






OpenAI前首席科学家、联合创始人Ilya Sutskever曾在多个场合表达观点:只要能够非常好的预测下一个token,就能帮助人类达到通用人工智能(AGI)。虽然,下一token预测已在大语言模型领域实现了ChatGPT等突破,但是在多模态模型中的适用性仍不明确。多模态任务仍然由扩散模型(如Stable Diffusion)和组合方法(如结合 CLIP视觉编码器和LLM)所主导。2024年10月21日,智源研究院正式发布原生多模态世界模型Emu3。该模型只基于下一个token预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。感觉还是蛮有意思的,这里主要是自己阅读论文的记录,感兴趣的话可以参考一下,如果想要直接阅读原文,可以来这里,如下所示:

摘要
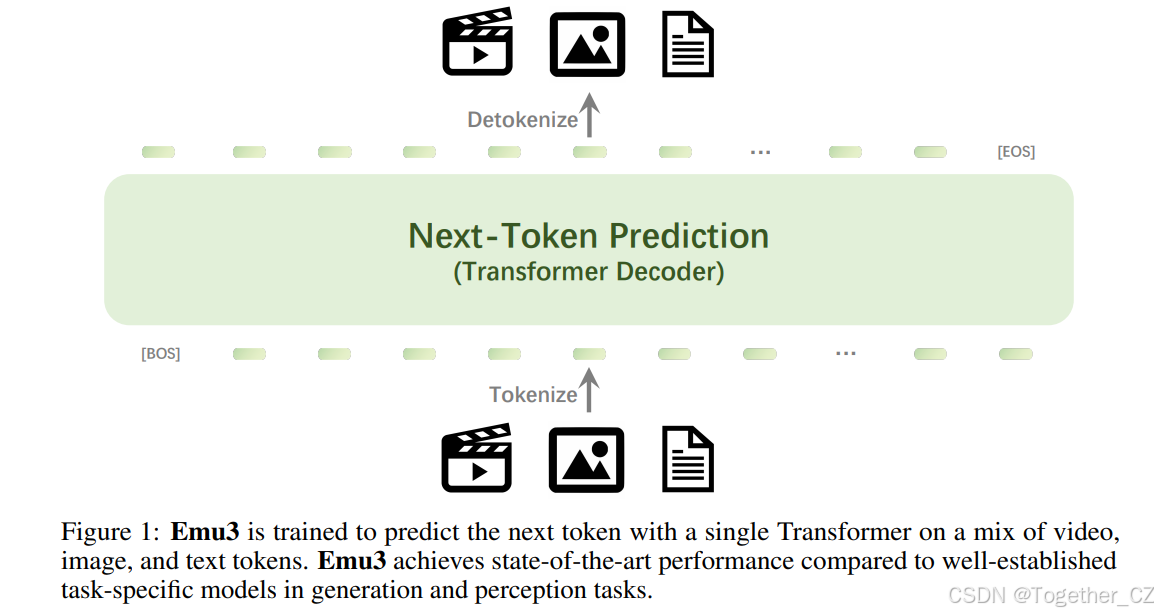
图1:Emu3 通过一个 Transformer 模型,在混合的视频、图像和文本标记上进行训练,以预测下一个标记。与已建立的任务特定模型相比,Emu3 在生成和感知任务中达到了最先进的性能。
尽管下一个标记预测被认为是通向人工通用智能的一条有前景的路径,但在多模态任务中,它仍然难以超越扩散模型(如Stable Diffusion)和组合方法(如CLIP与LLMs的结合)。在本文中,我们介绍了Emu3,这是一套全新的最先进的多模态模型,仅通过下一个标记预测进行训练。通过将图像、文本和视频标记化为离散空间,我们在多模态序列的混合上从头开始训练一个单一的Transformer。Emu3在生成和感知任务中均优于多个已建立的任务特定模型,超越了旗舰模型如SDXL和LLaVA-1.6,同时消除了对扩散或组合架构的需求。Emu3还能够通过预测视频序列中的下一个标记来生成高保真视频。我们通过将复杂的多模态模型设计简化为单一焦点:标记,解锁了在训练和推理过程中扩展的巨大潜力。我们的结果表明,下一个标记预测是构建超越语言的通用多模态智能的一条有前景的路径。我们开源了关键技术和模型,以支持这一方向的进一步研究。
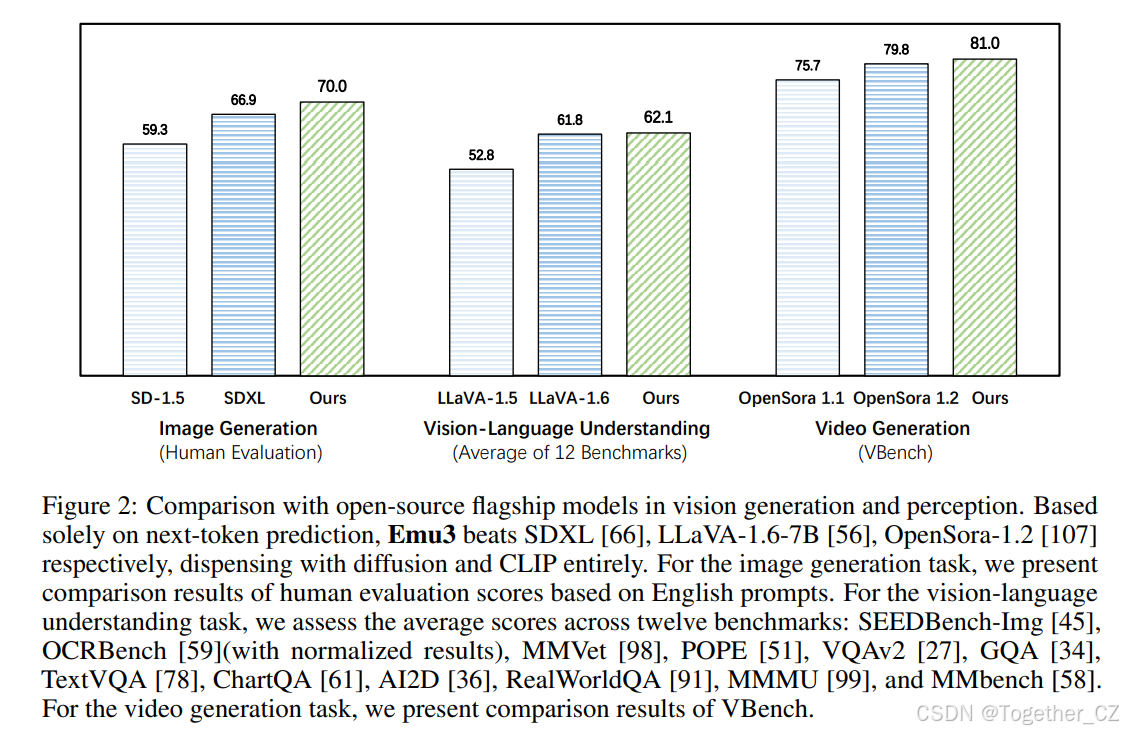
图2:与开源旗舰模型在视觉生成和感知方面的比较。仅基于下一个标记预测,Emu3 分别击败了 SDXL [66]、LLaVA-1.6-7B [56] 和 OpenSora-1.2 [107],完全摒弃了扩散和 CLIP 模型。对于图像生成任务,我们展示了基于英文提示的人类评估分数的比较结果。对于视觉语言理解任务,我们在十二个基准上评估了平均分数:SEEDBench-Img [45]、OCRBench [59](含标准化结果)、MMVet [98]、POPE [51]、VQAv2 [27]、GQA [34]、TextVQA [78]、ChartQA [61]、AI2D [36]、RealWorldQA [91]、MMMU [99] 和 MMbench [58]。对于视频生成任务,我们展示了 VBench 的比较结果。
1 引言
下一个标记预测已经彻底改变了语言模型领域[86, 69, 9],实现了如ChatGPT[64]这样的突破,并引发了关于人工通用智能(AGI)早期迹象的讨论[10]。然而,这一范式在多模态模型中的适用性仍不明确,其有效性在不同任务中实现竞争性表现的证据有限。
在多模态模型的领域中,视觉生成主要由复杂的扩散模型(如Stable Diffusion[73])主导,而视觉-语言感知则由CLIP[67]与LLMs(如LLaVA[57])等组合方法引领。尽管早期有统一生成和感知的尝试,如Emu[82]和Chameleon[83],这些努力要么依赖于将LLMs与扩散模型连接,要么未能达到为生成和感知量身定制的任务特定方法的性能。
在这项工作中,我们提出了Emu3,一套全新的基于下一个标记预测的最先进多模态模型,完全消除了对扩散或组合方法的需求。我们将图像、文本和视频标记化为离散空间,并在多模态序列的混合上从头开始联合训练一个单一的Transformer。

图3:重建样本。左侧:原始和重建的视频,分辨率为540×960,展示了以30帧每秒采样的8帧。右侧:原始和重建的512×512分辨率图像。放大以查看细节。
Emu3在与已建立的任务特定模型在生成和感知任务中的比较中达到了最先进的性能。Emu3在人类评估和公开的文本到图像基准测试(如MSCOCO-30K[15]、GenEval[26]、T2I-CompBench[32]和DPG-Bench[31])中均优于旗舰Stable Diffusion模型,即SDXL[66]。在视觉-语言理解方面,Emu3在一系列公开的视觉-语言基准测试(包括SEED-Bench[45]、RealWorldQA[91]、OCRBench[59]等)中与流行的视觉-语言模型LLaVA-1.6[56]竞争。
Emu3能够生成视频。与Sora[8]通过视频扩散模型从噪声生成视频不同,Emu3通过预测视频序列中的下一个标记来因果生成视频。该模型能够模拟物理世界中环境、人和动物的某些方面。在上下文中提供视频时,Emu3可以扩展视频并预测接下来会发生什么。根据用户的提示,模型可以生成高保真视频,遵循文本描述。Emu3在文本到视频生成的VBench基准测试[33]中脱颖而出,与其他视频扩散模型竞争。
我们开源了关键技术和模型,以促进这一方向的未来研究。值得注意的是,我们提供了一个强大的视觉标记器,能够将视频和图像转换为离散标记,这在之前是公开不可用的。我们还展示了下一个标记预测框架的多功能性,表明直接偏好优化(DPO)[68]可以无缝应用于自回归视觉生成,使模型与人类偏好对齐。
我们的结果提供了强有力的证据,表明下一个标记预测可以作为多模态模型的强大范式,超越语言模型并在多模态任务中提供最先进的性能。通过简化复杂模型设计并专注于标记,它解锁了在训练和推理过程中扩展的显著潜力。我们相信,下一个标记预测为构建通用多模态智能提供了有前景的路径。
2 方法
数据
Emu3从头开始在语言、图像和视频数据的混合上进行训练。

图4:Emu3 文本到图像生成的定性结果。
**语言数据。**我们使用了与Aquila[101]相同的语言数据,这是一个由中文和英文数据组成的高质量语料库。
**图像数据。**我们策划了一个大规模的图像-文本数据集,包括开源网络数据、AI生成数据和高质量的内部数据。过滤过程涉及几个关键步骤:**1)**我们应用分辨率过滤器,丢弃分辨率低于512×512像素的样本。**2)**我们使用LAION-AI美学预测器2评估每张图像的美学质量,排除评分低于5.5的图像,以确保整体美学质量。**3)**对于未通过美学过滤器的图像,我们使用文本检测3和颜色过滤来保留非单色图像和文本最少的图像,提高开放世界图像的过滤召回率。**4)**此外,我们为图像理解准备了补充数据。通过遵循DenseFusion[50]中的数据处理管道,我们从多样化的开源网络数据中提取了数百万张涵盖广泛类别的代表性图像,包括图表、表格、文本丰富的内容等。
为了注释过滤后的数据集,我们基于Emu2[81]开发了一个图像字幕模型,以构建密集的合成字幕。我们利用GPT-4V[64]和详细的提示生成约100万张图像-字幕对。然后使用这个注释数据集对Emu2-17B[81]模型进行微调,作为我们的图像字幕器。此外,我们利用开源的vLLM库[40]加速标注过程。
**视频数据。**我们收集了涵盖各种类别的视频,如风景、动物、植物、游戏和动作。这些视频通过一个复杂的管道[6]进行预处理,分为四个阶段:**1)**我们使用PySceneDetect4将视频分割为场景,同时使用ContentDetector和ThresholdDetector分别识别内容变化和淡入/淡出事件。**2)**使用PaddleOCR5进行文本检测,删除文本覆盖过多的片段。为了减少计算成本,我们以2 FPS采样视频帧并将较短的边调整为256。**3)**我们进一步计算光流[84]以消除运动最小或极端的片段。与上一步类似,我们采样和调整视频帧以提高效率。光流分数定义为所有像素的平均光流幅度与较短边的比率。我们排除光流分数超出可接受范围的片段。**4)**最后,我们使用LAION-AI美学预测器6评估每个片段的美学质量。我们采样三个帧并为每个片段获得三个分数,丢弃最低分数小于5的片段。
我们使用基于图像字幕器训练的视频字幕器对过滤后的视频片段进行字幕。训练数据最初由GPT-4V[64]标注。对于每个视频片段,我们采样八个帧,并为GPT-4V创建一个详细的提示,以描述这些帧中的内容和运动。部分标注数据经过手动修订。然后,我们在这个标注数据上对图像字幕器进行微调,以开发我们的视频字幕器。对于大规模部署,我们使用vLLM[40]加速字幕。时长少于20秒的片段使用12个均匀采样的帧进行字幕,而更长的片段则分割为10-20秒的子片段,每个子片段独立字幕。
视觉标记器
我们基于SBER-MoVQGAN7训练视觉标记器,该标记器可以将4×512×512的视频片段或512×512的图像编码为32,768大小的码本中的4096个离散标记。我们的标记器在时间维度上实现了4倍的压缩,在空间维度上实现了8×8的压缩,适用于任何时间和空间分辨率。基于MoVQGAN架构[106],我们在编码器和解码器模块中加入了两个带有3D卷积核的时间残差层,以增强视频标记化能力。标记器在LAION-High-Resolution8图像数据集和InternVid[89]视频数据集上进行端到端训练,使用L2损失、LPIPS感知损失[104]、GAN损失和承诺损失[23]的组合目标函数。
表1:Emu3 视觉标记器配置。 表2:视频压缩指标。
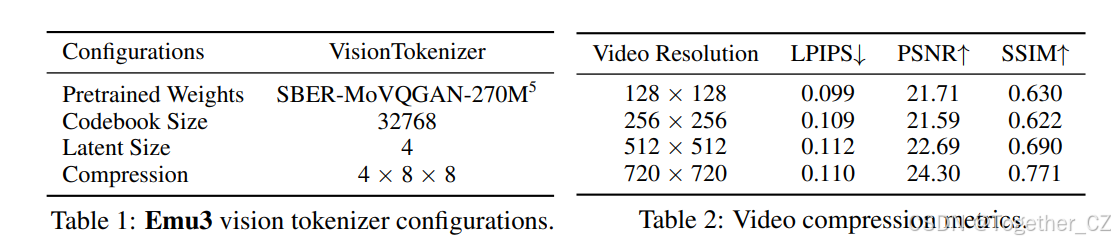
定性结果如图3所示。我们使用来自Pexels9的3,172个视频的评估数据集报告了LPIPS(通过AlexNet特征计算)、PSNR和SSIM分数,如表2所示。视频在保持宽高比的同时重建了5秒。在评估过程中,原始和重建视频根据较短边进行调整和裁剪,并以12 FPS均匀采样8帧。
架构
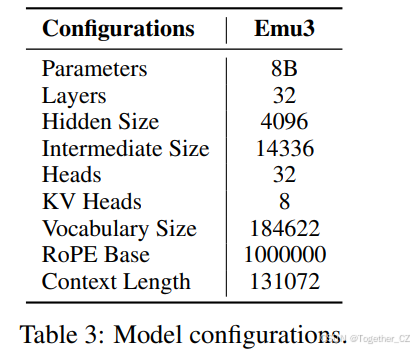
Emu3模型保留了已建立的大型语言模型(如Llama-2[85])的架构框架,主要修改是扩展嵌入层以容纳离散视觉标记。我们使用RMSNorm[100]进行归一化,使用GQA[1]进行注意力机制,同时采用SwiGLU[76]激活函数和旋转位置嵌入(RoPE)[79]。qkv和线性投影层中的偏置被移除。此外,实施了0.1的dropout率以提高训练稳定性。我们使用QwenTokenizer8对多语言文本进行标记化。详细配置如表3所示。
表3:模型配置。
预训练
**数据准备。**在预训练期间,我们首先定义多模态数据格式。与依赖外部文本编码器的扩散模型不同,Emu3原生集成文本条件信息以进行图像/视频生成。我们调整图像/视频的宽高比,使其面积接近512×512,然后使用我们的视觉标记器生成视觉标记。然后,我们合并五个特殊标记以合并文本和视觉数据,为训练过程创建类似文档的输入。生成的训练数据结构如下:
[BOS] {字幕文本} [SOV] {元文本} [SOT] {视觉标记} [EOV] [EOS]。
其中[BOS]和[EOS]是文本标记器中的原始特殊标记,[SOV]标记视觉输入的开始,[SOT]标记视觉标记的开始,[EOV]指示视觉输入的结束。此外,[EOL]和[EOF]插入视觉标记中以表示换行和帧中断。“元文本”包含图像的分辨率信息,对于视频,还包括分辨率、帧率和持续时间,均以纯文本格式呈现。我们还将在部分数据集中将“字幕文本”字段移至[EOV]标记之后,从而构建面向视觉理解任务的数据。
训练目标。由于Emu3中的视觉信号完全转换为离散标记,我们只需使用标准的交叉熵损失进行下一个标记预测任务进行训练。为了防止视觉标记主导学习过程,我们对与视觉标记相关的损失应用0.5的权重。
训练细节。****Emu3模型在预训练期间使用广泛的上下文长度来处理视频数据。为了便于训练,我们结合了张量并行(TP)、上下文并行(CP)和数据并行(DP)。我们将文本-图像数据同时打包到最大上下文长度中,以充分利用计算资源,同时确保在打包过程中不分割完整的图像。预训练过程分为两个阶段。在第一阶段,不使用视频数据,从上下文长度为5120的文本和图像数据从头开始训练。在第二阶段,引入视频数据,并使用131072的上下文长度。两个阶段都使用5×10^-5的学习率,并使用余弦退火将学习率退火至零。
后训练
2.5.1 视觉生成
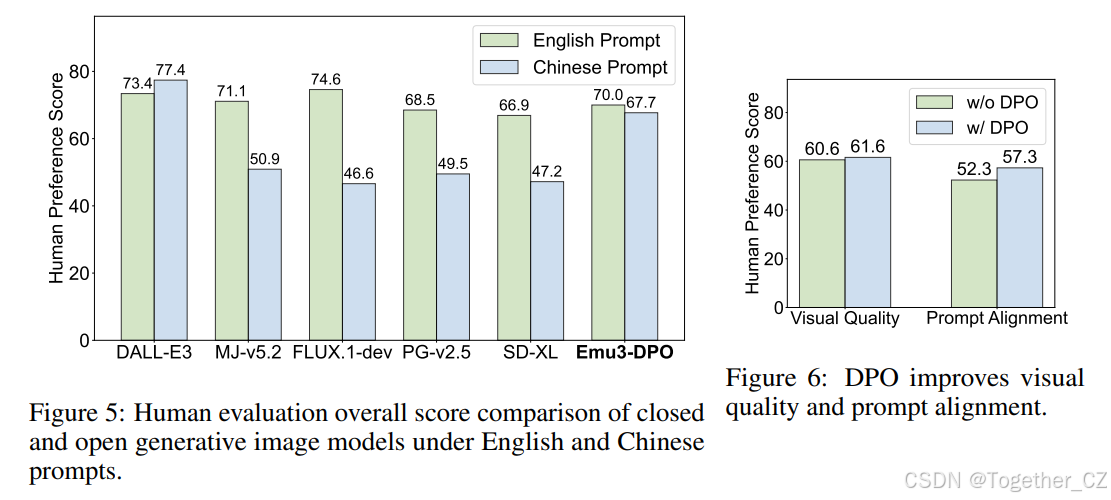
图5:在英文和中文提示下,闭源和开源生成图像模型的人类评估总体分数比较。
**质量微调。**在预训练阶段之后,我们进行视觉生成任务的后训练以提高生成输出的质量。我们使用高质量数据进行质量微调(QFT)。模型继续使用下一个标记预测任务和标准交叉熵损失进行训练;然而,监督仅应用于视觉标记。对于QFT中的图像数据,我们选择多样的高质量来源并根据三个流行的偏好分数(HPSv2.1[90]、MPS[105]和LAION美学分数[43])的平均值进行过滤。在QFT期间,我们将训练数据分辨率从512像素提高到720像素以提高生成质量。对于视频数据,我们从高质量来源采样并应用严格的分辨率和光流过滤以确保质量。此外,在训练结束时,我们使用退火策略将学习率线性衰减至零。
**直接偏好优化。**直接偏好优化(DPO)[68]是一种有效的方法,用于更好地将模型与人类偏好对齐。我们将DPO技术应用于自回归多模态生成任务,利用人类偏好数据来增强模型性能。我们将数据集构建分为三个步骤:**1)**我们使用质量微调模型对每个用户收集的提示(p)进行8-10次推理,创建初始数据池(x)。**2)**每个提示由三名投票者评估,重点关注视觉吸引力和提示对齐。**3)**根据分数,选择得分最高的样本,拒绝得分最低的样本,形成一个三元组(p_i,x_i^chosen,x_i^rejected)以供进一步训练。具体来说,数据构建过程中的标记被存储以供未来训练阶段直接使用。这种策略消除了由于重新标记化引起的重建差异。Emu3-DPO最小化DPO损失和下一个标记预测交叉熵损失以微调QFT模型。
2.5.2 视觉-语言理解
预训练模型经历了一个两阶段的后训练过程,用于视觉-语言理解:1)图像到文本训练,和2)指令调优。在第一阶段,我们的方法将图像理解数据与纯语言数据集成,同时忽略与视觉标记相关的损失以进行纯文本预测。每个图像调整分辨率至约512×512,同时保持原始宽高比。在第二阶段,我们从[44]中采样子集的问题-答案对以增强视觉指令遵循能力。分辨率低于512×512或高于1024×1024的图像将调整至较低或较高的分辨率限制,同时保持宽高比,而其他图像保持原始分辨率。
3 主要结果
图像生成
3.1.1 自动化指标评估
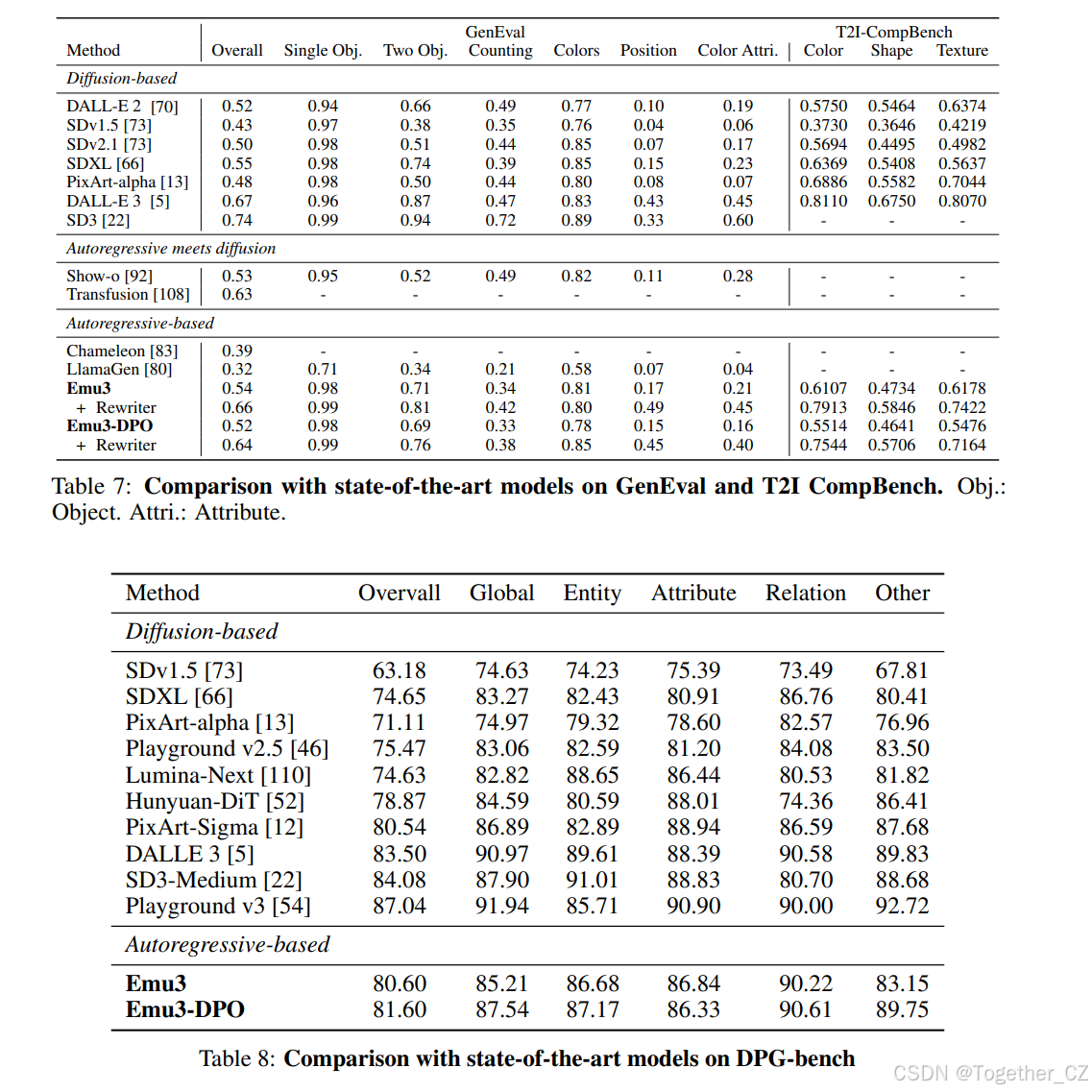
我们在流行的文本到图像基准测试(MSCOCO-30K[15]、GenEval[26]、T2I-CompBench[32]和DPG-Bench[31])上通过自动化指标评估Emu3的性能。Emu3与扩散方法、自回归扩散方法和自回归方法在这些基准测试中的比较结果如表4所示。我们的方法在图像-文本对齐评估中优于自回归扩散方法,并且与最先进的扩散模型相当,尽管没有使用任何预训练的语言模型。
表4:与最先进模型在文本到图像基准上的比较。我们在 MSCOCO-30K [15]、GenEval [26]、T2I-CompBench [32] 和 DPG-Bench [31] 上进行评估。† 结果是经过重写的。
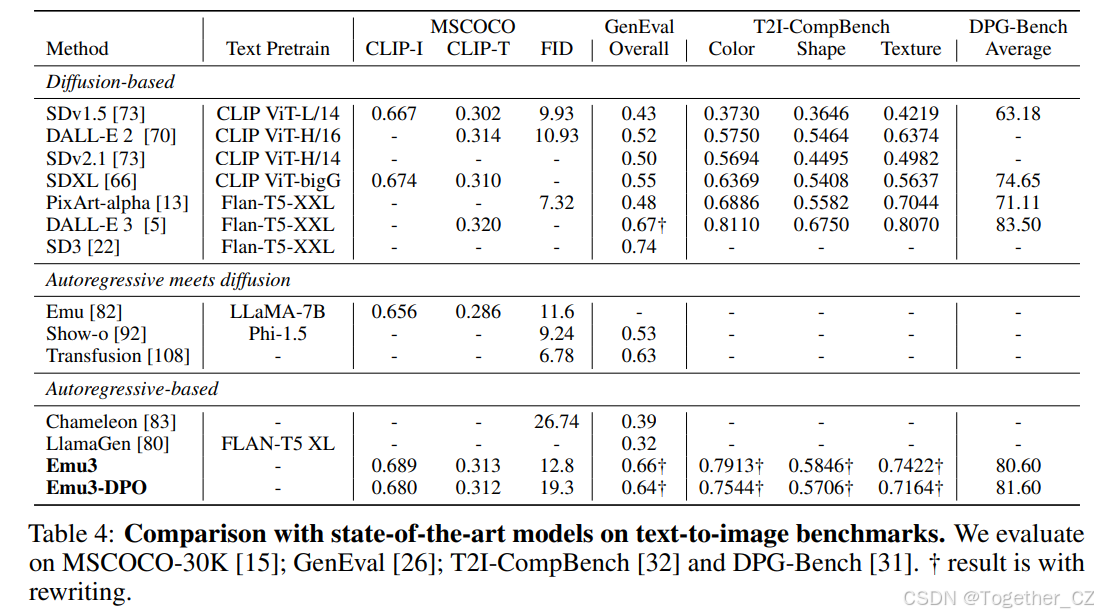
我们在使用重写器扩展短提示后报告了GenEval和T2I-CompBench的结果。由于Emu3在训练期间使用了大量合成标签,因此在密集字幕方面表现优于较短的提示。然而,GenEval和T2I-CompBench中的评估提示过于简短,无法准确反映模型的真实性能。遵循DALL-E 3,我们还使用GPT-4V作为重写器报告了我们的评估结果。GenEval总体得分结果表明,Emu3显著优于多模态自回归模型Chameleon,以及最新的自回归扩散方法Show-O和Transfusion。此外,Emu3超越了SDXL,并与包括DALL-E 3在内的最先进扩散模型表现相当。详细的跨维度比较,包括原始提示的结果,在附录B.1中提供。
为了进一步评估最先进的文本到图像方法,特别是扩散模型,我们使用T2I-CompBench评估生成图像与文本条件之间的对齐。Emu3与最先进的扩散模型相比表现出竞争力。此外,我们在DPG-Bench上与最先进(SoTA)模型进行比较,该基准测试提供了包含更多详细信息的长提示进行评估。我们的Emu3-DPO总体得分为81.6,超越了SDXL和PixArt-alpha,并与DALL-E 3相当,进一步证明了模型遵循长提示的能力。在比较Emu3和Emu3-DPO时,我们观察到应用DPO后评估结果略有下降,这可能是由于我们的DPO数据集中的偏好强调整体美学质量,这与自动化评估模型的领域不同,使得仅通过自动化评估得出的结论复杂化。因此,我们在第3.1.2节中引入了人类评估。
3.1.2 人类评估
我们进行了一项人类评估,比较不同模型的文本到图像生成能力。收集了一组100个多样化的用户提示,每个提示由三名独立的投票者评估。评估重点是视觉质量和提示遵循,加权分数反映了整体表现。如图5所示,我们展示了当前闭源和开源生成图像模型的人类偏好比较。结果表明,Emu3在整体得分上优于SDXL,并与DALL-E 3和MJ-v5.2相当。此外,图6展示了通过DPO微调对齐的影响,这有效地提高了视觉质量和提示遵循。
3.1.3 定性结果
图4展示了Emu3生成的25张图像,以展示其能力。Emu3支持灵活的分辨率和宽高比,并能够处理各种风格。
视频生成
与训练阶段一致,Emu3原生支持以24 FPS生成5秒的视频,并通过自回归方法无限扩展。图7展示了视频生成的定性示例,从中提取了前3秒的6帧进行展示。
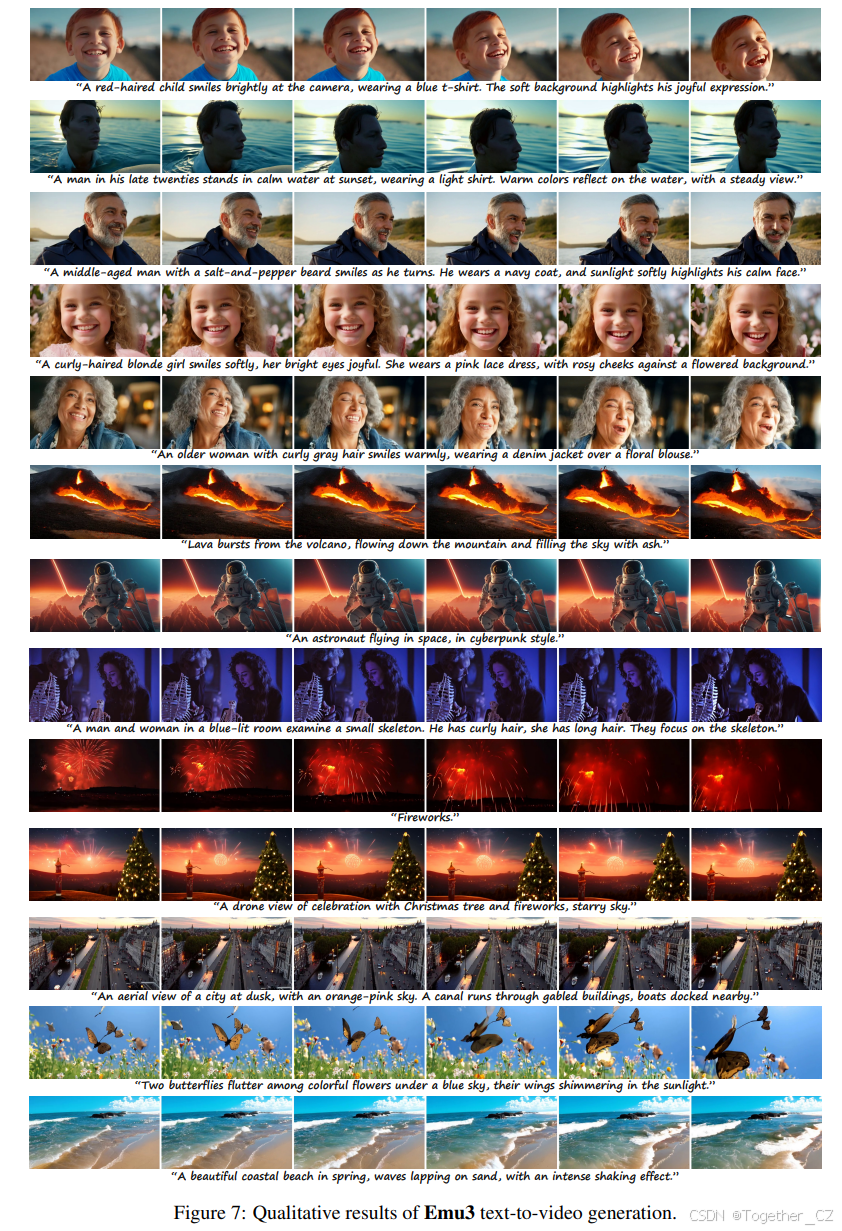
图7:Emu3 文本到视频生成的定性结果。
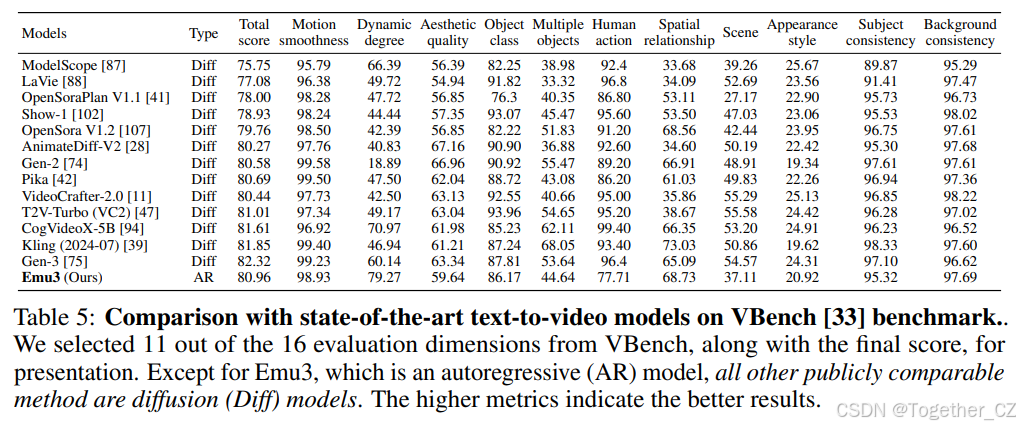
我们在Emu3与13个表现最佳的开源和专有文本到视频模型之间进行了定量比较。使用的基准测试是VBench[33],这是一个全面评估视频生成性能的工具包,评估每个模型在16个维度上的质量和语义能力。除了Emu3(一个自回归模型)之外,所有其他公开可比的方法都是扩散模型。尽管如此,如表5所示,Emu3在总体得分上与其他最先进的模型相比表现出高度竞争力。具体来说,虽然它落后于最先进的专有模型如Kling[39]和Gen-3[75],但它优于大多数开源文本到视频模型。这些结果突显了Emu3在视频生成方面的强大能力。
表5:与最先进的文本到视频模型在 VBench [33] 基准上的比较。我们从 VBench 的 16 个评估维度中选择了 11 个,以及最终分数,进行展示。除了 Emu3 是自回归(AR)模型外,所有其他公开可比较的方法都是扩散(Diff)模型。指标越高表示结果越好。
未来预测
Emu3可以通过预测未来帧来扩展视频。在图8中,我们展示了视频扩展的定性示例,其中2秒的视频以24 FPS标记化为离散视觉标记作为上下文。Emu3预测后续2秒内容的相同形式的离散视觉标记,可以解码以生成未来预测的视频。这些示例表明,仅使用下一个标记预测可以促进视频的时间扩展,包括预测人类和动物的动作、与现实世界的互动以及三维动画的变化。此外,通过这种方式扩展视频时长,我们的方法能够迭代生成超越其上下文长度的视频。我们观察到,使用2秒的视频数据作为上下文成功扩展8秒的未来视频帧是可行的。
表6:视觉语言基准上的比较。我们收集的评估包括:SEEDB:SEEDBench-Img [45];OCRB:OCRBench [59];MMV:MMVet [98];POPE [51];VQAv2 [27];GQA [34];SQA:ScienceQA-Img [60];TVQA:TextVQA [78];CQA:ChartQA [61];DVQA:DocVQA [63];IVQA:InfoVQA [62];AI2D [36];RWQA:RealWorldQA [91];MMMU [99];MMB:MMBench [58]。* 相关训练数据集的图像在训练期间被观察到。
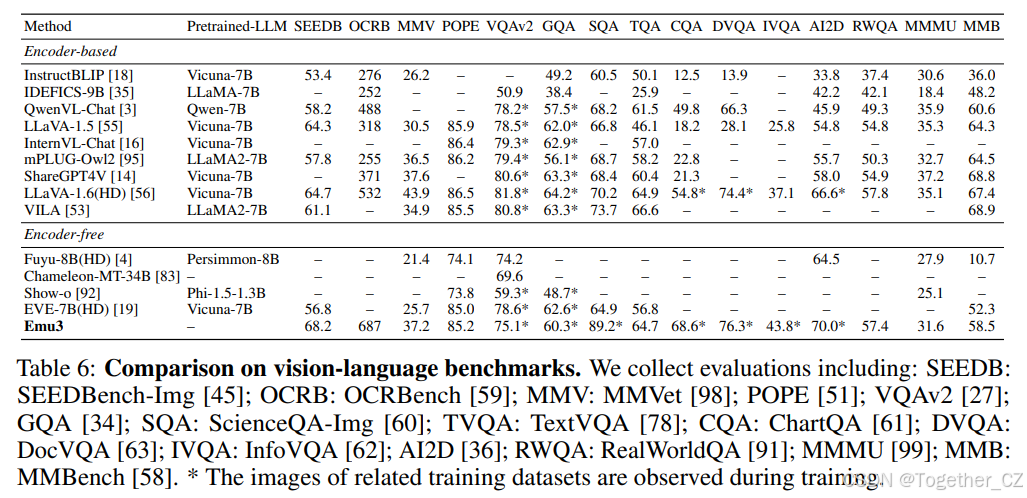
视觉-语言理解
为了评估Emu3在第2.5.2节中微调后的视觉-语言理解能力,我们在各种公开的视觉-语言基准测试中测试了我们的模型。主要结果如表6所示,比较了两类方法:1)使用预训练CLIP视觉编码器的基于编码器的方法,和2)不使用预训练编码器的无编码器方法。Emu3作为纯无编码器方法脱颖而出,在多个基准测试中显著优于其同类方法。这一成就无需依赖专门的预训练LLM和CLIP,突显了Emu3在多模态理解中的内在能力和有前景的潜力。

图8:Emu3 在视频扩展上的定性结果。我们每秒采样3帧进行展示。
4 相关工作
**视觉-语言理解。**CLIP[67]通过在大量图像-文本对上进行对比学习,学习了可泛化的视觉表示,在图像分类任务中取得了令人印象深刻的零样本结果。Flamingo[2]通过连接类似于CLIP的预训练视觉编码器和语言模型,最初展示了有前景的少样本多模态理解能力。随着LLMs的可用性和进展,将预训练视觉编码器与LLMs融合已成为训练广泛视觉-语言模型(VLMs)的常见方法。BLIP系列[49, 48]、MiniGPT4[109]和LLaVA[57]通过将视觉编码器与LLMs连接并在图像-文本对和视觉指令调优数据上进行训练,展示了令人鼓舞的结果。通过精心策划的数据集和改进的训练策略,LLaVA系列[55, 56]和其他令人印象深刻的作品[3, 17]进一步提高了性能。尽管像Fuyu[4]和EVE[19]这样的模型引入了无编码器的视觉-语言架构,将图像块输入LLMs,但它们在竞争最先进的VLMs方面仍面临挑战。Emu3首次证明,仅通过下一个标记预测训练的解码器模型可以与基于编码器的VLMs相媲美甚至超越其性能。这为进一步改进此类架构铺平了道路。
**视觉生成。**视觉生成的最新进展主要由扩散模型[73, 70, 66, 65, 5]主导。这些模型通过扩散过程展示了生成高分辨率图像的令人印象深刻的能力。Stable Diffusion系列的开放源代码推动了这一方向的广泛研究和开发。另一条研究线是训练自回归模型通过预测序列中的下一个标记来生成图像,如DALL-E[71]、CogView[20]和Parti[96]。VideoGPT[93]和VideoPoet[38]也在视频领域采用了自回归方法。然而,它们要么未能与扩散模型相匹配,要么依赖于级联/组合方法,例如VideoPoet使用两阶段的生成和细化框架以及额外的文本编码器。在这项工作中,Emu3展示了单一Transformer解码器的最先进图像和视频生成能力。值得注意的是,我们开源了这些内容以支持这一方向的进一步研究和开发。
**统一理解和生成。**早期的努力试图统一视觉理解和生成[82, 97, 25, 21],探索图像和文本数据上的各种生成目标。Emu和Emu2[82, 81]引入了一个统一的自回归目标:通过回归视觉嵌入或分类文本标记来预测下一个多模态元素。CM3Leon[97]和Chameleon[83]在混合图像和文本数据上训练基于标记的自回归模型。更近期的方法如TransFusion[108]和Show-O[92]试图结合扩散和自回归方法以提升性能。然而,这些模型在视觉生成和理解方面仍落后于任务特定的架构,如SDXL[66]和LLaVA-1.6[56]。Emu3首次证明,跨图像、视频和文本的下一个标记预测可以超越这些已建立的模型,而不依赖于组合方法。
5 结论
在本文中,我们介绍了Emu3,这是一系列通过下一个标记预测在多模态生成和感知方面表现出色的多模态模型。通过将图像、文本和视频标记化为离散空间并从头开始训练一个单一的Transformer,Emu3不仅消除了对扩散和组合方法的依赖,还超越了已建立的任务特定模型如SDXL和LLaVA-1.6。我们的结果提供了令人信服的证据,表明下一个标记预测可以作为多模态模型的强大范式,超越语言模型并在多样任务中提供最先进的性能,包括具有挑战性的视频生成。我们相信,下一个标记预测不仅是可行的,而且在追求通用多模态智能的过程中具有优势,使我们更接近实现人工通用智能。
附录A 数据集详细信息
视频数据集
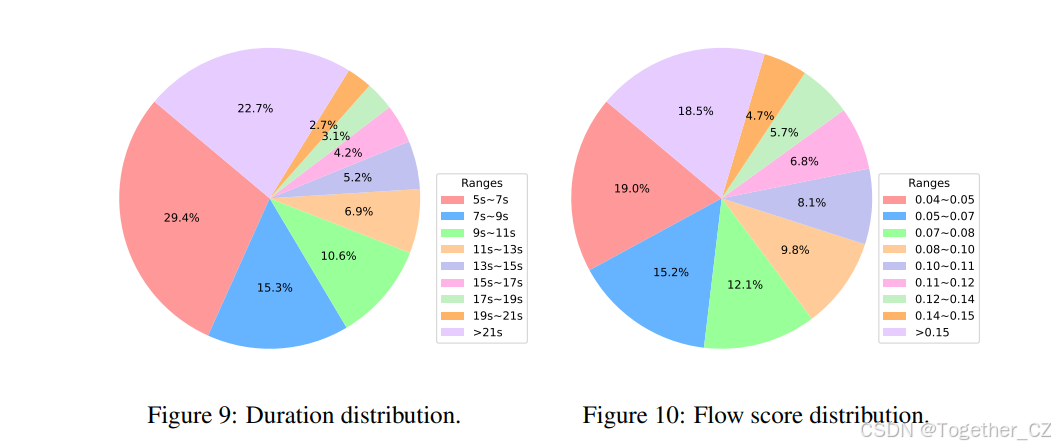
我们分析了剩余片段的分布。剩余片段的时长分布如图9所示。过滤片段的光流分数分布如图10所示。
附录B 评估详细信息
图像生成
对于所有T2I评估,我们将Top-k设置为16,384,Top-p设置为1.0以进行图像生成。Emu3的输出分辨率为512×512。Emu3-DPO的输出分辨率为720×720。
MSCOCO 30K的结果。我们在表4中展示了Emu3和Emu3-DPO在MSCOCO 30K上的零样本CLIP分数和FID。遵循[82],我们从验证集中随机采样30k个提示并计算零样本FID[29]。我们使用CLIP-ViT-B[67]计算CLIP-T分数以评估提示跟随能力。此外,我们使用CLIP-ViT-L[67]计算CLIP-I分数以测量图像相似性。对于DALL-E3和DALL-E2,CLIP-T分数在4,096个样本上计算。我们采用无分类器引导[30]以提高生成质量。引导尺度设置为5.0。MSCOCO 30K中其他方法的结果来自[82; 92; 108]。
GenEval的结果。遵循SD3[22],我们在GenEval基准测试[26]上评估Emu3的文本到图像生成能力。我们在表7中展示了GenEval基准测试的分数,涵盖六个维度,包括“单一对象”、“两个对象”、“计数”、“颜色”、“位置”、“颜色属性”。我们为每个提示生成4张图像,引导尺度为5.5。与Dalle-3一样,我们还报告了使用GPT4-V作为重写器的评估结果。GenEval中其他方法的结果来自[26; 92; 108; 22]。
**T2I CompBench的结果。**遵循Dalle-3[5],我们在表7中报告了颜色绑定、形状绑定和纹理绑定的分数。我们使用BLIP-VQA模型评估这些结果。我们为每个提示生成10张图像,引导尺度为5.0。T2I CompBench中其他方法的结果来自[5; 24; 13]。
**DPG-bench的结果。**为了评估遵循密集文本的能力,我们在DPG-Bench上与最先进的(SoTA)扩散模型进行了比较,该基准测试提供了包含更多详细信息的长提示进行评估。我们在表8中测量了DPG-bench的结果,我们的模型总体得分为81.60,高于SDXL和PixArt-alpha,并与Dalle-3的结果相当。我们使用mPLUG-large模型根据指定问题评估生成的图像。DPG-Benchmark中其他方法的结果来自[31; 54]。我们为每个提示生成4张图像,引导尺度为5.0。
后处理
为了进一步提高时间一致性和视觉质量,我们对生成的视频应用了稳定化和超分辨率技术。视频评估也在处理后的视频上进行。具体来说,我们为这两个任务训练了专门的模型。

**视频稳定化。**我们基于稳定视频扩散[7]的时间VAE训练视频稳定化模型。该模型在我们的策划视频数据上进行训练,结合了L1损失、LPIPS感知损失[104]、GAN损失和KL惩罚[37; 72]。训练数据对由我们的标记器输出的自动编码视频片段和地面真实视频片段组成,两者尺寸均为16×256×256。
**超分辨率。**我们实现了一个用于超分辨率任务的空间-时间unet模型,能够将任何图像或视频片段上采样4倍。我们采用BlurPool[103]进行下采样操作,采用子像素[77]进行上采样操作。该模型在我们策划视频的一部分随机裁剪的8×256×256上进行训练,这些视频的分辨率大于1024×1024,结合了L2损失、LPIPS感知损失[104]和GAN损失。
附录C 多模态理解定性示例
示例
用户 描述地标。
Emu3 图像展示了布鲁克林大桥,这是纽约市一座著名的悬索桥,以其独特的塔楼和支撑它的电缆网而闻名。这座标志性结构连接了布鲁克林区和曼哈顿区。
示例
用户 请用LaTeX格式写出图像中的公式表达式。
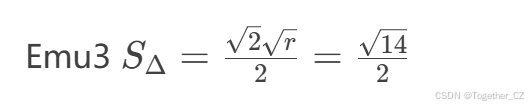
示例
用户 根据给定的食物链,如果浮游植物减少,会发生什么?A. 海豹种群将灭绝 B. 鱼类种群将减少。C. 鲸鱼种群将减少。D. 企鹅种群将增加。直接从给定的选项中选择答案。
Emu3 B
示例
用户 请详细描述图像

Emu3 图像是一本名为“Parktakes”的杂志的封面,这是2017年秋季刊。封面展示了两个人在白色皮划艇中划水。皮划艇呈对角线放置,两人坐在前面。两人都穿着红色带黑色带子的救生衣,手持橙色桨叶的桨。左边的人是一位留着长黑发的女性,戴着墨镜,穿着黑色上衣。右边的人是一位留着短发的男性,穿着绿色衬衫和浅色帽子。两人都面带微笑,享受水上时光。背景显示了一个自然环境,有树木和绿色植物,表明他们可能在一个公园或自然保护区。水面平静,天空不可见,表明环境宁静和平。杂志封面包括几个文本元素:1. 标题:“Parktakes”以大号、粗体、蓝色字母醒目地显示在顶部。2. 秋季2017刊:在右上角以较小的白色字体标记。3. 主要功能:“Enjoy Fall Adventures in Parks”以大号、粗体、橙色字体书写,强调户外活动的主题。4. 附加功能:封面列出了杂志中涵盖的几个主题:- “观鸟、划船和徒步旅行” - “季节性节日” - “新景点” 5. 注册信息:底部有一个行动号召:“8月1日开始注册完整课程”和一个网站链接:“www.fairfaxcounty.gov/parks。” 分析和描述 “Parktakes”的封面有效地传达了户外休闲活动的主题,特别是公园活动。图像中两人在皮划艇中的形象表明杂志内容与皮划艇、独木舟和其他水上运动相关。救生衣的包含表明重点是水上活动的安全和准备。季节性节日和新景点的提及意味着杂志包括公园内各种活动和景点的信息。封面还强调了杂志作为户外活动综合指南的承诺,重点是安全和可访问性。注册信息表明杂志是规划和参与各种户外活动的资源,可能面向对公园和休闲活动感兴趣的广泛受众。总之,杂志封面旨在吸引对户外冒险、安全和季节性公园活动感兴趣的读者。使用皮划艇和救生衣强调了杂志对水上运动和安全的关注,而各种功能和注册信息的包含表明了一个全面的公园游客资源。



















 68
68

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











