







主要内容
构建项目baseline(训练、推断、配置文件)
- baseline结构和实现
- 语义分割的metrics
- 语义分割的loss
训练
1.baseline 基本原则
- no data augmentation
尽可能不使用数据增强,便于筛选模型 - no big model
一般开始时使用模型选小的,降低试错的时间成本 - low resolution(先做缩小)
输入图像分辨率越大越好,但是资源占用高,baseline中尽量使用低分辨率输入图像。 - little tricks
类似于第一条,baseline中尽可能少的使用有效trick
2.训练过程
- 创建网络模型
- 加载预训练权重(可选)
- 设置优化器
- SGD+Momentum 类比手动挡,对学习率等超参数敏感
- Adam 类比自动挡 最常用的优化器
- 生成训练训练数据
** 主要参数**
epoch/batchnum/(iterations)
调整学习率(Decay逐渐衰减、cycle循环学习率,在最大值与最小值之前循环,如正弦余弦、warmup 缓慢上升学习率 )
前向计算 (pred = model(input))
计算损失 (loss = pred - label)
反向传播
3. Metrics 模型评价标准
metrics与loss关系:
metrics 用来评价已经训练完毕的模型
loss 用在训练模型过程
原则上两者越一致越好,但实际情况为了方便优化,两者会有出入。
TP/FP/TN/FN
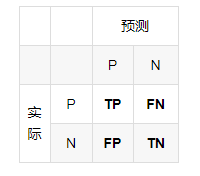
F1指标
计算方式如下,公式中准确率( TP/(TP+FP) )与召回率( TP/(TP+FN) )

图像分割中类别不平衡问题
图像分割本质为分类问题,但是当前景分割类别占据图像较小,背景占据图像较大面积时,训练过程中会趋向于预测最大的类别,即占据图像面积最对的类别,由此来得到最高的准确率。例如1000个样本,其中100个positive,900个negtive,则模型会趋向于将1000个样本全部预测为负样本,由此得到90%的准确率。 解决这种问题就要设计合理的评价标准。下图为类别不平衡案例:
最后预测图为纯黑图像

IoU/Jaccard Index
IoU Loss = 1 - IoU
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









