







上个月开始跟着Andrew Ng在Coursera上学习Machine Learning。起初十分顺利,觉得大部分问题自己都能领悟。但是在学习了四周之后猛然发现之前学习的知识都忘记得差不多了。于是我又重新开始看视频。由于察觉到自己的天资愚钝,因此认为我这样下去只会反反复复地忘记。所以想将课上讲的内容记在博客里,以备自己快速地查阅,也许还能帮助到向我一样的初学者。由于本人见识短浅,若有写得不周正的地方,还望指正。谢谢,共勉。

课程开始的时候介绍了机器学习的例子。包括数据挖掘,不能手工编程的程序(其中手写识别,自然语言处理和计算机视觉真是让人一听就兴奋的领域)和自定制的程序。
我们在日常生活中不知不觉地用到了机器学习编写的程序,其中包括谷歌的搜索引擎。

到这里好奇如我的朋友一定会希望更具体地了解机器学习的概念。于是Andrew Ng适时地为机器学习下了一个定义:机器学习就是让计算机在不通过具体编程的情况下去学习的科学。一个“不通过具体编程”道出了机器学习的神奇之处。反过来,如果通过编程精确定义机器的学习过程的话我们是没办法精确定义学习的每个细节的。而不同的学习需求又有不同的学习方式,针对每种学习需求编写不同的程序,这样的编程量将是巨大的。

Andrew Ng继续为我们举了例子。比如让机器人收拾家务,烹饪甚至在棋类运动中与人类对弈。这些程序的编写都需要应用机器学习这门科学。

接下来介绍到机器学习的两个大类:监督学习和非监督学习。其中监督学习又分为回归和分类。上图就是回归的例子。我们将房价数据以点的方式画在坐标系上,用一条直线去拟合这些数据,然后就可以用这条携带着房价变化规律的直线去预测数据中没有的面积所对应的房价。也就是说,这时候程序学习到的是我们拟合出来的那条直线,也就是房价随面积的变化规律(虽然准确性还有待商榷)。
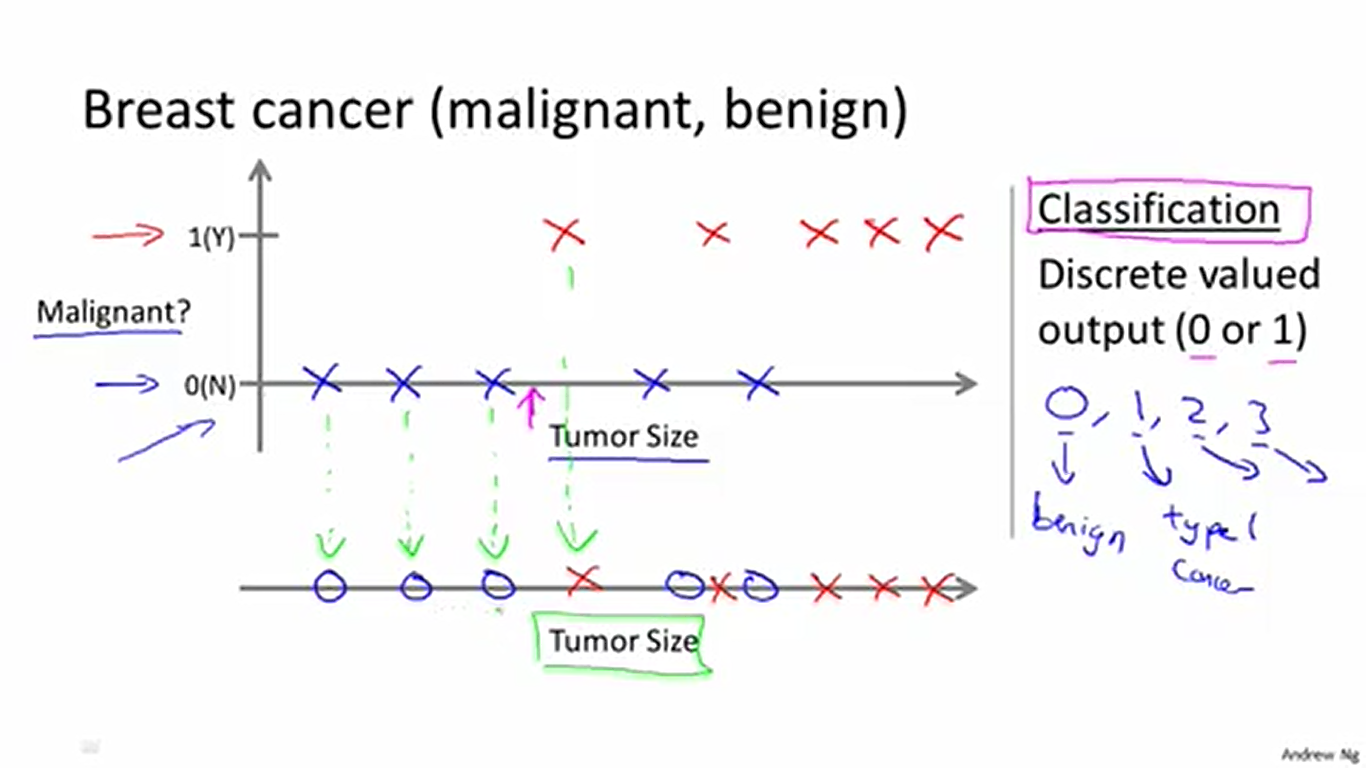
上图是分类的例子。这时候我们的预测值不是连续的如房价一样的信息,而是离散的,如表示“是否是恶性肿瘤”的0和1这样的离散的信息(或表示“是何种肿瘤”的0, 1, 2, 3…这样的离散信息)。表示方法同回归一样(根据数据在坐标系上做标记)。但是我们不会用直线去拟合它,因为这样是不合理的。
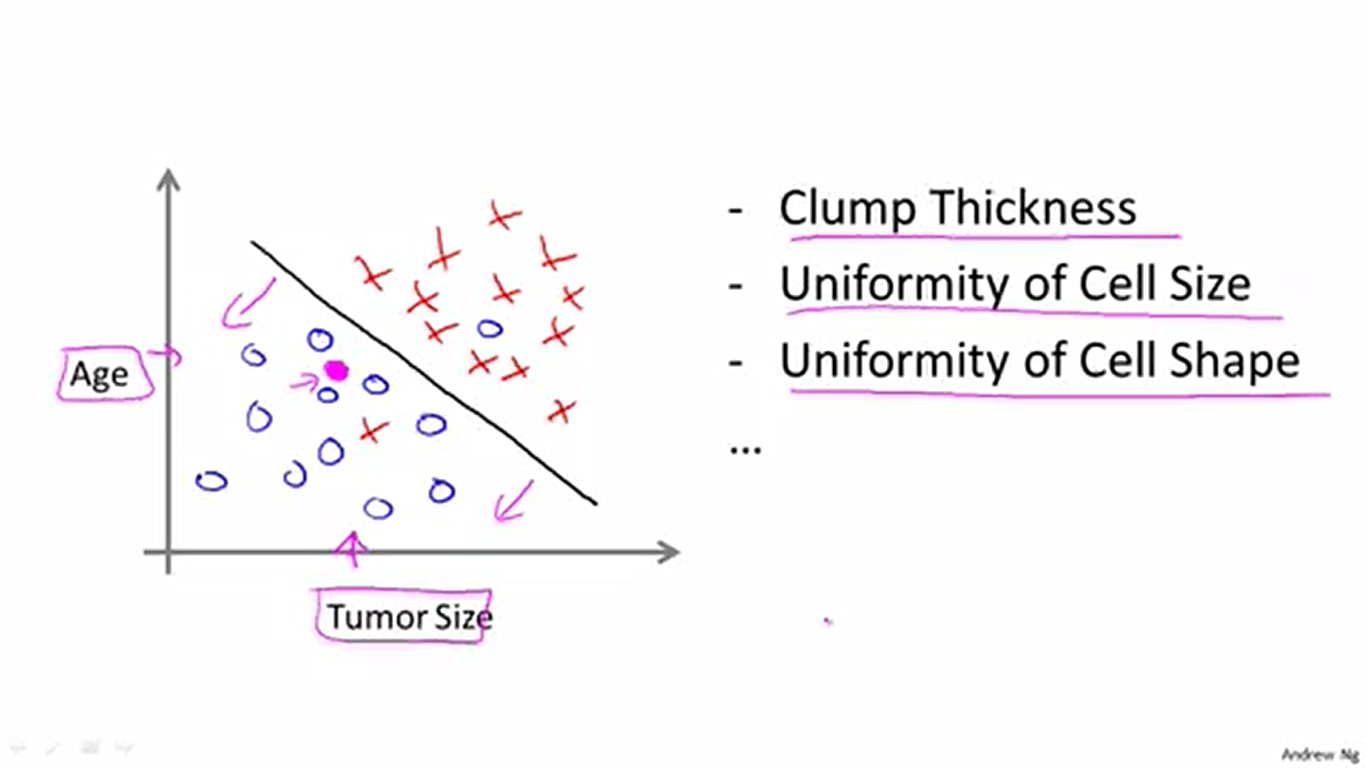
那么具体怎么分类呢?判断肿瘤是恶性的还是良性的可以用到许多特征。例如肿瘤密度,细胞大小的均匀性和细胞形状的均匀性这些。假如我们使用两种特征——年龄和肿瘤大小,那么我们将这两种特征对应的数据标记在坐标系上,用X表示恶性肿瘤,用O表示良性肿瘤。然后尝试在坐标系用一条直线把两种数据分离开。最后就可以用这条直线对数据中没有的特征组合进行预测了。具体是,如图落在直线左下方的数据将被预测为良性肿瘤,而落在直线右上方的数据将被预测为恶性肿瘤。
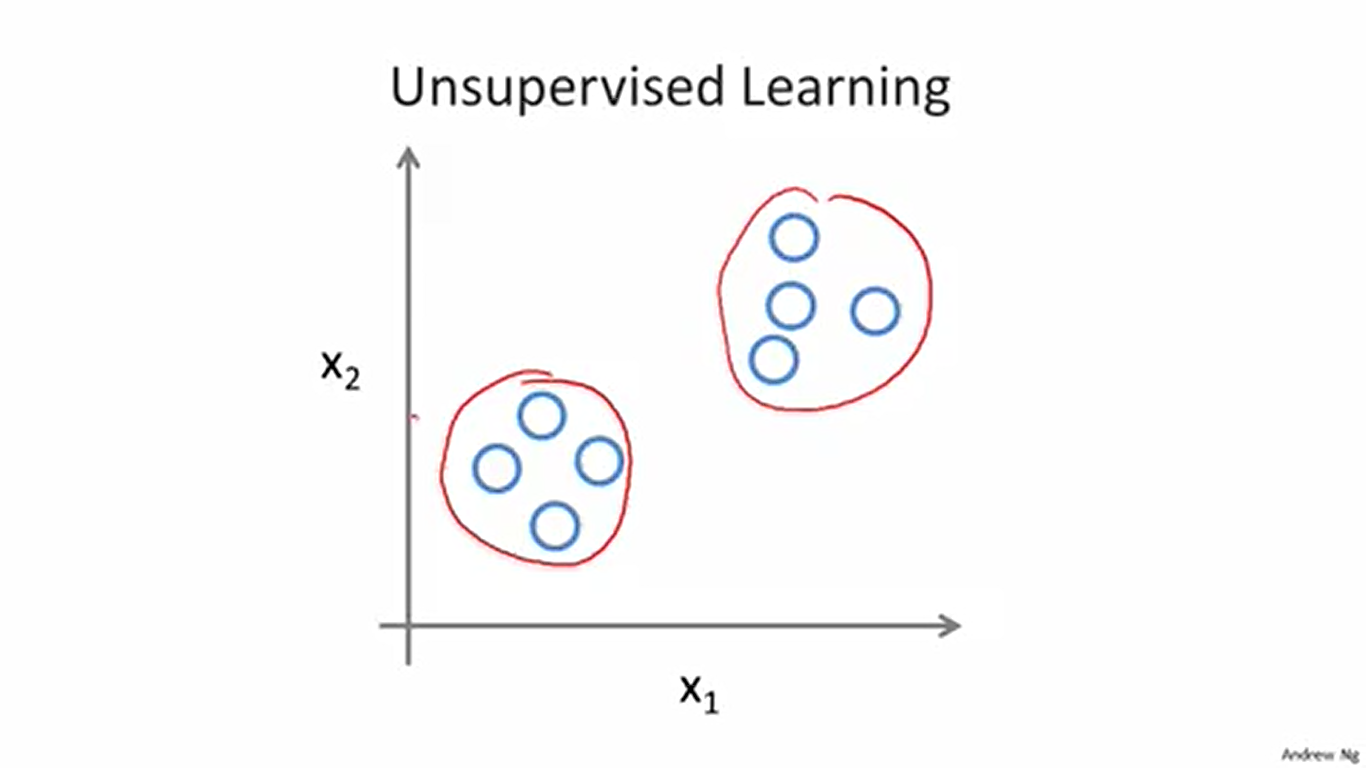
监督学习大体上介绍完了。其特征就是我们的训练数据中是包含输入(房子面积)和输出(房价)的。而非监督学习的训练数据是不包含输出的。也就是说没有历史规律可循,程序必须自行发现训练数据的不同并将它们进行分类。
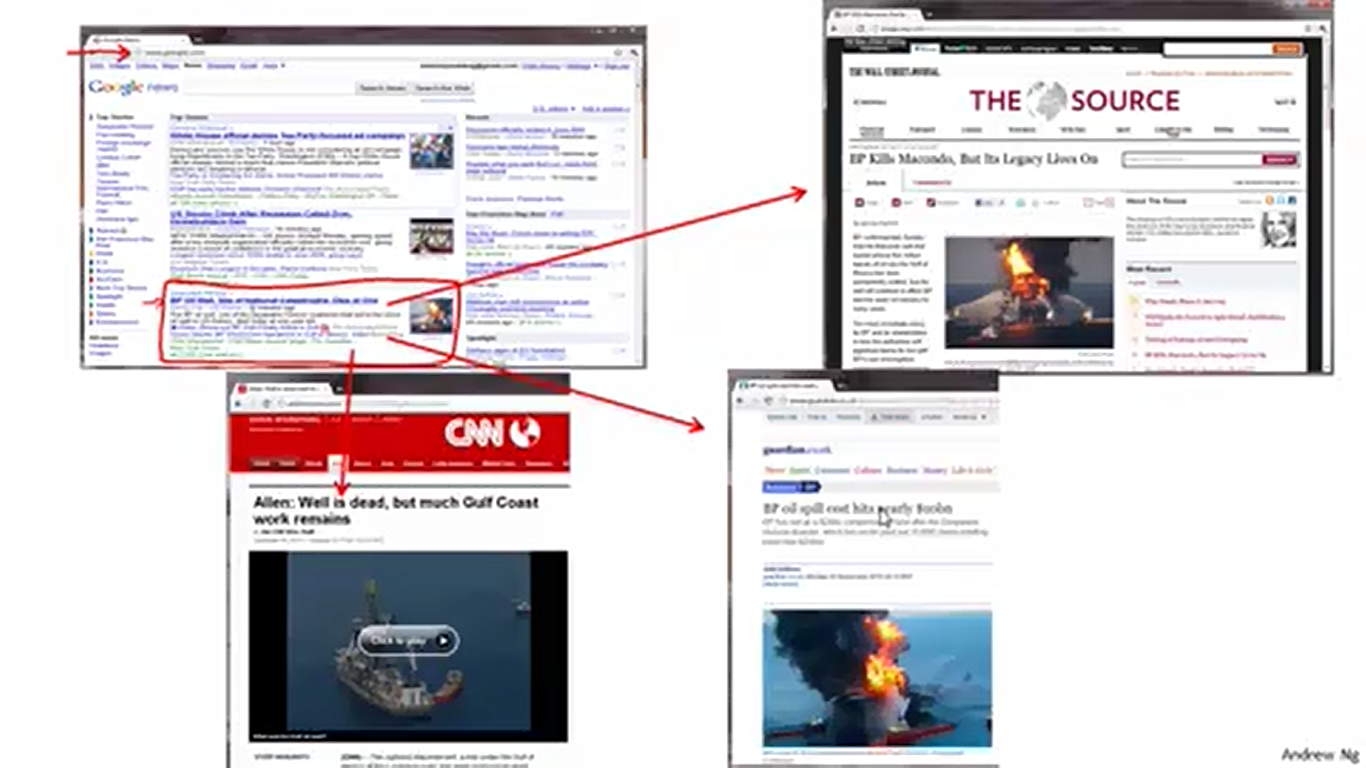
非监督学习有着广泛的应用,这里举出了非监督学习的例子——谷歌搜索引擎的新闻分类系统。
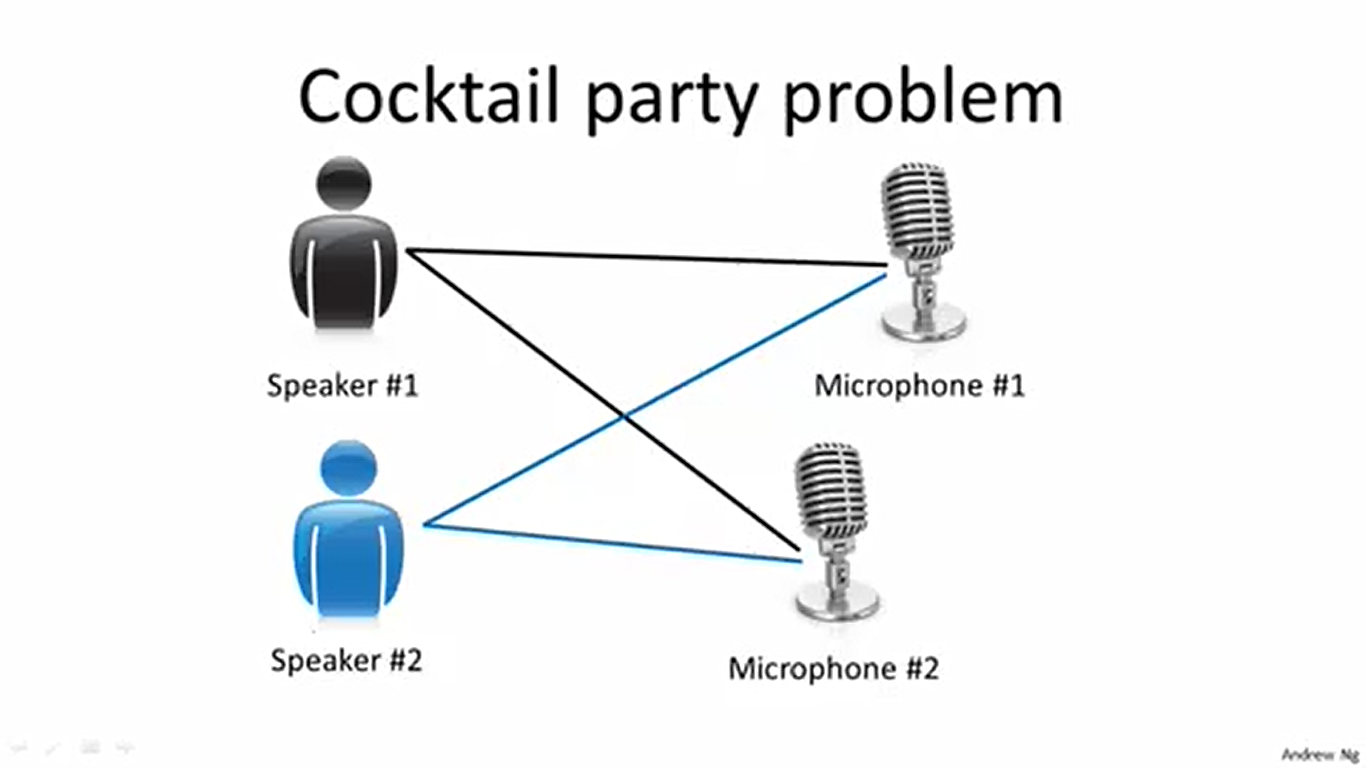
一个有趣的例子是“鸡尾酒会问题”。问题的目标是用两个话筒接收手机鸡尾酒会上的声音信息,然后将两个不同发言人的声音分离开来。接下来Adrew Ng用他的程序演示了非监督学习。效果还是不错的。

这是Andrew Ng实现鸡尾酒问题算法的Octave/Matlab代码。非常简洁。至此,我们对机器学习理论有了大体的概念。下面我们就可以进入到更深入的讨论中去了。
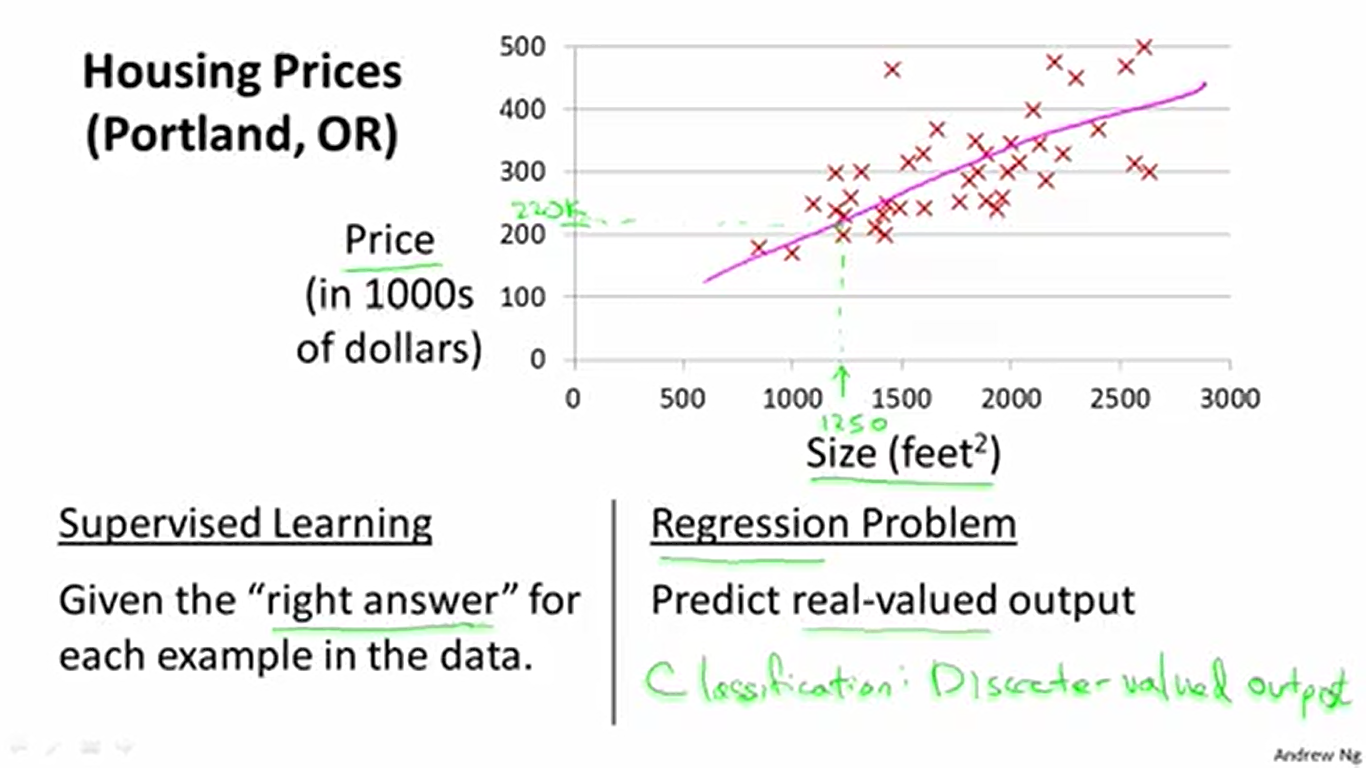
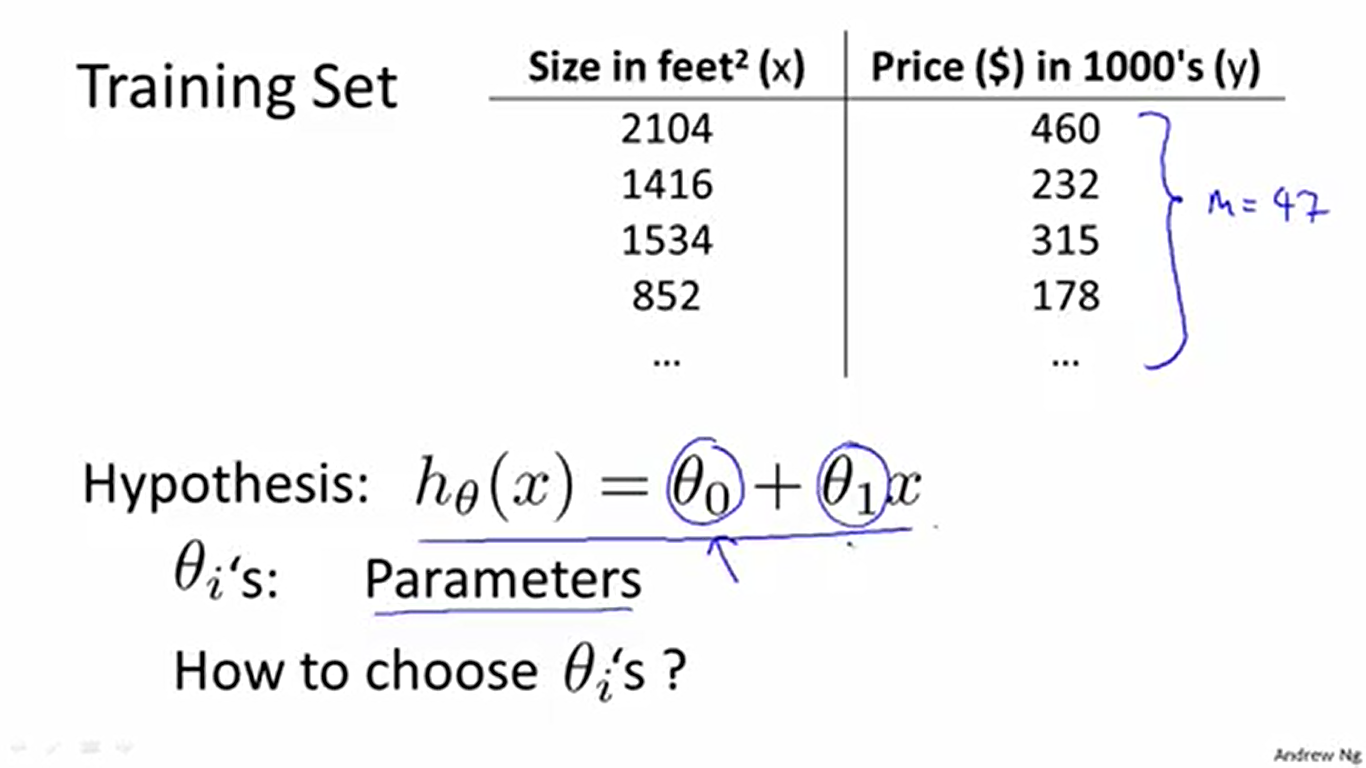
回到房价问题,前面说过,解决这个问题需要用到监督学习的方法。更具体地,应该使用回归(用直线来拟合数据)的方法。
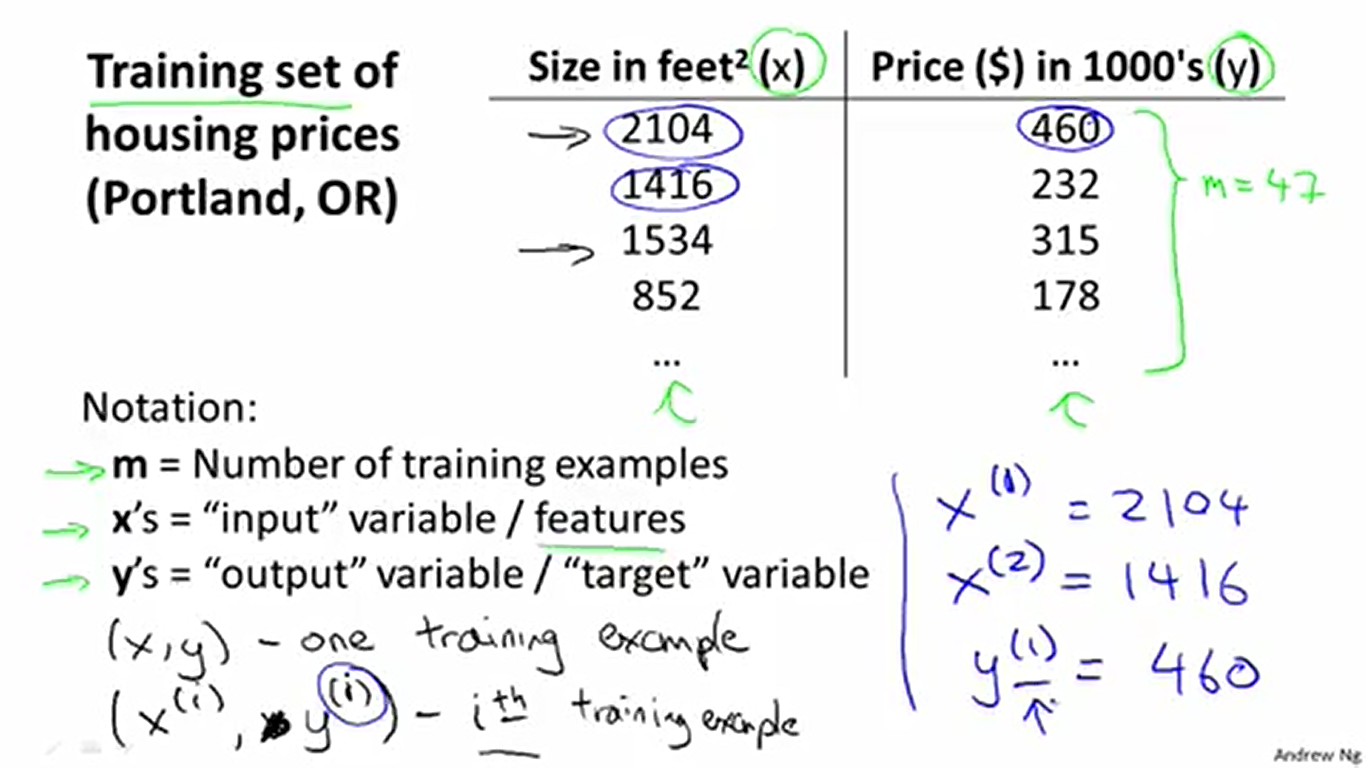
为了方便后面的描述,这里先规定一些术语。这里的术语主要有4个:训练集Training set(数据),训练组数
m
(数据的组数),输入变量
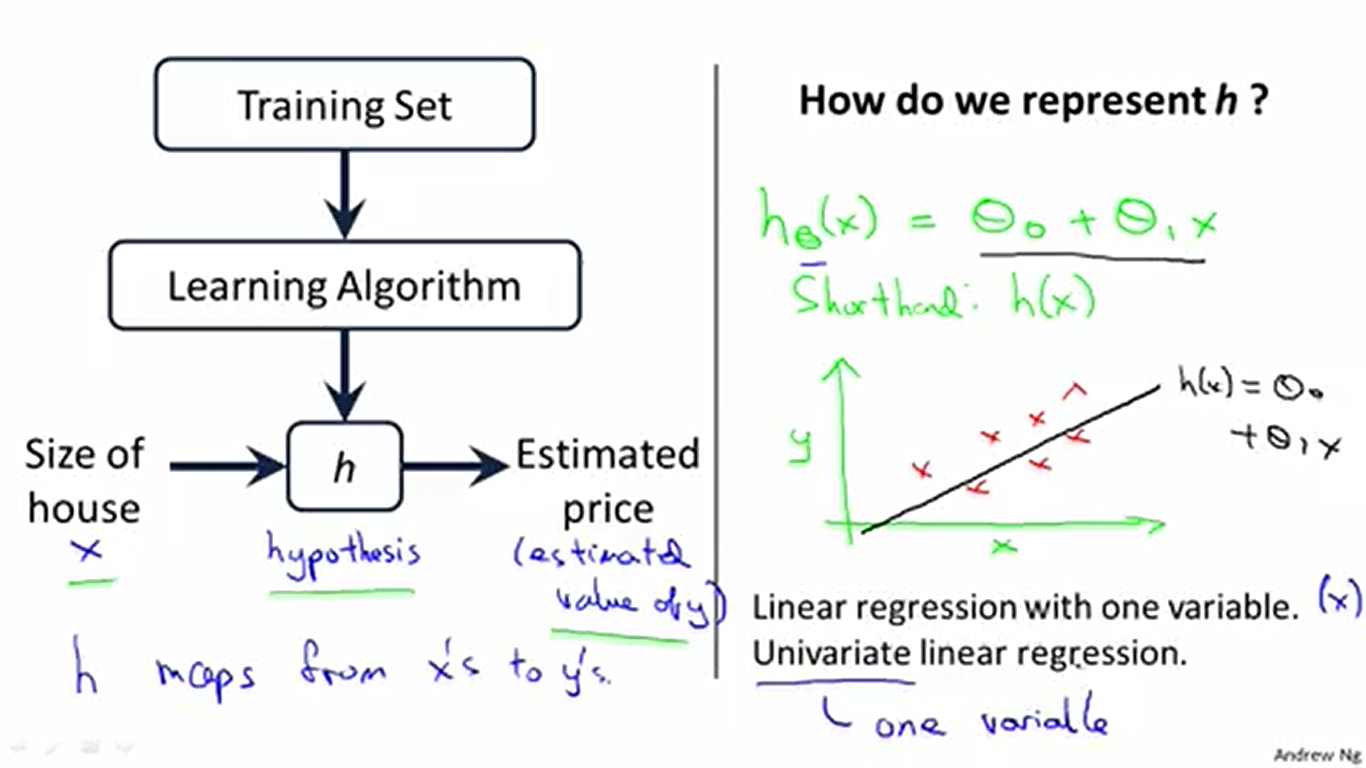
现在考虑怎样编写我们的学习算法(也就是如何让算法能够预测结果,或者说,如何拟合数据)。我们实际上需要做出一个函数
接下来要解决的问题是,我们怎样选择合适的 θ(θ0,θ1) 来拟合数据呢?按理来说我们需要一种自动选择 θ 的算法,而不是根据感觉来选择 θ 。
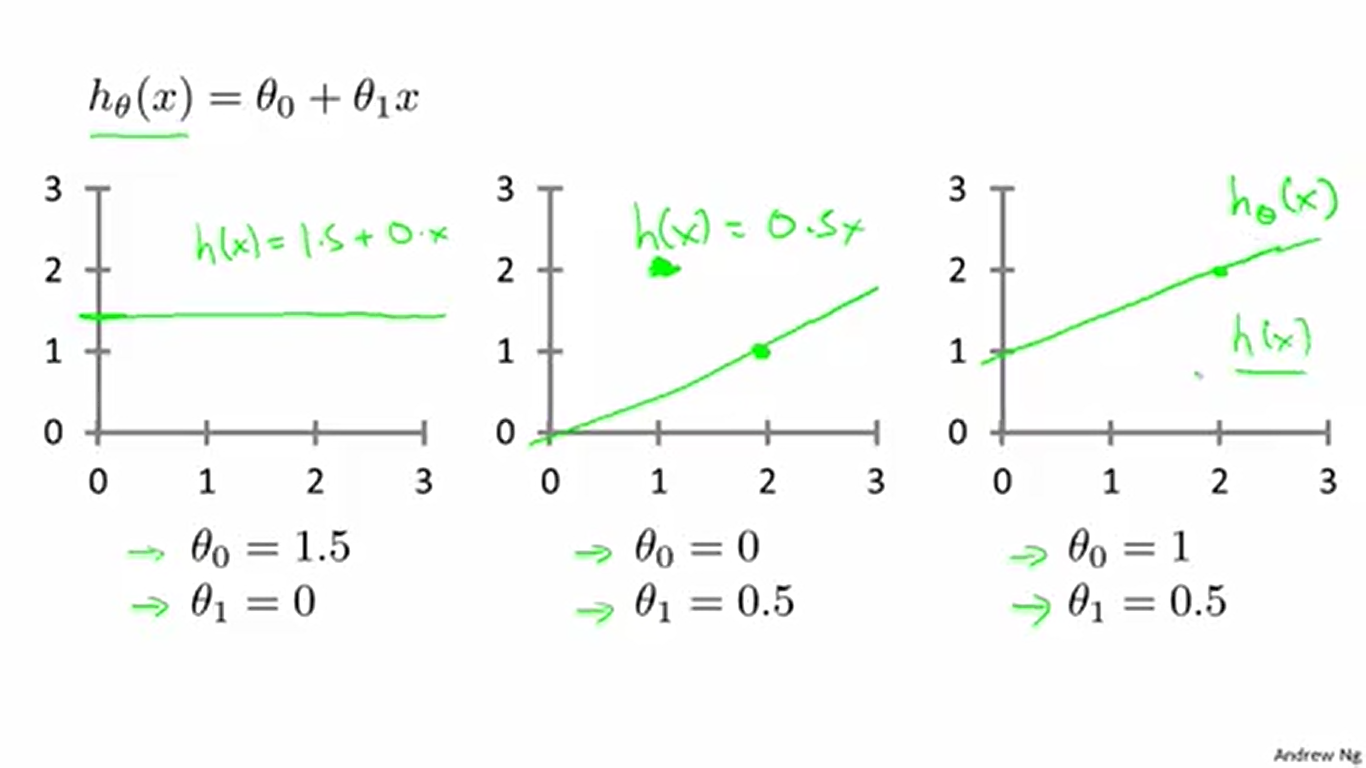
上图表示不同的 θ 使得直线呈现出不同的形态。

一个显而易见的的主意是,我们选择的 θ 要让所有的h(x)与其对应的y都十分接近。这样我们才能放心地用这条直线来做预测,因为此时 θ 构成的直线实际上携带了我们人类称之为“经验”,而在机器学习中我们称之为“数据”的信息。接下来,我们将这个主意用数学语言表达为 minimizeθ0,θ112m∑i=1m(hθ(x)(i)−y(i))2 。求和式前的 1m 表示平均的意思, 12 是方便求导。至于为什么对差值求二次方而不是套绝对值符号,我的理解是方便表示和方便求导,而且很多时候处理代数式的绝对值也是用先平方后开方法去做的。由于Andrew Ng没有说明白再加上在下知识浅薄,就只好姑妄言之了(实际上这可以用数学知识解释,感兴趣的话可以搜索“平方误差”和“均方误差”了解)。另外,为了方便以后的描述,我们将 J(θ0,θ1)=12m∑i=1m(hθ(x)(i)−y(i))2 定义为代价函数Cost function。为什么叫代价函数呢?因为在线性回归问题中,我们希望这个函数值尽量小。于是这个函数值越大,我们用 h(x) 做预测的偏差(代价)就越大(做出越离谱的预测,就越容易被别人嫌弃……)。好吧,这仅代表个人的理解。总之,现在可以用新的更容易理解的数学语言来表示我们选择 θ 的方法了: minθ0,θ1J(θ0,θ1) 。

为了对代价函数有更感性的认识,下面简化线性回归模型。把 θ0,θ1 精简为 θ 。注意,这个简化后的模型是没什么意义的,它的存在只是为了加深我们对代价函数的感性认识。
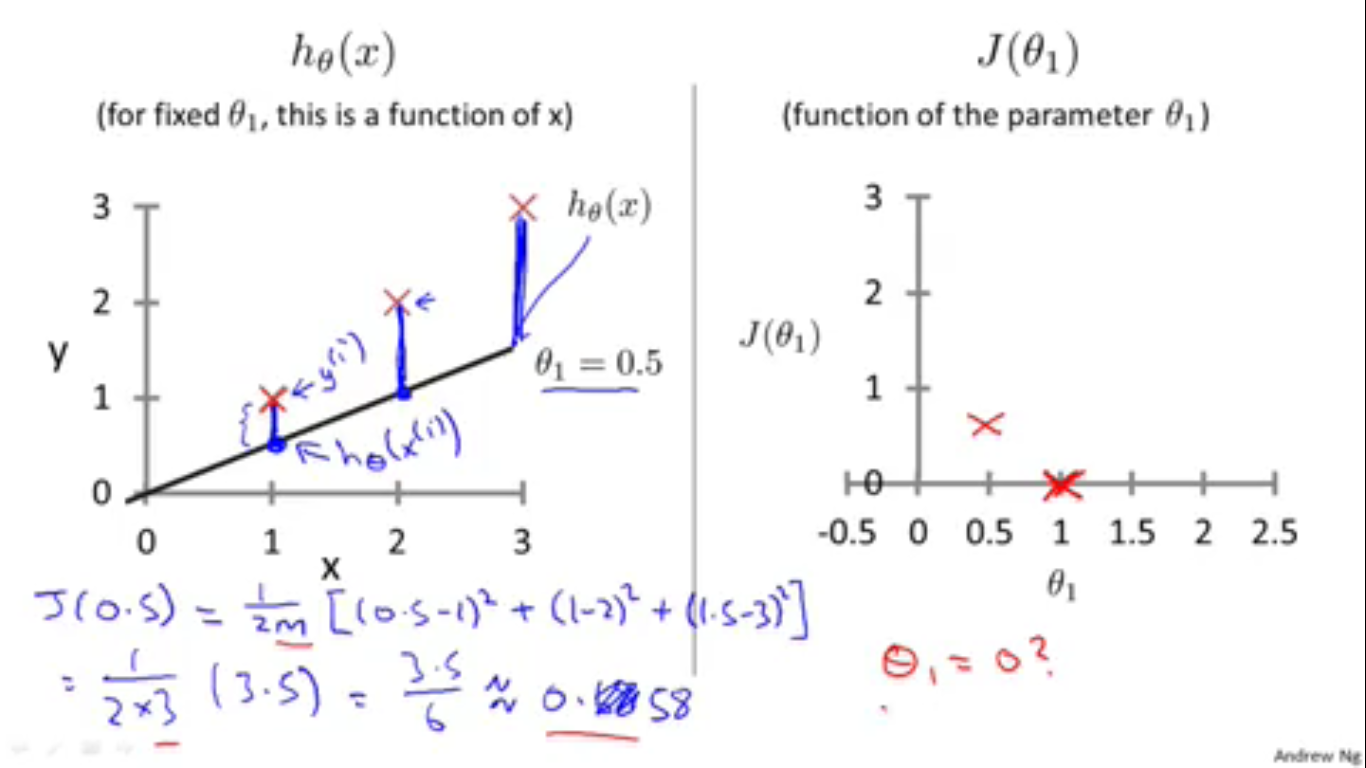
模型精简了以后,我们就可以通过在二维坐标系上画图的方式研究代价函数了。例如从左图可以明白地看出代价(蓝色的竖线)同 h(x)−y 之间的关系,而从右图就可以明白地看出不同的 θ 所对应的不同的代价函数。
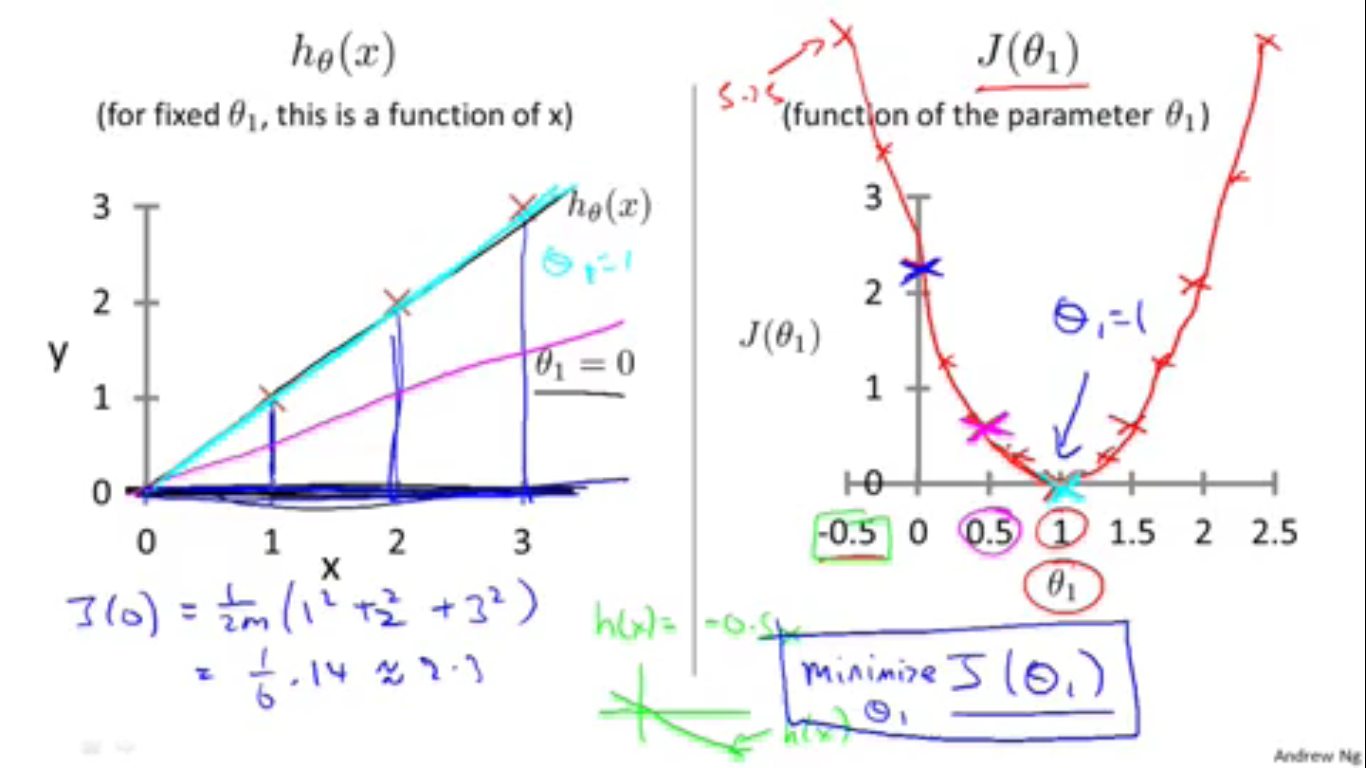
虽然不同的 θ 会有同的代价,但总有一个 θ 对应着最小的代价。注意,最小化代价函数使我们的目标(但是这个目标的本质还是自动选择合适的 θ )。因此这就是我们想要的 θ 。

简单总结一下前面的知识。以便继续讨论代价函数。注意,我们讨论代价函数是因为我们要想找到合适的 θ0,θ1 就需要最小化代价函数。所以我们讨论它,来找到让它最小化的途径。实际上让它最小化的途径已经在之前的精简模型中讨论过了,下面将方法推广到精简前的模型中去。
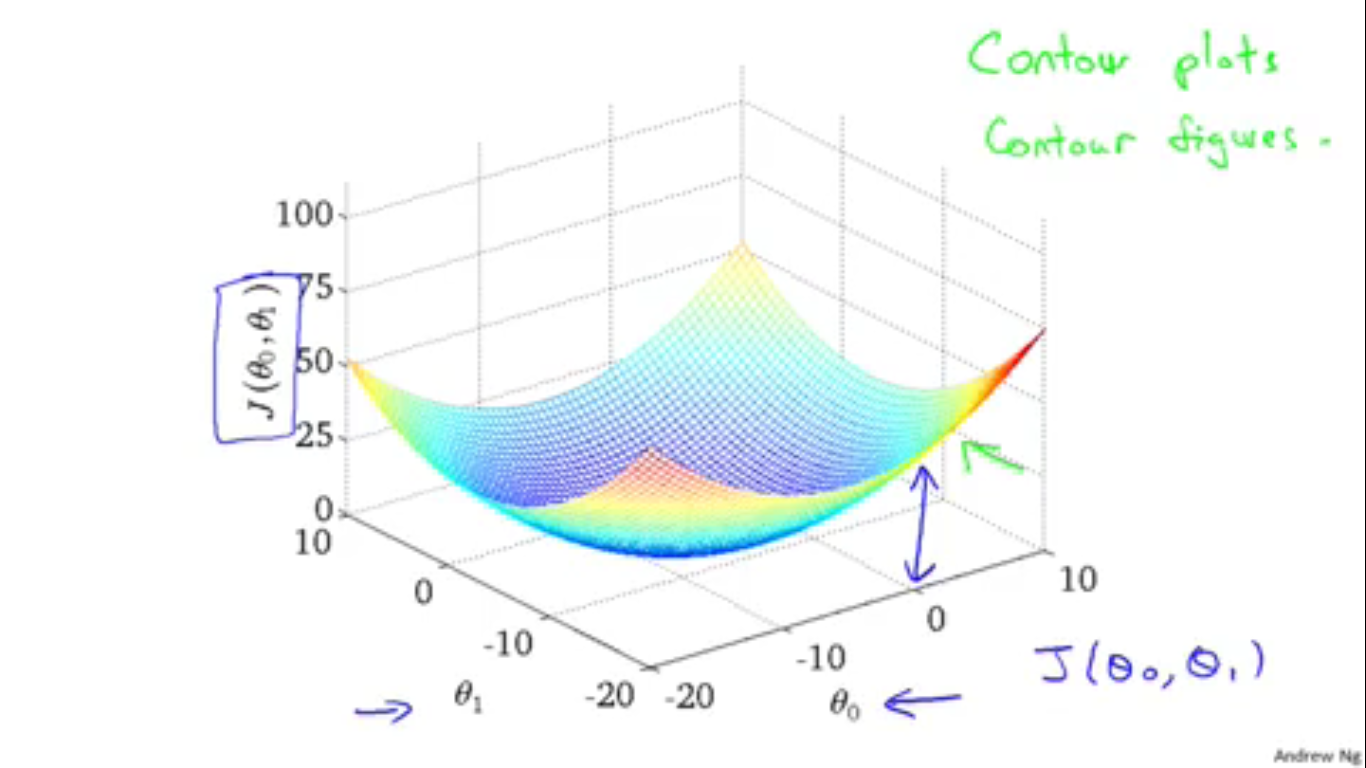
这是代价函数 J(θ0,θ1) 的三维图像。
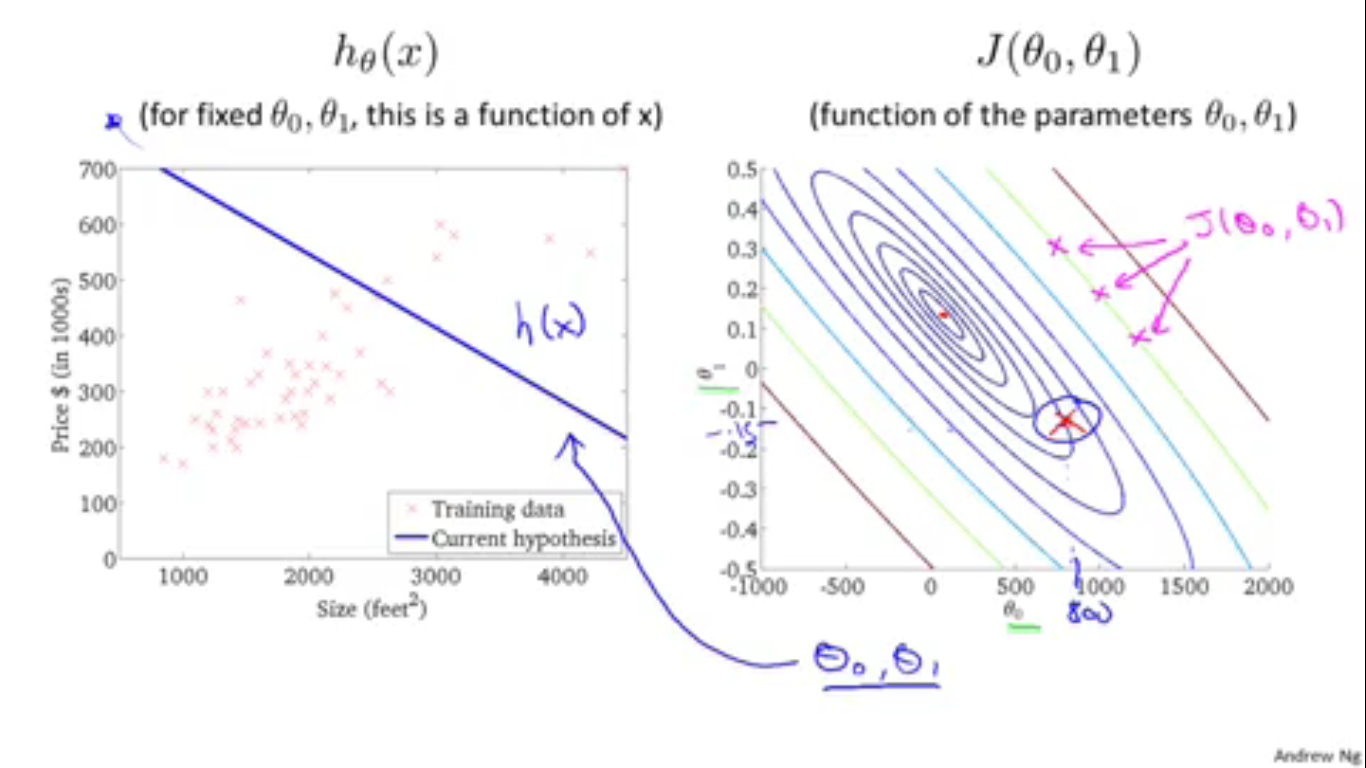
上面的三维图像可能不太好观察,于是Andrew Ng又引入了Contour figures(有点类似于气象中的气压等高线)。其中蓝色越深的部分代价函数越小。这个图像是不是有点类似于梯田的俯视图?
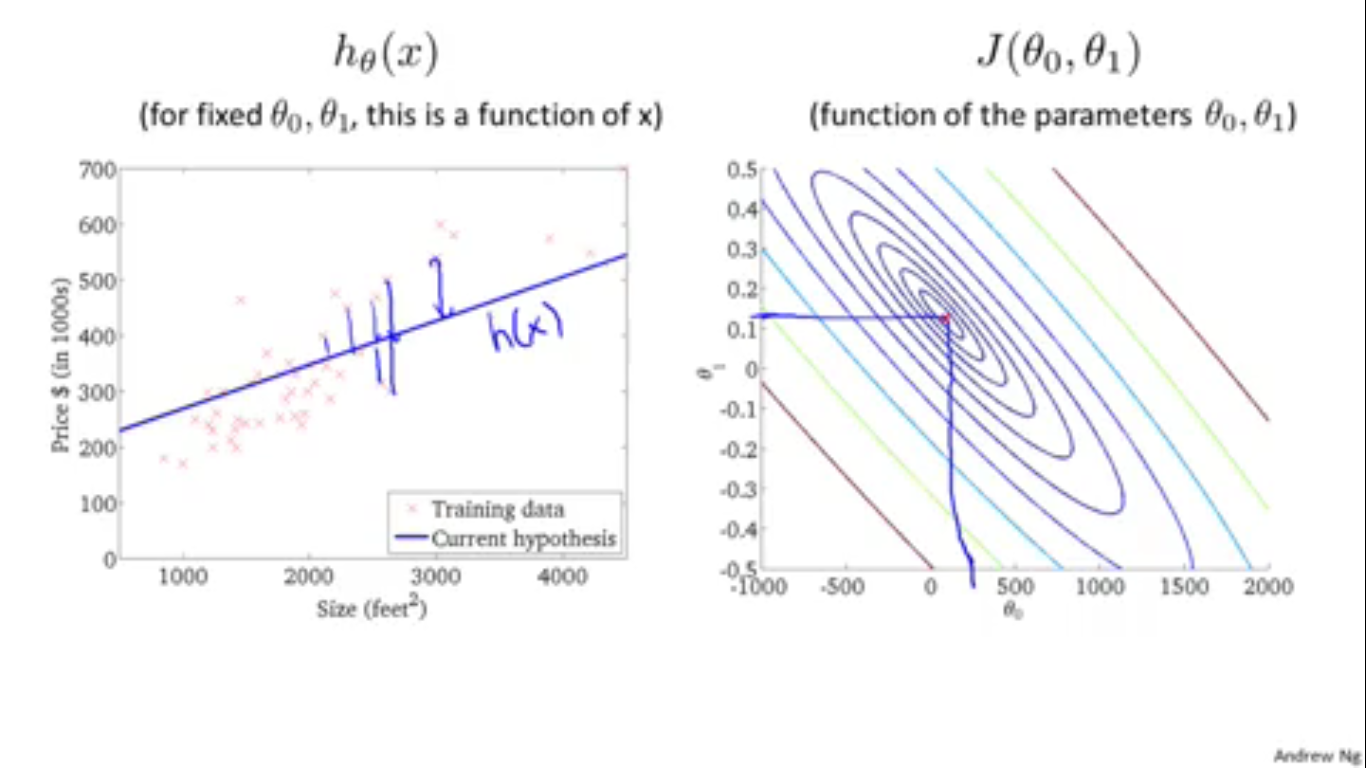
当选择的 θ 越来越合适时,代价函数就越来越近于代价函数最小的位置。从上面的Contour figures中就可以看出来。

从前面的过程中得到启示,在此得出了最小化代价函数值的思路:先选择一组参数,例如 θ0=0,θ1=0 , 然后不断改变参数,使得代价函数值不断减小。直到代价函数值达到最小值。

就像这样,图中的黑叉表示我们选择过的参数组合,黑色曲线表示按照前面说的方法,我们的“选择路径”。

根据前面的分析,我们迫切地需要一个算法让我们能用计算机快速地改变 θ ,并且这样的改变是能够使代价函数减小的改变。幸运的是正好存在这种算法供我们实现。这就是梯度下降算法(Gradient Descent Algorithm)。描述出来就是,先算出代价函数对 θj(0≤j≤1) 的偏导数并将结果乘以学习率 α ,再让 θj 减去这个值。这样改变 θj 以后,新的代价函数值必然被减小了。所以我们要做的就是重复这些操作,直到代价函数收敛为止。需要注意的是, θ0 和 θ1 必须同时减小( θ 的减小会使代价函数的值改变)。
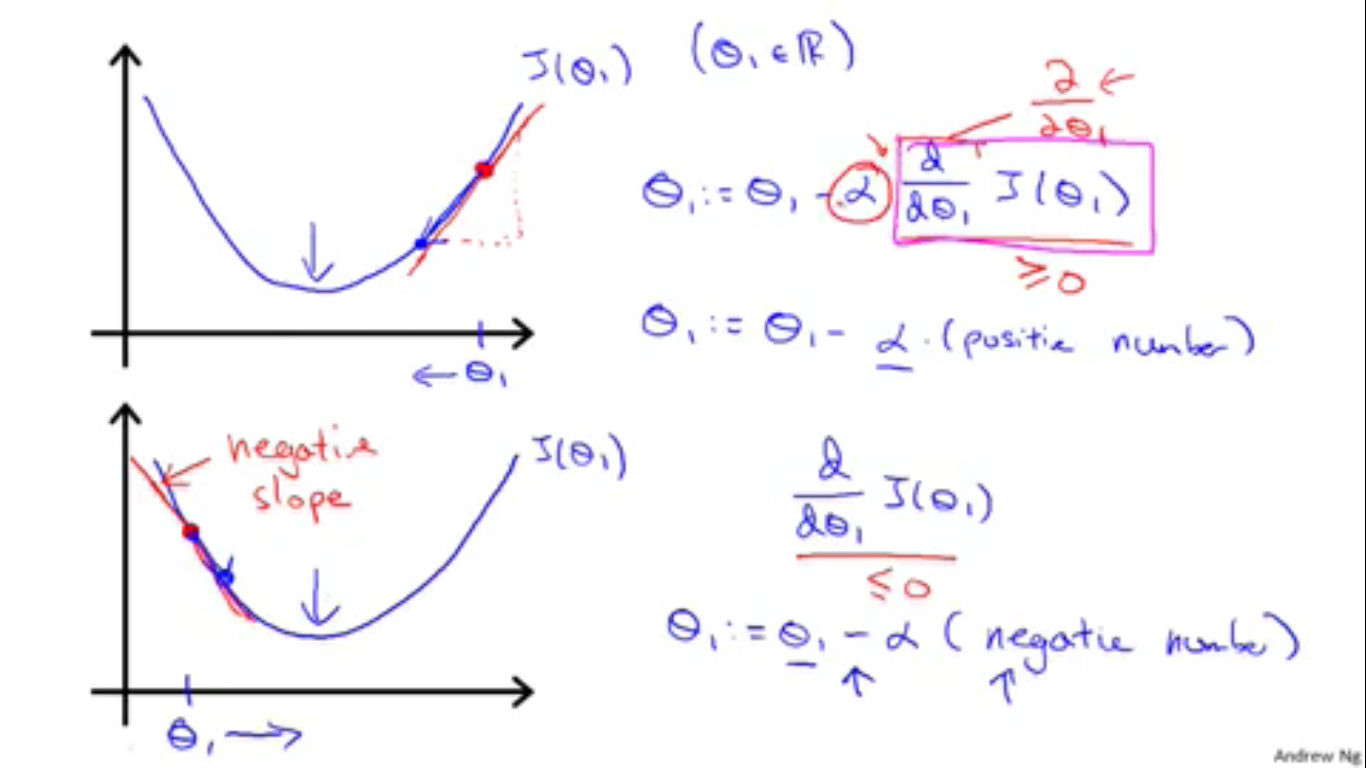
为了解释梯度下降算法是什么以及它为什么会有效。Andrew Ng又将模型简化到参数只有一个 θ (这真是十分精彩的引导方法)。并运用了一个比喻:梯度下降算法的每次迭代都像是在山坡(表示代价函数的曲线)上走的一小步(一次走步对应着一次 θ 的改变),每次朝山坡的坡底走一步,最终就能走到山坡底部(得到最小值)。(如上图)
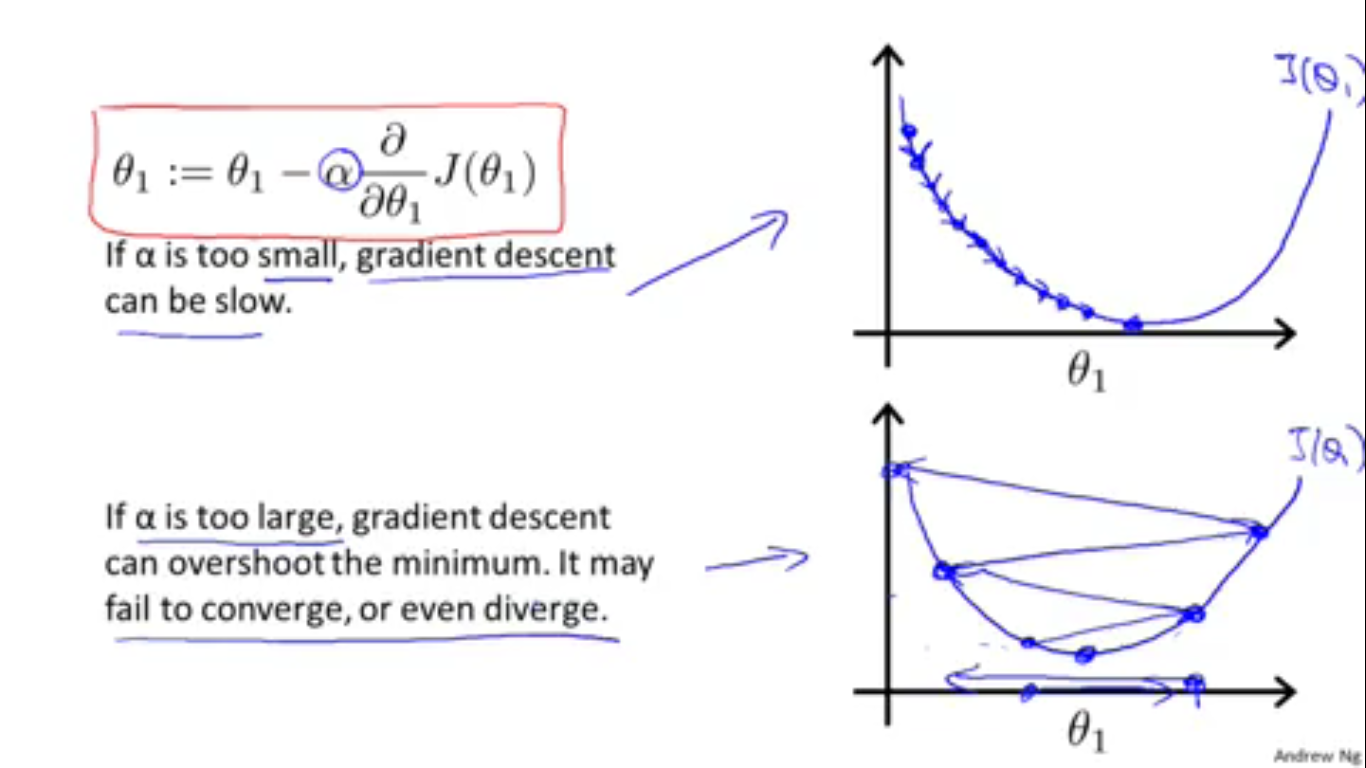
学习率 α 太大,会使得每次 θ 改变得太大,相当于在山坡上每步跨的太大,可能会一步跨到对面山上(现实生活中当然不会发生这样的情况),这样糟糕的情况反而会让所处的位置的海拔“升高”了。也就是可能会使代价函数不收敛甚至发散。学习率太小,会使得每次 θ 改变得太小,也就是每步跨得太小,相当于使得我们到达山谷底部的速度很慢,也就是需要很长时间才能是代价函数收敛。所以说如何恰当地选择学习率,这是真是一门艺术。
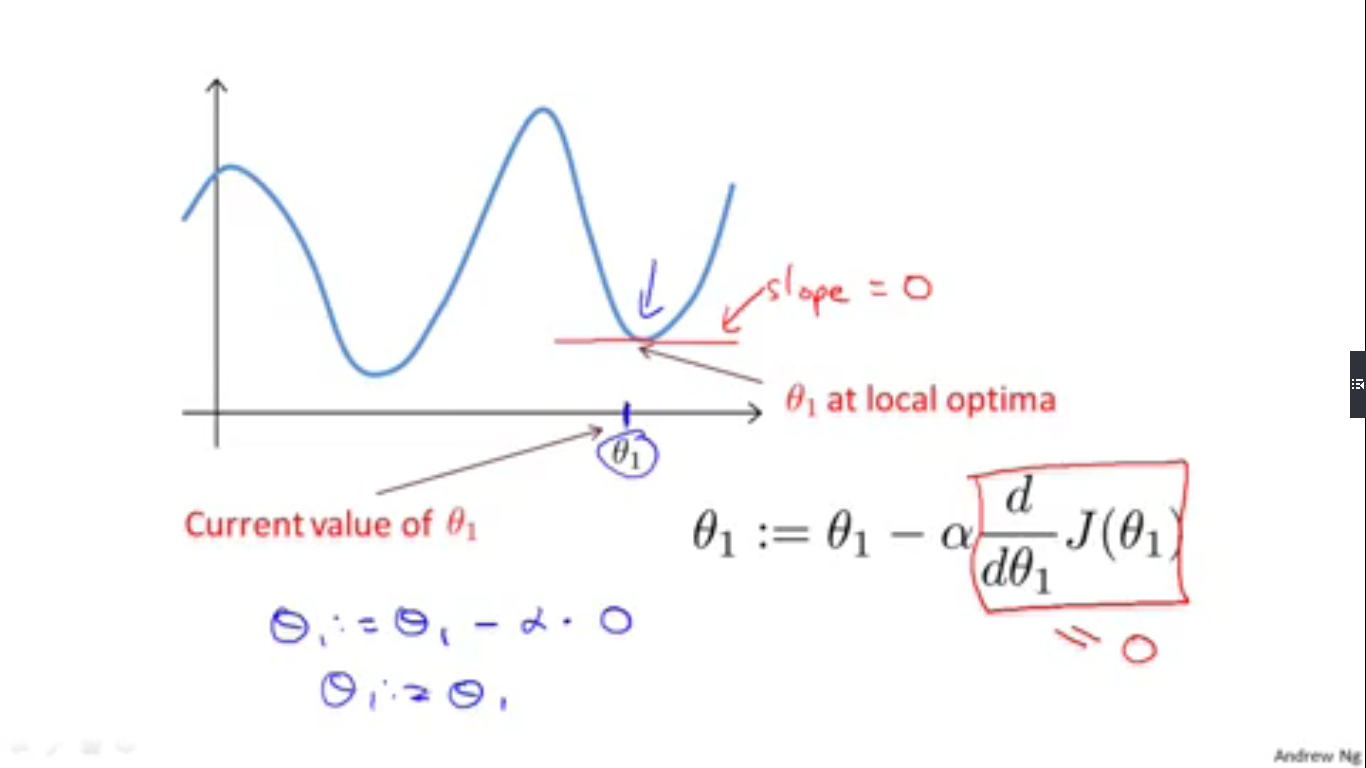
当代价函数去到极小值的时候,也就是代价函数对 θ 的偏导数为零的时候,受偏导数为零的影响, θ 就不会再改变了,此时的代价函数值就是一个局部最优解。
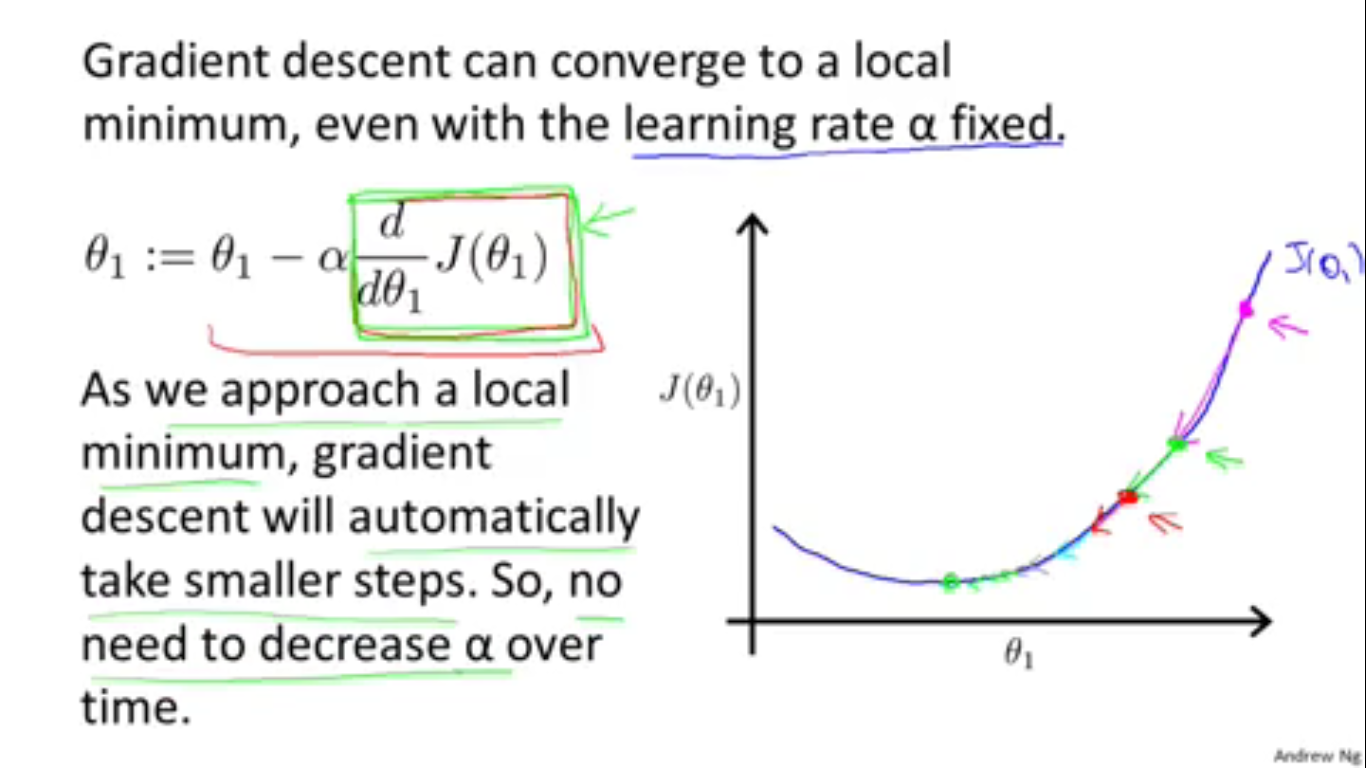
接着Andrew Ng解释了为什么”不需要在迭代的过程中改变 α “。因为 α 选择得合适的话,(如图)代价函数每次下降的高度是递减的(因为偏导数越来越小),这样的话就一定不会错过最小值了。

到此,梯度下降算法的介绍就告一段落了。介绍梯度下降算法是为了在线性回归问题中自动减小代价函数。于是我们回到线性回归中来。

要在线性回归中应用梯度下降算法,只需要求得线性回归的代价函数对 θj 求的偏导数。
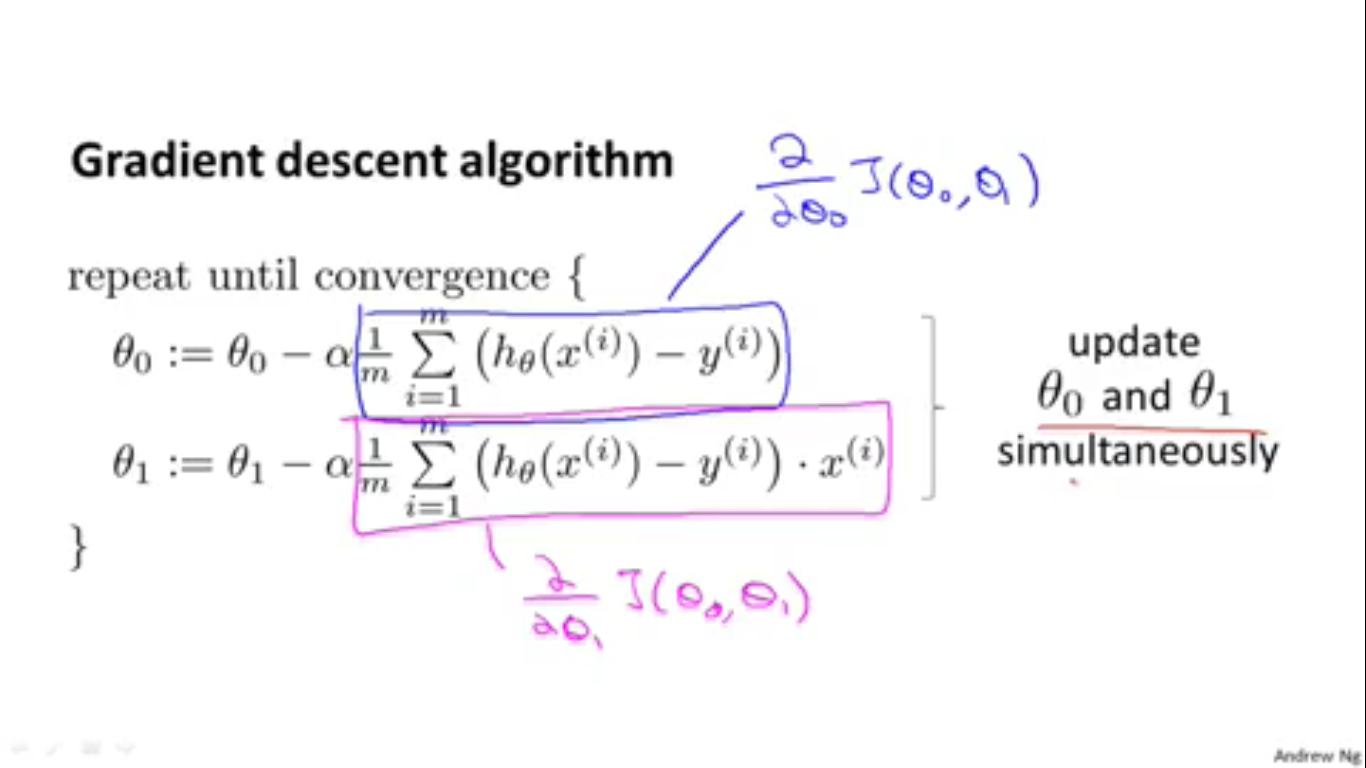
最后我们就得到了最小化线性回归代价函数的梯度下降算法。

这里还有一个问题。万一我们运气不好得到的是局部最优解怎么办呢?我们非常幸运。线性回归的代价函数是“凸函数“,或者说是“碗型”的。因此函数只有一个局部最优解(极小值),也就是全局最优解(最小值)。
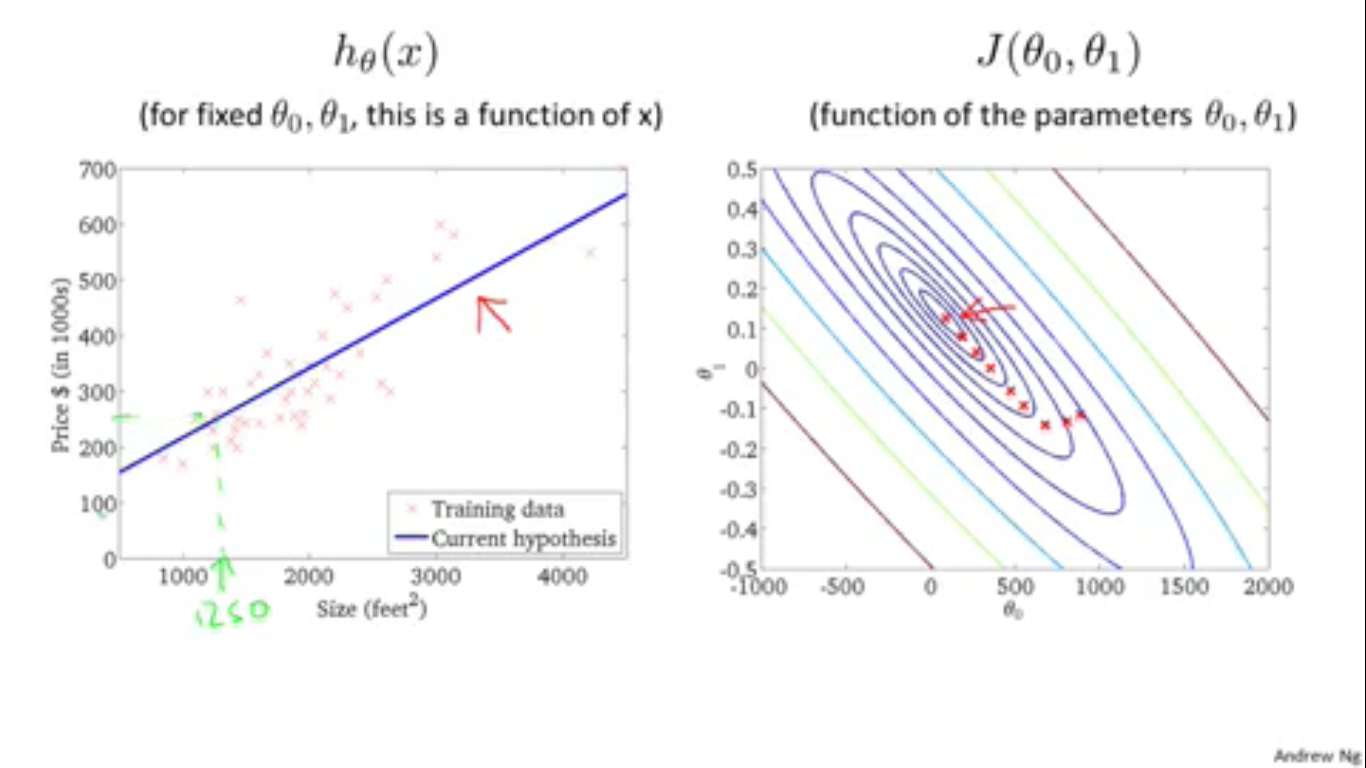
上图右半部分的红点表示 θ 在迭代的过程中改变过程,可以看出,最后代价函数收敛到了全局最优解的位置。一切都是那么的优美。
以上就是课程第一周的内容。在Andrew Ng的引导下,课程内容那个显得十分浅显有趣。所以请期待下一周的课程~















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









