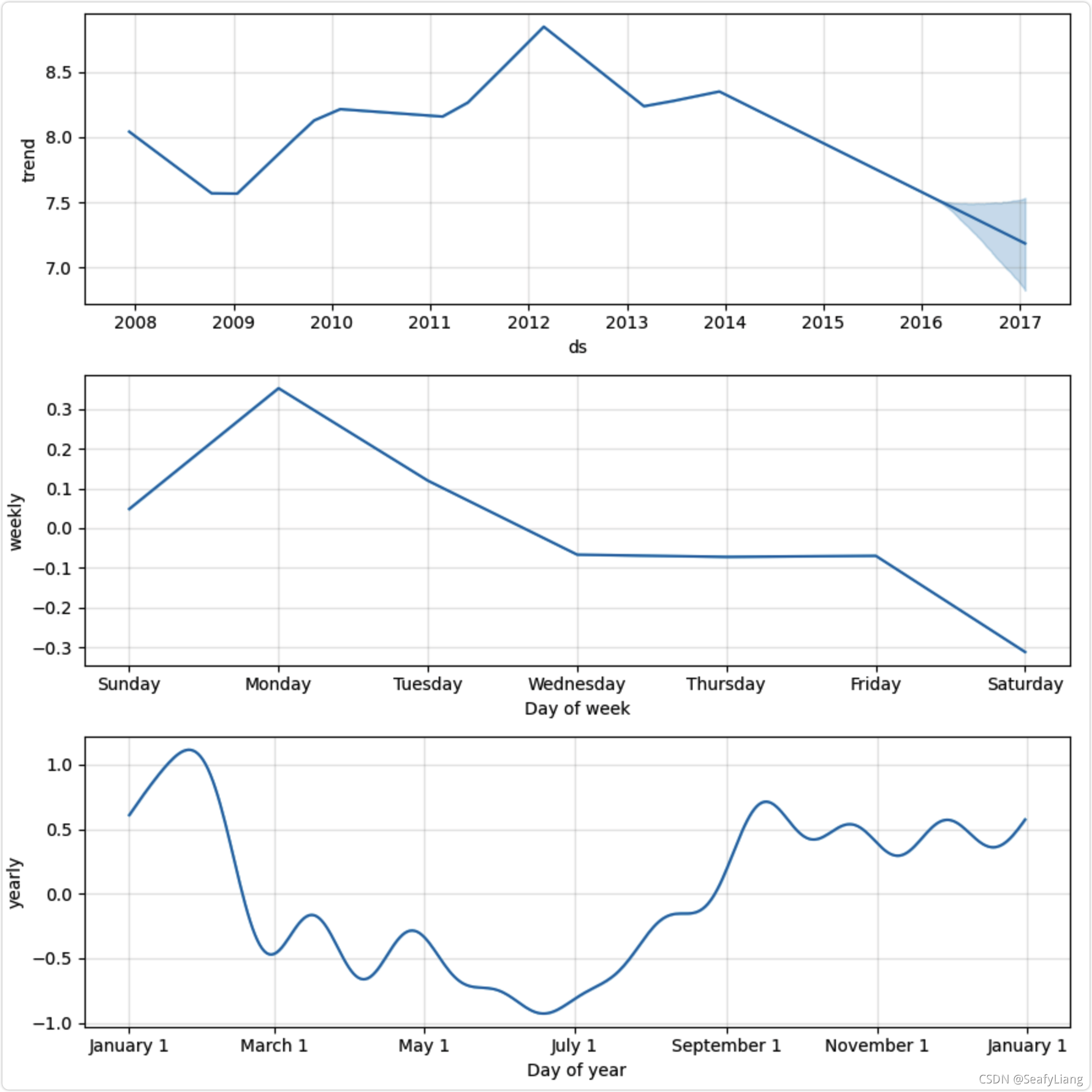
# 预测的成分分析绘图,展示预测中的趋势、周效应和年度效应
m.plot_components(forecast)
plt.show()
参考资料
官方链接:
-
论文:《Forecasting at scale》,https://peerj.com/preprints/3190/

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









