







目录
Gradient Descent with Large Datasets
Stochastic Gradient Descent Convergence
Map Reduce and Data Parallelism
Large Scale Machine Learning
Gradient Descent with Large Datasets
Learning WithLarge Datasets
一般来说,设计得当的模型,喂给他们的数据集越大,得到的训练效果越好,但同时需要的计算资源/时间/开销也越大。
Stochastic Gradient Descent
随机梯度下降算法的核心步骤是:
1. 随机排列dataset
2. 随机下降的每一步,都选一个未被选中的train data,来更新theta,直到所有的data都被选过一遍
这样在面对大数据量data时避免了sum up所有的数据带来的内存和时间消耗。每一步下降的方向不一定最优,但最终会到global min范围附近。
Mini-Batch Gradient Descent
已涉及到的三种gradient descent区别如下:

mini-batch是介于批梯度下降和随机梯度下降之间的算法,比批梯度下降快,并行化好时也可比随机梯度下降更快。
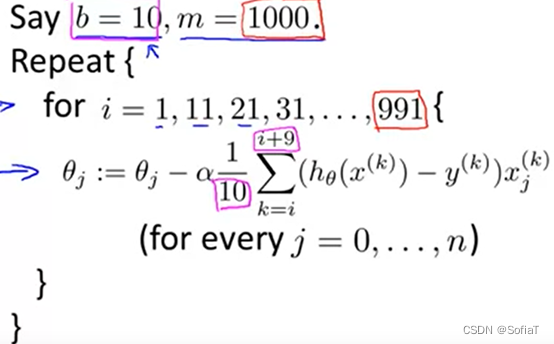
Stochastic Gradient Descent Convergence
为了检查alpha是否合适,以及随机梯度下降是否收敛,可以借助画图的方式,例如每1000次更新后画出当前的损失函数值:

一些常见的图像如下:
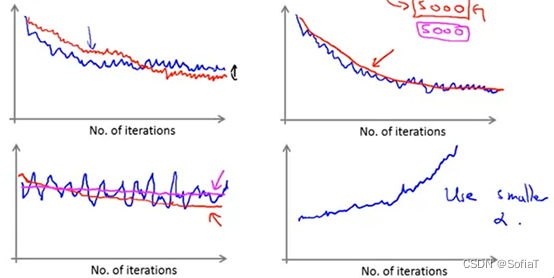
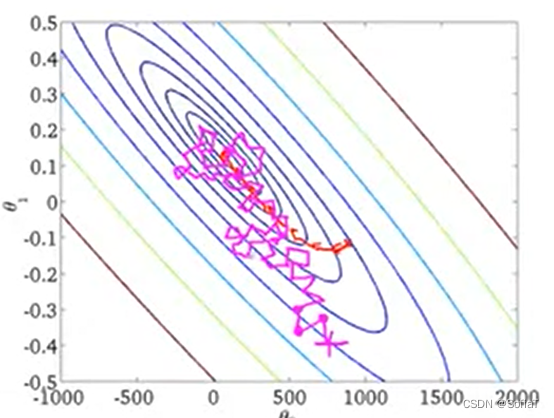
按照左上、右上、左下、右下依次介绍。
图1为选取不同alpha时收敛的情况
图2为iteration每5000而非1000时会发生的情况,当画图迭代区间增大时,图像会趋于平滑,不过也会导致数据更新delay
图3为不收敛的图像,如果感觉震荡很大无法观察,可以调大区间。解决不收敛可能需要改alpha/特征值/算法模型
图4为alpha过大的图像,需要调小α
以上都是alpha为常量,事实上我们可以让它随着迭代而改变。但也有人不推荐这样做,因为这会使需要调整的参数增多,变量增多就需要更多的尝试来找到最佳解决方案。
Advanced Topics
Online Learning
实时学习模型。放弃了固有训练集的概念,而是记录Xi/Yi的数据到一个循环算法,之后不再使用这些数据。可以change user peference。
- 不是扫描固定的训练集,而是从一个例子中学习,然后丢弃它并继续,适合连续的数据流
- 尝试预测的事物正在缓慢变化,例如购物网站的用户品味在缓慢变化一样,在线学习算法可以慢慢适应
Map Reduce and Data Parallelism
使用map reduce能在处理比stochastic gradient descent更大规模上的数据。原理类似于分布式系统or多核处理器,把要计算的数据分拆,然后得到结果,再合并。
















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









