







 图像检索的关键是向量相似度比较,常用方法是通过比较欧式距离。随着数据量增大,朴素遍历法效率低下,因此出现了近似最邻近算法(ANN)。产品量化(Product Quantization)是ANN的一种,它将向量分解后分别量化,降低计算复杂度。通过建立codebook并进行量化,可以高效检索。产品量化算法结合了Lloyd量化器的思想,通过优化的量化方法减少误差。在检索过程中,利用倒排索引结构加速计算,实现高效图像匹配。
图像检索的关键是向量相似度比较,常用方法是通过比较欧式距离。随着数据量增大,朴素遍历法效率低下,因此出现了近似最邻近算法(ANN)。产品量化(Product Quantization)是ANN的一种,它将向量分解后分别量化,降低计算复杂度。通过建立codebook并进行量化,可以高效检索。产品量化算法结合了Lloyd量化器的思想,通过优化的量化方法减少误差。在检索过程中,利用倒排索引结构加速计算,实现高效图像匹配。
图像搜索首先需要提取图像的特征信息。由于全局信息具有不稳定性和敏感性,鲁棒性较差。所以现在一般都提取图像的局部信息,如SIFT,SUFT等。这样,一副图像就可以用许多特征点组成。每个特征点用一个向量表示,对于SIFT,SUFT,这个向量是128维的。在提取出特征向量之后。因为一般每幅图像都可以提取几百上千个特征点,为了方便图像匹配,一般还需要将这些特征向量聚合成一个向量,方便比较。当然,也不是所有的算法都需要将特征向量进行聚合。

因此可以看到图像匹配的本质就是比较向量的相似程度。现在主要是通过比较向量的欧式距离来比较他们的相似程度。比较过程就是对于一个输入向量,在数据库中找到与其在欧式空间上距离最近的向量。因此,朴素的算法是对数据库中的特征向量进行遍历。因为要找到最邻近的匹配值,起码都要把所有的向量比较一遍。但有两个问题,一个是数据库中一般含有的特征向量数目非常多,起码都是千万级别的。因此遍历一遍会花很多时间;其次,计算向量之间的欧氏距离也是一个花销非常大的过程。
为了解决最邻近算法的这些问题,现在提出了近似最邻近算法(approximate nearest neighbor-ANN)。ANN算法目的不是寻找最邻近向量,而是近似最邻近向量。
ANN算法的核心思想是先建立codebook,,然后将特征向量量化到code word上。最后通过比较对应的code word的距离即可。可以认为被量化到同一个code word上的特征是近似最邻近的。因此前面的距离算法到这里就编程了量化算法。但是量化算法也有一些缺点,就是存在量化误差-可能会把欧式空间中相邻的特征量化到不同的code word上。毕竟量化过程会丢失特征向量的某些特征。为了弥补这些误差,各种算法都提出了一些优化措施。
本文主要是介绍量化算法中的一种叫做product quantization。目前有许多很有名的ANN算法,product quantization是其中比较好的算法。相关详细信息可以参考论文:Jegou, Herve, Matthijs Douze, and Cordelia Schmid. "Product quantization for nearest neighbor search." Pattern Analysis and Machine Intelligence, IEEE Transactions on 33.1 (2011): 117-128
1.背景知识
首先介绍一下向量量化的一些背景知识。向量量化的目标是为了减少空间结构的复杂度。因为经过量化,任何空间中的点都可以用有限的几个code word来表示。假设存在量化函数q,和词汇 C,则对于空间中的任何一个向量x都有
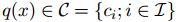
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









