







目录
引言
在当今的人工智能领域,深度学习框架犹如搭建智能大厦的基石。TensorFlow 作为其中的佼佼者,凭借其强大的功能和广泛的应用场景,受到了众多开发者和研究人员的青睐。本文将深入介绍 TensorFlow 深度学习框架,并通过具体操作示例,帮助你快速上手。
一、TensorFlow 简介
(一)诞生与发展
TensorFlow 最初由 Google Brain 团队开发,于 2015 年开源。经过多年的发展,它已经成为了一个高度灵活且功能丰富的深度学习框架,广泛应用于各类机器学习算法的编程实现。
(二)特点
- 高度灵活性:TensorFlow 允许用户在 CPU、GPU 甚至是分布式系统上轻松构建和训练模型,无论是简单的线性回归还是复杂的卷积神经网络,都能游刃有余地处理。
- 可视化工具:TensorBoard 是 TensorFlow 自带的可视化工具,它可以帮助用户理解模型的训练过程,比如查看损失函数的变化趋势、可视化网络结构等。
- 社区支持:拥有庞大的开源社区,开发者可以在社区中获取丰富的文档、教程以及预训练模型,同时也能方便地与其他开发者交流经验,解决遇到的问题。
二、TensorFlow 基础概念
(一)张量(Tensor)
张量是 TensorFlow 中的核心数据结构,它可以理解为一个多维数组。0 维张量是标量(scalar),1 维张量是向量(vector),2 维张量是矩阵(matrix),更高维的张量则用于处理更复杂的数据结构,如在图像识别中,一张彩色图片可以表示为一个三维张量(长、宽、通道数)。
(二)计算图(Computational Graph)
TensorFlow 使用计算图来表示计算任务。计算图由节点(Node)和边(Edge)组成,节点表示操作(如加法、乘法等运算,或者是变量、占位符等),边则表示张量在操作之间的流动。在计算图中,先定义好计算流程,然后通过会话(Session)来执行计算图。
(三)会话(Session)
会话负责执行计算图中的操作。通过会话,我们可以将数据(以张量形式)输入到计算图中,并获取计算结果。在使用完会话后,需要及时关闭会话以释放资源,也可以使用 with 语句来自动管理会话的生命周期。
三、TensorFlow 操作使用
(一)安装 TensorFlow
在开始使用之前,需要先安装 TensorFlow。如果使用的是 Python 环境,可以通过 pip 进行安装。对于 CPU 版本,运行以下命令:
bash环境:
pip install tensorflow
如果需要使用 GPU 加速(前提是你的计算机具备支持的 GPU 及相应驱动),则安装 GPU 版本:
bash环境:
pip install tensorflow - gpu
(二)基础运算示例
- 导入 TensorFlow 库
python环境:
import tensorflow as tf
- 创建张量并进行运算
python环境:
import tensorflow as tf
# 创建两个常量张量
a = tf.constant([[1.0, 2.0], [3.0, 4.0]])
b = tf.constant([[5.0, 6.0], [7.0, 8.0]])
# 矩阵乘法运算
c = tf.matmul(a, b)
# 直接打印结果
print(c.numpy()) # 使用 .numpy() 将张量转换为 NumPy 数组
在上述代码中,首先创建了两个常量张量 a 和 b,然后定义了它们的矩阵乘法运算 c。最后通过会话 sess 来执行计算图,获取运算结果并打印。
(三)构建简单神经网络示例
以一个简单的手写数字识别任务为例,使用 TensorFlow 构建一个多层感知机(MLP)。
1. 导入必要的库
python环境:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
2. 加载和预处理数据
python环境:
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 将图像数据归一化到[0, 1]区间
train_images = train_images.reshape((-1, 28 * 28)).astype('float32') / 255.0
test_images = test_images.reshape((-1, 28 * 28)).astype('float32') / 255.0
# 将标签进行独热编码
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
3. 构建模型
python环境:
model = tf.keras.Sequential([
tf.keras.layers.Dense(512, activation='relu', input_shape=(28 * 28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
这里构建了一个包含两个全连接层的多层感知机,第一层有 512 个神经元,使用 ReLU 激活函数,第二层有 10 个神经元(对应 10 个数字类别),使用 softmax 激活函数用于输出概率分布。
4. 编译模型
python环境:
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
选择 RMSProp 优化器,分类交叉熵损失函数,并以准确率作为评估指标。
5. 训练模型
python环境:
model.fit(train_images, train_labels, epochs = 5, batch_size = 64)
使用训练数据对模型进行 5 个 epoch 的训练,每个 batch 大小为 64。
6. 评估模型
python环境:
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
在测试集上评估模型的性能,打印测试准确率。
(四)构建简单神经网络示例(完整代码Demo)
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 将图像数据归一化到[0, 1]区间
train_images = train_images.reshape((-1, 28 * 28)).astype('float32') / 255.0
test_images = test_images.reshape((-1, 28 * 28)).astype('float32') / 255.0
# 将标签进行独热编码
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 构建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(512, activation='relu', input_shape=(28 * 28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs = 5, batch_size = 64)
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)四、运行结果:
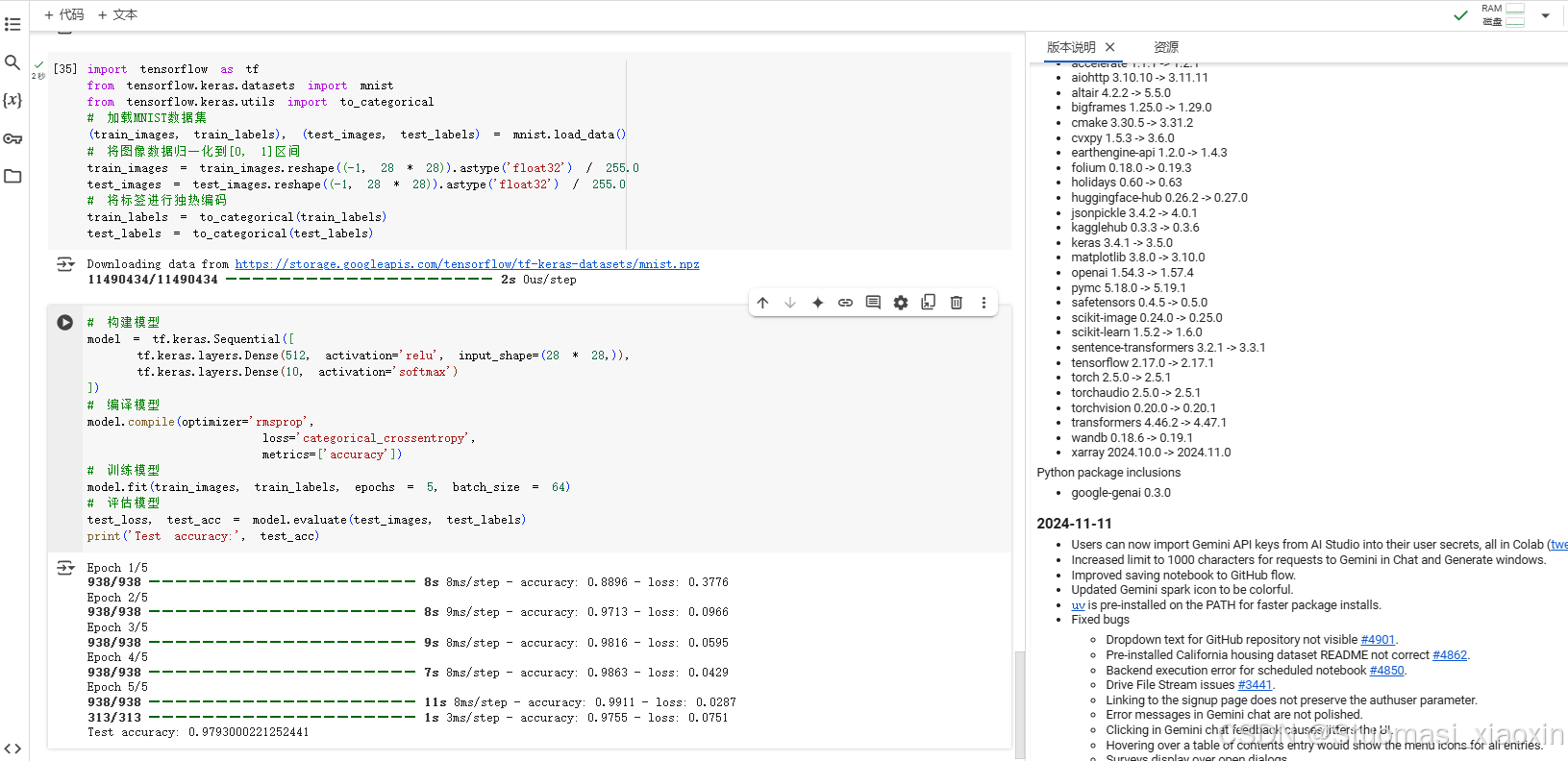
代码运行可自行在本地jupyter notebook、Pycharm或在线Colab运行!
五、总结
TensorFlow 作为一款功能强大的深度学习框架,为开发者提供了丰富的工具和灵活的编程模型,无论是初学者快速上手深度学习,还是研究人员进行复杂模型的开发,都能从中受益。通过本文的介绍和操作示例,希望你能对 TensorFlow 有更深入的理解,并在实际项目中灵活运用。在后续的学习中,可以进一步探索 TensorFlow 的高级特性,如分布式训练、自定义模型等,以满足更复杂的需求。



















 2132
2132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











