






目标
学习建模过程,并了解调参的过程。
总结
由于自身机器的原因无法对特征进行提取并做工程,以至于影响到了此次学习的代码实践。所以此次学习我主要是用自己的理解对这些建模过程和调参的流程进行重述和总结。
经过此次学习,我对模型的优化和调参有了更深刻的理解,明白了什么是调参侠。如何对模型逼近最优解,选择一个合适的模型也尤为关键。但似乎此次学习给的参数几乎是最优的了,无法对其进行更优的调参,等下次学习看是否可以提高模型效果
逻辑回归模型
参考链接
逻辑回归虽说是回归模型,但是做的较多的是分类任务,尤其是二分类。
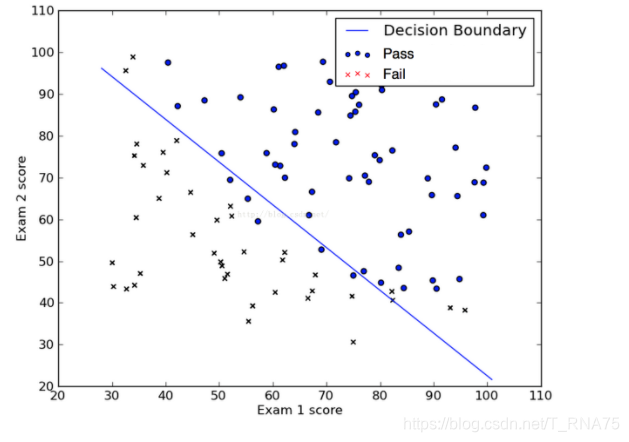
对分类问题划分一个边界,在边界的一次可以说是一类,另一次就是不同的。逻辑回归的成功之处在于,将原本输出结果范围可以非常大的θTX 通过sigmoid函数映射到(0,1),从而完成概率的估测。而直观地在二维空间理解逻辑回归,是sigmoid函数的特性,使得判定的阈值能够映射为平面的一条判定边界,当然随着特征的复杂化,判定边界可能是多种多样的样貌,但是它能够较好地把两类样本点分隔开,解决分类问题。求解逻辑回归参数的传统方法是梯度下降,构造为凸函数的代价函数后,每次沿着偏导方向(下降速度最快方向)迈进一小部分,直至N次迭代后到达最低点。
决策树模型
参考链接
听到决策树这个名字我们很容易联想到数据结构中的二叉树模型。其实二者很类似,甚至我们可以认为决策树是基于二叉树实现的。
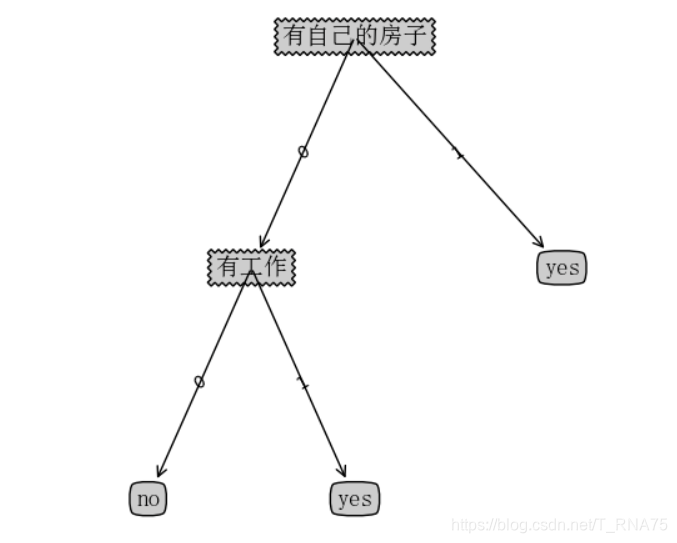
正如你所料 可视化后就是上图这种形式。
对代码层面不进行过多深究。就根据资料总结一些优点
- 可以可视化
- 数据可不预处理,对新手友好
- 可以同时处理数值变量和分类变量
- 可以处理多值输出问题
- 白盒模型可解释性强
缺点也是存在的
- 不能太过复杂,容易过拟合
- 容易遇到np难题
- 对一些文字概念难以理解
- 样本不均衡的情况下效果极差
集成模型
以下是较为常见的集成模型
GBDT模型
XGBoost模型
LightGBM模型
Catboost模型
对于集成模型,分成两个流派 一个是bagging 另一个是 boosting 两个流派各有千秋
采用boosting思想的模型有Adaboost, GBDT,Xgboost , lightgbm等等
两者的差别主要在与 bagging追求人人平等 而 boosting追求三六九等
接下来我们主要介绍二者的区别
- 样本选择上:bagging是又放回抽样,每次都是一个独立事件。而boosting方法需要每一轮的训练集不变只是对权重进行调整。
- 样例权重上:bagging使用均匀取样,所以每个样本的权重相等;而boosting方法会根据错误率进行实时改变。
- 预测函数上:也是权重方面的问题
- 并行计算上: Bagging方法中各个预测函数可以并行生成;而Boosting方法各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









