






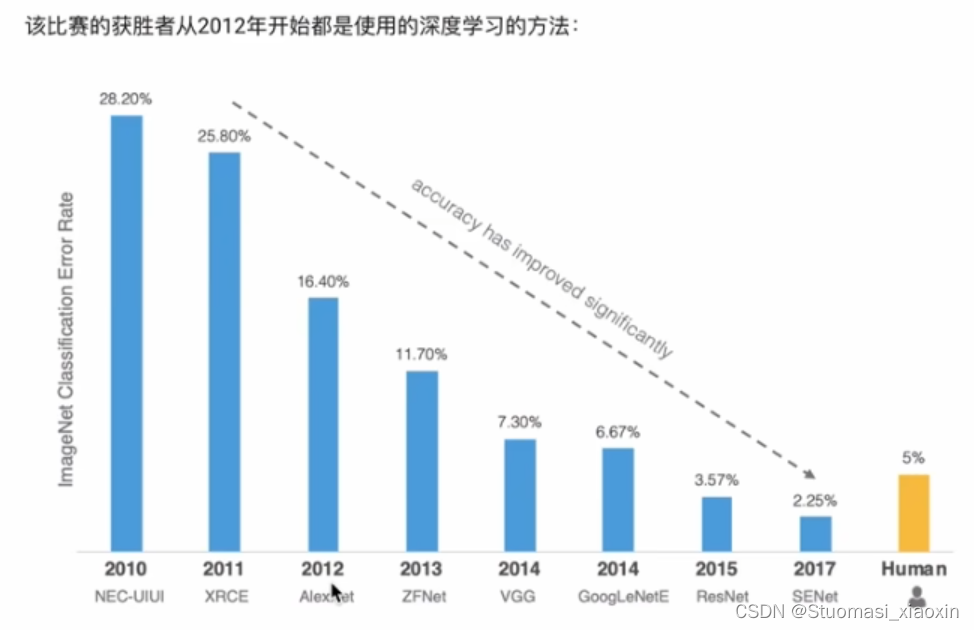

AlexNet网络介绍:
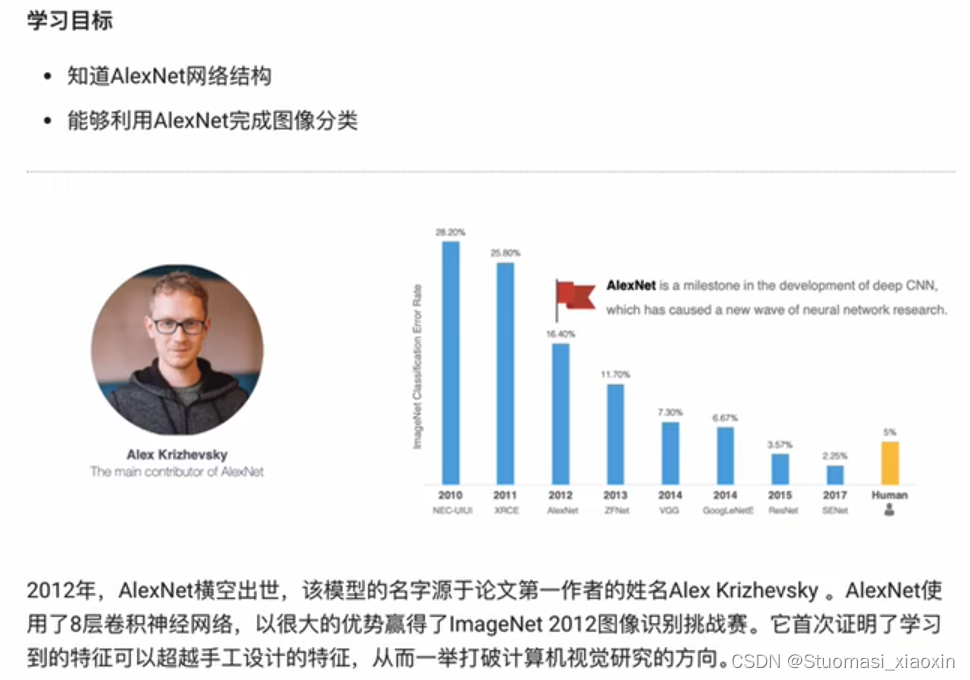

AlexNet网络的特点:
- 8层变换,有5层卷积和2层全连接隐藏层,以及1个全连接输出层
- 卷积核:11*11 5*5 3*3
- 池化: 3*3 stride 2
- 激活函数使用RELU
- dropOut作正则化
- 图像增强方法,提高数据量
池化层(降低维度):
- 最大池化:取窗口内的最大值作为输出
- 平均池化:窗口内的所有值的均值作为输出
全连接层(输出结果):
一般在CNN网络的末端
作用:将特征图reshape成一维向量,再送入至连接层中进行分类或回归
案例:
from tensorflow.keras.datasets import cifar10
(train_images,train_labels),(test_images,test_labels) = cifar10.load_data()
test_images.shape
train_images.shape
import matplotlib.pyplot as plt
plt.figure(figsize=(1,1))
plt.imshow(train_images[4])AlexNet网络代码:
import tensorflow as tf
# 模型构建
net = tf.keras.models.Sequential([
# 卷积层:96 11*11 4 relu
tf.keras.layers.Conv2D(filters=96,kernel_size=11,strides=4,activation="relu"),
# 池化: 3*3 2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2),
# 卷积:256 5*5 1 relu same
tf.keras.layers.Conv2D(filters=256,kernel_size=5,padding="same",activation="relu"),
# 池化: 3*3 2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2),
# 卷积:384 3*3 1 relu same
tf.keras.layers.Conv2D(filters=384,kernel_size=3,padding="same",activation="relu"),
# 卷积:384 3*3 1 relu same
tf.keras.layers.Conv2D(filters=384,kernel_size=3,padding="same",activation="relu"),
# 卷积:384 3*3 1 relu same
tf.keras.layers.Conv2D(filters=256,kernel_size=3,padding="same",activation="relu"),
# 池化:3*3 2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2),
# 展开
tf.keras.layers.Flatten(),
# 全连接层:4096 relu
tf.keras.layers.Dense(4096,activation="relu"),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 输出层
tf.keras.layers.Dense(10,activation="softmax")
])
# 输出网络
X=tf.random.uniform((1,227,227,1))
y=net(X)
net.summary()Lenet-5网络:
网络构成 :
1.conv +pooling ...+FC
2. 数据的维度【B,H,W,C】
数据获取处理:
1.加载mnist
2.维度调整:添加一个通道维
3.模型构建:2个卷积+池化,flatten+FC
4.模型编译: Loss,opt,metric
5.模型训练:model.fit(data,epochs,batch_size...)
6.模型评估:net.evalute()
开源数据集:{mnist、Cifar10/cifar100、ImageNet(数据量大、作为网络的预训练数据集、Alexnet、VGG、GooLenet、Resnet)}
import tensorflow as tf
net = tf.keras.models.Sequential([
# 卷积层:96 11*11 4 relu 个数 大小 步幅 激活函数
tf.keras.layers.Conv2D(filters=96,kernel_size=11,strides=4,activation="relu"),
# 池化:3*3 2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2),
# 卷积:256 5*5 1 relu same
tf.keras.layers.Conv2D(filters=256,kernel_size=5,padding="same",activation="relu"),
# 池化: 3*3 2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2),
# 卷积:384 3*3 1 relu same
tf.keras.layers.Conv2D(filters=384,kernel_size=3,padding="same",activation="rele"),
# 卷积:384 3*3 1 relu same
tf.keras.layers.Conv2D(filters=384, kernel_size=3, padding="same", activation="rele"),
# 卷积:256 3*3 1 relu same
tf.keras.layers.Conv2D(filters=256,kernel_size=3,padding="same",activation="rele"),
# 池化:3*3 2
tf.keras.layers.MaxPool2D(pool_size=3,strides=2),
# 展开
tf.keras.layers.Flatten(),
# 全连接层
tf.keras.layers.Dense(4096,activation="relu"),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 全连接层
tf.keras.layers.Dense(4096, activation="relu"),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 输出层:
tf.keras.layers.Dense(10,activation="softmax")
])
X = tf.random.uniform((1,227,227,1))
y = net(X)
net.summary()P7 导入其思维导图
手写数字识别:
- 数据加载和处理 — 维度调整:N、H、W、C 尺寸调整: resize
- 模型训练 编译,compile fit()
- 模型评估: evalute
VGGNet网络:
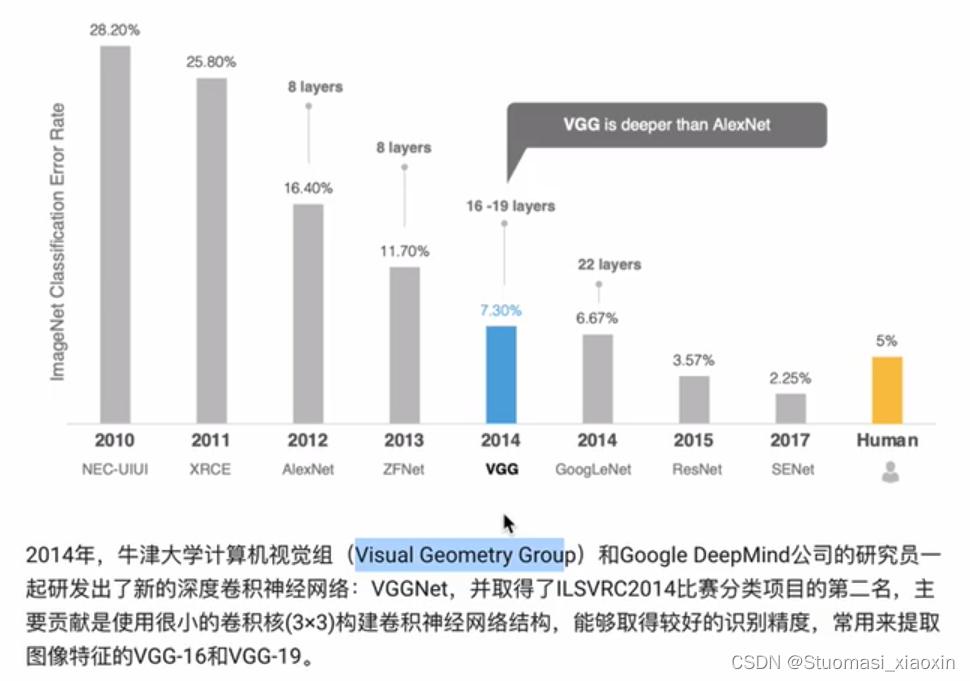 VGG-16和VGG-19 表示网络中卷积层和全连接层的个数
VGG-16和VGG-19 表示网络中卷积层和全连接层的个数
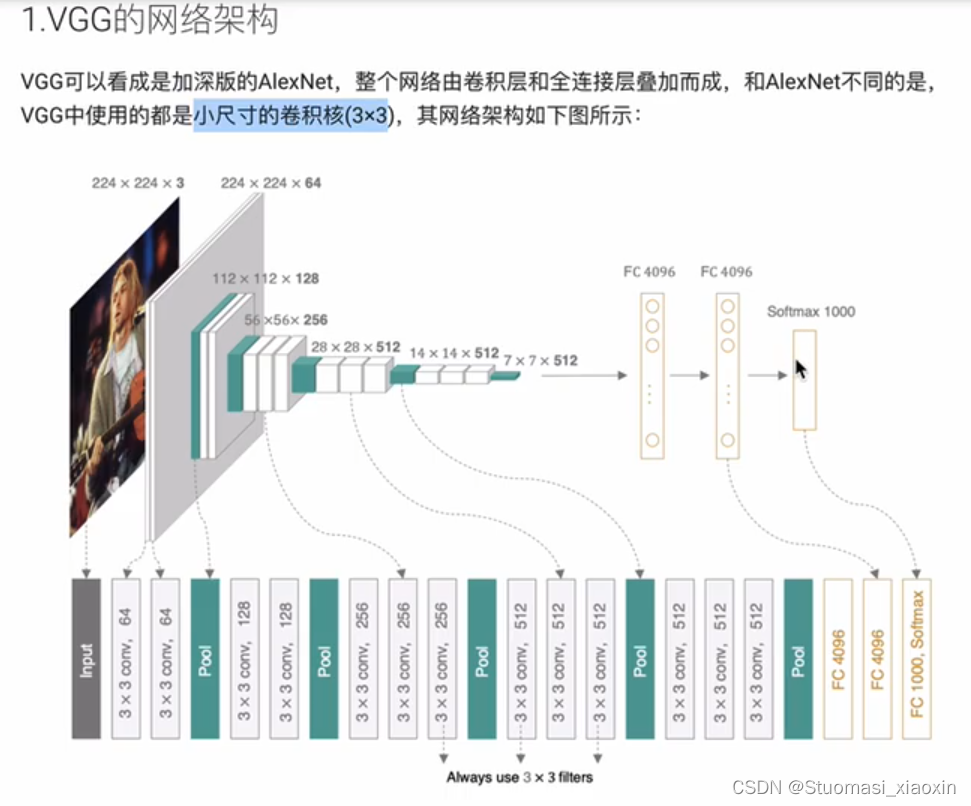





VGG网络代码:
# 1 VGG网络构建
import tensorflow as tf
#1.1 VGG块的构建
def vgg_block(num_conv,num_filters):
# 序列模型
blk = tf.keras.models.Sequential()
# 遍历卷积层
for _ in range(num_conv):
# 设置卷积层
blk.add(tf.keras.layers.Conv2D(num_filters,kernel_size=3,padding='same',activation="relu"))
# 池化层
blk.add(tf.keras.layers.MaxPooling2D(pool_size=2, strides=2))
return blk
# 2 模型构建
def vgg(conv_arch):
# 序列模型
net = tf.keras.models.Sequential()
# 生成卷积部分
for (num_conv,num_filters) in conv_arch:
net.add(vgg_block(num_conv,num_filters))
# 全连接层
net.add(tf.keras.models.Sequential([
# 展评
tf.keras.layers.Flatten(),
# 全连接层
tf.keras.layers.Dense(4096,activation="relu"),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 全连接层
tf.keras.layers.Dense(4096,activation="relu"),
# 随机失活
tf.keras.layers.Dropout(0.5),
# 输出层
tf.keras.layers.Dense(10,activation="softmax")
]))
return net
# 卷积块参数
conv_arch = ((2,64),(2,128),(3,256),(3,512),(3,512))
net = vgg(conv_arch)
X=tf.random.uniform((1,224,224,1))
y=net(X)
net.summary()模型:

# 2、数据获取
import numpy as np
from tensorflow.keras.datasets import mnist
# 获取手写数字数据集
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
# 训练集数据维度的调整:N H W C
train_images = np.reshape(train_images,(train_images.shape[0],train_images.shape[1],train_images.shape[2],1))
# 测试集数据维度的调整:N H W C
test_images = np.reshape(test_images,(test_images.shape[0],test_images.shape[1],test_images.shape[2],1))
# 定义两个方法随机抽取部分样本演示
# 获取训练数据
def get_train(size):
# 随机生成要抽样的样本索引
index = np.random.randint(0,np.shape(train_images)[0],size)
# 将这些数据resize成22*227大小
resized_images = tf.image.resize_with_pad(train_images[index],224,224)
# 返回抽取的
return resized_images.numpy(),train_labels[index]
# 获取测试集数据
def get_test(size):
# 随机生成要抽样的样本的索引
index = np.random.randint(0, np.shape(test_images)[0], size) # 修正此处的拼写错误
# 将这些数据resize成224*224大小
resized_images = tf.image.resize_with_pad(test_images[index], 224, 224) # 修正此处的变量名错误
# 返回抽样的测试样本
return resized_images.numpy(), test_labels[index] # 修正此处的变量名错误
# 获取训练样本和测试样本
train_images,train_labels = get_train(256)
test_images,test_labels = get_test(128)
# 3 模型编译
# 指定优化器,损失函数和评价指标
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01,momentum=0.0)
net.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 4 模型训练:指定训练数据,batchsize,epoch,验证集
net.fit(train_images,train_labels,batch_size=128,epochs=3,verbose=1,validation_split=0.1)
# 5 模型评估
# 指定测试数据
net.evaluate(test_images,test_labels,verbose=1)模型训练:
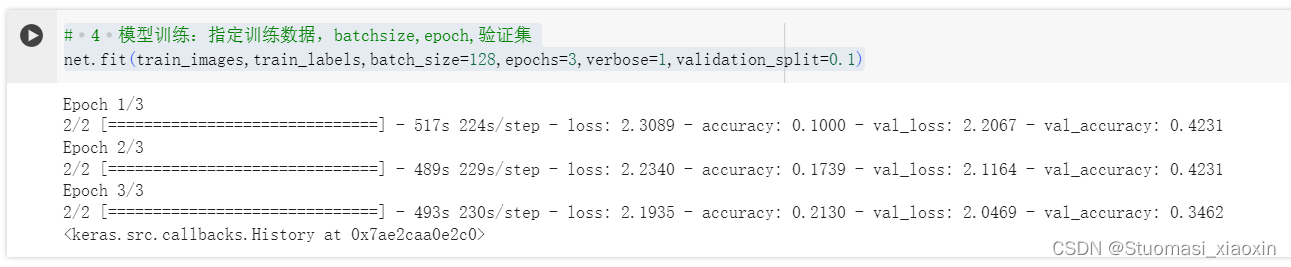
模型评估:

VGG: 证明使用小的卷积核:3*3也可以获得很好的精度
特点:
- 使用的都是小尺寸的卷积核(3*3,padding=same,relu),相对于alexnet层数更多
- 多个VGG块由卷积+Pooling完成
实现:
- 构建VGG块
- 将VGG块串联在一起,并加上全连接层来构建整个网络
GoogLeNet网络:
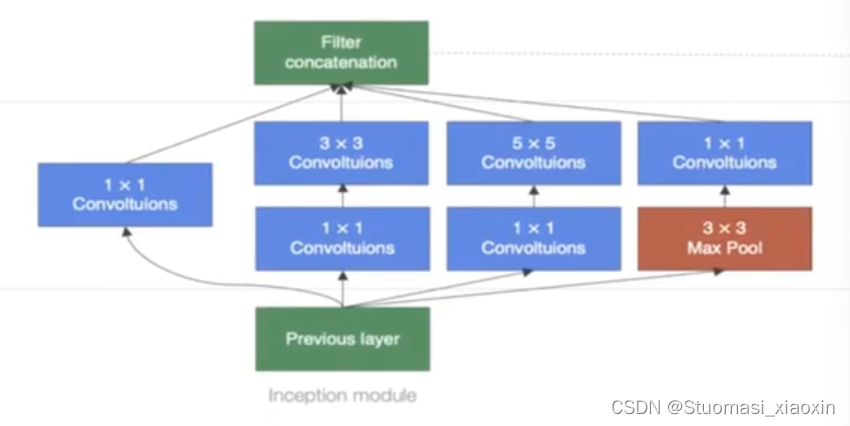

加深度的同时做了结构上,增加了网络的宽度
Inception




















 1397
1397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











