






在风控领域中,对于模型的评估常用的指标其实并不是精准率、召回率这些,而是 ROC。
原因很简单:样本。
试想一下,在一个用户数据集中有 100w 个用户,但是其中只有 1000 个用户是坏用户,如果用这个数据集去建模型,用什么指标去评估模型好坏?为什么?
ok,如果你有答案了,可以直接跳到文末了解四个灵魂问题。
如果你一脸懵,建议带着这个问题去看今天的文章。
ROC 曲线
先来看一下 ROC 曲线的定义:根据分类结果计算得到空间中相应的点,连接这些点就形成 ROC curve
其中横坐标为 False Positive Rate (FPR:假正率),纵坐标为 True Positive Rate (TPR:真正率)。
贴一下 TPR 和 FPR 的公式
一般情况下,这个曲线都应该处于 (0,0) 和 (1,1) 连线的上方,如图:
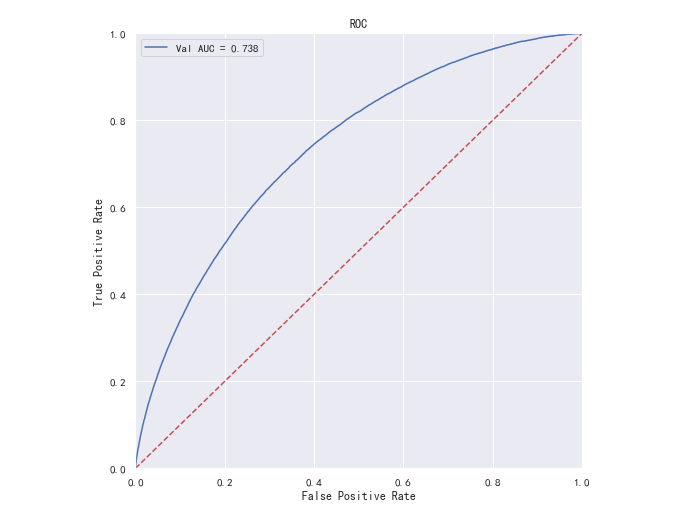
再来看一下这些计算点是怎么来的
对于一个特定的分类器和测试数据集,显然只能得到一个分类结果,即一组 FPR 和 TPR 结果,而要得到一个曲线,我们实际上需要一系列FPR和TPR的值才能得到这样的曲线。
首先,我们在分类问题中,对于预测结果归属于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。
如果我们减小这个阀值,更多的样本会被识别为正类,提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。
所以我们可以通过分类器的一个重要功能 “概率输出”,也就是分类器认为某个样本具有多大的概率属于正样本,来 动态调整 样本是正样本还是负样本。
如果我们已经得到了所有样本的概率输出,也就是样本预测为正样本的概率,那我们就可以画出上图所述的 ROC 曲线。
不是很懂?能举个栗子嘛!
ok !! 安排!
下图是一个示例,图中共有 20 个测试样本。
Class 一栏表示每个测试样本真正的标签,其中 p 表示正样本,n 表示负样本,Score 一栏表示每个样本属于正样本的概率。
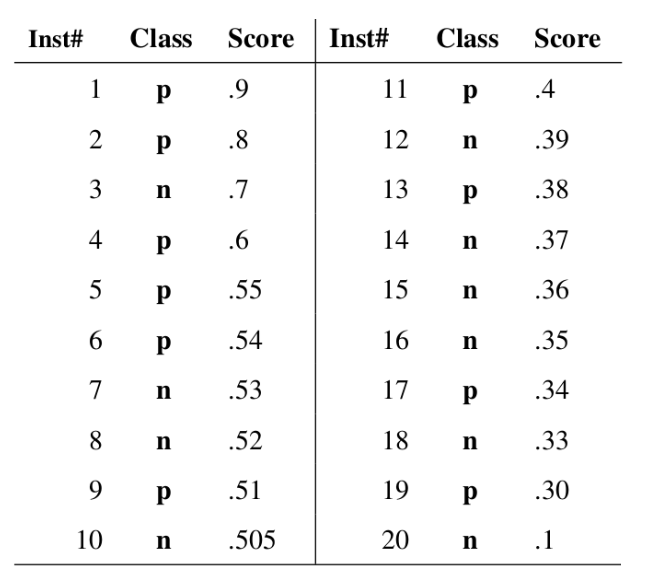
接下来,我们从高到低,依次将 Score 值作为阈值,当样本属于正样本的概率大于或等于这个阈值时,我们认为它为正样本,否则为负样本。
比如对于图中的第 4 个样本,其 Score 值为 0.6,因为样本 1、2、3、4 的 Score 值都大于等于 0.6,所以它们都会被认为是正样本,而其他样本则都认为是负样本。
然后我们可以根据公式计算出真正率 TPR 和 假正率 FPR,分别如下:
注意一点,在后面会用到,很重要!
TP+FN 的结果就是实际正样本的个数,TN+FP 的个数就是实际负样本的个数。
也就是说,TPR 只与正样本有关,FPR 只与负样本有关
根据计算结果,当阈值 Score 设置为 0.6时,对应的点为:(FPR,TPR) => (0.1,0.3)
通过 依次选取不同的阈值,我们就可以得到一组 FPR 和 TPR 值,对应为 ROC 曲线上的一点。
这样一来,我们一共得到了 20 组 FPR 和 TPR 的值,将它们画在坐标轴中如下:
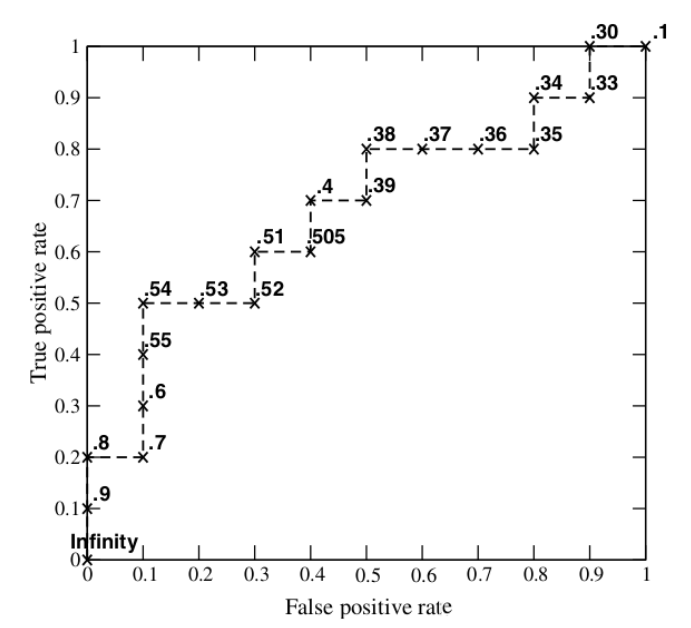
当我们将阈值设置为 1 和 0 时,分别可以得到 ROC 曲线上的 (0,0) 和 (1,1) 两个点。
将这些 (FPR,TPR) 点连接起来,就可以得到 ROC 曲线。当阈值取值越多,ROC曲线越平滑。
ok,对于 ROC 曲线的得来应该说的很清楚了。
常见 ROC 问题 - 01
如何判断 ROC 曲线的好坏?
需要清楚的是,ROC 是通过 TPR 和 FPR 共同决定的,所以问题的关键就在于这两个指标。
首先,TPR 指的是对于正样本预测正确的概率,说直白一点:就是正样本被预测为正样本。
在预测中我们希望不论正样本还是负样本,模型预测的准确率越高越好,对应的 TPR 我们当然希望越大越好。
其次,FPR 指的是对于负样本预测错误的概率,也直白一点:负样本被预测为正样本。
在预测中我们并不希望负样本被预测为正样本,所以对于 FPR,我们希望它越小越好。
综合一下,就是 TPR 越高,同时 FPR 越低,对应的 ROC 曲线越陡峭,模型的性能越好
常见 ROC 问题 - 02
在模型的评估中,当数据样本不平衡的时候,为什么采用 ROC 做评估指标比较好?
根据计算公式,我们知道 TPR 只与正样本有关,FPR 只与负样本有关(上面提到过)。
所以在整体样本中,假设总样本中 10% 是正样本、90% 是负样本,计算 TPR 时只需要考虑 10% 正样本预测的结果,计算 FPR 时只需要 90% 负样本的预测结果。
也就是说,无论你样本分布是怎么样的,都不影响我 TPR 和 FPR 的计算,也就不会影响 ROC 曲线的趋势了。
再说过来,如果不用 ROC,使用精确率或者准确率来评估,先看公式:
很明显,在精确率中分母即包含正样本 TP 也包含负样本 FP,准确率中分子即包含正样本 TP 也包含负样本 TN
所以,无论是精确率的计算还是准确率的计算,都无法避免会因为样本分布而影响到整体值。
举个最极端的例子:整体样本中正样本个数为10,负样本个数为 990,
在计算的时候,即使正样本都预测正确,也只有 10 个样本,而 990 个负样本中只要随便超过 10 个样本预测为正样本(预测错误了),精确率都会直接降低到 50% 以下。
要想从 990 个负样本中挑选 10 个预测错误简直太容易了,所以对于样本分布及不平衡的数据集,用精确率评估预测效果会上蹿下跳的,非常差劲!
常见 ROC 问题 - 03
ROC 的最佳阈值如何确定?
前面我们知道,我们会依次将 Score 值作为阈值然后分别计算 TPR 和 FPR,我们希望 TPR 越大,对应的 FPR 越小。
也就是当 TPR-FPR 最大时,对应的 Score 就是阈值。
代码如下:
# ROC 实现
from sklearn import metrics
import numpy as np
y_true = np.array([0, 1, 1, 1, 1])
y_score = np.array([0.4, 0.4, 0.55, 0.8, 0.7])
fpr, tpr, thresholds = metrics.roc_curve(y_true, y_score)
roc_auc = metrics.auc(fpr, tpr)
# 确定最佳阈值
optimal_threshold = thresholds[np.argmax(tpr-fpr)]
point = [fpr[np.argmax(tpr-fpr)], tpr[np.argmax(tpr-fpr)]]
print(optimal_threshold, roc_auc, point)
# 输出:最佳阈值、AUC面积、最佳阈值对应点
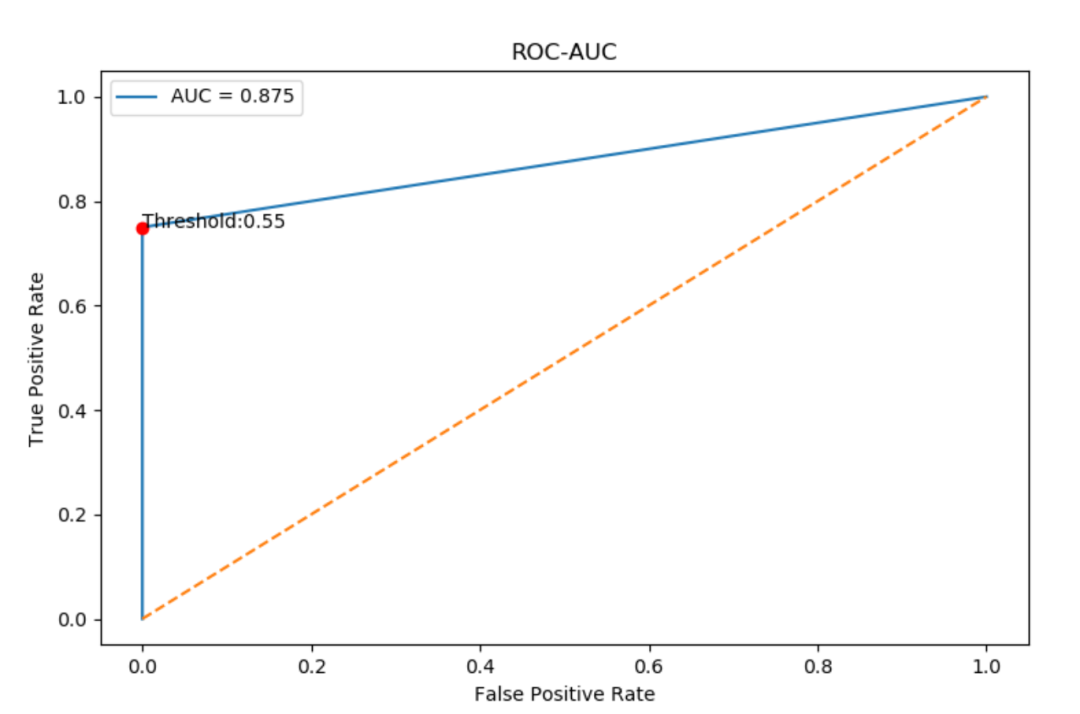
0.55 0.875 [0.0, 0.75]
稍微解释一下以上代码:
直接通过 metrics 包调用 roc_curve 函数计算每一步的 tpr、fpr 和对应 阈值 thresholds
取 tpr-fpr 的最大值对应的阈值为最佳阈值,并通过 auc 函数计算 auc 值
画图显示如下:
plt.figure(1)
plt.plot(fpr, tpr, label=f"AUC = {roc_auc:.3f}")
plt.plot([0, 1], [0, 1], linestyle="--")
plt.plot(point[0], point[1], marker='o', color='r')
plt.text(point[0], point[1], f'Threshold:{optimal_threshold:.2f}')
plt.title("ROC-AUC")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.legend()
plt.show()
常见 ROC 问题 - 04
最后一个常见问题,ROC 的缺点是什么?
ROC 的缺点主要是 FPR 在 ROC 曲线中体现不出来。
举个例子,如果新样本中负样本比例较高,那么在 FPR 增长的时候,对应的 ROC 曲线不会发生明显的变化。
比如负样本 10000 个,正样本 10 个,如果被判错的负样本由 10 个增长到 20 个,FPR 也只是由 0.001 到 0.002:
但是这个其实也不算是缺点,毕竟我们要的是 TPR,FPR 体现不出来不影响 TPR。
●解一道反常的Pandas题●12000+字超详细 SQL 语法速成!
后台回复“入群”即可加入小z干货交流群

















 2852
2852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









