






定义执行逻辑
1. 定义全局变量:
ep=200 __train=False mt_data_len=200000 max_encoder_length = 2*96 max_prediction_length = 30 batch_size = 128

添加图片注释,不超过 140 字(可选)
__train用于控制赫兹量化交易软件当前是在训练还是测试模型。
值得注意的是,ep用于控制最大训练时期。由于我们已经设置了EarlyStoping,因此可以将该值设置得更大一点,因为当模型不再收敛时,它将自动停止。
mt_data_len是从客户端获得的最近时间序列数据的数量。
max_encoder_length 和 max_prediction_length 分别是最大编码长度和最大预测长度。
2.训练
当训练完成时,赫兹量化交易软件还需要将当前的最佳训练结果保存到本地文件中,因此我们定义了一个json文件来保存这些信息:
info_file='results.json'
为了使我们的训练过程更加清晰,赫兹量化交易软件需要避免在训练过程中输出一些不必要的警告信息,因此我们将添加以下代码:
warnings.filterwarnings("ignore")
接下来是我们的训练逻辑:
dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2)
训练完成后,您可以在根目录的results.json文件中找到我们最佳模型的存储位置和最佳分数。
在训练过程中,您将看到一个进度条,显示每个 epoch 的进度。
训练:
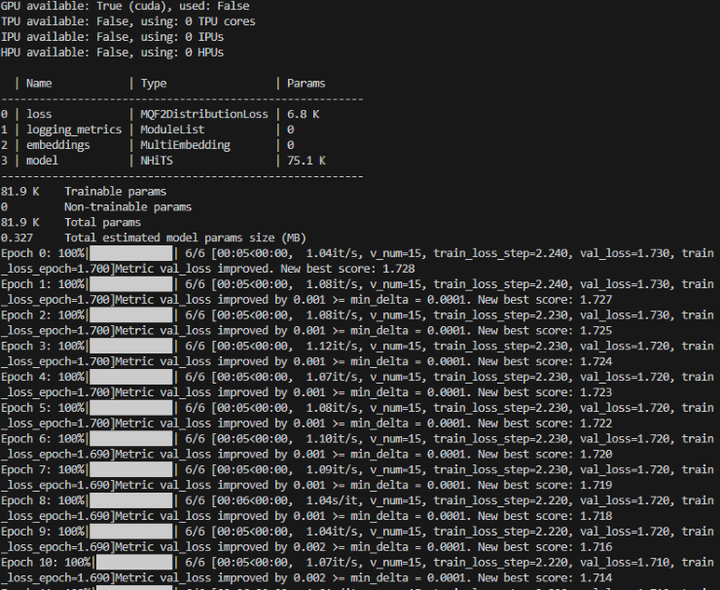
添加图片注释,不超过 140 字(可选)
训练完成
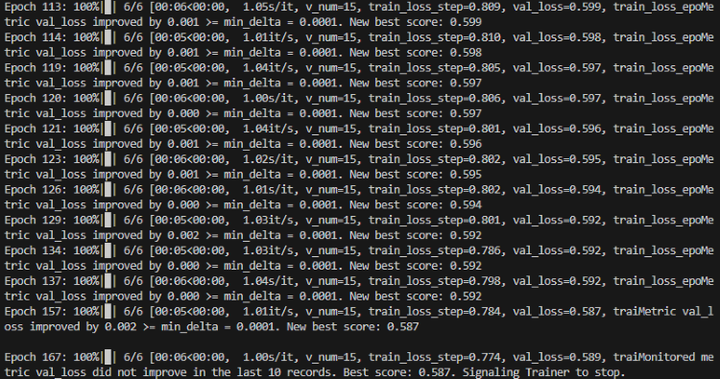
添加图片注释,不超过 140 字(可选)
3. 验证模型
在训练之后,赫兹量化交易软件希望验证模型并将其可视化。我们可以添加以下代码:
best_model = NHiTS.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) # sample 500 paths samples = best_model.loss.sample(raw_predictions.output["prediction"][[0]], n_samples=500)[0] # plot prediction fig = best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=0, add_loss_to_title=True) ax = fig.get_axes()[0] # plot first two sampled paths ax.plot(samples[:, 0], color="g", label="Sample 1") ax.plot(samples[:, 1], color="r", label="Sample 2") fig.legend() plt.show()
您也可以在训练期间使用TensorBoard实时查看训练情况的可视化,我们在这里不做演示。
结果:
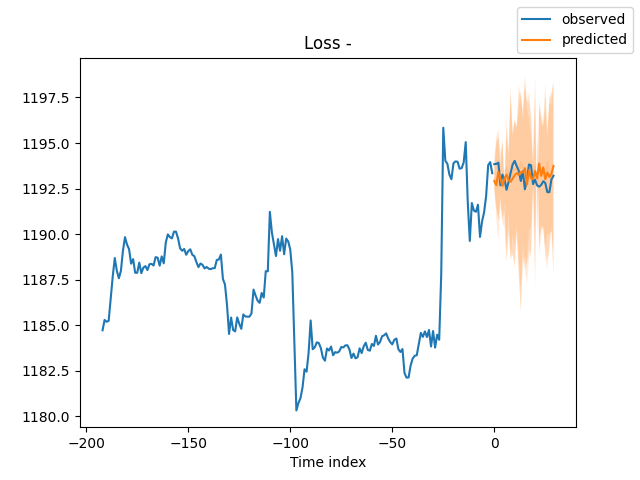
添加图片注释,不超过 140 字(可选)

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









