










任务目录
- 什么是Machine learning
- 学习中心极限定理,学习正态分布,学习最大似然估计
- 推导回归Loss function
- 学习损失函数与凸函数之间的关系
- 了解全局最优和局部最优
- 学习导数,泰勒展开
- 推导梯度下降公式
- 写出梯度下降的代码
- 学习L2-Norm,L1-Norm,L0-Norm
- 推导正则化公式
- 说明为什么用L1-Norm代替L0-Norm
- 学习为什么只对w/Θ做限制,不对b做限制
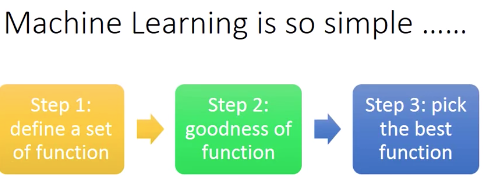
Question 1:What is Machine Learning?
≈Looking for a function from Data
(看李宏毅机器学习P1,P2部分截图)




知识点1:中心极限定理

通俗理解就是:
中心极限定理是说:
样本的平均值约等于总体的平均值。
不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的整体平均值周围,并且呈正态分布,只要样本足够大。
知识点2:正态分布

正态分布的应用非常广泛,而且很多的现实数据都呈正态分布,比如一个地区的人的身高,体重,工资等。
知识点3:最大似然估计
极大似然估计方法(Maximum Likelihood Estimate,MLE)也称为最大概似估计或最大似然估计,是求估计的另一种方法



知识点4:推导回归Loss function

对于线性回归模型,我们的一个基本假设是,对于各个样本点来说,ϵ是独立同分布的,这样,根据独立同分布的中心极限定理,当样本点很多时,ϵ应该服从均值为0,方差为σ^2的高斯分布。注意!这是我们进行以下推导的前提,如果在实际项目中该假设不成立,则我们的结论也不成立,整个线性回归问题的算法将会被推翻。


知识点5:损失函数与凸函数之间的关系
如果损失函数是凸函数(convex)的话,那么梯度下降就一定能达到全局最优解,不管从什么位置开始迭代。
如,线性回归:

知识点6:全局最优和局部最优
损失函数在梯度下降的过程中,可能会下降到局部最优点,即其值小于最小值点,但是又是极小值点。如图所示:
全局最优则是函数的最小值。如果函数为凸函数的话,那么梯度下降就可以避免这个问题,所以我们偏好凸函数作为损失函数。

知识点7:导数,泰勒展开
导数(Derivative),也叫导函数值。又名微商,是微积分中的重要基础概念。当函数y=f(x)的自变量x在一点x0上产生一个增量Δx时,函数输出值的增量Δy与自变量增量Δx的比值在Δx趋于0时的极限a如果存在,a即为在x0处的导数,记作f'(x0)或df(x0)/dx。
导数是函数的局部性质。一个函数在某一点的导数描述了这个函数在这一点附近的变化率。如果函数的自变量和取值都是实数的话,函数在某一点的导数就是该函数所代表的曲线在这一点上的切线斜率。导数的本质是通过极限的概念对函数进行局部的线性逼近。例如在运动学中,物体的位移对于时间的导数就是物体的瞬时速度。
泰勒展开式:

知识点8:推导梯度下降公式

知识点9:写出梯度下降的代码
def batchGradientDescent(x, y, theta, alpha, m, maxIterations):
xTrains = x.transpose()
for i in range(0, maxIterations):
hypothesis = np.dot(x, theta)
loss = hypothesis - y
# print loss
gradient = np.dot(xTrains, loss) / m
theta = theta - alpha * gradient
return theta知识点10:学习L2-Norm,L1-Norm,L0-Norm
正则化:用来解决过拟合问题,以及特征的选取

知识点11:推导正则化公式

知识点12:说明为什么用L1-Norm代替L0-Norm
虽然L0正则优势很明显,但求解困难属于NP问题,因此一般情况下引入L0正则的最近凸优化L1正则(方便求解)来近似求解并同样可实现稀疏效果。
知识点13:学习为什么只对w/Θ做限制,不对b做限制
因为b(bias)只是让函数值上下移动,它是一个常数,所以不会改变函数的全局最优的点,所以没必要限制b。
参考资料:百度百科
https://blog.csdn.net/winone361/article/details/82555283
https://blog.csdn.net/Crafts_Neo/article/details/90142517















 5820
5820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









