







DeepLab v1
ICLR 2015
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs.
文章目录
1 Background and Motivation
自LeCun等人以来,DCNN(深卷积神经网络)一直是文档识别的首选方法,但直到最近才成为 high-level vision 研究(例如 image classification and object detection)的主流。在过去的两年中,DCNN将计算机视觉系统的性能推到了许多高级问题的高度,这些高级问题包括 image classification ,object detection,fine-grained categorization等。
在处理high-level问题时发现,以end-to-end 的方式训练的DCNN所产生的结果要比依传统的视觉算法(SIFT.或HOG.)的效果要好。 这种成功可以部分归功于DCNN对局部图像变换的内在不变性,这根本是源于重复的池化和下采样组合层。平移不变性增强了对数据的层次抽象的能力。 虽然这种不变性是high-level vision tasks所需要的,但它可能会阻碍 low-level tasks,例如姿势估计和语义分割,在这任务中我们希望得到精确定位而不是抽像的空间细节。而对于精确的对象分割,DCNN的最后一层的响应没有得到足够的定位。
在将DCNN应用于 image labeling 任务时,存在两个技术障碍:
- signal downsampling(信号下采样)
- spatial insensitivity(空间“不敏感”)。
第一个问题:在标准DCNN的每一层上重复进行最大池化和降采样而引起的信号分辨率的降低的问题。作者采用atrous(带孔)算法来扩展感受野,以便能够获得更多的上下文信息。
第二个问题:从分类器中获取以对象为中心的决策需要对空间变换的不变性,从而固有地限制了DCNN模型的定位精度。作者采用完全连接的条件随机场(DenseCRF),从而提高了模型捕获精细细节的能力。
作者通过将最终DCNN层的响应与完全连接的条件随机场(CRF)结合起来,以解决 pixel-level classification 的任务,最终克服了深层网络的局限性。
2 Advantages
DeepLab的三个主要优点:
- 速度:通过atrous算法,Dense DCNN以8 fps的速度运行,而完全连接的CRF的平均场推断则需要0.5秒;
- 精度:在PASCAL语义分割挑战中获得了第二名;
- 简单:DeepLab系统由两个相当完善的模块(DCNN和CRF)组成。
3 Method
3.1 Convolutional Neural Networks for Dense image labeling
作者描述了如何将VGG-16网络重新利用和发现,并将其转变为一种有效的密集特征提取器,用于本文的密集语义图像分割系统。
密集空间分数评估是密集CNN功能提取器成功的工具。具体操作为将VGG-16的FC层转换为卷积层,并以原始分辨率对图像进行卷积得到非常稀疏的计算检测得分(32步幅)。为了计算更密集的分数(8步幅),作者在网络最后两个最大池化层之后跳过下采样(padiing到原来的大小),再通过2或4的采样率的空洞卷积对特征图做采样扩大感受野,缩小步幅。这种方法被称为空洞算法,关于 空洞卷积如下:

Atrous Convolution(中文叫做空洞卷积) 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(正常的 convolution 是 dilatation rate 1)


蓝色为输入图像,青色为输出图像。可以看一下dilated conv原始论文中的示意图:

(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv),©图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
训练时将预训练的VGG16的权重做fine-tune,损失函数取是输出的特征图与ground truth下采样8倍做交叉熵和;测试时取输出图双线性上采样8倍得到结果。但DCNN的预测物体的位置是粗略的,没有确切的轮廓。
3.2 Detailed Boundary Recovery:fully-connected conditional random fields and multi-scale prediction
DCNN score图(如下图)可以可靠地预测图像中对象的存在和大致位置,但不能精确指出其确切轮廓。卷积网络在分类精度和定位精度之间存在一个自然的折中:在卷积网络中,因为有多个最大池化层和下采样的重复组合层使得模型的具有平移不变性,我们在其输出的high-level的基础上做定位是比较难的。

针对以上问题,作者提出了两个方向:
- 第一种方法是利用卷积网络中多层的信息,以便更好地估计对象边界;
- 第二种方法是采用超像素表示,从本质上将定位任务委托给低级分割方法。
DeepLab是结合了DCNNs的识别能力和全连接的CRF的细粒度定位精度,寻求一个结合的方法,结果证明能够产生准确的语义分割结果。
精确定位的条件随机场(CRF)

传统上,条件随机场(CRF)已用于平滑噪声分割图。本文中使用的DCNN体系结构产生了得分图和语义标签预测,它们在质上有所不同(如图2所示),分数图通常很平滑并且可以产生均匀的分类结果。在这种情况下,使用短距离CRF可能是有害的,因为我们的目标应该是恢复详细的局部结构而不是进一步使其平滑。将对比敏感的potentials与局部CRF结合使用可以潜在地改善定位,但仍会丢失薄结构,并且通常需要解决昂贵的离散优化问题。为了克服短距离CRF的局限性,作者将Krâhenbóuhl&Koltun的系统CRF模型集成到了本文的系统中(CRF在语义分割上的应用.)。模型应用能量函数:
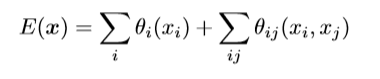
- x x x是像素的标签分布
- 使用一元电势 θ i = − l o g P ( x i ) \theta _{i}=-log P\left ( x_{i} \right ) θi=−logP(xi),其中 P ( x i ) P\left ( x_{i} \right ) P(xi)是DCNN计算的像素i处的标签分配概率
- 成对电位 θ i j ( x i , x j ) = μ ( x i , x j ) ∑ m = 1 K w m ⋅ k m ( f i , f j ) \theta _{ij}(x_{i},x_{j})=\mu (x_{i},x_{j})\sum_{m=1}^{K}w_{m}\cdot k^{m}(f_{i},f_{j}) θij(xi,xj)=μ(xi,xj)m=1∑Kwm⋅km(fi,fj)其中,如果 x i ≠ x j x_{i}\neq x_{j} xi=xj, μ ( x i , x j ) = 1 \mu (x_{i},x_{j})=1 μ(xi,xj)=1,否则为0。
内核是: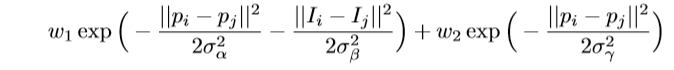
- 第一个内核同时取决于像素位置 p p p(和像素颜色强度 I I I;第二个内核仅取决于像素位置。超参数 σ α \sigma _{\alpha } σα, σ β \sigma _{\beta } σβ和 σ γ \sigma _{\gamma } σγ控制高斯核的“尺度”。
多尺度预测
论文还探讨了使用多尺度预测提高边界定位效果。具体的,在输入图像和前四个最大池化层的输出上附加了两层的MLP(第一层是128个3×33×3卷积,第二层是128个1×11×1卷积),最终输出的特征映射送到模型的最后一层辅助预测,合起来模型最后的softmax层输入特征多了5×128=6405×128=640个通道,实验表示多尺度有助于提升预测结果,但是效果不如CRF明显。
4 Experiments
4.1 Experimental details
DeepLab由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。在对DCNN做了fine-tune后,对CRF做交叉验证。
- Dataset:作者在PASCAL VOC 2012 segmentation benchmark 上测试了DeepLab模型,该模型由20个前景对象类和一个背景类组成。其中: training-1464,validation-1449,testing-1456个图像。Hariharan等人提供的额外annotations产生了10582张训练图像,扩充了数据集。 性能是根据21个类别的IOU平均值来衡量的。
- DCNN模型:权重采用预训练的VGG16
- DCNN损失函数:交叉熵
- 训练器:SGD,batch=20
- 学习率:初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1
- 权重:0.9的动量, 0.0005的衰减
4.2 Experimental results
在验证集上的表现

可以看出带CRF和多尺度的(MSc)的DeepLab模型效果明显上升了。
DeepLab 和 DeepLab-CRF 的视觉比较

可以看出使用完全连接的CRF可以显着改善结果,从而使模型可以准确地捕获复杂的对象边界。
多尺度的视觉表现

利用多尺度特征可以稍微完善对象边界。
Field of View
在使用离散卷积的过程中,可控制离散卷积的采样率来扩展特征感受野的范围,不同配置的参数如下:
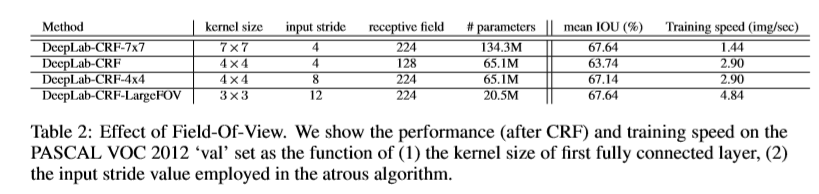
沿ObjectBoundaries的平均像素IOU

通过完全连接的CRF利用来自中间层的多尺度特征并细分分段结果显着改善了对象边界周围的结果。
与最新技术的比较

与最新技术相比,DeepLab模型能够捕获复杂的对象边界。
测试集结果

最佳模型DeepLab-MSc-CRF-LargeFOV通过同时使用多尺度功能和大FOV来获得71.6%的最佳性能。
5 Conclusion
- 结合DCNN和DenseCRFs,产生了一种新颖的方法,该方法能够生成语义上准确的预测和详细的细分图,同时计算效率高。实验结果表明,所提出的方法大大提高了具有挑战性的PASCAL VOC 2012语义图像分割任务的最新水平。
- DeepLab是卷积神经网络和概率图模型的交集,后续可考虑将CNN和CRF结合到一起做end-to-end训练。
- 可以尝试把DeepLab应用到更多的数据集上,比如depth maps or videos。















 2732
2732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









