








注:本篇算是半讲解半翻译吧,我真的觉得这篇论文写的很难理解.......可能是我水平不够,也可能作者省略了一些具体信息,主要是提供了他的idea吧。
但是DeepLab这个思路的确是不错,所以这个论文还是有必要看的。
1、导引
• Our system works directly on the pixel representation, similarly to FCN ,Long et al. (2014).
他们的系统和FCN十分相似,也是直接对像素进行预测。
• we believe it is advantageous that segmentation is only used at a later stage, avoiding the commitment to premature decisions.
他们坚信分割的步骤放在最后的阶段要好一些,以此避免一些前面不成熟的预测。
• The main difference between our model and other state-of-the-art models is the combination of pixel-level CRFs and DCNN-based ‘unary terms’.
他们的模型和其他的state-of-art的模型最大的区别就是他们把基于像素水平的CRFs和基于DCNN的一元表示 相结合。
• Our approach instead treats every pixel as a CRF node, exploits long-range dependencies, and uses CRF inference to directly optimize a DCNN-driven cost function.
我们的方法不是把每一个像素点为CRF节点,而是利用远程依赖关系,并使用CRF推理直接优化DCNN驱动的损失函数。
• We note that mean field had been extensively studied for traditional image segmentation/ edge detection tasks, but recently Koltun showed that the inference can be very efficient for fully connected CRF and particularly effective in the context of semantic segmentation
我们注意到,平均场已被广泛研究用于传统图像分割/边缘检测任务,但是最近Koltun表明,对于全连接的CRF,推理可以是非常有效的,并且在语义分割的上下文中特别有效
• we have re-purposed and finetuned the publicly available VGG-16 NET into an efficient and effective dense feature extractor for our dense semantic image segmentation system.
他们已经重新构建并且微调了大家广泛应用的VGG16 layers的模型。把它变成了一个高效且有效的密集特征提取器,来应用到他们的密集图像语义分割系统中。
2、EFFICIENT DENSE SLIDING WINDOW FEATURE EXTRACTION WITH THE HOLE ALGORITHM
运用 孔算法 的高效密集滑动窗口特征提取we convert the fully-connected layers of VGG-16 into convolutional ones and run the network in a convolutional fashion on the image at its original resolution.
他们把VGG16模型中的全连接层全部转换成卷积层,然后运行这个网络。
其实得到的特征map还是很稀疏,
-------------------------------------------------------------------------------------------------------------------------------------------------
这里补充一下,VGG中卷积层的参数:stride=1,kernel_size = 3, padding =1,
所以进行卷积操作后:(H – 3 + 2 x 1)/1 + 1 = H,即卷积没有缩小图像的分辨率;
而VGG16Layer中有5个Maxpooling层,参数为:stride = 2, kernel_size = 2, padding =0;
所以:池化操作后:(H – 2)/2 + 1 = H/2,即图像分辨率减小一半,5个pooling层就是一共缩小了 2^5=32 倍,
-----------------------------------------------------------------------------------------------------------------------------------------------------
而本论文作者的目标是只让它缩小8倍就好,于是想了个办法:
We skip subsampling after the last two max-pooling layers in the network of VGG16 and modify the convolutional filters in the layers that follow them by introducing zeros to increase their length (2X in the last three convolutional layers and 4x in the first fully connected layer).
这句话要分成两部分看,前半部分是对池化层的操作,后半部分是对卷积核的操作。
①他们想skip the subsampling,
但是他们不是把pooling层直接去掉,而是把stride改成了1.然后还加上了padding = 1. 这个操作我在论文上似乎是没有看见详细说明,但是它的代码上是这么写的。这样的效果就是( H – 2 + 2 x 1) / 1 + 1 = H + 1,多了一个像素应该不影响把,它也没有详细解释这个问题,但是总之它把分辨率现在改回到基本不变了,所以就相当于少了两次缩小,就总共只缩小了8倍。
②分辨率是改大了,但是就因此出现了一个问题,就是后面卷积层卷积核的感受野变了,因此想要利用原先的VGG16的weights进行微调就有问题。
所以他们想的idea对原卷积核填充0,也就是hole,把kernel试着变大。
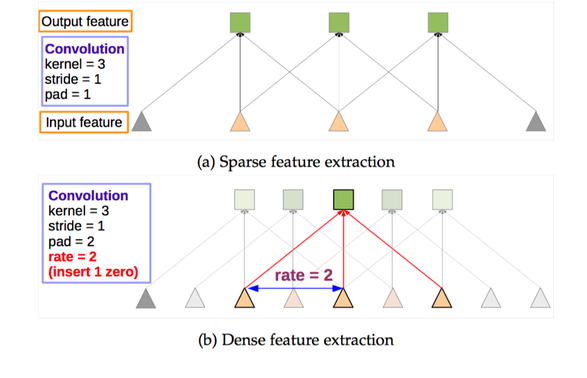
We can implement this more efficiently by keeping the filters intact and instead sparsely sample the feature maps on which they are applied on using an input stride of 2 or 4 pixels, respectively.
pool4的stride由2变为1,则紧接着的conv5_1, conv5_2和conv5_3中hole size为2。接着pool5由2变为1, 则后面的fc6中hole size为4。
这个就是他们提出的 hole algorithm
不过在具体实现上填0会带来额外的计算量,所以实际上是通过im2col调整像素的位置实现的,这里不展开,有兴趣的可以看看caffe源码(hole算法已经集成在caffe里了,在caffe里叫dilation)
于是,通过hole算法,得到了一个8s的feature map
3、CONTROLLING THE RECEPTIVE FIELD SIZE AND ACCELERATING DENSE COMPUTATION WITH CONVOLUTIONAL NETS
控制感受野的大小,并且加速卷积网络的 密集计算After converting the network to a fully convolutional one, the first fully connected layer has 4,096 filters of large 7x7 spatial size and becomes the computational bottleneck in our dense score map computation.
在把VGG的后面的全连接层转换为卷积层之后,比如说第一个全连接层(即原来的FC6)现在的卷积filter的size就是7x7大小的了,这个计算量就有些大…
所以他们的思路是:
We have addressed this practical problem by spatially subsampling (by simple decimation) the first FC layer to 4x4 (or 3x3) spatial size.
直接从7x7的范围中抽取一个4x4 (or 3x3)的范围以此来减小计算量、计算时间比原来减少了2-3倍。
4、DETAILED BOUNDARY RECOVERY: FULLY-CONNECTED CONDITIONAL RANDOM FIELDS AND MULTI-SCALE PREDICTION
细节边界恢复:完全连接的条件随机场和多尺寸预测4.1 DEEP CONVOLUTIONAL NETWORKS AND THE LOCALIZATION CHALLENGE
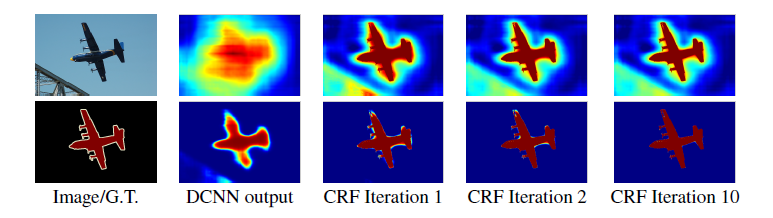
DCNN score maps can reliably predict the presence and rough position of objects in an image but are less well suited for pin-pointing their exact outline.
得分图可以可靠地预测图像中对象的存在和粗略位置,但不太适合用于刻画精准的轮廓。
Deeper models with multiple max-pooling layers have proven most successful in classification tasks, however their increased invariance and large receptive fields make the problem of inferring position from the scores at their top output levels more challenging.
就是说DCNN用于分类确实很成功,但是它们的不变性和很大的感受野对于从得分图中精确定位还是有些难度。所以作者提出来他们的想法:
4.2 FULLY-CONNECTED CONDITIONAL RANDOM FIELDS FOR ACCURATE LOCALIZATION
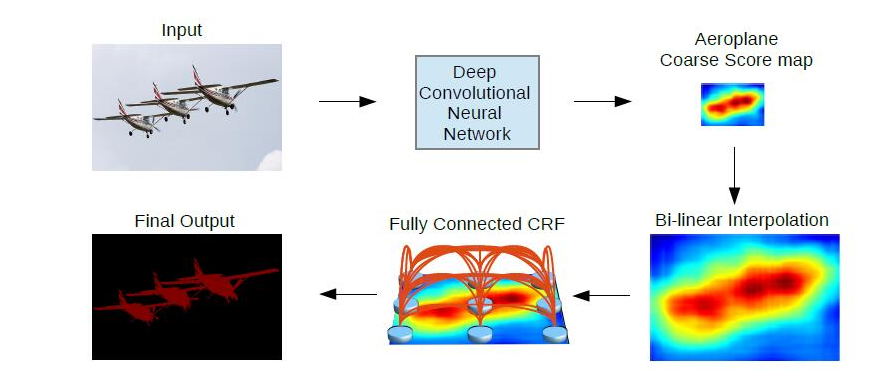
基于完全连接的条件随机域的准确定位CRF简单来说,能做到的就是在决定一个位置的像素值时(在这个paper里是label),会考虑周围邻居的像素值(label),这样能抹除一些噪音。但是通过CNN得到的feature map在一定程度上已经足够平滑了,所以short range的CRF没什么意义。于是作者采用了fully connected CRF,这样考虑的就是全局的信息了。
在全连接的CRF模型中,标签x 的能量可以表示为:
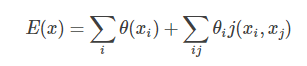
其中, θi(xi) 是一元能量项,代表着将像素 i分成label xi 的能量,二元能量项φp(xi,xj)是对像素点 i、j同时分割成xi、xj的能量。 二元能量项描述像素点与像素点之间的关系,鼓励相似像素分配相同的标签,而相差较大的像素分配不同标签,而这个“距离”的定义与颜色值和实际相对距离有关。所以这样CRF能够使图片尽量在边界处分割。最小化上面的能量就可以找到最有可能的分割。而全连接条件随机场的不同就在于,二元势函数描述的是每一个像素与其他所有像素的关系,所以叫“全连接”。

4.3 MULTI-SCALE PREDICTION
多尺度预测we attach to the input image and the output of each of the first four max pooling layers a two-layer MLP (first layer: 128 3x3 convolutional filters, second layer: 128 1x1 convolutional filters)whose feature map is concatenated to the main network’s last layer feature map.
这句话是说,我们在input image后面和 前面的4个maxpooling层的输出后面 都 紧接一个2层的MLP(Multi-layer Perceptron,多层感知器)。这个两层的MLP的构造为:第一层:128个3x3大小的卷积核,第二层:128个1xx大小的卷积核。然后把这写MLP得出的feature map 和主网络最后一层得出的feature map 排在一起。
所以最后送入到softmax layer的feature map 就得到了增强,也就是多了这5 *128个channels的值。(我个人感觉这个操作有点FCN中skip layer的意思)















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









