






转载公众号 | 知识图谱科技
在我们关于用于知识管理的 AI 系列的这一部分中,您将了解知识图谱如何改进检索增强生成 (RAG) 以在公司中进行信息检索。
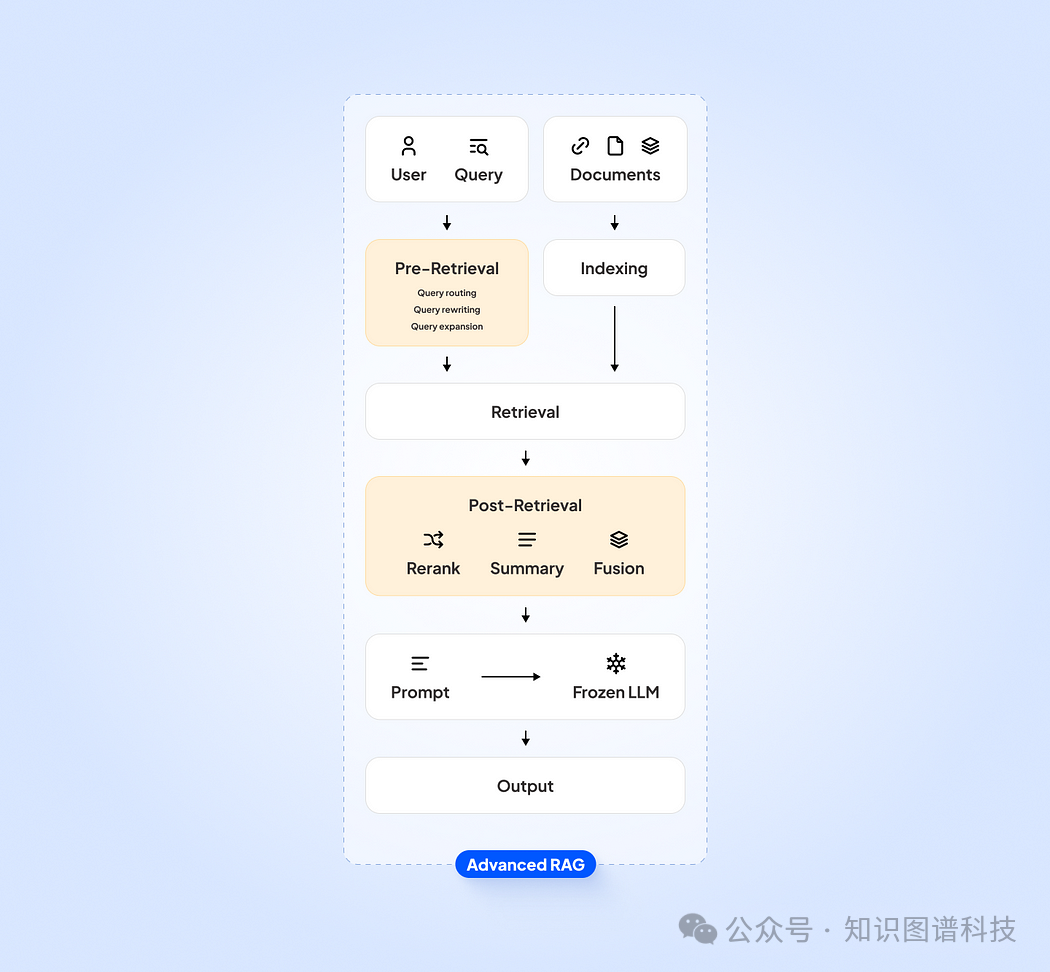 高级 RAG 流程
高级 RAG 流程
介绍
在用于公司知识管理的 AI 系统中,检索增强生成(RAG)是一种流行的架构,可以克服大型语言模型(LLM)的一些限制。
但是,RAG 存在局限性,包括难以处理结构化和非结构化公司数据的混合。解决这些限制的一种方法是将 RAG 与知识图谱(KG)相结合。
在本文中,我们将解释 Graph RAG (GRAG)如何通过使用知识图谱来提供更准确和上下文更丰富的答案,从而增强传统的RAG方法。
这不要与其他(互补)方法混淆,其中 LLM 用于提取结构化信息以构建知识图谱(也称为“Graph RAG”),例如在 Microsoft 最近的库中。
该帖子由五个主题组成:
1. 回顾:LLM 的局限性和 RAG 简介
2. 问题:传统 RAG 的局限性
3. 科普:什么是知识图谱?
4.解决方案:GRAG 简介
5.深入探讨:了解 GRAG 流程
6. 影响:GRAG 的性能影响
1. 回顾:LLM 的局限性和 RAG 简介
大型语言模型 (LLM), 如 Llama 或 Gemini 根据广泛的训练数据生成文本。尽管 LLM 的功能令人印象深刻,但它们在企业知识检索方面存在一些限制:
无法访问私人信息:LLM 接受过公开可用数据的培训,因此他们缺乏特定于公司的私人知识。
1. 幻觉: 众所周知,LLM 经常产生合理但完全错误的反应,称为 “幻觉”。
2. 静态知识: LLM 的知识是静态的,仅限于他们最近培训中包含的数据。
这意味着 LLM 在生成文本方面非常出色,但在知识管理方面却很糟糕。进入 Retrieval Augmented Generation (RAG)。
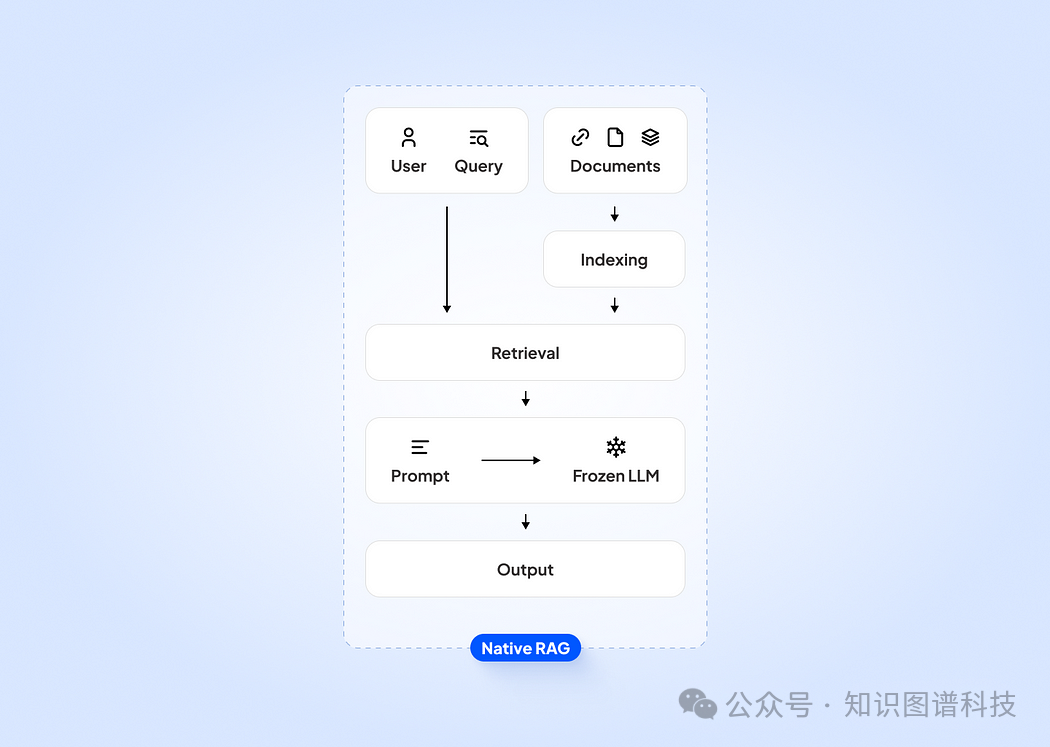
Simple RAG
检索增强生成(RAG)是一种将外部数据源与LLM(大型语言模型)结合的AI架构。其工作分为两步:
1. 检索:使用用户查询从数据库(例如公司知识库)中检索相关信息(“上下文”)。
2. 生成:根据检索到的上下文指示LLM回答用户的查询。
通过为 LLM 提供上下文作为参考,RAG 解决了前面提到的限制。有关基本 RAG 的工作原理以及它如何与 LLM 配合使用的更多背景信息,请查看我们之前的介绍性文章或 AppliedAI 的这篇详细摘要。
2. 动机:RAG 的局限性
尽管 RAG 具有优势和受欢迎程度,但在应用于知识管理时仍然存在局限性。这些限制与特定公司数据的上下文检索有关:
使用通用模型进行检索不佳: 检索模型(嵌入编码器)通常在 Internet 数据上进行训练,因此它们可能很难在特定领域的公司知识中找到正确的上下文。
拼写错误与非拼写错误的处理: 嵌入编码器通常可以容忍拼写错误。这对于一般查询(例如,搜索 “curiosty” 与 “curiosity”) 很有帮助,但对于特定于上下文的查询可能会有问题,例如,“Airbus A320” 与 “Airbus A330”。
向 LLM 提供不正确的上下文可能会用错误或捏造的事实来污染答案。提供看似合理的答案但信息不正确可能会削弱用户对系统的信心,甚至更糟糕的是,会导致现实世界中的错误。
其中一些问题可以通过提示模板来解决,这些模板指示 LLM 忽略不相关的信息,但这只能到此程度才能改善结果。
知识图谱 RAG (GRAG) 是解决公司数据这些限制的一种令人兴奋的方法。
科普:什么是知识图谱?
知识图谱是信息的表示形式,包括实体及其之间的关系。这些信息通常存储在 Neo4J 或 Curiosity 等图形数据库中,有两个主要组件:
节点: 这些表示对象、文件或人员等实体。例如,节点可以是公司 (Curiosity) 或位置 (Munich)。
边: 这些定义节点之间的关系。例如,边可能指示Curiosity位于慕尼黑。
根据图形数据库的类型,节点和边缘也可以具有属性 。
 知识图谱表示实体(文件、人员等)和边缘(关系)
知识图谱表示实体(文件、人员等)和边缘(关系)
解决方案:Graph RAG 简介
Graph RAG (GRAG) 使用知识图谱来提高知识检索的 RAG 性能。它的工作原理是使用存储在图中的结构化和链接信息增强检索,并且越来越受欢迎(例如这里)。
GRAG 的工作原理是向标准 RAG 流程添加步骤。它使用图谱中的信息来增强结果的检索和过滤方式,然后再将它们作为上下文发送到 LLM 以生成答案。
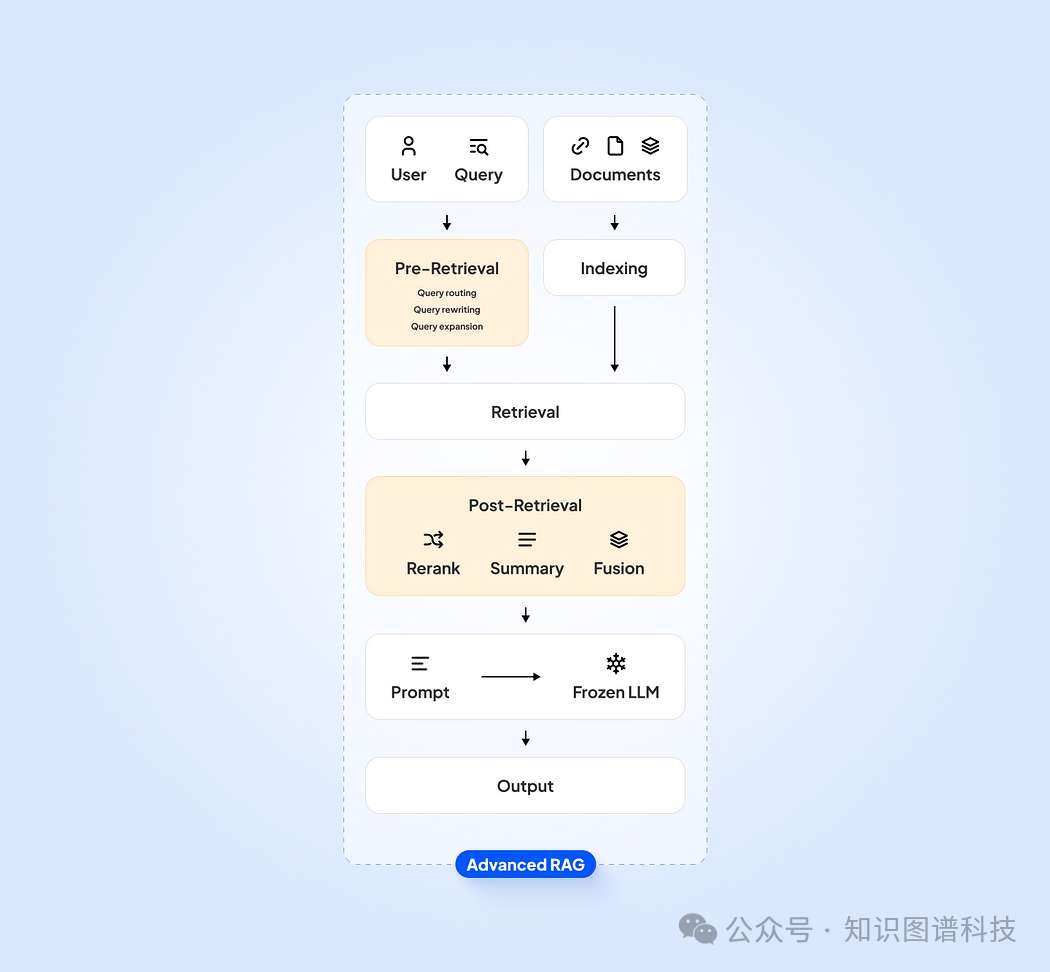 高级 RAG(无知识图谱)
高级 RAG(无知识图谱)
GRAG 增强标准 RAG 的主要方式有三种:
除了文档嵌入之外,它还允许您使用文档中捕获的实体(例如,部件号、流程引用等)来计算图形嵌入。这些代表数据中有意义的连接,并有助于过滤掉长文档中的干扰。
它允许您根据用户上下文(例如部门)和查询中捕获的实体来筛选结果。
它允许您根据上下文和捕获的实体提升/降级结果。
这些技术的组合有助于检索 LLM 准确回答问题的最佳上下文,并考虑结构化信息。
深入探讨:了解 GRAG 流程
更深入地挖掘,以下部分为您提供了如何构建 GRAG 流的快速概述。
步骤1:预处理数据并构建知识图谱(索引时间)
预处理非结构化文本数据(包括分块)并将其添加到图形中,使用命名实体识别 (NER) 提取实体、引用和关系。
将结构化数据添加到知识图谱中(例如,机器引用)。
将结构化数据、文本和捕获的实体连接到知识图谱,从而创建任何给定文档与图中其他数据之间联系的表示形式。
在非结构化文本上训练文档嵌入模型。
在连接到图中文本的对象结构上训练图嵌入模型,例如,使用 OSS 库 Catalyst
步骤 2:处理用户问题(查询时间)
当用户提交问题时,对其进行分析以识别关键实体和引用(例如机器参考和时间段)以筛选候选文档。
使用文档嵌入模型对问题文本进行编码。
使用图形嵌入模型对连接到文档的对象的连接进行编码。
步骤 3:检索和筛选上下文(查询时间)
结合图形和文档嵌入以找到最佳候选结果(又名“向量搜索”),例如,match使用 OSS 库 HNSW。
使用图形结构筛选候选结果,例如,使用从查询中捕获的用户上下文和实体。
通过根据图表中的连接提升或降级候选结果来进一步优化候选结果。
步骤4:生成答案(查询时间)
向 LLM 提供用户查询,并指示它根据排名靠前的结果 (块) 提供的上下文进行回答。
将响应返回给用户,包括对结果(“来源”)的引用,以提高透明度和可信度。
影响:GRAG 的影响
设置知识图谱、提取实体、训练更多模型和添加提升逻辑听起来像是一项艰巨的工作。那么,这真的值得吗?
从我们的角度来看,答案是响亮的“Yes!”。首先,我们紧密集成的解决方案 Curiosity 让我们可以在几天内从文档过渡到完整的 GRAG 解决方案。
然而,更重要的是,由于预处理和过滤步骤,提供给 LLM 的上下文质量得到了显著提高,这反过来又提高了响应的质量。
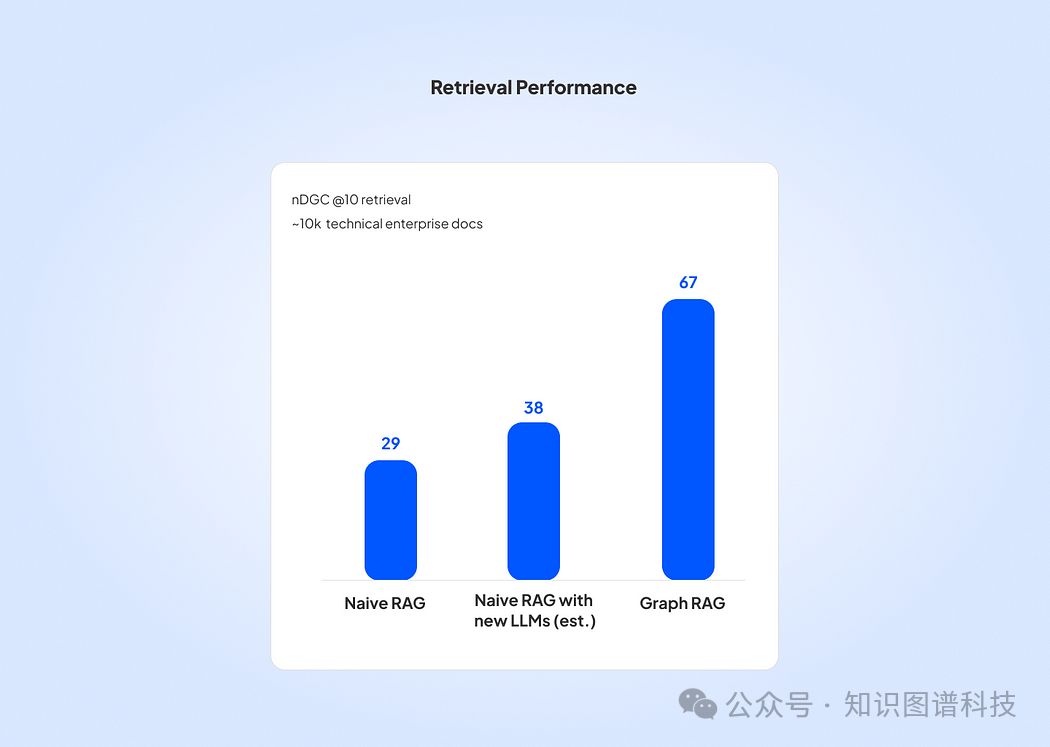
在 2023 年的一个项目中,我们衡量了 GRAG 与朴素 RAG 相比对大量专有技术文档的影响。
 Graph RAG 性能提升
Graph RAG 性能提升
我们使用 NDCG 分数(Normalized Discounted Cumulative Gain) 来衡量性能,该分数通过检查它们返回的有序列表的相关性来评估排名检索系统的性能。
使用图表进行检索的影响是深远的:对于前 10 个文档,本机 RAG 系统的 NDGC 分数为 29。估计 LLM 更新的影响,我们估计可能增加到 38 个。然而,使用 Graph RAG 时,NDGC 分数跃升至 67。
使用该图表的改进在与专家用户的测试中得到证实,这表明 GRAG 是正确的选择——至少对于此应用程序。
总结
总之,GRAG 通过将预处理和结构整合到知识图谱中来增强传统的 RAG 模型。这有助于考虑企业数据中的复杂关系,从而提高文档检索和上下文质量。改进的上下文有助于 LLM 生成更准确且上下文更丰富的答案。
在 Curiosity,我们计划继续使用和改进 GRAG,我们对它为企业知识管理带来的可能性感到兴奋。我们还对如何使用 LLM 构建知识图谱来补充 GRAG 感兴趣,从而使 LLM 和图数据库之间的交互完整循环。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









