





论文网址:PLM-ICD: Automatic ICD Coding with Pretrained Language Models - ACL Anthology
论文代码:https://github.com/MiuLab/PLM-ICD
目录
2.3.2. Pretrained Language Models
2.5.1. Domain-Specific Pretraining
2.7.2. Effect of Pretrained Models
2.7.3. Effect of Label Attention Mechanisms
2.7.4. Effect of Long Input Strategies
2.7.5. Effect of Maximum Length
2.7.6. Effect of Optimization Process
1. 心得
(1)写的很细,Preliminaries写了很多
2. 论文逐段精读
2.1. Abstract
①任务:电子健康记录多标签分类(electronic health records, EHRs)
②现存问题:大标签域、长输入序列、预训练和微调域不匹配问题
③作者提出pretrained language models (PLM)-ICD来解决这些问题
2.2. Introduction
①领域现存问题:EHRs是非常自由的文本;分类ICD编码非常耗费人力;标签域大;数据分布不均
②EHRs分类的意义:追踪健康统计,质量结果和账单(好奇怪的一句话)
③使用预训练模型现存问题:临床文本超过了PLM的最大长度;常规微调在多标签域上的不会带来很好的分类效果;常规语料库预训练大模型和医学的有出入
④模型设计:域特定预训练以解决域不匹配问题;对长输入序列使用分割池化;对大标签集合标签注意
corpora n. 语料库
2.3. Related Work
2.3.1. Automatic ICD Coding
①现有处理EHR的方法:RNN,多过滤器卷积,引入外部知识,注意力机制,树级序列LSTM,增加损失函数,图卷积,LAAT(标签注意力),effectiveCAN,focal loss(对数量多的样本分配更低的权重)
2.3.2. Pretrained Language Models
①通用文本领域训练的大模型:XLNet、RoBERTa
②一些医学文本预训练的大模型:BioBERT,ClinicalBERT,PubMerBERT,和RoBERTa-PM
③X-BERT专门契合多标签任务,有作者对于长序列输入问题提出五个截断和分割策略
④也有模型专门去EHR上预训练,然后用标签注意力AttentionXML
⑤作者自己使用文档级特定标签表征而不是chunk级别的
2.4. Challenges for PLMs
2.4.1. LongInput Text
①为了契合位置编码,通常设有最大序列长度512,但MIMIC III数据集平均有1500个词/2000个token
②作者在LAAT模式中把诊断文本裁剪成512个单词,在BERT模式中把诊断文本裁剪成512个token。作者测试了不同最大长度文本带来的性能:
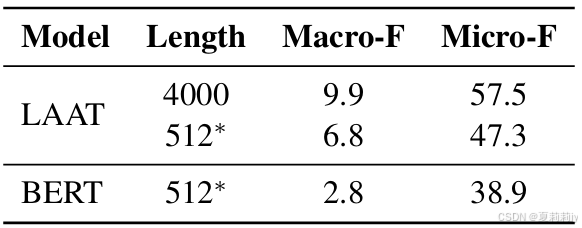
截断会导致性能下降(挺多的
detrimental adj.有害的,不利的 n.有害的人(或物);不利条件
2.4.2. Large Label Set
①MIMIC III有8921个标签
②使用[CLS]分类的BERT和使用标签注意力的LAAT性能对比:
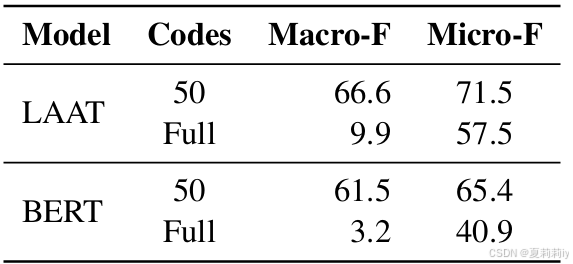
显然使用一个特征来进行多分类会导致信息丢失从而性能不佳
2.4.3. Domain Mismatch
①从通用领域训练的大模型需要对应的医学和临床任务下游微调
2.5. Proposed Framework
①假设一个EHR表示为,其中
是token,
是总token长度
②用EHR最终预测ICD码,
③PLM-ICD模型框架:
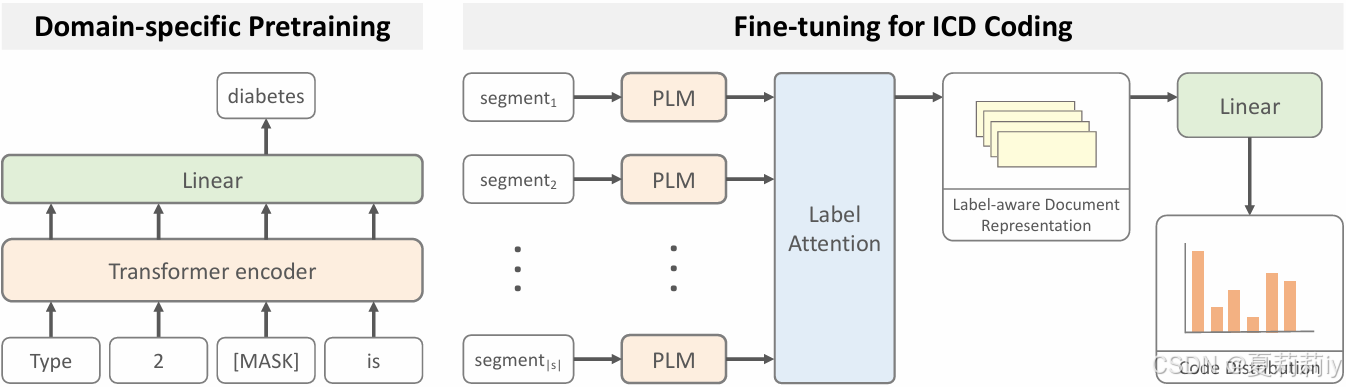
2.5.1. Domain-Specific Pretraining
①作者使用了在医学数据上预训练过的模型:BioBERT、PubMedBERT、RoBERTa-PM
2.5.2. Segment Pooling
①作者先把整个临床文本切分成段,使用PLM编码之后得到段落表征,然后再聚合:
2.5.3. Label-Aware Attention
①计算标签级注意力矩阵:
其中和
是线性层
②标签级表示:
实际上,这里我觉得很奇怪,可能要联系上面的:
来看,可能每个片段
是一个竖直的向量,所以
的形状可能是
,实际上特征是在第0个维度,和平时的数学公式不太一样(可能代码里会这样用,但很多人写论文还是喜欢实体当第0个维度而特征当第一个维度。
因此后面的线性层+
或
实际上是在先平滑特征再归一化特征,我猜
会是一个
的形状,然后
则是
(作者没提到这些形状,由于有时候论文公式可能和真的代码变量形状有区别,所以我也不想在这里测试代码变量形状)。然后作者提到
③预测概率:
其中是第
个标签的向量,
是内积
④损失:
2.6. Experiments
2.6.1. Setup
①数据集:MIMIC II(训练集:20533个样本,测试集:2282个样本,标签个数:5031),MIMIC III(训练集:47724个样本,验证集:1632个样本,测试集:3372个样本,标签个数:8922)
2.6.2. Evaluation
①评估指标:macro F1, micro F1, macro AUC, micro AUC, and precision@K, K = {5,8,15}
2.6.3. Results
①训练轮次:3次的平均
②对比模型结果都是从他们论文里面直接摘抄的
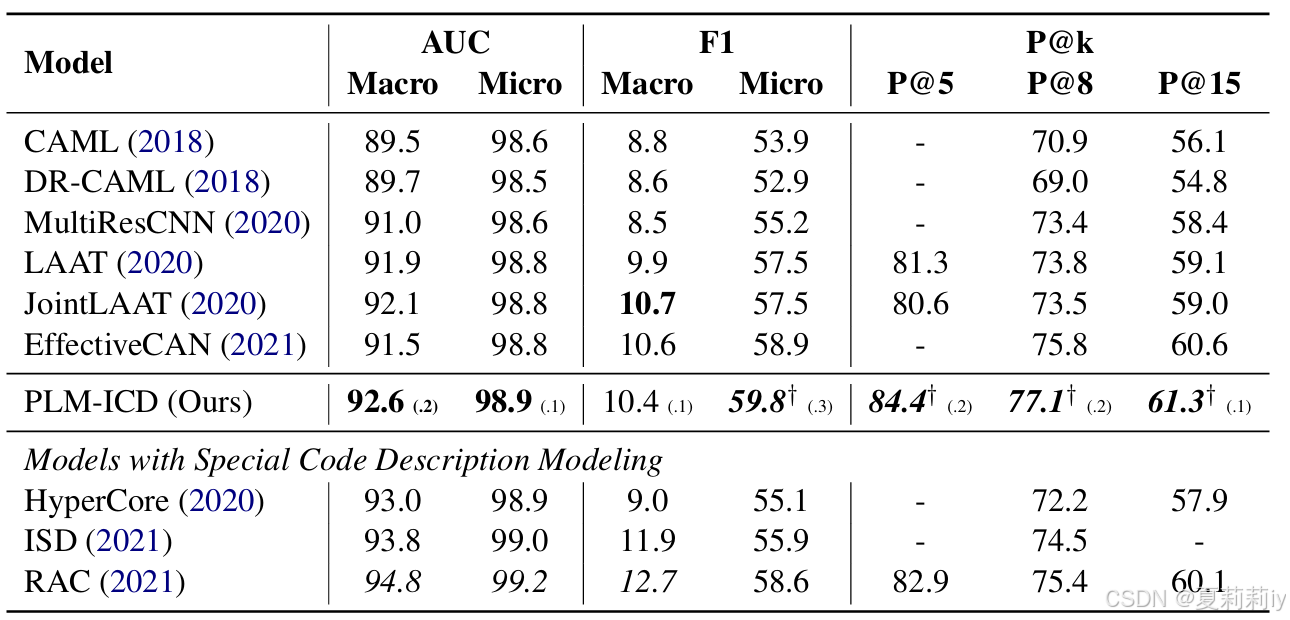
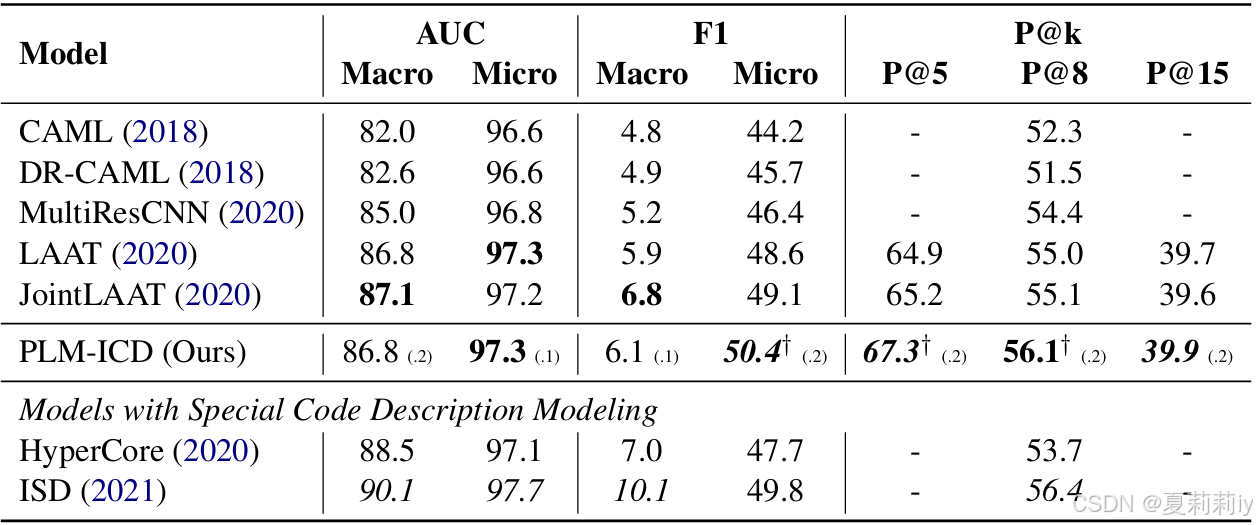
(1)MIMIC-3
①对比实验:
(2)MIMIC-2
①对比实验:
2.7. Analysis
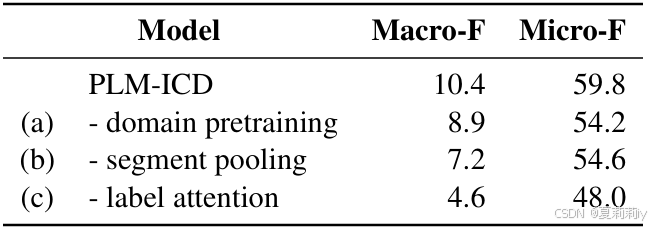
2.7.1. Ablation Study
①MIMIC III上的模块消融:
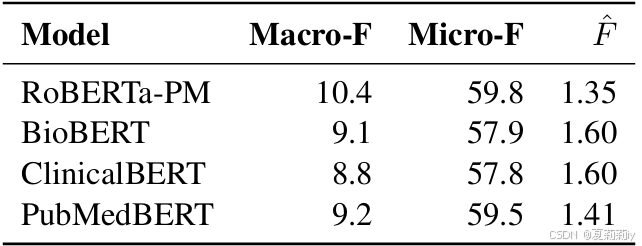
2.7.2. Effect of Pretrained Models
①预训练模型对比:
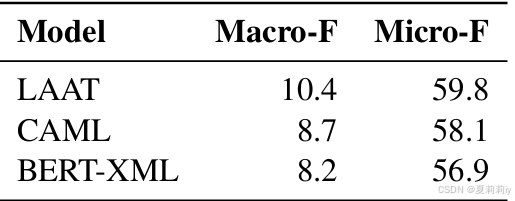
2.7.3. Effect of Label Attention Mechanisms
①不同注意力机制下的结果:
2.7.4. Effect of Long Input Strategies
①对长文本处理方法的对比实验:
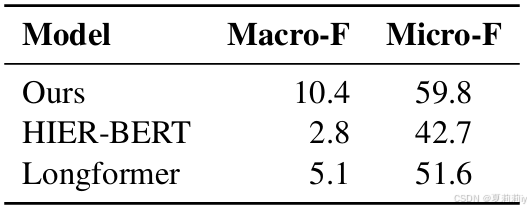
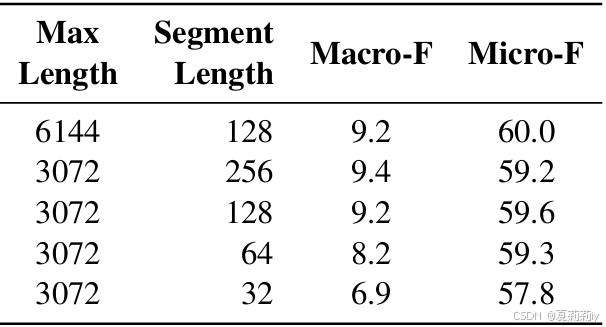
2.7.5. Effect of Maximum Length
①不同最大文本长度和截断长度下的模型表现:
2.7.6. Effect of Optimization Process
①这个模型是优化策略敏感的
2.7.7. Best Practices
~
2.8. Conclusion
~

















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









