







2 单变量线性回归
2.1 模型描述
下面将根据第一章提到的预测房价的例子来继续后面的内容。
记号约定
在监督学习中有一个数据集,这个数据集被称训练集。在整个课程中将用 m m m来表示训练样本的数量。
用 x x x表示输入变量(特征),用 y y y表示输出变量(要预测的目标变量)。
用 ( x , y ) (x,y) (x,y)表示一个训练样本,用 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i))表示第 i i i个训练样本,需要注意的是上标 i i i不是指数,而是数据集的一个索引。
监督学习算法的工作过程
向学习算法提供训练集,学习算法的任务是输出一个假设函数,通常用 h h h表示。
假设函数的作用是预测输入对应的输出。
假设函数
设计学习算法首先需要决定如何表示假设函数 h h h。
一种可能的表达方式为, h θ ( x ) = θ 0 + θ 1 x h_{\theta}(x)=\theta_{0}+\theta_{1} x hθ(x)=θ0+θ1x。这意味接下来这个假设函数将预测 y y y关于 x x x的线性函数。
因为只含有一个特征/输入变量,且是线性的,因此这样的回归问题叫作一元线性回归问题或单变量线性回归问题。
总结
监督学习的工作过程是,通过向学习算法提供训练集,学习算法输出一个假设函数 h h h。
在这里我们先将假设函数 h h h视为一个线性函数。
2.2 代价函数
代价函数是为了找到与数据拟合得最好的直线。
模型参数
对于假设函数 h θ ( x ) = θ 0 + θ 1 x h_{\theta}(x)=\theta_{0}+\theta_{1} x hθ(x)=θ0+θ1x, θ 0 \theta_{0} θ0和 θ 1 \theta_{1} θ1是模型参数。
平方误差函数
通过代价函数,可以找到一条和数据拟合得比较好的线,从而可以求得能够使建模误差最小的模型参数。
通常可以用平方误差函数 J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left(\theta_{0}, \theta_{1}\right)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2} J(θ0,θ1)=2m1∑i=1m(hθ(x(i))−y(i))2作为代价函数,对于大多数问题,特别是回归问题,平方误差代价函数都是一个合理的选择,当然也有其他类型的代价函数。
我们的优化目标便是为了使得代价函数最小。
总结
对于假设函数 h θ ( x ) = θ 0 + θ 1 x h_{\theta}(x)=\theta_{0}+\theta_{1} x hθ(x)=θ0+θ1x, θ 0 \theta_{0} θ0和 θ 1 \theta_{1} θ1是模型参数。
通常可以用平方误差函数作为代价函数,从而可以求得能够使建模误差最小的模型参数。
2.3-2.4 代价函数的直观理解
假设函数和代价函数
| 假设函数 h θ i ( x ) h_{\theta_{i}}(x) hθi(x) | 代价函数 J ( θ i ) J(\theta_{i}) J(θi) | |
|---|---|---|
| 自变量 | 对于给定的 θ \theta θ, h h h是关于 x x x的函数 | J J J是关于 θ \theta θ的函数 |
| 函数图像 | 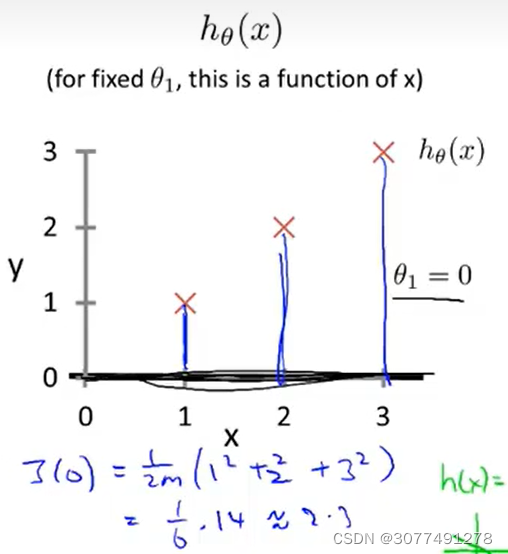 | 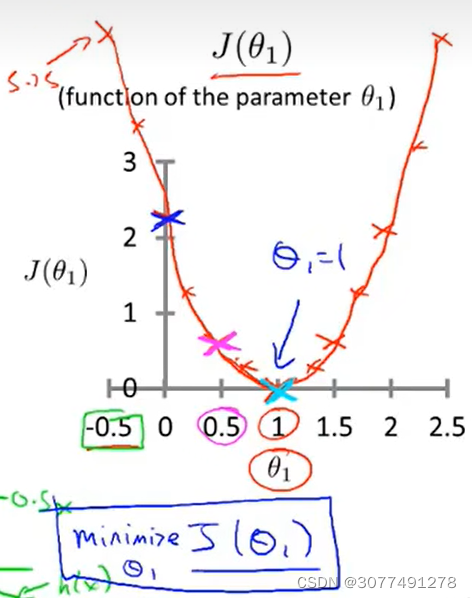 |
2.5-2.6 梯度下降法
梯度下降法
梯度下降法是一个用来求函数最小值的算法,可以用这种方法来最小化代价函数。
首先随机选择一个参数的组合计算代价函数,然后寻找下一个能让代价函数值下降最多的参数组合。持续这么做直到到到一个局部最小值(local minimum)。
因为没有尝试完所有的参数组合,所以不能确定找到的局部最小值是否便是全局最小值(global minimum)。
选择不同的初始参数组合,可能会找到不同的局部最小值。
梯度下降法的数学原理
重复直至收敛 {
θ
j
:
=
θ
j
−
α
∂
∂
θ
j
J
(
θ
0
,
θ
1
)
(for
j
=
0
and
j
=
1
)
\theta_{j}:=\theta_{j}-\alpha \frac{\partial}{\partial \theta_{j}} J\left(\theta_{0}, \theta_{1}\right) \quad \text { (for } j=0 \text { and } j=1 \text { ) }
θj:=θj−α∂θj∂J(θ0,θ1) (for j=0 and j=1 )
}
需要说明的是 : = := :=表示赋值运算符,而 = = =表示左值和右值相等。
α \alpha α是学习率,用来控制梯度下降时的步长。
需要说明的是参数 θ 0 \theta_{0} θ0和 θ 1 \theta_{1} θ1需要同步更新,即应该先计算公式右边的部分存入临时变量中,然后用临时变量同时更新 θ 0 \theta_{0} θ0和 θ 1 \theta_{1} θ1。
梯度下降法的理解
如果 α \alpha α过小,则需要很多步才能到达局部最低点;如果 α \alpha α过大,则可能无法收敛。
并且,随着梯度下降法的运行,导数值会变得越来越小,移动的幅度会变得越来越小,直至收敛到局部最小值,在局部最优点,导数值为0,因此没有必要再另外减小 α \alpha α的值。
总结
梯度下降法是一个用来求函数最小值的算法,可以用这种方法来最小化代价函数。
α \alpha α是学习率,用来控制梯度下降时的步长。
随着梯度下降法的运行,导数值会变得越来越小,移动的幅度会变得越来越小,直至收敛到局部最小值。
2.7 线性回归的梯度下降
线性回归代价函数的局部最优解就是全局最优解
用不同的值进行初始化可能会导致收敛到不同的局部最优解,而收敛到的局部最优解可能不是全局最优解。
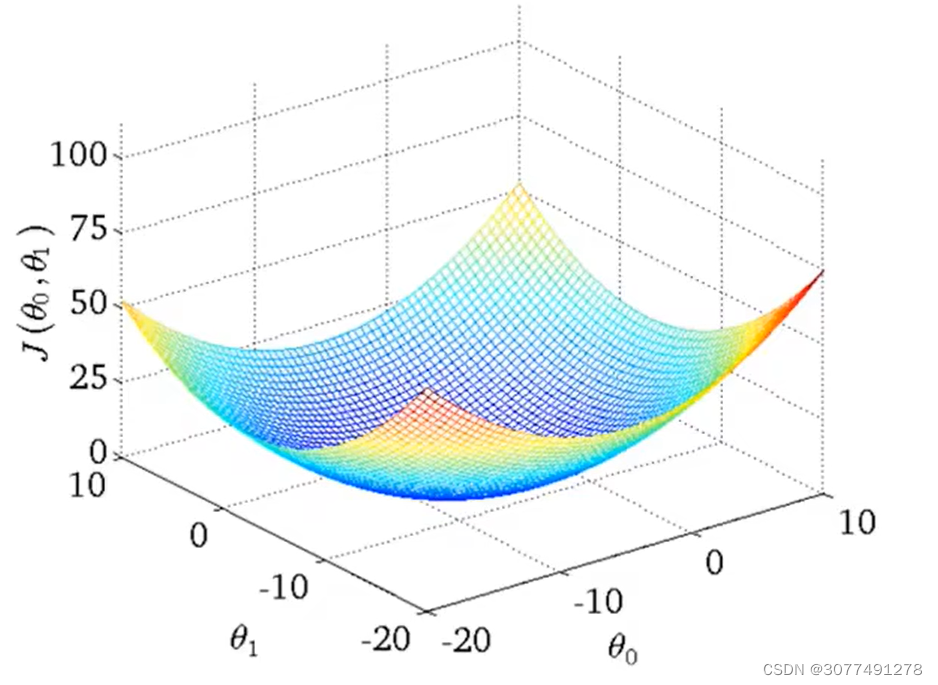
但如上图所示,线性回归的代价函数是凸函数,局部最优解就是全局最优解。
批量梯度下降法(Batch Gradient Descent)
梯度下降法也被称为批量梯度下降法(Batch Gradient Descent),意味着在梯度下降的每一步中,都用到了所有的训练样本。当计算偏导数时,计算的是所有训练样本单独的梯度下降之和。
总结
对线性回归的代价函数使用梯度下降法能够收敛到函数的全局最优解。
梯度下降法也被称为批量梯度下降法,在梯度下降的每一步中,计算的是所有训练样本单独的梯度下降之和。














 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









