







 本文详细介绍了机器学习在处理数据缺失值时的各种策略,包括删除缺失值、统计学填充、回归计算、Hot and Cold Deck Imputation、多重值估计以及基于机器学习的K-NN、SOM、MLP、RNN、AANN、MTL等方法。此外,还提到了评估缺失值处理效果的指标和基于模型的方法,如EM算法。这些方法在提高分类任务准确性的同时,关注缺失值处理的精确性。
本文详细介绍了机器学习在处理数据缺失值时的各种策略,包括删除缺失值、统计学填充、回归计算、Hot and Cold Deck Imputation、多重值估计以及基于机器学习的K-NN、SOM、MLP、RNN、AANN、MTL等方法。此外,还提到了评估缺失值处理效果的指标和基于模型的方法,如EM算法。这些方法在提高分类任务准确性的同时,关注缺失值处理的精确性。
1.删除含有缺失值实例
分为只要含有缺失值的即删除和关键值缺失的实例删除
2.基于统计学计算
1)使用均值填充
使用在该部分不缺失的实例的均值填充
使用同类在该部分不缺失的实例的均值填充
2)回归计算
线性回归计算和非线性回归计算
3)Hot and cold deck imputation
Hot deck imputation 使用本数据集中在其他不缺失值方面最接近的实例在缺失特征上的值来替代
Cold deck imputation 使用其他数据集的数据,余同Hot deck imputation。
4)多重值估计
即一次性填入多个值,分别计算评估,选取其中效果较好的在进行取平均等处理作为最总的估计值
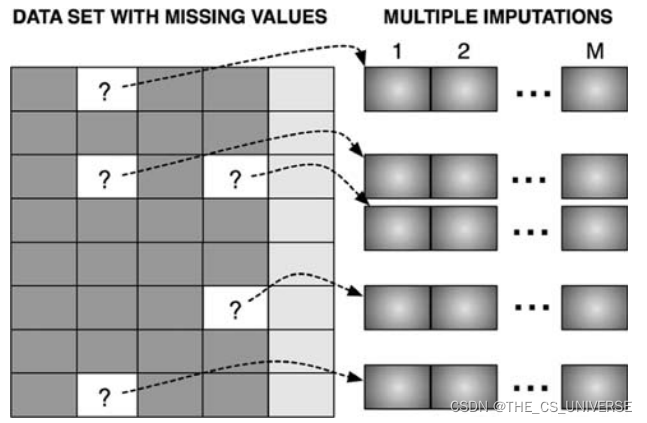
基本过程:
• The missing data is filled in M times to generate Mcomplete data sets.
• The M complete data sets are analyzed by usingstandard procedures.
• The results from the M complete data sets are combined for the inference.
3.基于机器学习的计算方法
1)K-NN
使用距离函数选取距离缺失样本最近的k个样本,用他们的值来填充缺失值
平局\按距离贡献加权
距离函数的选择十分重要
当缺失的数量非常大时也适用
Hot deck impution是K-nn K=1时的特例
主要缺点是要从整个数据集中寻找相近的实例,计算量比较大。
HEOM距离函数:
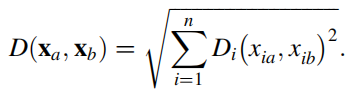
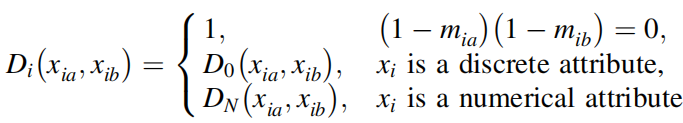
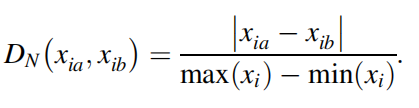
2)SOM imputation、
基本思想:高维输入映射到低维输入
SOM算法:SOM算法
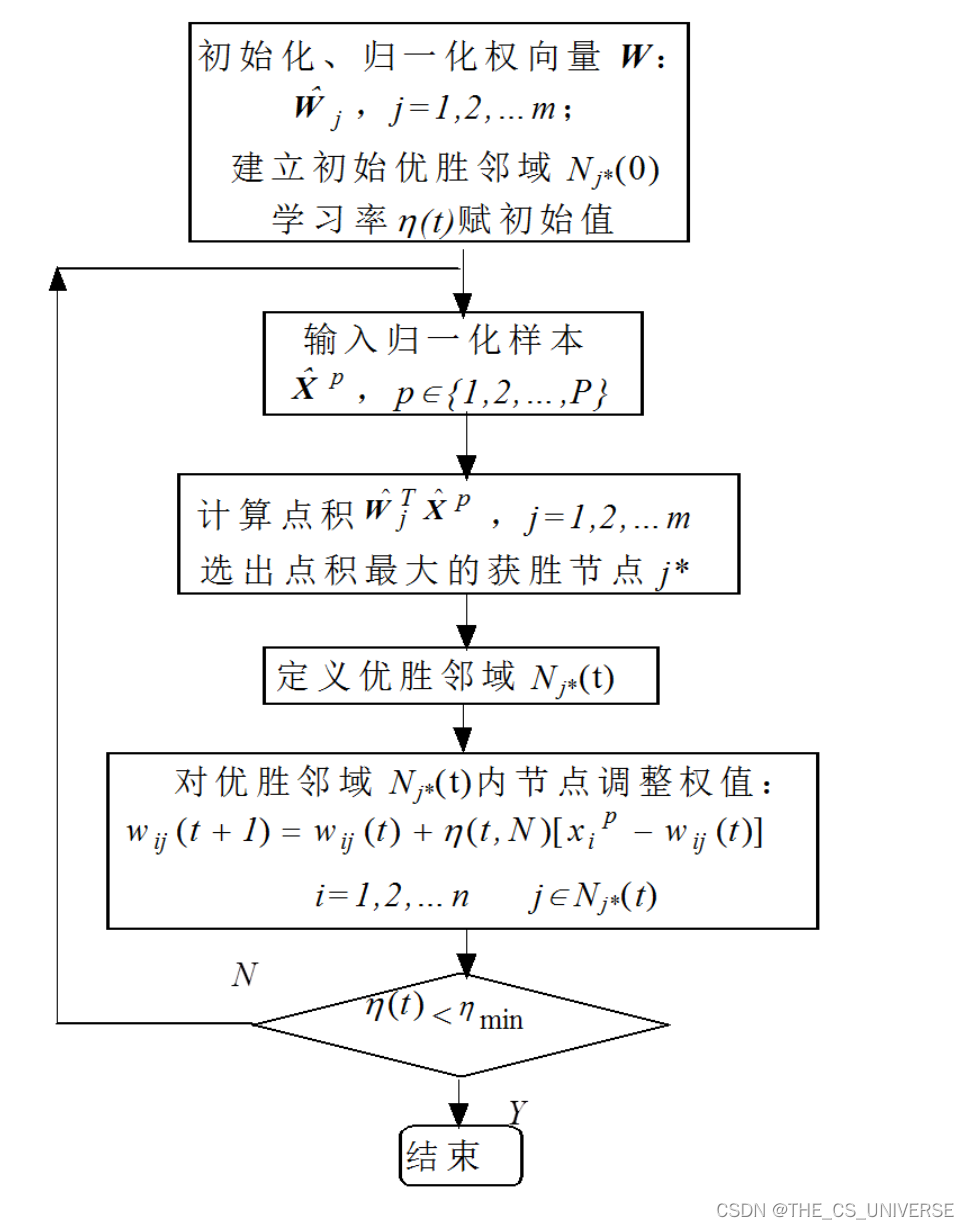
SOM算法应用到缺失值处理时,对于缺失的部分,在计算距离时直接忽略了,在选择image node和更新权重的时候仍然忽略了,这样有缺失值节点参与的权重计算结果比全部是完整节点的效果要好。然后根据选取的activation group中节点的权重来计算缺失节点的值。
基本算法过程:首先,当不完全模式呈现给SOM时,忽略缺失变量中的距离,选择其图像节点;其次,选择由图像节点邻居组成的激活组;最后,根据缺失维中节点激活组的权值计算每个输入值。
改进版:TS-SOM,优点:更快的收敛速度以及当输入向量的维数较大的时候效果更好。
3)MLP imputation
基本思想:首先将数据集分类:完整数据集和缺失数据集,针对缺失数据集中的每一种缺失组合建立一个MLP使用完整数据集中的数据进行有监督训练,将最后训练好的MLP用于缺失值模型的缺失值预测。
基本步骤:1.给定一个不完整的输入数据集X,将不包含任何缺失数据的输入向量(观察分量Xo)与具有缺失值的输入向量(缺失分量Xm)分开。 2.对于Xm中每个可能的不完全属性组合,使用Xo构造一个MLP方案。目标变量是缺少数据的属性,输入变量是其他剩余的属性[32]。在这种方法中,每个缺失变量组合有一个MLP模型。根据要计算的属性的性质(连续的或离散的),在训练过程中,不同的误差函数(平方和误差或交叉熵误差)都在最小化。
缺点:显而易见的可能需要建立多个MLP来训练针对不同的缺失值组合。
改进后的版本:SLP和TEST
4)RNN imputation
基本思想:基于RNN反馈神经网络,首先使用所有的输入特征值作为RNN的输入,对于缺失值使用完整输入实例的均值,同时利用此网络进行分类模型的训练,然后使用反馈值来更新缺失值的输入。

5)AANN imputation
基本思想:使用完整的数据样本来训练AANN,使最终的训练结果输出和输入相似,然后输入不完整样本将最后AANN的输出结果作为最终的预测结果。
基本步骤:首先,网络从完整的情况中学习,以便将所有的输入复制为输出。其次,当检测到未知值时,将不会更新权重。相反,缺失的值会被网络输出所取代。
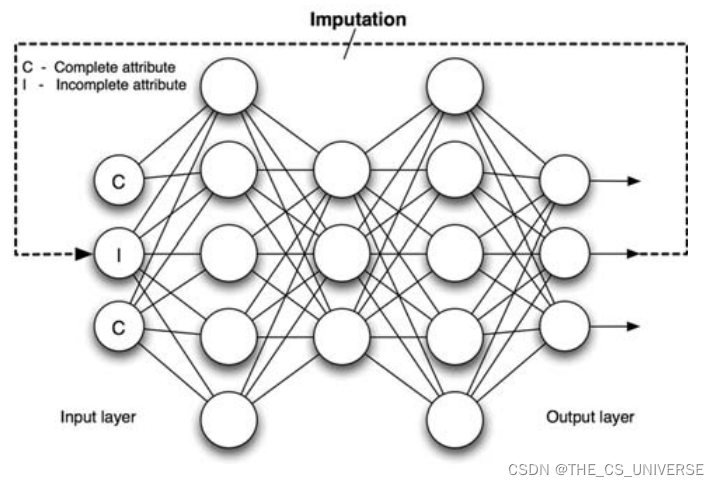
6)MTL imputation
基本思想:基于多任务的缺失值填充,将分类任务看作主任务而将缺失值的预测与处理看作副任务,网络的输出同时包含分类的结果和缺失值的预测结果,但缺失值预测的最终目的也是为分类任务服务的,因为在分类的过程中收到了缺失值预测的影响。
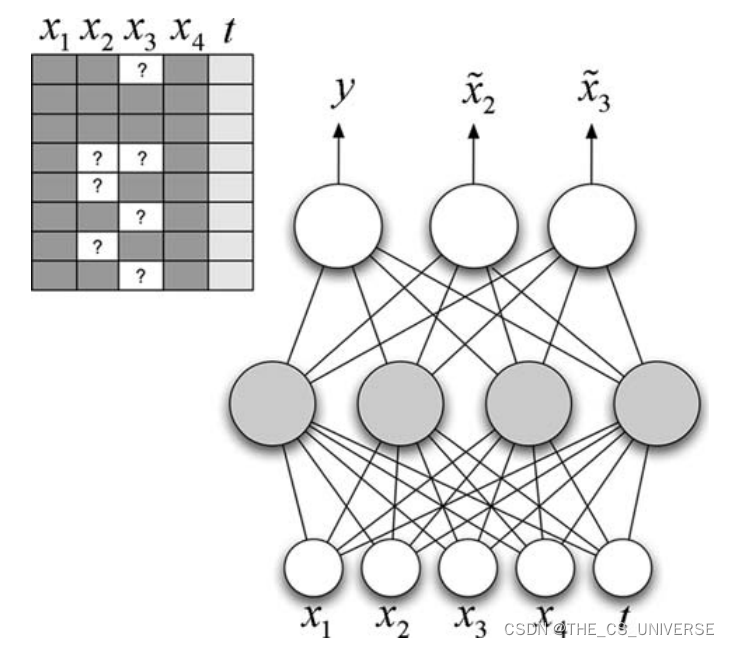
7)缺失值处理算法的评估
主要有两个任务需要进行评估:分类任务和缺失值处理任务
对于分类任务:查看分类准确率CER即可
对于缺失值处理任务:要综合考虑缺失值的比率和缺失值的组合等多重因素。皮尔逊相关性可以用来反应预测值与真实值之间的差距情况。
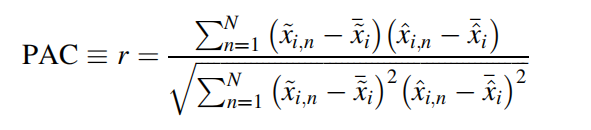
x^代表实际值,x~代表预测值,-代表均值的结果。
好的预测结果其PAC系数应该接近于1。
同时好的预测其分布应该也相似,所以使用DAC来计算此项值:
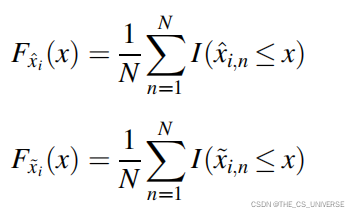
F分别为实际值和预测值的经验分布函数。
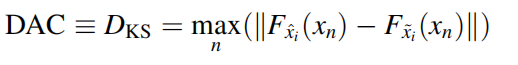
Xn为联合预测和实际值的输入,DAC越小代表其预测的效果越号。
但总的来说,因为主任务是分类,所以还是拥有较好效果CER的预测方法应该被采用。
4.基于模型的方法
基本思想:建立数据的分布函数,通过分布函数来估计缺失值。
常用算法有EM算法等。
5.基于机器学习的方法
1)利用神经网络建模
2)决策树
ID3、C4.5、CN2
3)基于模糊值的方法
基本思想:知道缺失值的取值范围,根据此进行处理。
4)支持向量机的方法

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









