







 超级会员免费看
超级会员免费看
本文介绍:本专栏文章不会讲太复杂的定义,将从小白的角度去进行讲解,为大家节省时间,高效去做实验,文章将会简单介绍一下相关模块(也会附带相关论文链接,有兴趣可以阅读,可以作为论文文献),本专栏主要专注于YOLO改进实战!适用于小白入门也可以水论文,大佬跳过!!!
文章适用人群:研一、准研究生(研0)、少部分本科生、着急毕业水论文的各位
更新时间:每天1~3篇左右,本专栏文章至少50+篇,如果需要单独设计可以联系我,咨询一下
售后:购买专栏后在运行时有问题直接私聊我,大部分都是环境配置问题,我会录教程带大家配置,保证代码畅通无阻!
新专栏福利:帮助入门小白缝合模块,创新模块(先到先得,名额有限,论文从此不缺创新点)!
专栏通知:专栏文章大于20篇时将涨价,早买有优惠,感谢各位读者支持!(更新时间:2024/12/03)
目录
“CBAM”同学简介
个人简介:大家好!我是CBAM模块,中文名是“卷积块注意模块”。别看我名字很长,其实我就是个“智能关注器”,能帮计算机更好地看懂图像。我有两个绝技:一个叫“通道注意力”,能帮助模型选出哪些特征更重要,就像从一堆声音中挑出最悦耳的旋律;另一个叫“空间注意力”,负责搞清楚图像的哪些区域是关键,就像在茫茫人海中锁定目标人物的脸。这样一来,在图像识别和理解的过程中,我能让电脑专注于“精华”,不浪费时间在“没用的细节”上。总之,我的使命是:帮助模型像人类一样,聪明地将注意力放在重要的信息上!
一、将主角“CBAM”加入到YOLO大家庭(代码)中
CBAM代码展示:
#-----------------------------------CBAM----------------------------------#
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.ca(x)
result = out * self.sa(out)
return result
使用步骤:
- 找到并打开“/ultralytics-main/ultralytics/nn/modules/block.py”文件,在箭头位置添加CBAM模块,如图1
- 复制上面提供的CBAM代码粘贴进block.py的57行(你们的不一定是57行,注意附近内容),如图2
- 在包结构中导入CBAM类,注意看,这步最容易错,图中有详解,如图3和图4
- 找到task.py导入你的新模块,task.py位置和模块导入方法,如图5
- 编写parse_model函数,首先你需要按住Ctrl和F,搜索def parse_model并跳转到这个函数的定义,然后开始往下滑找到如图6所示的位置(行数不一定相同,注意周围内容),并且在图示位置比着图6添加相关内容(直接复制粘贴下面代码块的内容到图中位置)
elif m is CBAM:
c1 = ch[f]
args =[c1]
图示教程:
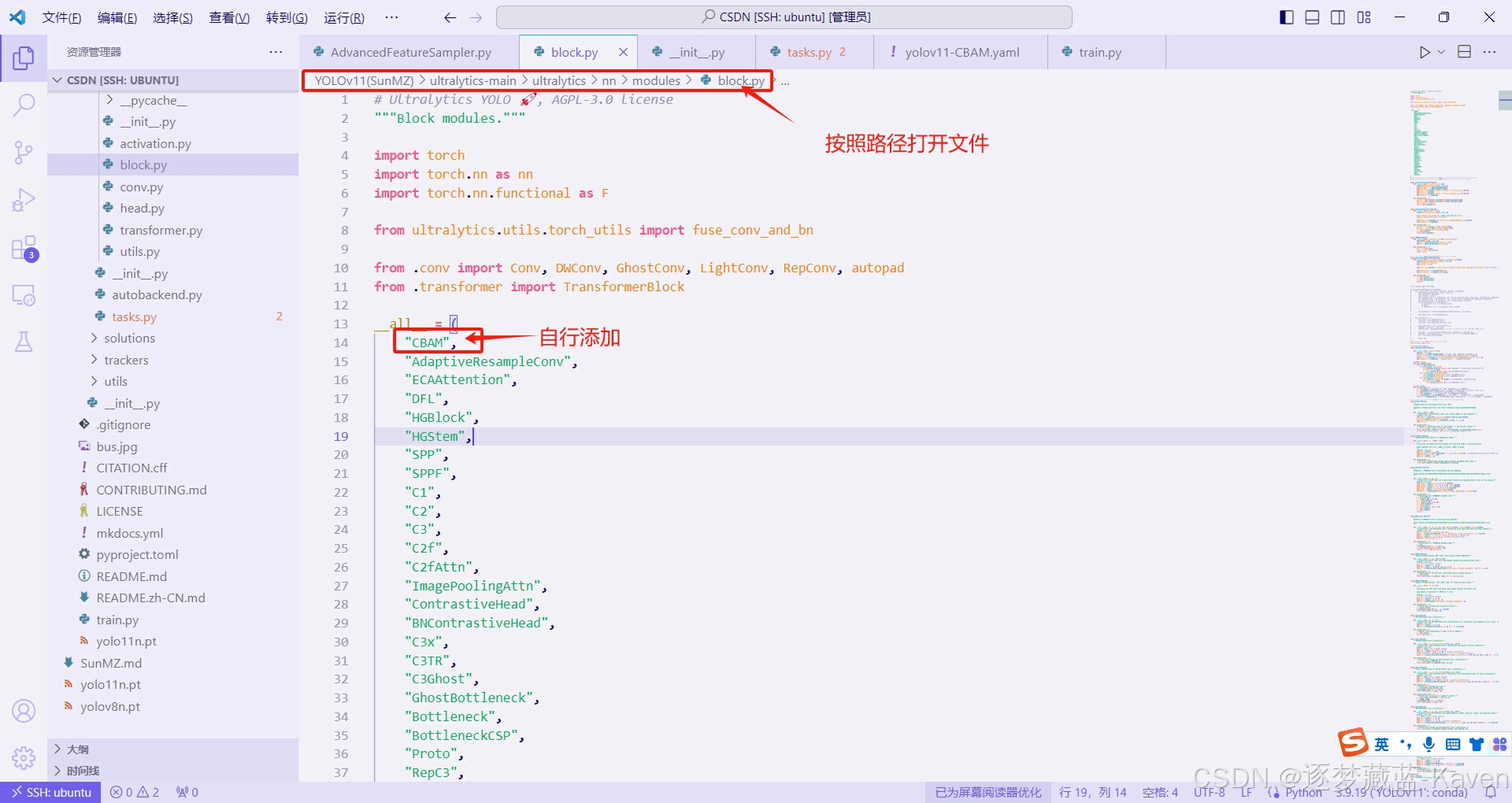 图1(上图)
图1(上图)
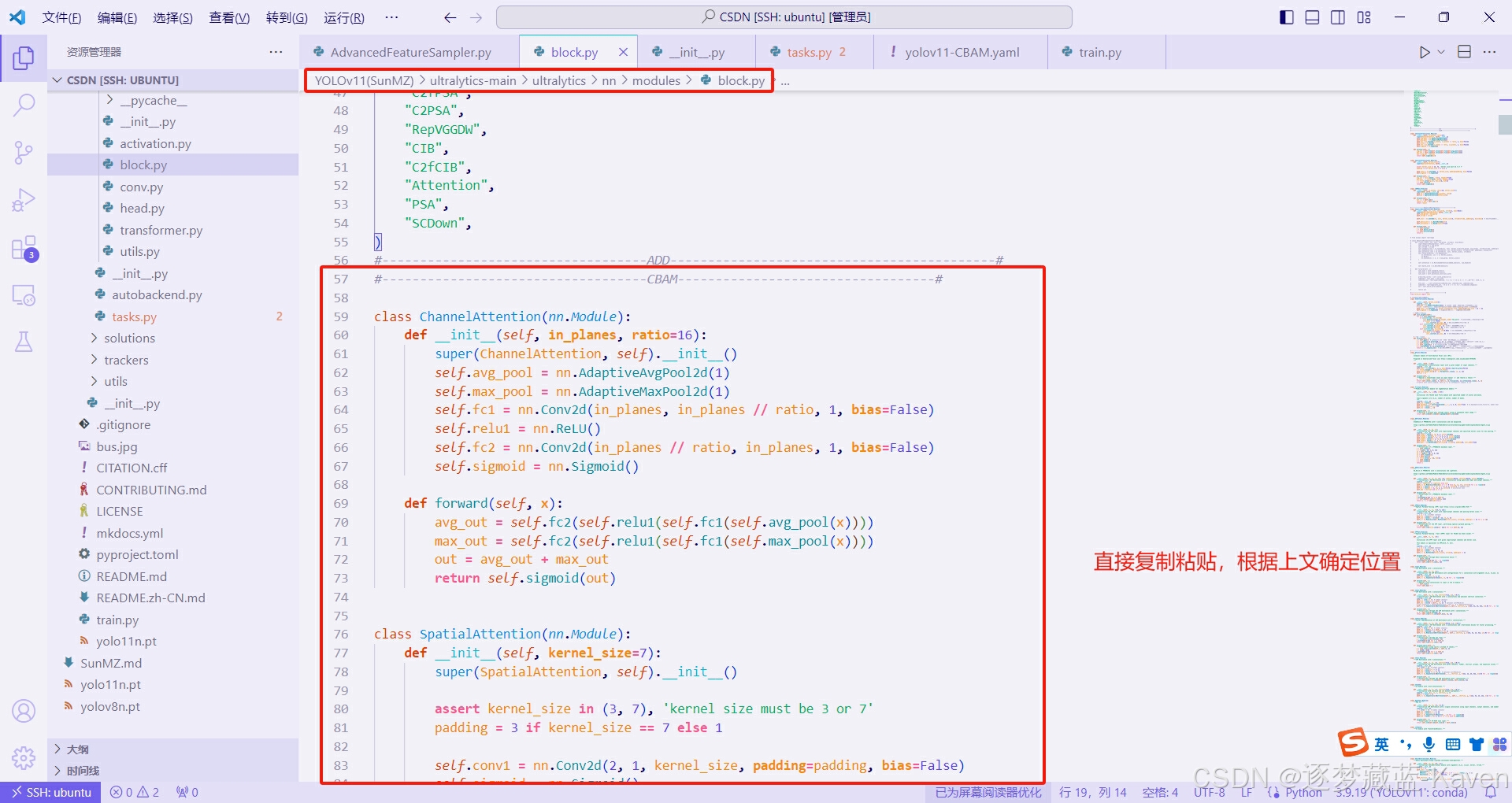 图2(上图)
图2(上图)
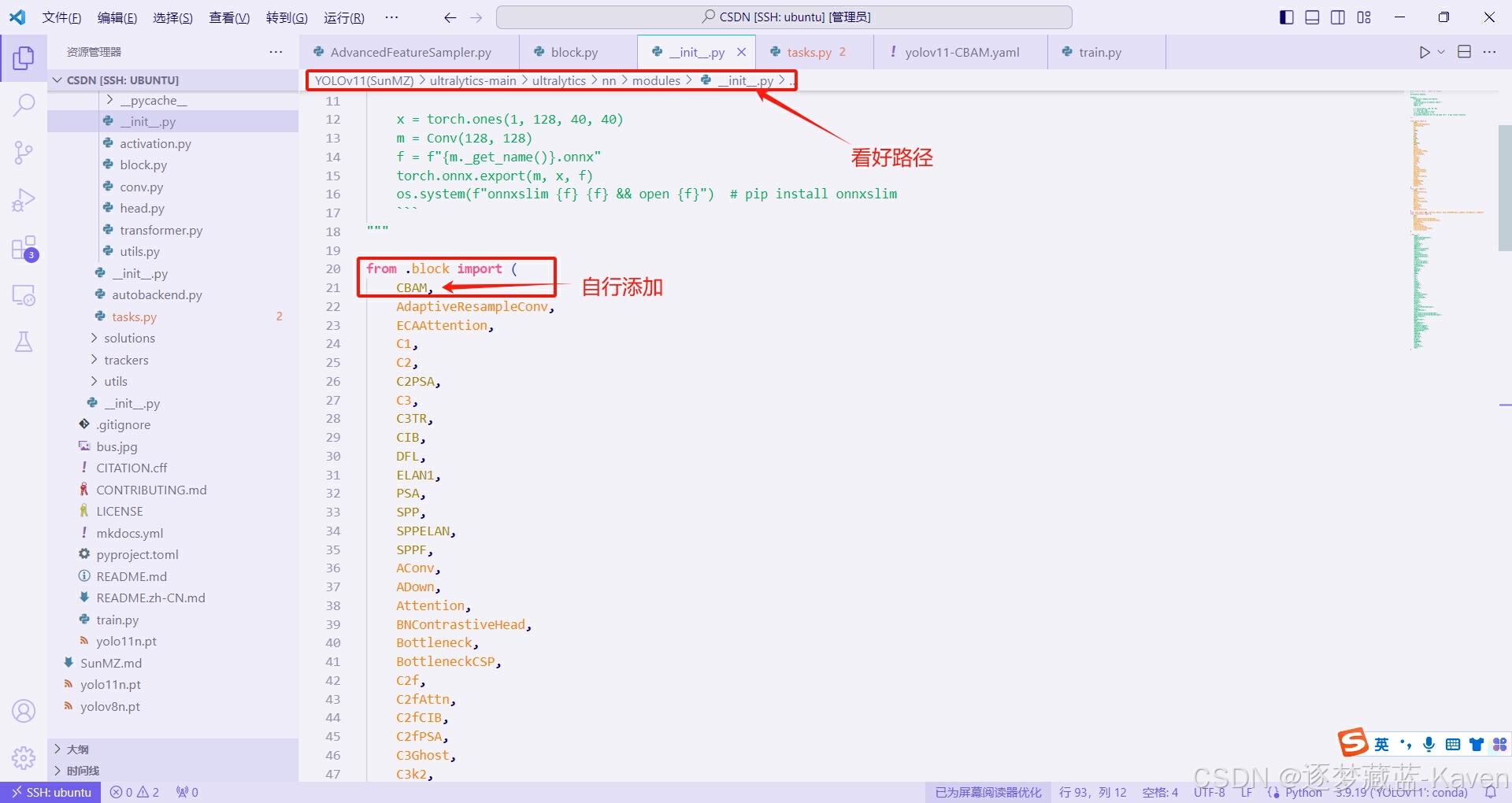 图3(上图)
图3(上图)
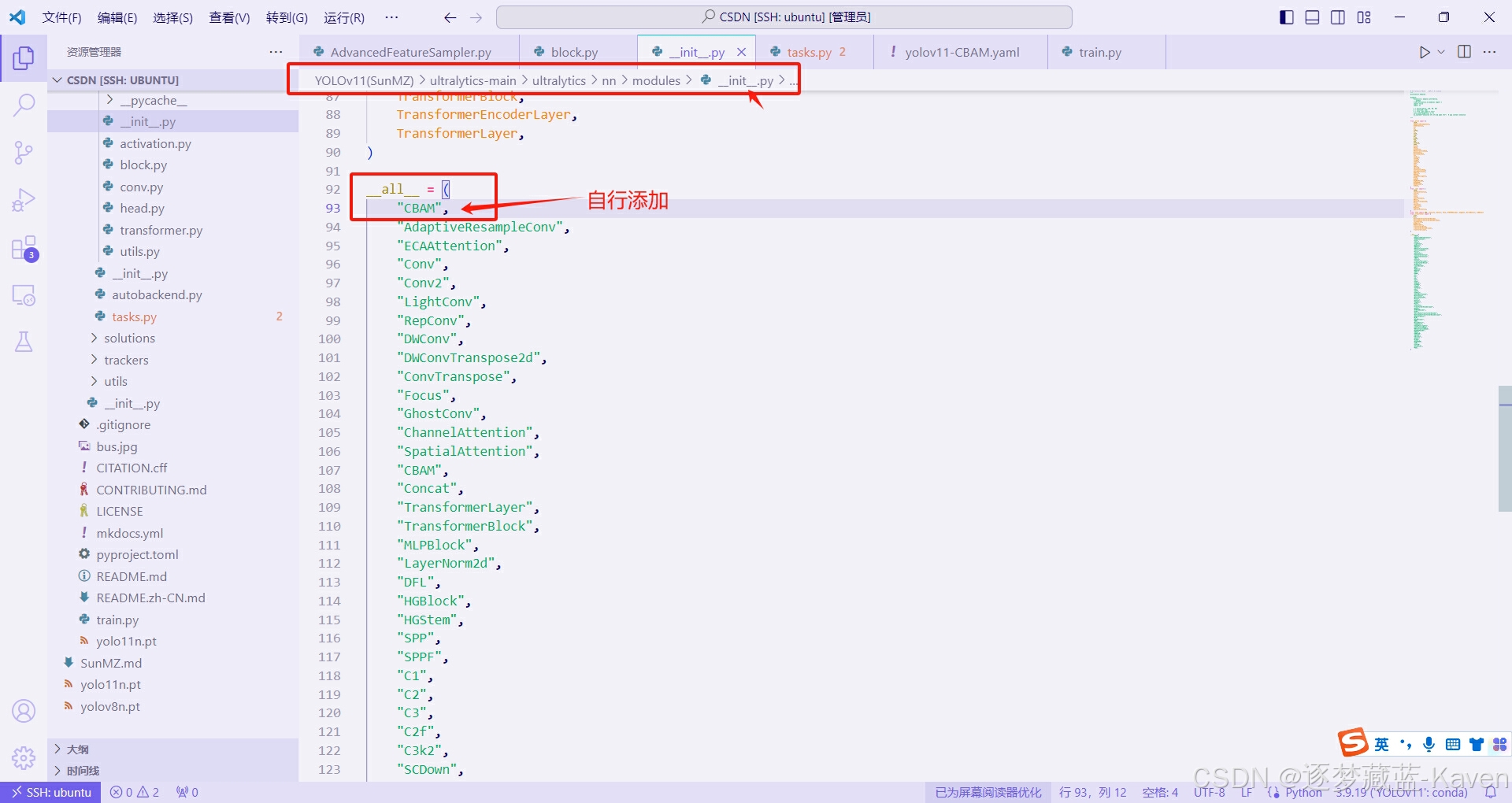 图4(上图)
图4(上图)
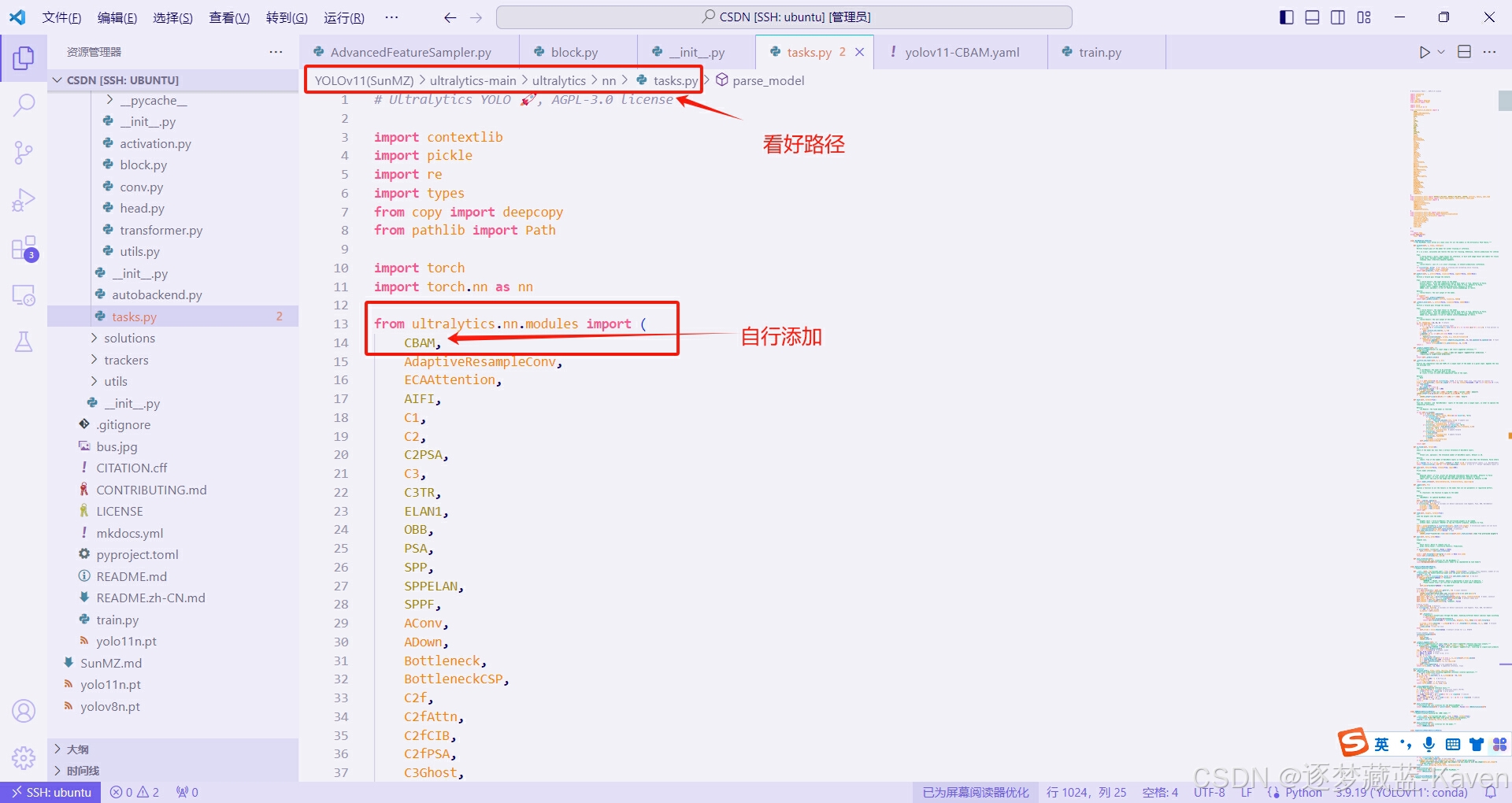 图5(上图)
图5(上图)
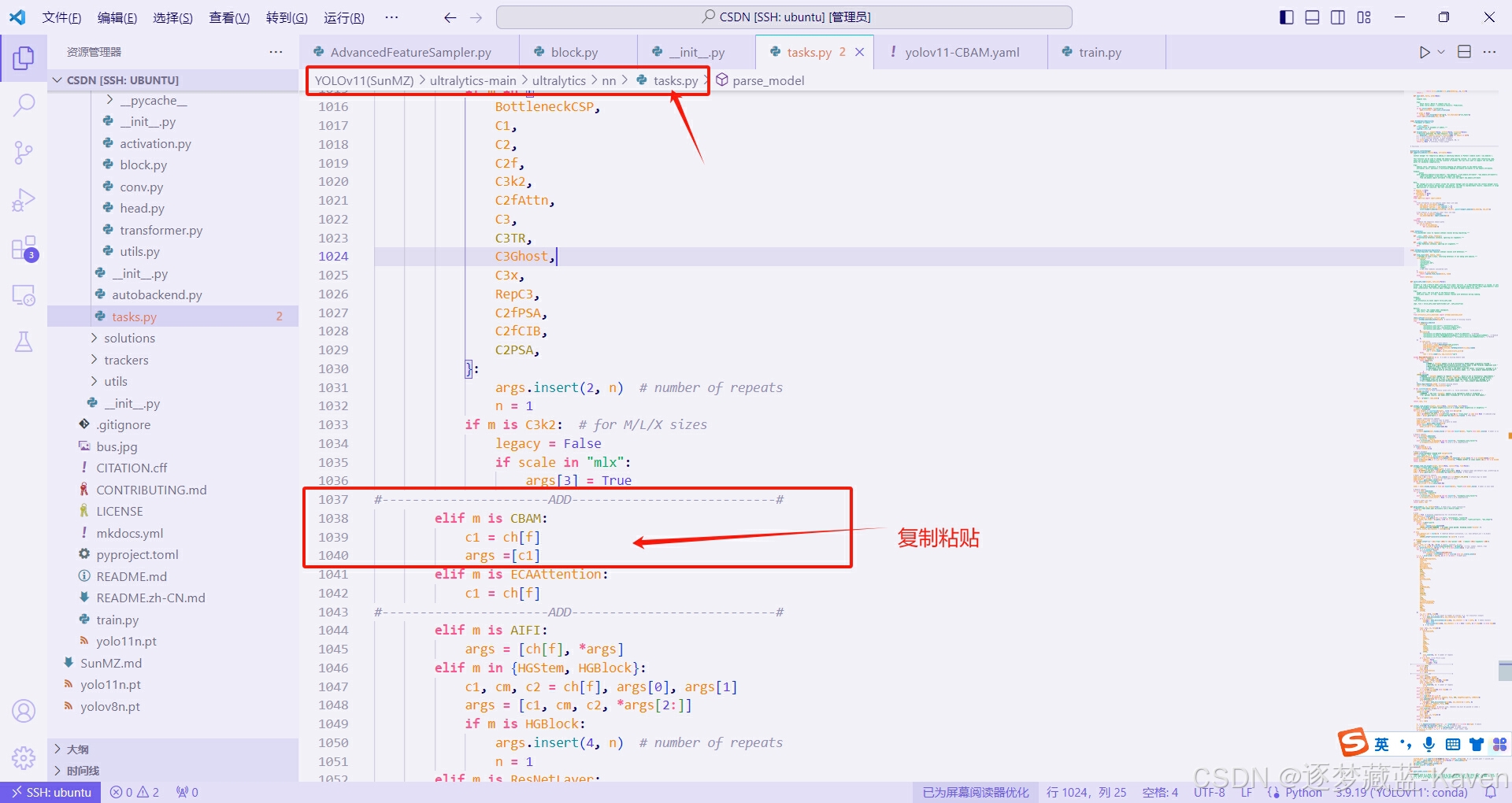 图6(上图)
图6(上图)
二、模型文件中加入CBAM注意力机制
步骤:
- 如图7所示,在相应位置创建model v11文件夹(用于存放新建的模型文件)和yolov11-CBAM.yaml模型文件
- 复制下面yolov11-CBAM.yaml文件内容到新建的yolov11-CBAM.yaml文件中并保存。
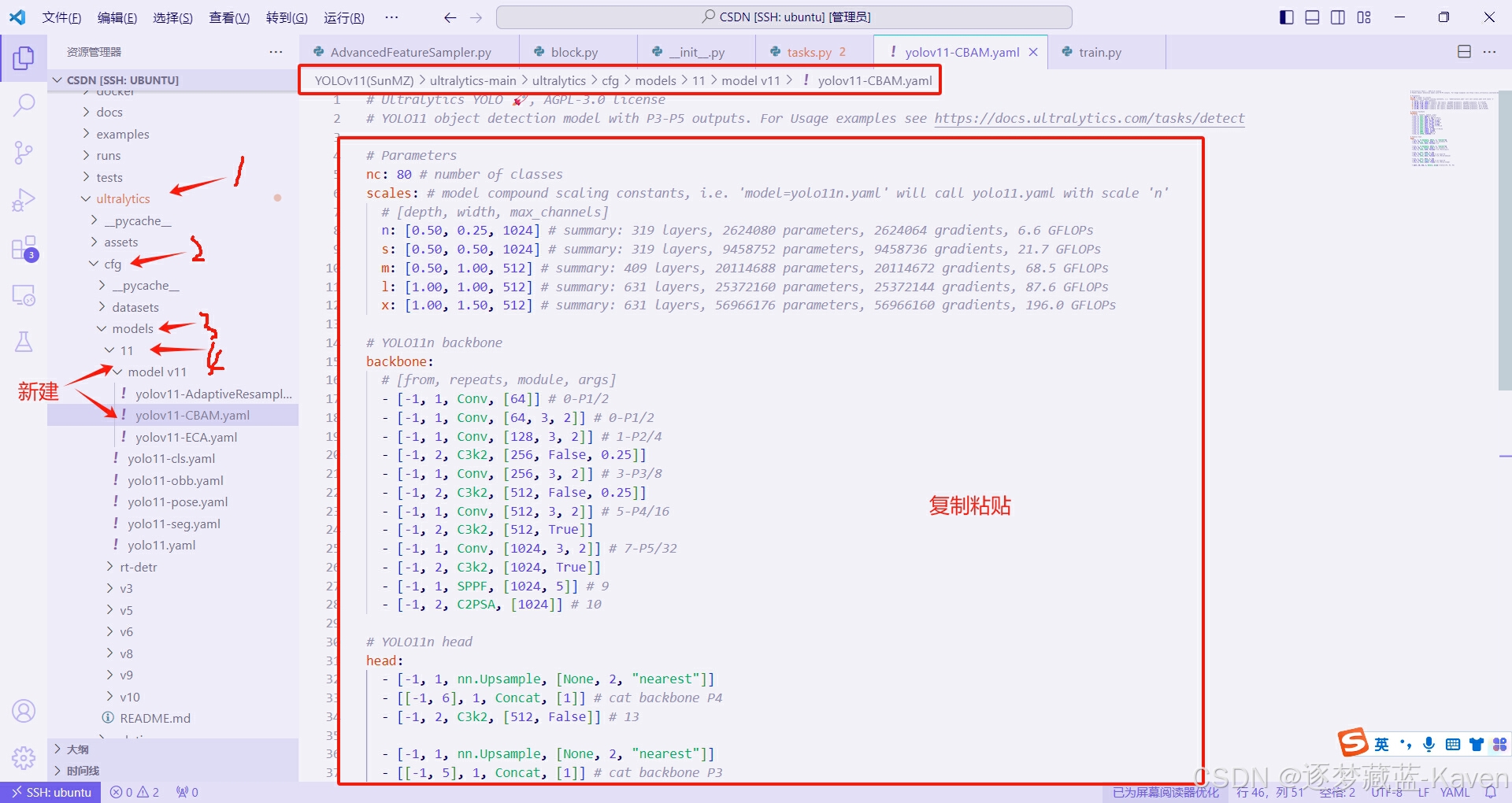 图7(上图)
图7(上图)
yolov11-CBAM.yaml文件内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, CBAM, [64]] # 0-P1/2
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
三、直接开跑
步骤:
- 运行train.py出现如图8所示即为运行成功
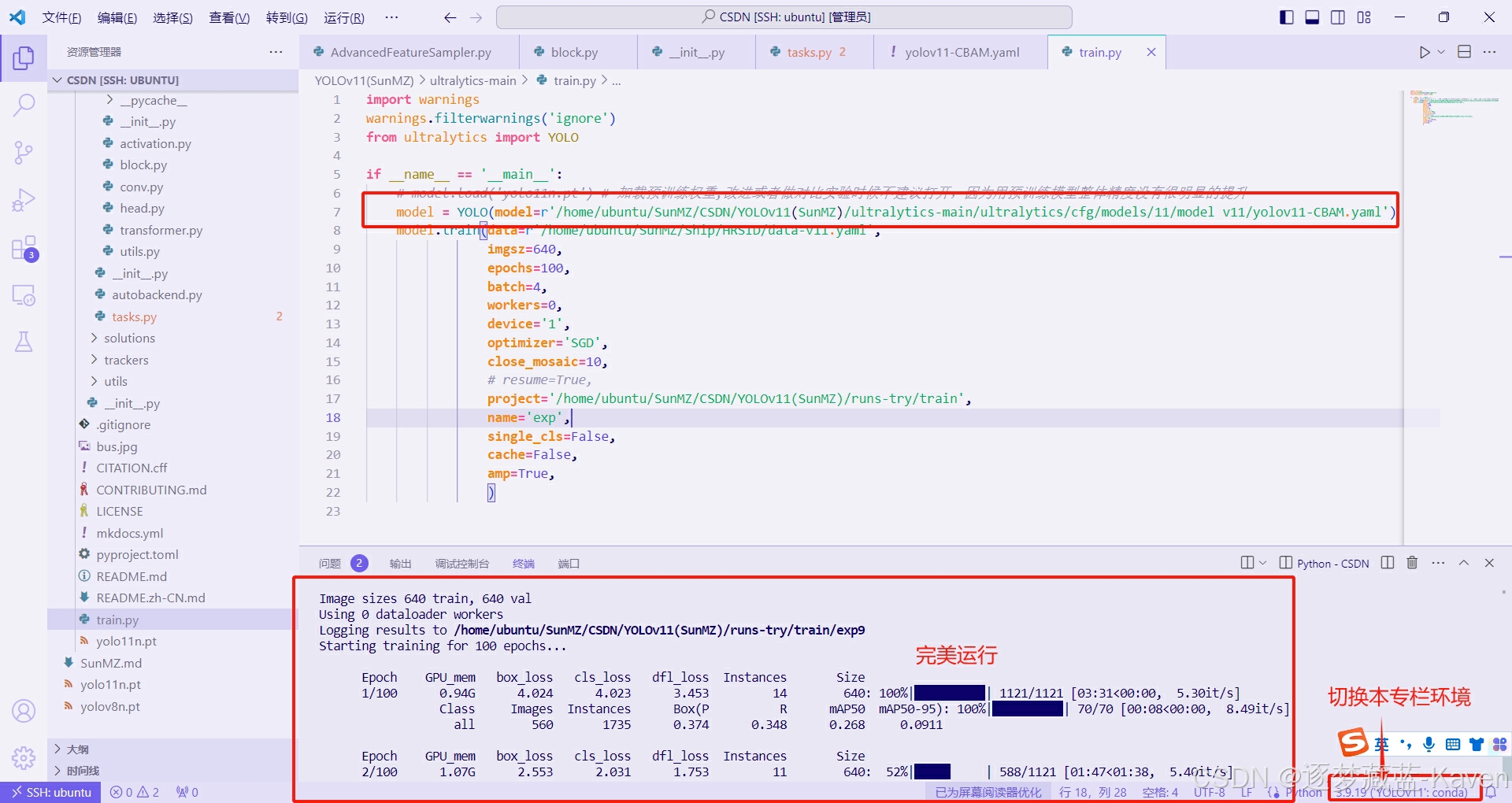 图8(上图)
图8(上图)
四、附赠CBAM(改进版)效果好可做创新点
代码如下所示:(添加方式与上面相同也可直接将源代码替换不需要额外操作,不会的私信我!)
# ------------------------------------CBAM增强版(有需要可用增强版)--------------------------------------------#
"""
如果增强版对你的任务map和精度有提高的话可以应用于论文,改进皆为原创!
增强版模块使用前需要注册模块哦!如果想使用增强版可以私聊我,人多的话出教程,人少的话就私聊了!
"""
import torch
from torch import nn
class EnhancedChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16, act=nn.ReLU, norm_layer=None):
super(EnhancedChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.std_pool = lambda x: torch.std(x, dim=[2, 3], keepdim=True)
self.shared_mlp = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),
act(),
nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
# Use InstanceNorm2d instead of BatchNorm2d
self.norm_layer = norm_layer
if self.norm_layer is not None:
self.bn1 = self.norm_layer(in_planes // ratio)
self.bn2 = self.norm_layer(in_planes)
def forward(self, x):
avg_out = self.shared_mlp(self.avg_pool(x))
max_out = self.shared_mlp(self.max_pool(x))
std_out = self.shared_mlp(self.std_pool(x))
out = avg_out + max_out + std_out
# Only apply normalization if input size is compatible
if self.norm_layer is not None and out.size(0) > 1:
out = self.bn2(out)
return self.sigmoid(out)
class EnhancedSpatialAttention(nn.Module):
def __init__(self, kernel_size=7, norm_layer=None):
super(EnhancedSpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(3, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
# Use InstanceNorm2d instead of BatchNorm2d
self.norm_layer = norm_layer
if self.norm_layer is not None:
self.bn = self.norm_layer(1)
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
std_out = torch.std(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out, std_out], dim=1)
x = self.conv1(x)
# Only apply normalization if input size is compatible
if self.norm_layer is not None and x.size(0) > 1:
x = self.bn(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7, act=nn.ReLU, norm_layer=None):
super(EnhancedCBAM, self).__init__()
self.ca = EnhancedChannelAttention(in_planes, ratio, act, norm_layer)
self.sa = EnhancedSpatialAttention(kernel_size, norm_layer)
def forward(self, x):
residual = x
out = self.ca(x) * x
out = self.sa(out) * out
return out + residual # Use residual connection
总结
改进后的CBAM的适用范围
改进后的CBAM扩展了原有模块的能力,适应性更强,适合更复杂或更多样化的任务:
-
复杂背景下的目标检测与分类:
- 由于多种池化策略和残差连接的应用,改进后的CBAM在复杂多变的环境下能够更好地提取和利用重要特征。
-
实时视频分析:
- 在需要快速处理大量视频数据的情况下(如监控系统),改进后的CBAM能帮助模型快速识别和跟踪目标。
-
医疗图像分析:
- 在医学成像领域,如CT或MRI,改进后的CBAM能帮助模型更有效地识别微小病变或器官区域,提高诊断的可靠性。
-
遥感图像处理:
- 对于遥感数据分析任务,如土地分类或变化检测,改进后的CBAM可以提高对细节和变化的敏感度。
-
多模态数据融合:
- 在需要处理和结合来自多种传感器或数据源的信息时(如自动驾驶中的视觉和雷达数据融合),CBAM的灵活性有助于提升整体模型的性能。

















 2017
2017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









