







✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
本文所有资源均可在该地址处获取。
引言和背景
图像水印技术最初是为了知识产权保护和复制保护而开发的,如好莱坞工作室对DVD的水印。随着生成性AI模型的发展,水印的应用也在演变。例如,美国白宫的行政命令、加州法案、欧盟AI法案和中国AI治理规则都要求AI生成的内容能够被轻松识别,并将水印作为检测和标记AI生成图像的推荐或强制措施。
这篇论文试图解决的是图像水印技术在处理小面积水印和图像部分编辑时的限制问题。具体来说,论文中提到传统图像水印技术主要面临的挑战包括:
-
小面积水印处理不足: 传统方法不擅长处理图像中只有部分区域被水印的情况。这限制了它们在现实世界场景中的应用,例如当图像的某些部分来自不同来源或被编辑时。
-
对图像编辑的鲁棒性不足: 现实中的图像可能会经历各种编辑操作,如裁剪、压缩、拼接等,这些操作可能会破坏水印信号,使得水印检测和信息提取变得困难。
-
对AI生成内容的检测需求: 随着生成性AI模型的发展,监管法规要求AI生成的内容能够被轻易识别,水印技术被视为一种检测和标记AI生成图像的推荐或强制措施。
-
图像拼接的挑战: 图像拼接是一种常见的操作,涉及在图像的大部分区域添加文本或表情包,或提取图像的部分并叠加到其他图像上。这种操作可以绕过现有的最先进的水印技术,因为这些技术通常对整个图像只做一次全局决策。
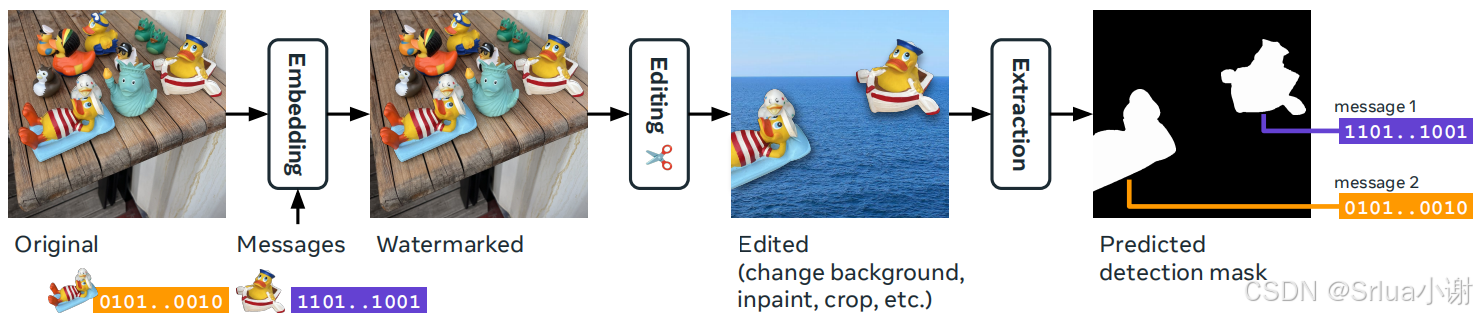
为了解决这些问题,论文《Watermark Anything with Localized Messages》提出了一种名为“Watermark Anything Model (WAM)”的深度学习模型,用于局部图像水印。
WAM的目标是将水印信号的强度与其像素表面面积解耦,与传统水印技术不同。WAM模型包括一个嵌入器和一个提取器。嵌入器用于将信息不可见地嵌入图像像素中,提取器用于分割接收到的图像成水印和非水印区域,并从被检测为水印的区域中恢复一个或多个隐藏消息。
通过这种方式,WAM能够提供新的功能,例如定位拼接图像中的水印区域,并从多个小区域中提取不同的32位消息,即使这些区域不超过图像面积的10%。
WAM模型介绍
任务定义
WAM将水印任务重新定义为一个分割任务,这意味着它不仅仅检测整个图像是否含有水印,而是能够识别出图像中哪些具体的像素被水印了。
这种方法与传统的水印技术不同,后者通常只对整个图像做出全局决策。WAM的提取器为每个像素输出一个向量,指示该像素是否被水印以及水印中隐藏的消息。
嵌入器
WAM的嵌入器负责将水印信息嵌入到图像中,同时确保这种嵌入对肉眼是不可见的。嵌入器由以下几个部分组成:

-
编码器:
编码器是一个深度神经网络,通常由多个卷积层和残差块组成,其目的是将输入图像压缩成一个低维的潜在空间表示。这个潜在空间表示捕捉了图像的关键特征,同时减少了数据的维度,使得后续的水印嵌入过程更加高效。 -
二进制消息查找表(Binary Message Lookup Table):
这是一个参数化的张量,用于将二进制消息(水印信息)映射到一个可以与图像潜在表示相加的嵌入张量。每个二进制位对应于查找表中的一个嵌入向量,这个向量是根据消息位的值(0或1)选择的。 -
解码器:
解码器是一个深度神经网络,它将编码器的输出(包括二进制消息的嵌入)映射回一个与原始图像相同维度的水印信号。这个水印信号是一个微小的扰动,当加到原始图像上时,能够嵌入水印信息,同时保持对肉眼的不可见性。 -
水印信号的缩放和添加:
水印信号通常在一个特定的范围内(例如[-1, 1]),通过一个缩放因子α(水印强度参数)来控制水印的强度。最终的水印图像是通过将水印信号加到原始图像上得到的,即watermarked_image = original_image + α * watermark_signal。 -
高分辨率处理:
由于嵌入过程在低分辨率下完成,所以需要将水印信号通过双线性插值扩展到高分辨率图像,以保持水印在不同尺度下的一致性。
提取器
提取器的任务是检测图像中的水印,并从中提取嵌入的消息。提取器的结构类似于图像分割网络,由以下几个主要部分组成:

-
图像编码器:
图像编码器通常是一个视觉变换器(Vision Transformer,ViT),它将输入图像分割成多个patches,并将这些patches映射到一个高维特征空间,ViT通过自注意力机制捕捉图像的全局和局部特征。 -
像素解码器:
像素解码器是一个卷积神经网络(CNN),它将ViT的输出特征上采样(upsample)回原始图像的分辨率。这个过程中,包含多个上采样块(upsampling blocks)和卷积层,以逐步恢复图像的空间维度。 -
输出层:
输出层是一个线性层,它将像素解码器的输出映射到一个(1+nbits)(1+nbits)维的向量,其中n是水印信息的位数。第一个维度用于水印检测,输出一个介于0和1之间的值,表示像素被水印的概率;接下来的n个维度用于消息提取,每个维度对应一个水印位的预测。 -
多水印处理:
提取器的输出被送入DBSCAN聚类算法,该算法根据像素级的二进制字符串将图像分割成多个区域,每个区域对应一个水印。DBSCAN算法不需要预设聚类的数量,能够根据数据的密度和邻近性自动发现聚类。 -
后处理:
对于全局检测,如果超过用户定义阈值的水印像素比例,则认为整个图像被水印覆盖。对于全局解码,通过多数投票恢复隐藏消息。对于局部化和多消息提取,DBSCAN算法用于识别和分离不同的水印区域,并提取相应的消息。
两阶段训练
第一阶段:预训练模型
目标:
在第一阶段,目标是获得一个鲁棒且可定位的局部水印,该水印可以在图像的一部分中隐藏一个 nbitsnbits 位的消息,而不太在意水印的不可感知性。这一阶段不包括任何感知损失,目的是在经过严重增强后实现完美的定位和解码。
过程:
- 嵌入器:嵌入器将 nbitsnbits位的消息编码成水印信号,并将其添加到原始图像中。
- 数据增强:随机掩蔽图像的一部分水印,并使用常见的处理技术(例如裁剪、缩放、压缩)增强结果。
- 提取器:输出每个像素的 1+nbits1+nbits 维向量,以预测图像中哪些部分被水印了,并解码相应的消息。
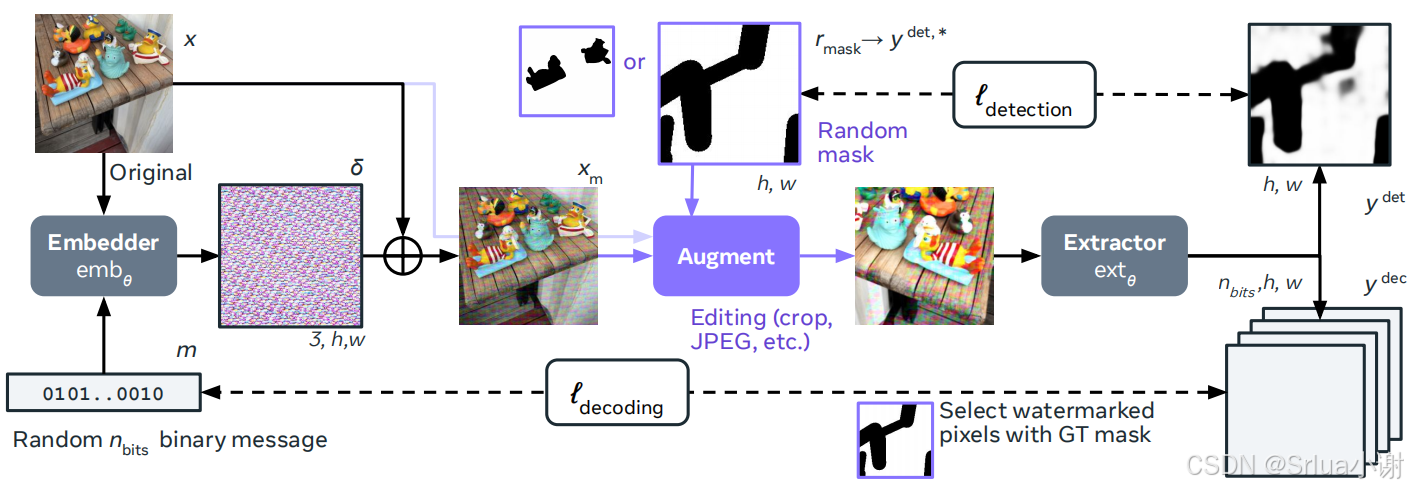
损失函数:
- 检测损失:像素级交叉熵的平均值,用于比较提取器的检测输出和真实的水印掩码。
- 解码损失:像素级和位级二进制交叉熵的平均值,仅在水印像素上计算,用于比较提取器的解码输出和原始嵌入的消息。
ℓdet(θ)=−1h×w∑i=1h×w[yidet,⋆log(yidet(θ))+(1−yidet,⋆)log(1−yidet(θ))]ℓdet(θ)=h×w−1i=1∑h×w[yidet,⋆log(yidet(θ))+(1−yidet,⋆)log(1−yidet(θ))]
ℓdec(θ)=−1nbits×∑i=1h×wyidet,⋆∑i=1h×wyidet,⋆∑k=1nbits[mklog(yi,kdec(θ))+(1−mk)log(1−yi,kdec(θ))]ℓdec(θ)=nbits×∑i=1h×wyidet,⋆−1i=1∑h×wyidet,⋆k=1∑nbits[mklog(yi,kdec(θ))+(1−mk)log(1−yi,kdec(θ))]
第二阶段:后训练模型
目标:
在第二阶段,目标是解决第一阶段训练出的模型水印可见性问题,并使其能够处理图像中的多个水印。
过程:
- 感知热图(Perceptual heatmap):使用 Just-Noticeable-Difference (JND) 图来调制水印的强度,使得水印在人眼不敏感的区域不那么可见。
- 多个水印(Multiple watermarks):通过引入多个掩模来解决模型倾向于在图像的不同区域解码出相同消息的问题。
损失函数:
- 检测损失:使用所有掩模的并集作为真实的水印掩码。
- 解码损失:分别为每个消息计算,并将损失相加。
评估方法
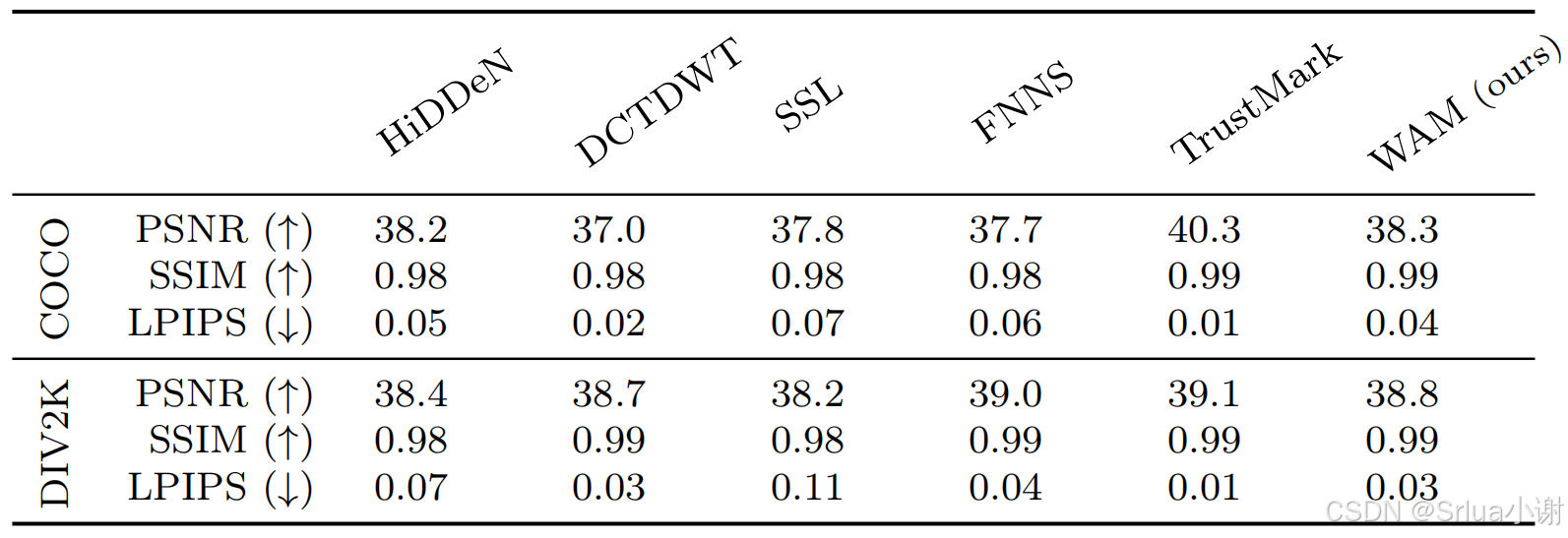
质量评估
- 指标:PSNR、SSIM和LPIPS用于评估水印嵌入后的不可感知性。这些指标衡量了水印图像与原始图像在视觉上的差异。
- 结果:文章提供了在COCO和DIV2K数据集上评估的结果,显示WAM在保持较高PSNR的同时,也能保持较低的LPIPS值,表明水印的嵌入对图像的视觉质量影响较小。
定位评估
- 方法:评估WAM在定位水印区域的准确性,使用交并比(IoU)来衡量预测的水印区域与真实水印区域的重叠程度。
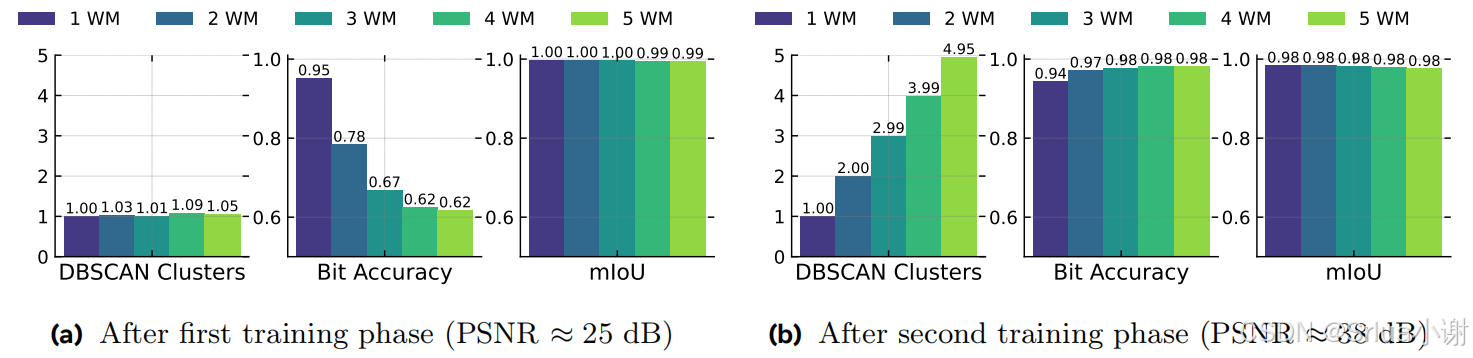
- 结果:文章展示了在不同水印面积下,WAM在定位水印区域的准确性,以及通过定位得到的比特准确率。
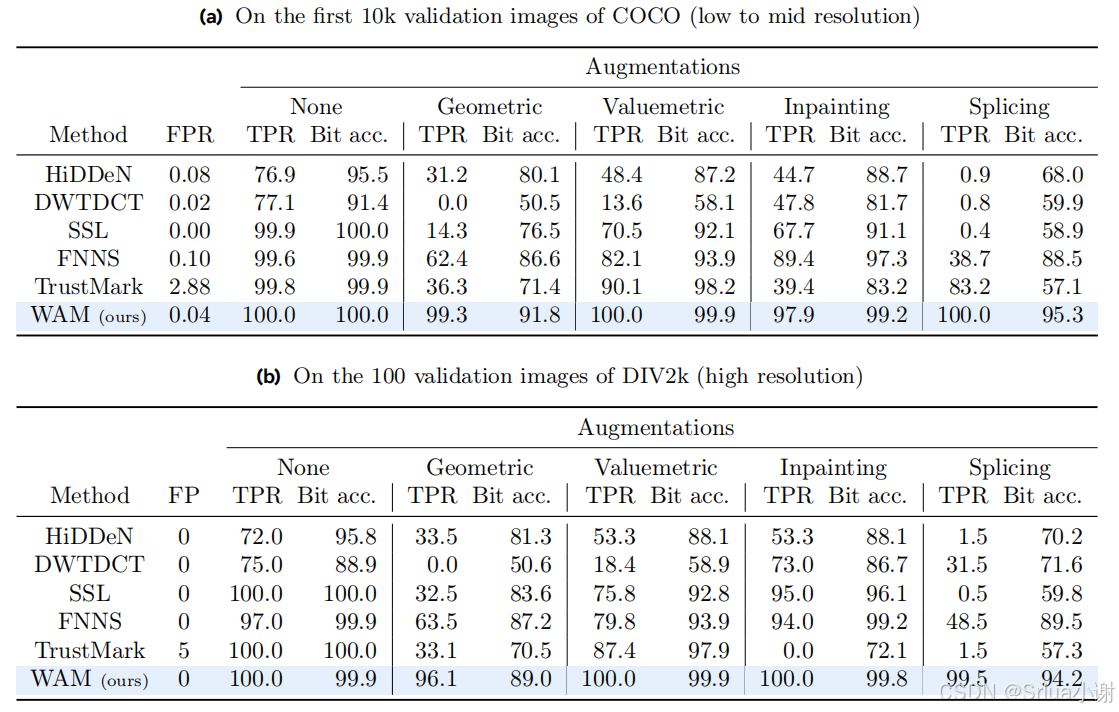
多个水印评估
- 方法:评估WAM在处理单个图像中的多个水印时的性能。通过在图像的不同区域嵌入不同的消息,并使用DBSCAN算法来检测和解码这些消息。
- 结果:文章提供了在不同数量的水印和不同水印面积下的检测和解码结果,展示了WAM在处理多个水印时的准确性和鲁棒性。

技术细节
使用DBSCAN算法提取多个水印
DBSCAN算法在WAM中被用于从图像中提取多个水印。以下是使用DBSCAN算法提取多个水印的详细步骤:
-
初始化DBSCAN算法参数:ϵϵ 是两个样本点被认为是邻居的最大距离,min_samples是一个簇被认为是有效簇所需的最小样本点数量。
-
局部解码消息:在WAM中,每个被识别为水印像素的像素都会产生一个局部解码消息(一个二进制字符串)。这些局部解码消息是DBSCAN算法的输入点。
-
寻找邻居:对于每个局部解码消息,DBSCAN算法会在 ϵϵ 距离内寻找所有其他局部解码消息,形成每个点的邻域。
-
形成簇:如果一个点的邻域包含至少min_samples个点,则围绕这个点形成一个簇,如果邻域中的点数少于min_samples,则将该点标记为噪声。
-
扩展簇:对于簇中的每个点 qq,找到所有在 ϵϵ 距离内的点,并将这些点添加到簇中,如果它们尚未被包含在内。
-
重复步骤3-5:继续扩展簇,直到没有更多的点可以添加。
-
标记簇:为数据集中的每个点分配一个标签,指示它属于哪个簇(如果有)。
DBSCAN算法会输出一些中心点和每个被识别为水印像素的像素的分配。这些中心点代表最终解码的消息,它们是二进制单词。
在WAM的训练过程中,可能会在同一图像中嵌入多个不同的水印。使用DBSCAN算法,可以不需要预先知道隐藏消息的数量,就能从局部解码消息中识别出不同的水印区域。
处理多水印和高分辨率图像
多水印
WAM处理多水印的关键在于其训练过程和提取器的设计,使其能够识别和解码图像中的多个独立水印。以下是处理多水印的具体步骤:
-
多水印训练策略:
在训练阶段,WAM使用多个随机消息和掩码来模拟图像中可能存在的多个水印。这些掩码可以是矩形、不规则形状或基于图像分割的掩码。每个掩码对应一个独特的消息,并且这些掩码可以随机地放置在图像的不同区域,以模拟多个水印的存在。 -
掩码的随机性:
在第二阶段训练中,WAM引入多个不重叠的掩码,每个掩码隐藏一个不同的水印消息。这种方法允许模型学习如何在同一个图像中区分和解码多个水印。 -
提取器的像素级输出:
提取器为每个像素输出一个 (1+nbits)(1+nbits) 维向量,其中 nbitsnbits 是水印消息的位数。这个输出包括一个水印检测分数和一个解码消息。 -
DBSCAN聚类算法:
提取器的输出被送入DBSCAN聚类算法,该算法根据像素级的二进制字符串将图像分割成多个区域,每个区域对应一个水印。
高分辨率
WAM通过固定分辨率操作和插值技术来处理高分辨率图像,以下是具体步骤:
-
固定分辨率操作:
WAM在固定分辨率下训练和操作,通常是较低的分辨率,以减少计算量和训练成本。 -
各向异性缩放:
对于高分辨率图像,WAM使用各向异性缩放将图像调整到训练时的固定分辨率。这样可以保持水印嵌入和提取过程的一致性。 -
双线性插值:
在嵌入阶段,WAM将低分辨率下生成的水印信号通过双线性插值扩展到高分辨率图像。这种插值方法能够在不同尺度之间平滑地过渡水印信号。 -
提取阶段的一致性:
在提取阶段,所有图像(无论原始分辨率如何)都被调整到固定分辨率,以确保提取过程与训练条件一致。
JND图
Just-Noticeable-Difference(JND)图是一种模拟人眼视觉系统的敏感度的模型,它用于确定图像中每个像素的最大可感知变化量。
JND图的基本原理
JND图基于两个主要的视觉现象:亮度适应(Luminance Adaptation,LA)和对比度掩蔽(Contrast Masking,CM)。
-
亮度适应(LA):人眼在明亮区域对细节的敏感度较低。亮度适应反映了人眼对不同亮度水平的适应性,即在较亮的区域,人眼对变化的敏感度降低。
-
对比度掩蔽(CM):在高对比度区域,人眼对小的变化不太敏感。对比度掩蔽考虑了图像中的局部对比度,即在边缘和纹理区域,人眼对细节的变化不太敏感。
JND图的计算
JND图的计算通常涉及以下步骤:
-
亮度核(Luminance Kernel):计算图像的局部背景亮度,使用一个固定的核来对像素周围的邻域进行平均。公式如下,其中 KlumKlum 是一个预定义的核,用于计算亮度。
B(x)(i,j)=132∑k,l∈[−2,2]2Klum(k,l)⋅x(i+k,j+l)B(x)(i,j)=321k,l∈[−2,2]2∑Klum(k,l)⋅x(i+k,j+l)
-
亮度适应(LA):根据亮度核的结果,计算每个像素的亮度适应值。使用一个非线性变换,以模拟人眼对亮度的非线性响应。公式如下,其中 ϵϵ 是一个用于确保反向传播可微分的小正值。
LA(x)(i,j)={17(1−B(x)(i,j)127+ϵ)+3,if B(x)(i,j)≤1273128⋅(B(x)(i,j)−127)+3,if B(x)(i,j)>127LA(x)(i,j)={17(1−127+ϵB(x)(i,j))+3,1283⋅(B(x)(i,j)−127)+3,if B(x)(i,j)≤127if B(x)(i,j)>127
-
梯度核(Gradient Kernel):计算图像的梯度幅度,使用水平和垂直的Sobel算子来估计。公式如下,其中 KXKX 和 KYKY 分别是水平和垂直的梯度核。
C(x)(i,j)=(∑k,lKX(k,l)⋅x(i+k,j+l))2+(∑k,lKY(k,l)⋅x(i+k,j+l))2C(x)(i,j)=⎝⎜⎛k,l∑KX(k,l)⋅x(i+k,j+l)⎠⎟⎞2+⎝⎜⎛k,l∑KY(k,l)⋅x(i+k,j+l)⎠⎟⎞2
-
对比度掩蔽(CM):根据梯度核的结果,计算每个像素的对比度掩蔽值。这同样涉及到一个非线性变换,以模拟人眼对对比度的非线性响应。公式如下。
CM(x)=16⋅C(x)2.4C(x)2+262CM(x)=16⋅C(x)2+262C(x)2.4
-
JND热图(JND Heatmap):结合亮度适应和对比度掩蔽的值,生成JND热图。这个热图表示了图像中每个像素的最大可感知变化量。公式如下,其中 γγ 是一个控制亮度适应和对比度掩蔽之间权衡的参数。
H(x)=LA(x)+CM(x)−γ⋅min(LA(x),CM(x))H(x)=LA(x)+CM(x)−γ⋅min(LA(x),CM(x))


可以看到,使用JND图调制水印强度的图像,相较于不使用JND图,与原始图像具有更小的差异,不使用JND图的水印图像有明显的噪声。
实验与结果
我们的实验部署配置如下:
GPU 3090 * 4
Ubuntu 20.04
PyTorch 2.1.2
Python 3.10
Cuda 11.8
推理代码解读
# 导入所需的库
import os
import numpy as np
from PIL import Image
import torch
import torch.nn.functional as F
from torchvision.utils import save_image
# 导入特定于项目的函数和类
from watermark_anything.data.metrics import msg_predict_inference
from notebooks.inference_utils import (
load_model_from_checkpoint,
default_transform,
create_random_mask,
unnormalize_img,
plot_outputs,
msg2str
)
# 检测是否有可用的CUDA设备,如果没有则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义一个函数来加载图像
def load_img(path):
# 使用PIL库打开图像,并将其转换为RGB格式
img = Image.open(path).convert("RGB")
# 应用默认的图像转换
img = default_transform(img).unsqueeze(0).to(device)
return img
# 从指定的检查点加载模型
exp_dir = "checkpoints"
json_path = os.path.join(exp_dir, "params.json")
ckpt_path = os.path.join(exp_dir, 'checkpoint.pth')
wam = load_model_from_checkpoint(json_path, ckpt_path).to(device).eval()
# 设置随机种子以确保结果的可重复性
seed = 42
torch.manual_seed(seed)
# 设置参数
img_dir = "assets/images" # 包含原始图像的目录
num_imgs = 2 # 从文件夹中水印图像的数量
proportion_masked = 0.5 # 图像被水印的比例(0.5表示50%的图像)
# 创建输出文件夹
output_dir = "outputs"
os.makedirs(output_dir, exist_ok=True)
# 定义一个32位的消息,将其嵌入到图像中
wm_msg = wam.get_random_msg(1) # [1, 32]
print(f"Original message to hide: {msg2str(wm_msg[0])}")
# 遍历目录中的每个图像
for img_ in os.listdir(img_dir)[:num_imgs]:
# 加载并预处理图像
img_pt = load_img(os.path.join(img_dir, img_)) # [1, 3, H, W]
# 将水印信息嵌入到图像中
outputs = wam.embed(img_pt, wm_msg)
# 创建一个随机掩码,只水印图像的一部分
mask = create_random_mask(img_pt, num_masks=1, mask_percentage=proportion_masked) # [1, 1, H, W]
img_w = outputs['imgs_w'] * mask + img_pt * (1 - mask) # [1, 3, H, W]
# 在水印图像中检测水印
preds = wam.detect(img_w)["preds"] # [1, 33, 256, 256]
mask_preds = F.sigmoid(preds[:, 0, :, :]) # [1, 256, 256], 预测掩码
bit_preds = preds[:, 1:, :, :] # [1, 32, 256, 256], 预测比特
# 预测嵌入的消息并计算比特准确率
pred_message = msg_predict_inference(bit_preds, mask_preds).cpu().float() # [1, 32]
bit_acc = (pred_message == wm_msg).float().mean().item()
# 保存水印图像和检测掩码
mask_preds_res = F.interpolate(mask_preds.unsqueeze(1), size=(img_pt.shape[-2], img_pt.shape[-1]), mode="bilinear", align_corners=False) # [1, 1, H, W]
save_image(unnormalize_img(img_w), f"{output_dir}/{img_}_wm.png")
save_image(mask_preds_res, f"{output_dir}/{img_}_pred.png")
save_image(mask, f"{output_dir}/{img_}_target.png")
plot_outputs(img_pt.detach(), img_w.detach(), mask.detach(), mask_preds_res.detach(), labels = None, centroids = None)
# 打印每张图像的预测消息和比特准确率
print(f"Predicted message for image {img_}: {msg2str(pred_message[0])}")
print(f"Bit accuracy for image {img_}: {bit_acc:.2f}")
实验结果展示
我们以下面的图像为例,添加的水印编码为01000100010000101110101111111100。

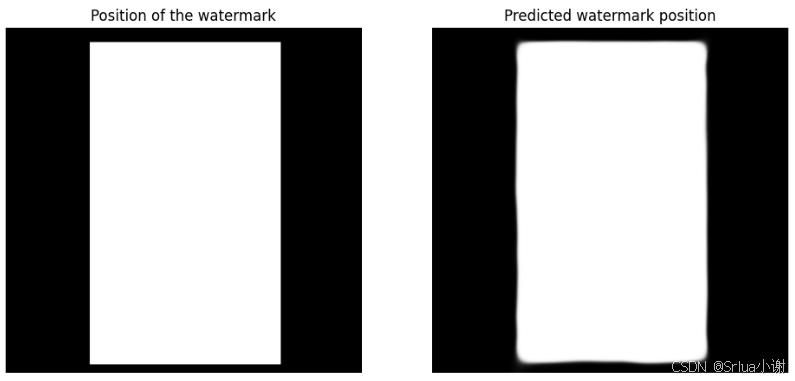
下图是嵌入水印部分的图像掩码与提取器预测的图像区域,提取器基本可以完全预测出水印位置,且提取的水印的比特准确率为100%。
我们将原始图像、水印图像和两图像的差异进行对比,可以看到,两图像在添加水印的掩码处存在差异,但原始图像与水印图像几乎不能用肉眼分辨出差异,算法具有良好的不可见性。

我们在图像中嵌入两个水印进行进一步的测试,并进行掩码和聚类的可视化,得到了如下的结果。

上图嵌入的水印为11101000001111101101010110000000和01101111010111010101001011111111,提取到的水印为11101000001111101101010110000000和11101111010111010101001011011111,比特准确率分别为100%和93.75%。

上图嵌入的水印为11101000001111101101010110000000和01101111010111010101001011111111,提取到的水印为11101000001111101101010110000000和01101111010111010101001011111111,比特准确率分别为100%和100%。
总结
本文介绍了一种名为Watermark Anything Model (WAM)的深度学习模型,用于实现局部图像水印技术。WAM能够在保持图像不可见性的同时,对输入图像进行修改,并在接收到的图像中分割出水印和非水印区域,从而恢复隐藏的信息。
该模型经过两阶段训练,首先在低分辨率下进行训练以实现鲁棒性,然后在高分辨率下进行微调以提高不可见性,并能够处理多个水印。实验结果表明,WAM在不可见性和鲁棒性方面与现有最先进方法相当,特别是在对抗图像修复和拼接方面表现出色,即使在高分辨率图像上也能准确地定位水印区域,并从多个小区域中提取不同的32位消息。
总体而言,这篇论文提出了一种新的图像水印方法,能够在保持不可见性的同时提供对编辑操作的鲁棒性,并引入了定位和提取多个水印的新功能,为图像水印领域带来了新的视角和技术进步。
我们在附件中,在论文原代码的基础上,实现了一键的训练、推理、可视化,由于COCO数据集较大,因此读者若要自行训练模型,需下载COCO数据集。


















 7952
7952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









