










更多博客可以关注MyBlog,欢迎大家一起学习交流!
1. 简介
题目:《Bootstrapping Entity Alignment with Knowledge Graph Embedding》
来源:IJCAI-2018
链接:论文链接
代码:Code和Dataset
关键字:Entity Alignment、Bootstrapping、Embedding
2. 研究背景
近些年(基于2018年的),一些基于Embedding的实体对齐方法被提出,虽然取得了不错的效果,但是仍存在一些问题:
1) KG Embedding部分主要复用面向KG补全的Embedding模型,面向实体对齐的Embedding模型有待探索。
2)在训练数据比较少的情况下,当前方法精度很低。
为此我们提出了一个Bootstrapping的方法,将实体对齐转化为一个分类问题,期望学习的Embeddings具有最大的实体对齐似然。具体地,我们提出了一个面向实体对齐的KG Embedding模型(AlignE);然后动态标记新的实体对齐作为训练数据来增强匹配效果(BootEA)。
3.Problem Formulation
X
X
X 与
Y
Y
Y 分别表示
K
G
1
KG_1
KG1 和
K
G
2
KG_2
KG2 的实体集合,实体对齐任务就是去寻找
A
=
{
(
x
,
y
)
∈
X
×
Y
∣
x
∼
R
y
}
A = \{(x,y) \in X\times Y|x \sim_R\,y\}
A={(x,y)∈X×Y∣x∼Ry} 不同
K
G
KG
KG 中的等价的实体对。作者将其任务定义为一个分类任务,即用
Y
Y
Y 中的实体去给
X
X
X 中的实体进行贴标签。不过这里和一般的分类任务不一样,这里的实体标签只能一对一,即一个
Y
Y
Y实体标签只能给一个实体
X
X
X进行标注,或者不标签,这里作者使用
Θ
\Theta
Θ 表示不同的
K
G
KG
KG 的嵌入表示,其中
y
∈
Y
y\in Y
y∈Y 作为标签,
x
∈
X
x \in X
x∈X 作为待标注的实体,其对于某个实体
x
x
x 对应是标签
y
y
y 的概率如下公式:
π
(
y
∣
x
;
Θ
)
=
σ
(
s
i
m
(
v
→
(
x
)
,
v
→
(
y
)
)
)
(1)
\pi(y|x;\Theta) = \sigma(sim(\overset{\rightarrow}{v}(x),\overset{\rightarrow}{v}(y))) \tag {1}
π(y∣x;Θ)=σ(sim(v→(x),v→(y)))(1)
其采用向量的第二范式距离,然后用激活函数转换表示标签的准确性概率的大小,然后作者采用选取全局整体的标签准确率之和最大的情况,其中的
L
x
\mathbb{L}_x
Lx 表示实体
x
x
x 正确的标签,而指示函数
1
[
⋅
]
1_{[\cdot]}
1[⋅]的取值为
(
0
o
r
1
)
(0\,or\,1)
(0or1):
Θ
^
=
arg
max
Θ
∑
x
∈
X
log
π
(
L
x
∣
x
;
Θ
)
=
arg
max
Θ
∑
x
∈
X
∑
y
∈
Y
1
[
y
=
L
x
]
log
π
(
y
∣
x
;
Θ
)
(2)
\begin{aligned} \hat\Theta &= \arg\max_{\Theta}\sum_{x\in X}\log \pi(\mathbb{L}_x |x;\Theta) \\ &=\arg\max_{\Theta}\sum_{x\in X}\sum_{y\in Y}1_{[y=\mathbb{L}_x]}\log \pi(y |x;\Theta) \end{aligned} \tag {2}
Θ^=argΘmaxx∈X∑logπ(Lx∣x;Θ)=argΘmaxx∈X∑y∈Y∑1[y=Lx]logπ(y∣x;Θ)(2)
上式中考虑的重点在于对齐的实体对的相似概率,而对于其他没对齐的实体的信息没保留,所以这个方程式对于实体对齐不太好,后续的目标函数也是处于这样的考虑的。
4. Methodology
4.1 Alignment-Oriented KG Embedding
作者本文将两个
K
G
KG
KG 的实体编码在统一空间中,这样就可以直接计算实体之间的相似性。作者采用Translation-based Model去捕获语义信息,即评价函数为:
f
(
τ
)
=
∣
∣
v
→
(
h
)
+
v
→
(
r
)
−
v
→
(
t
)
∣
∣
2
2
f(\tau) = ||\overset{\rightarrow}{v}(h)+\overset{\rightarrow}{v}(r)-\overset{\rightarrow}{v}(t)||^{2}_{2}
f(τ)=∣∣v→(h)+v→(r)−v→(t)∣∣22 ,用来表示三元组
τ
=
(
h
,
r
,
t
)
\tau = (h,r,t)
τ=(h,r,t) 的可能性,采用Margin-based Ranking Loss的损失函数虽然是保证正实例之间的距离能够小与负样本之间的距离,但是[Zhou etal., 2017]文中研究发现,这个函数不能保证正样例的距离足够小,即表示的之间的可能性不准确,所以作者提出了一种新的损失函数:
O
e
=
∑
τ
∈
T
+
[
f
(
τ
)
−
γ
1
]
+
+
μ
1
∑
τ
′
∈
T
−
[
γ
2
−
f
(
τ
′
)
]
+
(3)
O_{e}=\sum_{\tau\in\mathbb{T}^{+}}[f(\tau)-\gamma_{1}]_{+}+\mu_{1}\sum_{\tau^{\prime}\in\mathbb{T}^{-}}[\gamma_{2}- f(\tau^{\prime})]_{+} \tag {3}
Oe=τ∈T+∑[f(τ)−γ1]++μ1τ′∈T−∑[γ2−f(τ′)]+(3)
其中
[
⋅
]
+
=
max
(
⋅
,
0
)
,
γ
1
a
n
d
γ
2
>
0
,
μ
1
>
0
[\cdot]_{+}=\max(\cdot,0),\gamma_{1}\,and\,\gamma_{2} > 0,\mu_{1}>0
[⋅]+=max(⋅,0),γ1andγ2>0,μ1>0,而对应的
T
+
和
T
−
\mathbb{T}^{+}和 \,\mathbb{T}^{-}
T+和T− 分别表示正负样本集合。该方程式有两个特性:1-该方程可以保证正确的实体对能维持更小的距离值,同时保证负样本能后具有更大的距离值,这里设定
γ
2
>
γ
1
\gamma_{2}>\gamma_{1}
γ2>γ1;同时能够保证
f
(
τ
′
)
−
f
(
τ
)
≥
γ
2
−
γ
1
f(\tau^{\prime})-f(\tau)\ge\gamma_{2} -\gamma_{1}
f(τ′)−f(τ)≥γ2−γ1,这个也保留了原先的Margin-based Ranking Loss的特性。
4.2 ϵ \epsilon ϵ-Truncated Uniform Negative Sampling
一般生成负样例的方法就是随机的替换关系中的头结点或者尾结点,但是这样的替换可能与原先的关系组很容易区分,即差别太大了,对于嵌入式的学习来说可能影响不大,作者本文中希望能识别出很近关系组之间的区别,作者对实体 x x x 的替换选择如下:选择离其最近的 s s s 个实体,其中 s = ⌈ ( 1 − ϵ ) N ⌉ , ϵ ∈ [ 0 , 1 ) s= \left\lceil (1-\epsilon)N\right\rceil,\epsilon\in[0,1) s=⌈(1−ϵ)N⌉,ϵ∈[0,1) , N N N 是 K G KG KG 中的实体的数目, ⌈ ⋅ ⌉ \left\lceil \cdot\right\rceil ⌈⋅⌉是向上取值函数,取代的实体将和原先的实体非常相似,这样对训练更有帮助。
Parameter Swapping
作者通过扩增三元组的同时将两个图谱在同一空间进行嵌入学习,对于对齐的实体对
(
x
,
y
)
∈
A
′
(x,y)\in A^{\prime}
(x,y)∈A′ ,通过替换对应的实体来增加对齐的三元组:
T
(
x
,
y
)
s
=
{
(
y
,
r
,
t
)
∣
(
x
,
r
,
t
)
∈
T
1
+
}
∪
{
(
h
,
r
,
y
)
∣
(
h
,
r
,
x
)
∈
T
1
+
}
∪
{
(
x
,
r
,
t
)
∣
(
y
,
r
,
t
)
∈
T
2
+
}
∪
{
(
h
,
r
,
x
)
∣
(
h
,
r
,
y
)
∈
T
2
+
}
(4)
\mathbb{T}^{s}_{(x,y)} = \{(y,r,t)|(x,r,t)\in\mathbb{T}^{+}_{1}\}\cup\{ (h,r,y)|(h,r,x)\in\mathbb{T}^{+}_{1}\}\cup \{(x,r,t)|(y,r,t)\in\mathbb{T}^{+}_{2}\} \cup\{(h,r,x)|(h,r,y)\in\mathbb{T}^{+}_{2}\} \tag {4}
T(x,y)s={(y,r,t)∣(x,r,t)∈T1+}∪{(h,r,y)∣(h,r,x)∈T1+}∪{(x,r,t)∣(y,r,t)∈T2+}∪{(h,r,x)∣(h,r,y)∈T2+}(4)
然后作者根据产生的正样例再分别按照上诉方法取负样例。注意是这种替换可能增加了某个图中没有的关系三元组,丰富了关系组合。
4.2 Bootstrapping Alignment
嵌入表达学习由于缺少对齐的实体对,作者通过迭代不断的增加对齐的实体对,从而提升对齐的性能。作者将具有较高可信度的实体对加入到已知对齐的实体对中间去,作为训练数据。
Likely Alignment Labeling and Editing
传统的Bootstrapping方法每次都是选取最可信的标签去标签数据,但是本研究中标签的数据是受限的,就是一对一的关系,就是一个标签使用以后就不能标签其他实体了,作者由此提出了其下面优化的目标函数:
max
∑
x
∈
X
′
∑
y
∈
Y
x
′
π
(
y
∣
x
;
Θ
(
t
)
⋅
ψ
(
t
)
(
x
,
y
)
)
s
.
t
.
∑
x
′
∈
X
′
ψ
(
t
)
(
x
′
,
y
)
≤
1
,
∑
y
′
∈
Y
x
′
ψ
(
t
)
(
x
,
y
′
)
≤
1
,
∀
x
,
y
(5)
\max \sum_{x\in X^{\prime}}\sum_{y\in Y^{\prime}_{x}}\pi(y|x;\Theta^{(t)}\cdot\psi^{(t)}(x,y)) \\ s.t.\sum_{x^{\prime}\in X^{\prime}}\psi^{(t)}(x^{\prime},y)\le1,\sum_{y^{\prime}\in Y^{\prime}_{x}}\psi^{(t)}(x,y^{\prime})\le1,\forall x,y \tag {5}
maxx∈X′∑y∈Yx′∑π(y∣x;Θ(t)⋅ψ(t)(x,y))s.t.x′∈X′∑ψ(t)(x′,y)≤1,y′∈Yx′∑ψ(t)(x,y′)≤1,∀x,y(5)
其中的
Θ
(
t
)
\Theta^{(t)}
Θ(t) 表示第
t
t
t 次迭代时候的嵌入表达向量,
Y
x
′
=
y
∣
y
∈
Y
′
a
n
d
π
(
y
∣
x
;
Θ
(
t
)
)
>
γ
3
Y^{\prime}_{x} = {y|y\in Y^{\prime} and\,\pi(y|x;\Theta^{(t)})\gt\gamma_{3}}
Yx′=y∣y∈Y′andπ(y∣x;Θ(t))>γ3 表示实体
x
x
x 的候选实体集,
ψ
(
t
)
(
⋅
)
\psi^{(t)}{(\cdot)}
ψ(t)(⋅) 就是一个指示函数,如果实体
x
x
x 被
y
y
y 贴上标签,那么值就为1,否则就为0。上面两个不等式保证了一对一的关系,不会存在一个标签重复使用的情况。每次迭代后,作者将新加的实体对增加到训练数据中去,继续后续的训练。
随着时间的递增,训练效果应该越来越好,但是任然会产生误差,为了去缓解这种误差的影响,在该训练中,对于一个已经被贴新标签的实体,在后续的训练中,可以被取消标签或者替换新的标签,这样的方法在本次研究中心,既简单有有效,在判断标签是否有效的时候,是通过比较其距离的大小,如下式:
△
(
x
,
y
,
y
′
)
(
t
)
=
π
(
y
∣
x
;
Θ
(
t
)
)
−
π
(
y
′
∣
x
;
Θ
(
t
)
)
(6)
\triangle^{(t)}_{(x,y,y^{\prime})} = \pi(y|x;\Theta^{(t)})-\pi(y^{\prime}|x;\Theta^{(t)}) \tag {6}
△(x,y,y′)(t)=π(y∣x;Θ(t))−π(y′∣x;Θ(t))(6)
Learning from Holistic Perspective
为了获取一个全局的已标签或未标签的情况,对其定义了以下的分布(7),如果被标记了,那么其对应的概率为1(只有y等于真正标签的时候),没有被标记的话就是一个均匀分布(和总体的未标记的数目有关),然后给定该概率分布后,得到新的对齐目标函数(求其最小值):
ϕ
x
(
y
)
=
{
1
[
y
=
y
^
]
=
i
f
x
i
s
l
a
b
e
l
e
d
a
s
y
^
1
∣
Y
′
∣
=
i
f
x
i
s
u
n
l
a
b
e
l
e
d
(7)
\phi_{x}(y)=\left\{ \begin{aligned} 1_{[y=\hat{y}]} & = &if\,x\, is \, labeled\,as\,\hat{y} \\ \frac{1}{|Y^{\prime}|} & = &if\,x\, is \, unlabeled \end{aligned} \right. \tag {7}
ϕx(y)=⎩⎪⎨⎪⎧1[y=y^]∣Y′∣1==ifxislabeledasy^ifxisunlabeled(7)
O a = − ∑ x ∈ X ∑ y ∈ Y ϕ X ( y ) log π ( y ∣ x ; Θ ) (8) O_{a}=-\sum_{x\in X}\sum_{y\in Y}\phi_{X}(y)\log\pi(y|x;\Theta) \tag {8} Oa=−x∈X∑y∈Y∑ϕX(y)logπ(y∣x;Θ)(8)
最后作者整体考虑,其最终的目标函数如下:
O
=
Q
e
+
μ
2
⋅
Q
A
(9)
O=Q_{e}+\mu_{2}\cdot Q_{A} \tag {9}
O=Qe+μ2⋅QA(9)
4.3 Implementation Details
本部分主要是对参数的具体说明,详见论文。
5. 实验分析
本文作者采用了DBP15K和DWY100K两类数据集,其中后面一个数据集的详情如下:
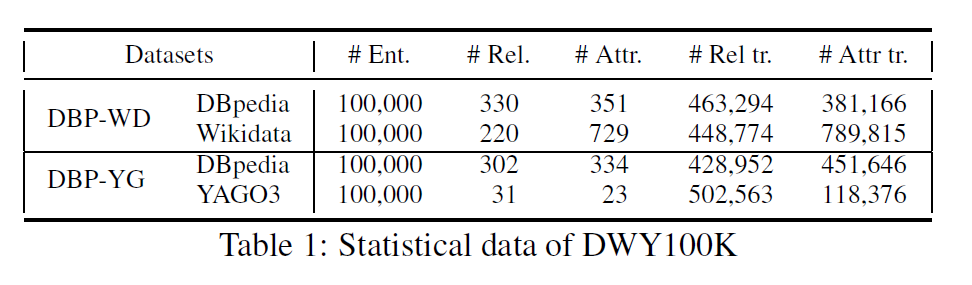
其中对照的模型以及对其的实验结果如下图:

其结果可以看出其结果优于当其先提出的模型,而且在性能上面有较大的提升。
结果分析
作者为了说明其性能的优越性的原因,分别对以下4各方面进行对照实验:
- Effectiveness of ϵ \epsilon ϵ-Truncated Uniform Negative Sampling
- Accuracy of Likely Alignment
- Sensitivity to Proportion of Prior Alignment
- F1-score w.r.t. Distribution of Relation Triple Numbers

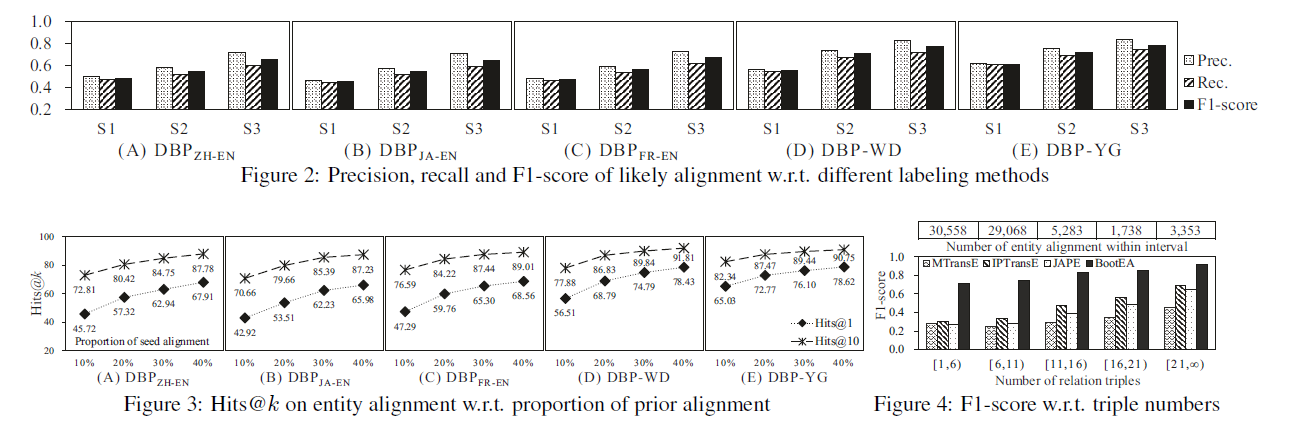
作者通过其上面的实验,进一步说明其提出的相关策略的有效性,其具体的分析可以见原文,里面介绍很详细。
















 1176
1176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









