







需求说明:深度学习FPGA实现知识储备
来自:http://blog.csdn.net/xudong0612/article/details/8930891
最近一时兴起打算研究下深度学习,这个名词近来很火,貌似成为了人工智能领域一根新的稻草。经过几天的查资料和看论文,已经初步有了第一印象,闲话少说,结合一些资料,进入正题。
深度学习的起源
深度学习(Deep Learning)是机器学习中一个非常接近AI的领域,其动机在于建立、模拟人脑进行分析学习的神经网络。
深度学习的概念源于人工神经网络的研究。深度学习是相对于简单学习而言的,目前多数分类、回归等学习算法都属于简单学习,其局限性在于有限样本和计算单元情况下对复杂函数的表示能力有限,针对复杂分类问题其泛化能力受到一定制约。深度学习可通过学习一种深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式表示,并展现了强大的从少数样本集中学习数据集本质特征的能力。含多隐层的多层感知器就是一种深度学习结构。深度学习模拟更多的神经层神经活动,通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示,深度学习的示意图如图1所示。
深度学习的概念由Hinton等人于2006年提出。基于深信度网(DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等人提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。
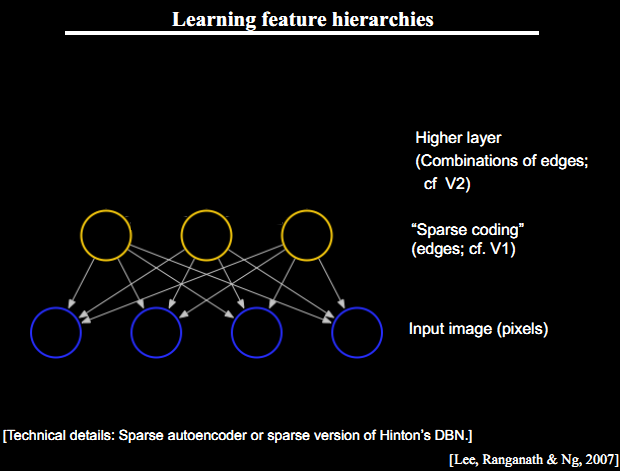
图1 深度学习示意图
什么是深度学习
研究人员通过分析人脑的工作方式发现:通过感官信号从视网膜传递到前额大脑皮质再到运动神经的时间,推断出大脑皮质并未直接地对数据进行特征提取处理,而是使接收到的刺激信号通过一个复杂的层状网络模型,进而获取观测数据展现的规则。也就是说,人脑并不是直接根据外部世界在视网膜上投影,而是根据经聚集和分解过程处理后的信息来识别物体。因此视皮层的功能是对感知信号进行特征提取和计算,而不仅仅是简单地重现视网膜的图像。人类感知系统这种明确的层次结构极大地降低了视觉系统处理的数据量,并保留了物体有用的结构信息。深度学习正是希望通过模拟人脑多层次的分析方式来提高学习的准确性。
实际生活中,人们为了解决一个问题,如对象的分类(对象可是文档、图像等),首先必须做的事情是如何来表达一个对象,即必须抽取一些特征来表示一个对象,因此特征对结果的影响非常大。在传统的数据挖掘方法中,特征的选择一般都是通过手工完成的,通过手工选取的好处是可以借助人的经验或者专业知识选择出正确的特征;但缺点是效率低,而且在复杂的问题中,人工选择可能也会陷入困惑。于是,人们就在寻找一种能够自动的选择特征,而且还能保证特征准确的方法。DeepLearning就是能实现这一点,它能够通过多层次通过组合低层特征形成更抽象的高层特征,从而实现自动的学习特征,而不需要人参与特征的选取。
深度学习的核心思想
假设我们有一个系统S,它有n层(S1,…Sn),它的输入是I,输出是O,形象地表示为: I=>S1=>S2=>…..=>Sn => O,如果输出O等于输入I,即输入I经过这个系统变化之后没有任何的信息损失,保持了不变,这意味着输入I经过每一层Si都没有任何的信息损失,即在任何一层Si,它都是原有信息(即输入I)的另外一种表示。现在回到我们的主题DeepLearning,我们需要自动地学习特征,假设我们有一堆输入I(如一堆图像或者文本),假设我们设计了一个系统S(有n层),我们通过调整系统中参数,使得它的输出仍然是输入I,那么我们就可以自动地获取得到输入I的一系列层次特征,即S1,…, Sn。
另外,前面是假设输出严格地等于输入,这个限制太严格,我们可以略微地放松这个限制,例如我们只要使得输入与输出的差别尽可能地小即可。深度学习的动机
学习基于深度架构的学习算法的主要动机是:
①不充分的深度是有害的;
在许多情形中深度2就足够(比如logicalgates, formal [threshold] neurons, sigmoid-neurons, Radial Basis Function [RBF]units like in SVMs)表示任何一个带有给定目标精度的函数。但是其代价是:图中所需要的节点数(比如计算和参数数量)可能变的非常大。理论结果证实那些事实上所需要的节点数随着输入的大小指数增长的函数族是存在的。这一点已经在logicalgates, formal [threshold] neurons 和rbf单元中得到证实。在后者中Hastad说明了但深度是d时,函数族可以被有效地(紧地)使用O(n)个节点(对于n个输入)来表示,但是如果深度被限制为d-1,则需要指数数量的节点数O(2^n)。
我们可以将深度架构看做一种因子分解。大部分随机选择的函数不能被有效地表示,无论是用深地或者浅的架构。但是许多能够有效地被深度架构表示的却不能被用浅的架构高效表示(seethe polynomials example in the Bengio survey paper)。一个紧的和深度的表示的存在意味着在潜在的可被表示的函数中存在某种结构。如果不存在任何结构,那将不可能很好地泛化。
②大脑有一个深度架构;
例如,视觉皮质得到了很好的研究,并显示出一系列的区域,在每一个这种区域中包含一个输入的表示和从一个到另一个的信号流(这里忽略了在一些层次并行路径上的关联,因此更复杂)。这个特征层次的每一层表示在一个不同的抽象层上的输入,并在层次的更上层有着更多的抽象特征,他们根据低层特征定义。
需要注意的是大脑中的表示是在中间紧密分布并且纯局部:他们是稀疏的:1%的神经元是同时活动的。给定大量的神经元,仍然有一个非常高效地(指数级高效)表示。
③认知过程是深度的;
人类层次化地组织思想和概念;
人类首先学习简单的概念,然后用他们去表示更抽象的;
工程师将任务分解成多个抽象层次去处理;深度学习结构
生成性深度结构
该结构描述数据的高阶相关特性,或观测数据和相应类别的联合概率分布。与传统区分型神经网络不同,可获取观测数据和标签的联合概率分布,这方便了先验概率和后验概率的估计,而区分型模型仅能对后验概率进行估计。论文Afast learning algorithm for deep learning中采用的深度信念网(DBN)就属于生成性深度结构。DBN解决传统BP算法训练多层神经网络的难题:1)需要大量含标签训练样本集;2)较慢的收敛速度;3)因不合适的参数选择陷入局部最优。
DBN由一系列受限波尔兹曼机(RBM)单元组成。RBM是一种典型神经网络,该网络可视层和隐层单元彼此互连(层内无连接),隐单元可获取输入可视单元的高阶相关性。相比传统sigmoid信度网络,RBM权值的学习相对容易。为了获取生成性权值,预训练采用无监督贪心逐层方式来实现。在训练过程中,首先将可视向量值映射给隐单元;然后可视单元由隐层单元重建;这些新可视单元再次映射给隐单元,这样就获取了新的隐单元。通过自底向上组合多个RBM可以构建一个DBN。应用高斯—伯努利RBM或伯努利—伯努利RBM,可用隐单元的输出作为训练上层伯努利—伯努利RBM的输入,第二层伯努利和伯努利的输出作为第三层的输入等,如图2所示。

图2 DBN模型
区分性深度结构
目的是提供对模式分类的区分性能力,通常描述数据的后验分布。卷积神经网络(Convolutional neural network, CNNs)是第一个真正成功训练多层网络结构的学习算法,与DBNs不同,它属于区分性训练算法。受视觉系统结构的启示,当具有相同参数的神经元应用于前一层的不同位置时,一种变换不变性特征就可获取了。后来LeCun等人沿着这种思路,利用BP算法设计并训练了CNNs。CNNs作为深度学习框架是基于最小化预处理数据要求而产生的。受早期的时间延迟神经网络影响。CNNs靠共享时域权值降低复杂度。CNNs是利用空间关系减少参数数目以提高一般前向BP训练的一种拓扑结构,并在多个实验中获取了较好性能。在CNNs中被称作局部感受区域的图像的一小部分作为分层结构的最底层输入。信息通过不同的网络层次进行传递,因此在每一层能够获取对平移、缩放和旋转不变的观测数据的显著特征。
混合型结构
它的目标是区分性的,但通常利用了生成型结构的输出会更易优化。混合型结构的学习过程包含两个部分,即生成性部分和区分性部分。现有典型的生成性单元通常最终用于区分性任务,生成性模型应用于分类任务时,预训练可结合其他典型区分性学习算法对所有权值进行优化。这个区分性寻优过程通常是附加一个顶层变量来表示训练集提供的期望输出或标签。BP算法可用于优化DBN权值,它的初始权值通过在RBM和DBN预训练中得到而非随机产生,这样的网络通常会比仅通过BP算法单独训练的网络性能优越。可以认为BP对DBNs训练仅完成局部参数空间搜索,与前馈型神经网络相比加速了训练和收敛时间。
里程碑式的论文
计算机视觉
ImageNetClassification with Deep Convolutional Neural Networks, Alex Krizhevsky, IlyaSutskever, Geoffrey E Hinton, NIPS 2012.
LearningHierarchical Features for Scene Labeling, Clement Farabet, Camille Couprie,Laurent Najman and Yann LeCun, IEEE Transactions on Pattern Analysis andMachine Intelligence, 2013.
LearningConvolutional Feature Hierachies for Visual Recognition, Koray Kavukcuoglu,Pierre Sermanet, Y-Lan Boureau, Karol Gregor, Michaël Mathieu and YannLeCun, Advances in Neural Information Processing Systems (NIPS 2010), 23, 2010.
语音识别
Dahl,George E., et al. Large vocabulary continuous speech recognition withcontext-dependent DBN-HMMs. Acoustics, Speech and Signal Processing (ICASSP),2011 IEEE International Conference on. IEEE, 2011.
Mohamed,A-R., et al. Deep belief networks using discriminative features for phonerecognition. Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEEInternational Conference on. IEEE, 2011.
Fasel,Ian, Jeff Berry. Deep belief networks for real-time extraction of tonguecontours from ultrasound during speech. Pattern Recognition (ICPR), 2010 20thInternational Conference on. IEEE, 2010.
Deng,Li, et al. Binary coding of speech spectrograms using a deep auto-encoder.Proc. Interspeech. 2010.
自然语言处理
DESELAERST,HASANS, BENDERO, et al. A deep learning approach to machine transliteration[C].Proc of the 4th Workshop on Statistical Machine Translation. 2009:233-241.
开发工具
Theano 是一个 Python 的扩展库,用来定义、优化和模拟数学表达式计算,可以高效的解决多维数组的计算问题。利用Theano更容易的实现深度学习模型。
使用Theano要求首先熟悉Python和numpy(如果你不了解,可以先看看这里:python、numpy)。接下来学习Theano建议先看Theano basic tutorial,然后按照Getting Started 下载相关数据并用gradient descent的方法进行学习。
学习了Theano的基本方法后,可以练习写以下几个算法:
有监督学习:
- Logistic Regression - using Theano for something simple
- Multilayer perceptron - introduction to layers
- Deep Convolutional Network - a simplified version of LeNet5
无监督学习:
- Auto Encoders, Denoising Autoencoders - description of autoencoders
- Stacked Denoising Auto-Encoders - easy steps into unsupervised pre-training for deep nets
- Restricted Boltzmann Machines - single layer generative RBM model
- Deep Belief Networks - unsupervised generative pre-training of stacked RBMs followed by supervised fine-tuning
参考文献
[6] 孙志军, 薛磊, 许阳明, 王正. (2012). 深度学习研究综述. 计算机应用研究,29(8), 2806-2810.















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









