







冬瓜哥最近闭关中,所以没经常出来分享。这次冬瓜哥想聊一聊高性能计算场景下的一例 IO 优化,这个例子非常偏向于应用层,而不是在底层架构上优化 IO 。
高性能计算是一个大场景,其由软件和硬件组成。
高性能计算领域的软硬件
硬件上,其就是一堆计算核心的组合,当然,这只是其本质,而表象上就有多种形式了,比如:多路 CPU 的服务器( HPC 领域内俗称胖节点)、一台服务器带着若干块 GPU 卡、一台服务器内多片众核心 CPU 、成千上万块独立的主板通过比如以太 /IB 网络互联起来。这些形态上本质都是一堆计算核心和一堆内存。
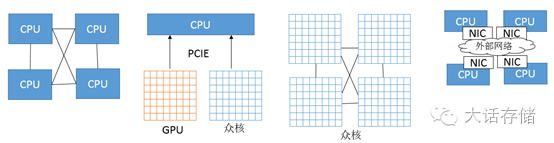
其中,胖节点的计算效率最高,编程简单,因为核心之间可以通过高速总线透明的共享内存,但是价格也最贵。
其次是众核心 CPU ,有些可共享内存,有些也不行,有些采用片上高速 DDR 可做缓存也可以直接寻址或者二者混合,这类形态需要有一定的编程模型和库来支撑了,并不是完全透明的,至少在想要达到更高性能的前提下。
再就是利用 GPU 内部的数千个计算核心,此时编程模型更加复杂了, GPU 和 CPU 无法共享内存(最新的一些 SDK 里也提供了可共享内存的框架),所以牵扯到数据和代码的传递,不过还好,数据和代码的传递还都是走内存和 PCIE 的,还是可以用单机控制的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3307
3307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









