







前言
- 今天就很有意思。看到一个摄影图片社区。里面的照片都是高清的,拿来当壁纸再合适不过了。
- 所以想到尝试一下爬虫,第一为了试验一下自己学的python,第二就是下载那些照片。
过程
-
首先爬虫是基于url链接访问爬取内容的。所以,用到python的库
requests,然后因为需要提取指定内容,所以用到了库re,再就是写入文件,用到了库os。其中,requests是第三库,需要额外安装。安装过程很简单,可以自行百度。 -
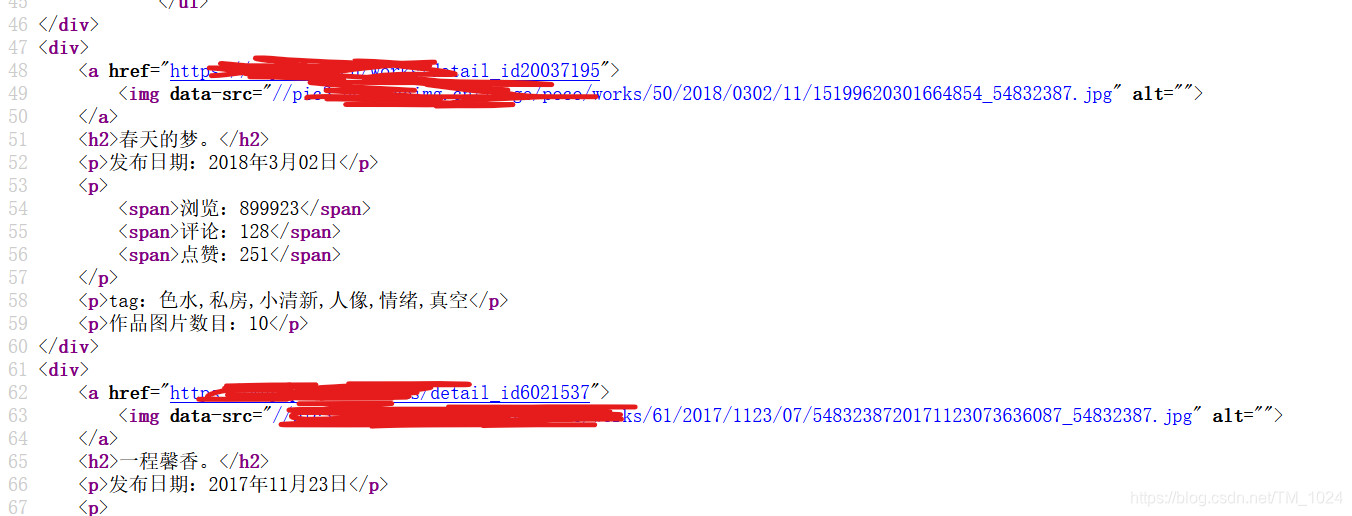
然后就是确定爬取目标,打开网站,查看源码或者检查元素,找到想下载的图片链接。
-
但我在网站主页没找到,都是一堆js。转而去找其它页面,终于在摄影师主页看到了想要的东西。
-
有照片的访问链接,同时发现,还有相册的链接,点进去相册链接,里面照片的链接都在。

-
所以,思路就是从摄影师主页获取相册链接,再访问相册链接获取照片链接批量下载。然后保存到本地。

-
垃圾编程
import requests
import os
import re
url0 = "https://www.simple.com/"
header0 = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
def a_get_0(sb_0): # 获取相册链接
r0 = requests.get(url=sb_0, headers=header0)
if r0.status_code == 200:
res_url = r'<a href="(.*?)"'#正则提取链接,主要是对标签
link0 = re.findall(res_url, r0.text, re.I | re.S | re.M)
return(link0)
def a_get_1(sb_1): # 获取照片链接
r1 = requests.get(url=sb_1, headers=header0)
if r1.status_code == 200:
res_url = r'<img data-src="//(.*?)"'
link1 = re.findall(res_url, r1.text, re.I | re.S | re.M)
return(link1)
def a_onput(url1): # 保存照片
root_path = r'D:\photo\\'
img_name = url1.split('/')[-1] # 截取url最后一段内容,也就是文件名
img_path = root_path + r'\{0}'.format(img_name) # 文件名命名
r = requests.get(url1)
with open(img_path, 'wb') as f:
f.write(r.content)
f.close()
i = 0
while(1):
link2 = a_get_0(url0)
for url1 in link2:
link3 = a_get_1(url1)
for url2 in link3:
url3 = "https://"+url2
a_onput(url3)
i = i+1
print("第"+str(i)+"张照片保存成功")
break
- 不得不说,这空格缩进真让人头疼。
- 分享一下POCO摄影社区
最后
- python确实,实用性很强,我也刚刚开始学,也很多东西很难理解。
- 这次主要目的还是实际动手,这也很简单,没有用上多线程多进程,同时,网站也没有反爬虫机制。算是最简单的吧。















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









