






这篇文章介绍了一种名为 MimicTalk 的个性化和富有表现力的3D说话人脸生成框架。其主要内容和贡献如下:
1. 背景与问题
-
说话人脸生成(TFG) 是一个跨模态任务,旨在通过音频驱动生成逼真的说话视频。
-
个性化TFG 强调生成结果与目标人物的外观和说话风格的高度相似性。
-
传统方法通常为每个身份单独训练模型(身份依赖方法),存在训练时间长、泛化能力差、数据效率低等问题。
-
另一种方法是身份无关方法(一次性方法),虽然泛化能力强,但无法利用目标身份的丰富样本,导致个性化不足。
2. MimicTalk 的核心思想
-
利用预训练的身份无关模型:MimicTalk 首次提出利用预训练的3D身份无关模型(基于NeRF),并通过适应过程将其调整为特定身份,从而继承其泛化性和高效性。
-
静态-动态混合适应管道(SD-Hybrid):通过优化三平面表示(静态特征)和注入低秩适应(LoRA)(动态特征),模型能够快速适应新身份,仅需15分钟,比传统方法快47倍。
-
上下文风格化的音频到运动模型(ICS-A2M):该模型通过流匹配技术生成与音频同步的面部运动,并能够模仿参考视频中的说话风格,避免信息丢失。
3. 主要贡献
-
高效性:适应过程仅需15分钟,比传统方法快47倍。
-
表现力:ICS-A2M模型能够生成富有表现力的面部运动,模仿目标人物的说话风格。
-
泛化性:通过身份无关模型的适应,模型在不同身份和音频条件下表现出色。
4. 实验结果
-
定量评估:MimicTalk 在身份相似性、视频质量、唇同步等方面超越了现有基线方法。
-
定性评估:生成的视频在视觉质量和说话风格上表现出色,用户研究也验证了其优越性。
-
消融研究:验证了SD混合适应管道和ICS-A2M模型的有效性。
5. 局限性与未来工作
-
当前方法主要关注面部区域,头发和躯干的建模较为简单,未来计划引入更复杂的模型(如条件视频扩散模型)来提升自然性。
-
未来还将考虑更多的条件,如眼球运动和手势,并提高推理速度。
6. 伦理与影响
-
讨论了说话人脸生成技术可能被滥用于深度伪造等伦理问题,并提出了通过水印和不可见水印等技术来防止滥用。
MimicTalk 通过利用预训练的身份无关模型和高效的适应管道,实现了快速、高质量且富有表现力的个性化3D说话人脸生成,解决了传统方法在效率、泛化和个性化方面的不足。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
说话人脸生成(Talking Face Generation, TFG)旨在通过动画化目标身份的面部来创建逼真的说话视频。个性化TFG是TFG的一个变体,强调合成结果在外观和说话风格上的感知身份相似性。尽管先前的工作通常通过为每个身份学习一个单独的神经辐射场(NeRF)来隐式存储其静态和动态信息,但我们发现由于每个身份的训练框架和有限的训练数据,这种方法效率低下且不具有泛化性。为此,我们提出了MimicTalk,这是首次尝试利用基于NeRF的与身份无关的通用模型中的丰富知识来提高个性化TFG的效率和鲁棒性。具体来说,(1)我们首先提出了一个与身份无关的3D TFG模型作为基础模型,并提出将其适应到特定身份;(2)我们提出了一个静态-动态混合适应管道,帮助模型学习个性化的静态外观和面部动态特征;(3)为了生成个性化的说话风格面部运动,我们提出了一个上下文风格化的音频到运动模型,通过隐式风格表示在参考视频中模仿隐含的说话风格,而不会造成信息损失。对未见过的身份的适应过程可以在15分钟内完成,比之前的身份依赖方法快47倍。实验表明,我们的MimicTalk在视频质量、效率和表现力方面超越了之前的基线。源代码和视频样本在这里,如下所示:

官方项目地址在这里,如下所示:
1 引言
音频驱动的说话人脸生成(TFG)(Prajwal et al., 2020; Hong et al., 2022; Tian et al., 2024; Xu et al., 2024)是一个跨模态任务,利用来自语音、视觉和计算机图形学的多模态知识,在给定任意驱动音频的情况下动画化目标身份的面部,旨在创建逼真的说话视频或交互式虚拟形象。个性化TFG(Suwajanakorn et al., 2017; Thies et al., ; Guo et al., 2021; Lu et al., )是TFG的一个变体,具有几个实际应用,如视频会议和音视频聊天机器人,其中我们强调生成的结果应在视觉质量和表现力方面与特定个体具有出色的感知相似性。在这种情况下,提供目标身份的视频片段(从几秒到几分钟)作为目标人物的详细参考,用于其个性化属性,如几何形状(Mildenhall et al., 2021; Kerbl et al., 2023)和说话风格(Wu et al., 2021; Ma et al., 2023; Tan et al., 2023)。为了满足高感知身份相似性的质量要求,社区主要关注身份依赖的方法(Tang et al., 2022; Li et al., ; Xu et al., 2023),其中为每个目标人物的视频从头开始训练一个单独的模型。这些身份依赖方法流行的主要原因是,在训练过程中,特定人物的模型可以隐式记忆目标人物视频的细微个性化细节,如他们的说话风格和微表情,这些细节很难通过手工条件明确表示。因此,这些方法可以训练小规模的身份依赖模型,实现高身份相似性和富有表现力的结果。
然而,身份依赖方法(Tang et al., 2022; Li et al., )面临两个众所周知的挑战:(1)第一个是泛化能力弱。每个身份的训练数据规模有限,限制了模型在推理过程中对域外(OOD)条件的泛化能力。例如,当由OOD音频(不同语言或说话者)驱动时,唇同步性能可能会下降,当合成OOD表情(如大角度偏转)时,渲染可能会失败。(2)第二个是训练和样本效率低。由于身份依赖模型需要在目标人物视频上从头开始训练,并且无法享受先验知识,训练过程可能需要几个小时(训练效率低),并且通常需要超过1分钟的训练数据才能实现合理的唇同步结果(样本效率低)。相比之下,另一类工作,身份无关(或称一次性)TFG方法(Zhou et al., 2020; Wang et al., 2021; Zhao and Zhang, 2022; Li et al., )在训练过程中结合了各种身份的视频,并在推理过程中仅使用一张源图像,由于在训练过程中看到了各种音频/表情,因此可以实现对OOD条件的良好泛化。然而,由于单张输入图像中的信息有限,一次性方法无法利用目标身份的丰富样本来模仿其个性化属性。因此,弥合身份无关的一次性方法与身份依赖的小规模模型之间的差距,以实现富有表现力、泛化和高效的个性化TFG是很有前景的。
本文的贡献总结如下:
-
我们是首个考虑利用3D身份无关模型进行个性化TFG的工作。我们提出了一个静态-动态混合管道,用于高效且高质量地适应目标说话者的静态和动态特征。
-
我们提出了ICS-A2M模型,实现了高质量的唇同步和上下文风格化的音频驱动TFG。
-
我们的MimicTalk仅需要几秒长的参考视频作为训练数据,训练时间仅需几分钟。实验表明,我们的MimicTalk在表现力和视频质量方面超越了之前的身份依赖基线,同时实现了47倍的收敛速度。
2 相关工作
我们的工作主要关于个性化和富有表现力的说话人脸生成。我们分别讨论了说话人脸生成和富有表现力的协同语音面部运动生成的相关工作。
说话人脸生成
根据不同的实际应用,说话人脸生成(TFG)方法主要分为两种设置:身份无关和身份依赖。身份无关方法专注于一次性场景:模型仅提供一张图像,旨在通过动画化该图像来创建视频。这些方法因此训练了一个大规模的通用模型,使用大量身份视频数据,以便在推理阶段可以泛化到未见过的照片。另一方面,身份依赖方法专注于为特定说话者实现更好的视频质量:通常使用目标用户的一段视频作为训练数据,并期望模型模仿该说话者的个性化特征,称为个性化TFG。这两类工作多年来独立发展,并发展出显著不同的方法。(1)对于身份无关方法,最早的工作(Chung et al., 2017; Prajwal et al., 2020; Wang et al., 2022)通常采用像素到像素的框架(Isola et al., 2017)或生成对抗网络(GAN)设置来生成结果,导致训练不稳定和视觉质量差。然后,大多数先前的工作(Averbuch-Elor et al., 2017; Ren et al., 2021; Wang et al., 2021; Hong et al., 2022; Zhao and Zhang, 2022; Hong and Xu, 2023; Liang et al., 2024; Jiang et al., )采用密集变形场(Siarohin et al., 2019)来根据从驱动资源中提取的3D感知关键点变形源图像的像素。变形方法实现了更好的图像保真度,但由于缺乏3D先验知识,偶尔会产生变形和失真伪影。最近,为了处理这些伪影,一些工作(Zeng et al., 2022; Sun et al., 2023; Li et al., , ; Ye et al., 2024)提出了一次性NeRF方法,通过从源图像中学习重建3D面部表示(三平面)(Chan et al., 2022)。(2)对于身份依赖设置(Thies et al., ; Yi et al., 2020; Lu et al., ; Ye et al., 2022),其在特定视频上训练一个单独的模型,最近的工作(Guo et al., 2021; Yao et al., 2022; Tang et al., 2022; Ye et al., 2023; Li et al., )主要基于NeRF,因其高图像保真度和逼真的3D建模。尽管基于NeRF的身份特定方法在所有TFG方法中实现了最佳的视频质量和身份相似性,但其对驱动条件的泛化能力受到有限训练数据的限制。据我们所知,MimicTalk是首个考虑弥合基于NeRF的身份无关和身份依赖方法之间差距的工作,以改进个性化TFG任务。
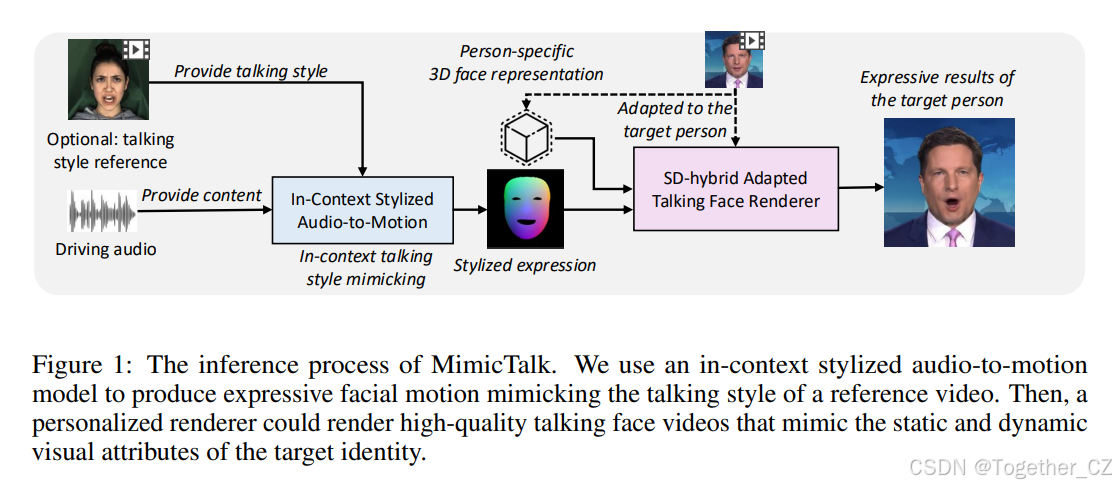
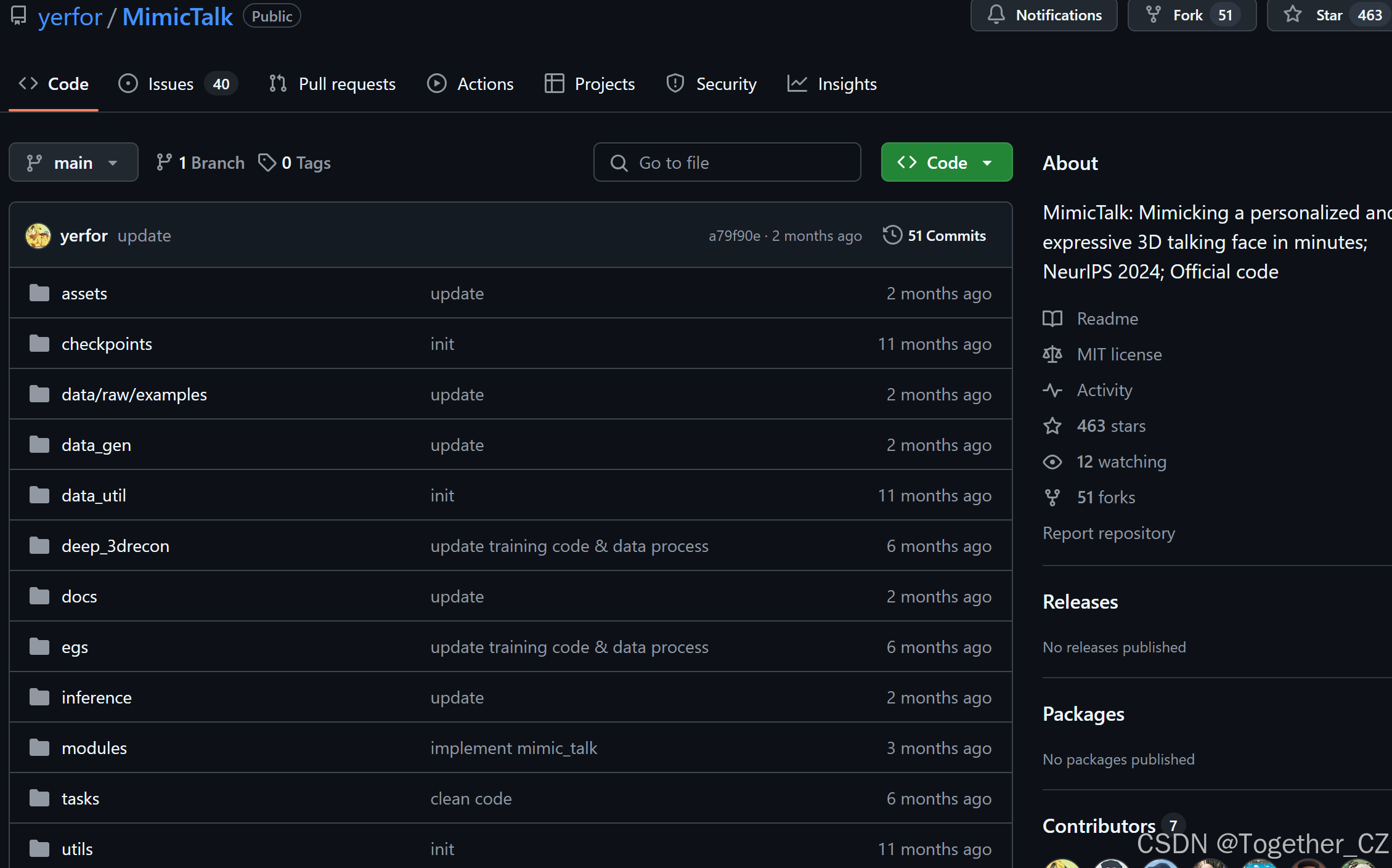
图1:MimicTalk的推理过程。我们使用一个上下文风格化的音频到运动模型来生成模仿参考视频说话风格的富有表现力的面部运动。然后,个性化渲染器可以渲染出高质量的说话人脸视频,模仿目标身份的静态和动态视觉属性
富有表现力的面部运动生成
神经渲染的最新进展显著提高了合成视频的图像质量、时间一致性和稳定性,使得表现力成为TFG社区的下一个关注点。实现高表现力的关键挑战是从音频内容生成高质量的面部运动。这要求生成的运动序列不仅与音频轨道同步,还要反映与目标说话者一致且富有表现力的说话风格。一些研究在确定性和端到端的音频到图像模型中隐式建模这一过程(Prajwal et al., 2020; Guo et al., 2021)。为了更好的可控性和音频唇同步,其他工作提出了使用外部生成模型显式建模音频到运动的映射(Thies et al., ; Ye et al., 2023)。然而,这些研究并未显式建模说话者的说话风格。为了解决这一问题,Wu et al. (2021) 和 Ma et al. (2023) 开发了一种从任意运动序列中提取的风格向量,以实现显式的说话风格控制。EMMN(Tan et al., 2023)解耦了表情风格和唇部运动,构建了一个记忆库,以生成具有生动表情的唇同步视频。一项并发工作,VASA-1(Xu et al., 2024),提出将先前的音频/运动潜在作为潜在扩散模型的输入,以保持时间一致性。我们可以看到,大多数先前的方法依赖于中间表示来表示说话风格,存在信息丢失的风险。相比之下,我们的方法首先实现了上下文学习(ICL)的说话风格控制,更好地保留了目标身份的说话风格。
图1:MimicTalk的推理过程。我们使用一个上下文风格化的音频到运动模型来生成模仿参考视频说话风格的富有表现力的面部运动。然后,个性化渲染器可以渲染出模仿目标身份静态和动态视觉属性的高质量说话人脸视频。
3 MimicTalk
如图1所示,MimicTalk是一个个性化和富有表现力的3D说话人脸生成框架,其中个性化渲染器通过静态-动态(SD)混合适应管道继承了与身份无关的通用模型中的丰富面部知识(在第3.1节中讨论)。在第3.2节中,我们提出了一个上下文风格化的音频到运动(ICS-A2M)模型,以生成个性化的面部运动,这对于在生成的视频中实现高表现力是必要的。我们在以下部分描述了设计和训练过程。由于篇幅限制,我们在附录B中提供了技术细节。
基于NeRF的身份无关渲染器
先前的个性化TFG工作在目标说话者上训练了一个单独的模型,以记忆目标人物的个性化信息,其中NeRF通常用作底层技术,以更好地存储目标说话者的几何、纹理和其他信息。我们旨在利用预训练的身份无关TFG模型的先验知识,以实现比先前身份依赖方法更大的泛化性和效率。为此,我们求助于最近的一次性NeRF基TFG工作(Li et al., ; Ye et al., 2024; Chu et al., 2024)来构建一个身份无关的TFG模型。具体来说,我们在Real3D-Portrait(Ye et al., 2024)的基础上构建了我们的基础模型,并使用了其官方实现4。如图2所示,第一步是从目标人物的源图像![]() 重建一个标准的3D面部(表示为三平面表示Chan et al., 2022):
重建一个标准的3D面部(表示为三平面表示Chan et al., 2022):

其中FaceRecon是一个基于SegFormer(Xie et al., 2021)的图像到3D面部重建模型,将输入图像转换为三平面表示(Chan et al., 2022)。然后,一个轻量级的基于SegFormer的运动适配器可以控制3D面部的表情,而Mip-NeRF(Barron et al., 2021)的体积渲染器可以通过控制相机渲染任意头部姿势的动态说话面部:

我们在附录B的图5中提供了身份无关渲染器的FaceRecon、MotionAdapter、VolumeRenderer和SuperResolution的详细网络结构。有关一次性身份无关基础模型的更多细节,请参阅Ye et al., 2024。
静态-动态混合身份适应
在第3.1节中介绍了预训练的身份无关渲染器后,我们可以为未见过的身份合成说话人脸视频,而无需任何适应。然而,未调整的渲染器与先前的身份依赖方法之间存在显著的身份相似性差距,这体现在两个方面:(1)静态相似性,衡量生成的帧是否具有与目标身份相同的纹理(如皱纹、牙齿和头发)或几何细节;(2)动态相似性,描述输入运动条件与输出面部图像中的面部肌肉/躯干运动之间的关系。更直观地说,在具有各种说话者的说话人脸数据集上训练的身份无关模型学习了面部动画的统计平均运动到图像映射,生成的说话人脸视频在语义上是正确的,但缺乏个性化特征。相比之下,先前的身份依赖方法通过在单个目标身份上过度拟合模型,内在地学习了模型中的个性化运动到图像映射。基于上述观察,我们提出了一个高效的静态-动态混合(SD-Hybrid)适应管道,以实现良好的静态/动态身份相似性,如图2所示。
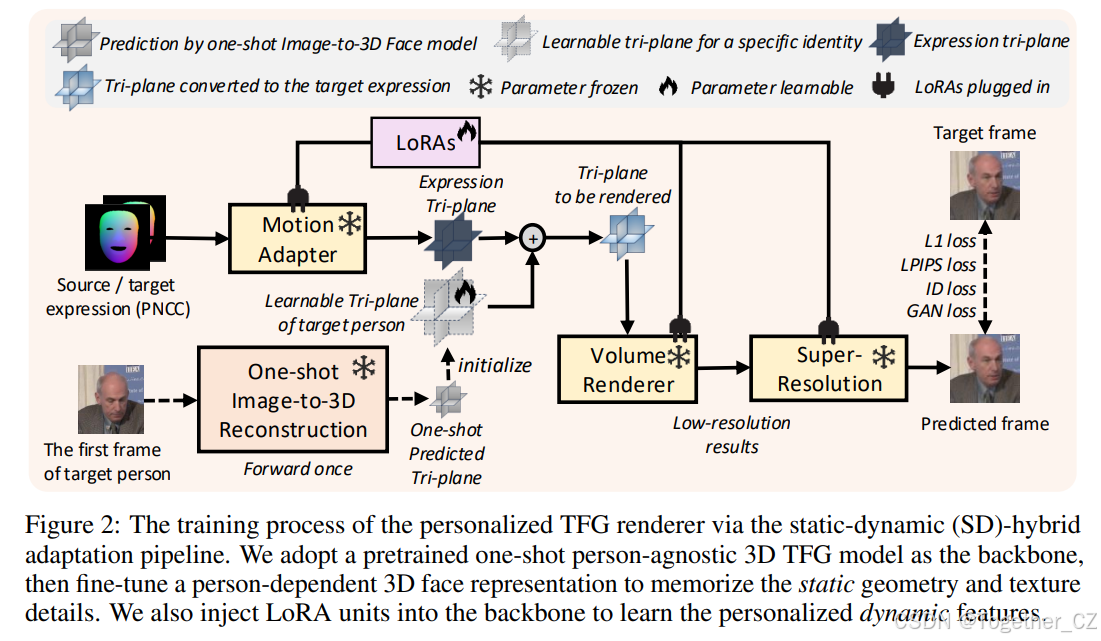
图2:通过静态-动态(SD)混合适应管道的个性化TFG渲染器的训练过程。我们采用预训练的一次性身份无关3D TFG模型作为骨干,然后微调一个身份依赖的3D面部表示,以记忆静态的几何和纹理细节。我们还向骨干中注入LoRA单元,以学习个性化的动态特征
三平面反演以实现静态相似性。 从源图像中通过预训练的3D面部重建模型(Ye et al., 2024)提取的标准3D面部表示![]() 存储了目标身份的所有静态属性(即几何和纹理信息)。我们发现,这种前馈图像到3D转换中的信息损失是我们方法中静态相似性较差的主要原因。为此,受先前GAN反演方法(Roich et al., 2021)的启发,我们提出了一种三平面反演技术,将标准3D面部表示视为可学习的参数,并对其进行优化以最大化静态身份相似性。具体来说,如图2所示,当适应模型到特定身份的给定视频片段时,我们使用第一帧的图像到3D预测初始化可学习的三平面,然后与其他参数一起优化三平面。
存储了目标身份的所有静态属性(即几何和纹理信息)。我们发现,这种前馈图像到3D转换中的信息损失是我们方法中静态相似性较差的主要原因。为此,受先前GAN反演方法(Roich et al., 2021)的启发,我们提出了一种三平面反演技术,将标准3D面部表示视为可学习的参数,并对其进行优化以最大化静态身份相似性。具体来说,如图2所示,当适应模型到特定身份的给定视频片段时,我们使用第一帧的图像到3D预测初始化可学习的三平面,然后与其他参数一起优化三平面。
注入LoRAs以实现动态相似性。 对于动态相似性,由于身份无关模型在多说话者说话人脸数据集中学习了平均的运动到图像映射,我们需要将通用模型专门适应到目标人物的视频,以学习其个性化的面部动态。一个简单的解决方案是直接在目标人物的视频上微调整个模型或最后几层。然而,考虑到模型容量大和目标人物视频的数据规模小,这面临几个挑战,如高GPU内存占用、训练不稳定和灾难性遗忘。为此,我们求助于低秩适应(LoRA)(Hu et al., 2021),最初是为高效适应语言模型而提出的,最近已扩展到计算机视觉应用,如文本到图像合成(Rombach et al., 2021)。如图6所示,LoRAs可以通过在每个线性层和卷积核中注入低秩可学习矩阵方便地插入到我们的身份无关模型中。身份无关模型中的所有预训练参数在训练期间保持固定,只有LoRAs被更新。
适应过程。 如图2所示,通过SD混合设计,预测图像的渲染过程可以表示为:

图2:通过静态-动态(SD)混合适应管道的个性化TFG渲染器的训练过程。我们采用预训练的一次性身份无关3D TFG模型作为骨干,然后微调一个身份依赖的3D面部表示以记忆静态几何和纹理细节。我们还向骨干中注入LoRA单元以学习个性化的动态特征。
其中![]() 分别表示L1损失、VGG16的LPIPS损失(Simonyan and Zisserman, 2014)和VGGFace的身份损失(Cao et al., 2018)。我们将学习率设置为0.001,
分别表示L1损失、VGG16的LPIPS损失(Simonyan and Zisserman, 2014)和VGGFace的身份损失(Cao et al., 2018)。我们将学习率设置为0.001, 。得益于静态-动态混合设计,我们的方法在实现良好的身份相似性的同时,享受了比现有身份依赖方法更快的低内存成本适应过程,如表1所示。此外,我们在图4中展示了我们的SD混合管道在训练和样本效率方面的良好表现。
。得益于静态-动态混合设计,我们的方法在实现良好的身份相似性的同时,享受了比现有身份依赖方法更快的低内存成本适应过程,如表1所示。此外,我们在图4中展示了我们的SD混合管道在训练和样本效率方面的良好表现。
上下文风格化的音频到运动
在上述部分中,我们提出了一个统一的框架用于运动条件下的说话人脸生成。然后,我们提出了**上下文风格化的音频到运动(ICS-A2M)**模型,以生成个性化的面部运动,用于音频驱动的场景。
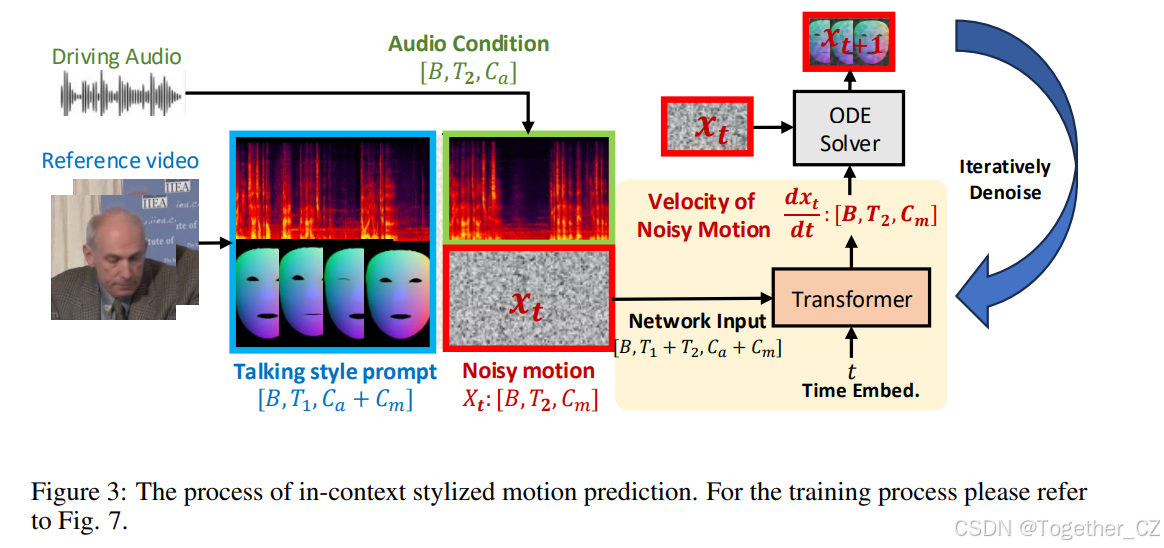
图3:上下文风格化运动预测的过程。有关训练过程,请参阅图7
音频引导的运动填充任务受大规模语言模型(Liu et al., 2023)和文本到语音合成(Le et al., 2023)中上下文学习方法成功的启发,我们设计了一个音频引导的运动填充任务。我们在附录B.3的图7中可视化了音频引导的运动填充任务的详细训练和推理管道。具体来说,音频-运动对在时间上对齐并在通道上连接,并由音频到运动模型处理。在训练过程中,我们在运动轨迹中随机掩码几个片段,并使用掩码片段上的运动重建误差训练模型。由于模型提供了周围未掩码的运动和完整的音频轨道,它学习利用运动上下文中的说话风格来更准确地预测掩码的协同语音运动。在推理过程中,如图3(a)所示,我们可以将参考音频-运动对作为说话风格提示,任意驱动音频作为条件,以及预测运动的噪声占位符作为模型的输入。这样,模型可以预测与音频同步的面部运动,并具有风格提示中提供的说话风格。

了流匹配的详细预备知识。为了直观起见,我们在图3(a)中可视化了基于流匹配的音频到运动模型的前向过程。网络输入与我们在前一段中定义的相同(风格提示、音频条件和噪声运动xtxt的连接)。模型的输出是噪声运动的速度vt,我们可以通过条件流匹配(CFM)目标来训练模型:


4 实验
实验设置
实现细节 我们从Ye et al., 2024的官方实现中获取了预训练的身份无关渲染器。对于SD混合适应,我们在1个Nvidia A100 GPU上训练模型,批量大小为1,总共迭代2000次,需要约8GB的GPU内存和0.26小时。关于ICS-A2M模型,我们在4个Nvidia A100 GPU上训练,每个GPU的批量大小为20000个梅尔帧。基于流匹配的ICS-A2M模型训练了500000次迭代,耗时80小时。我们在附录C中提供了完整的实验细节。
数据准备 为了评估个性化渲染器,我们在Tang et al., 2022和Ye et al., 2023提供的10个3分钟长的目标人物视频上进行了测试。为了训练ICS-A2M模型,我们使用了一个大规模的唇读数据集VoxCeleb2(Chung et al., 2018),该数据集包含来自6112位名人的约2000小时视频。
对比基线 我们将我们的方法与三种身份依赖方法进行了比较:(1)RAD-NeRF(Tang et al., 2022),(2)GeneFace(Ye et al., 2023),和(3)ER-NeRF(Li et al., )。我们还与一种考虑控制说话风格的TFG方法进行了比较,(4)StyleTalk(Ma et al., 2023)。我们在附录A中讨论了所有测试方法的特性。
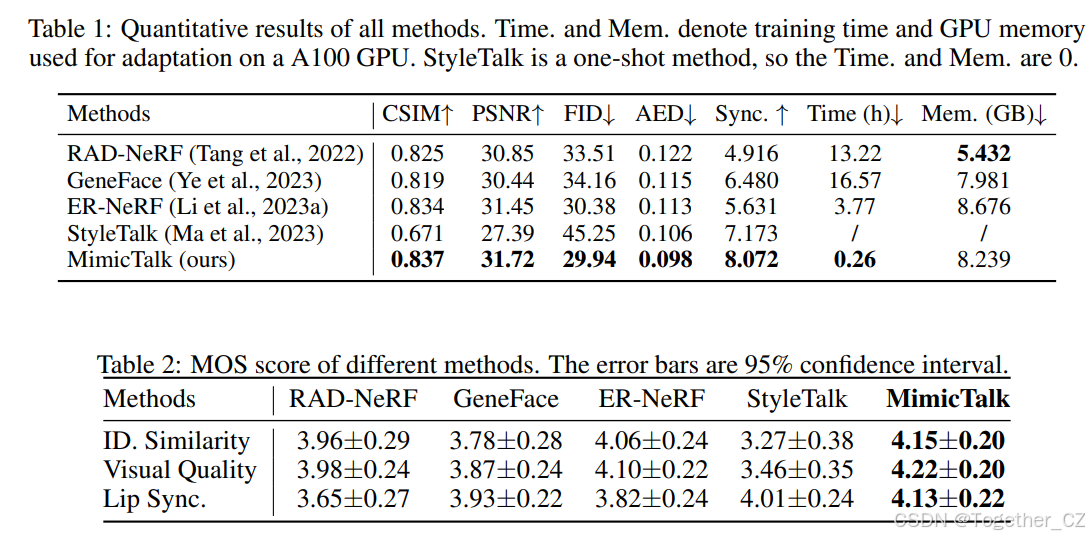
定量评估
我们使用CSIM来衡量身份保留,PSNR和FID来衡量图像质量,AED(Deng et al., 2019)和SyncNet置信度(Chung and Zisserman, 2017)来衡量音频唇同步。结果如表1所示。我们有以下观察结果:(1)得益于强大的流匹配模型和上下文风格模仿能力,我们的方法在唇同步准确性(AED)和感知唇同步质量(SyncNet置信度)方面表现最佳;(2)我们的SD混合适应渲染器在视觉质量上优于身份特定基线;(3)得益于基于LoRA的适应过程的效率,我们的方法在2000次迭代内适应新身份,仅需15分钟(比RAD-NeRF快47倍),并且适应过程中所需的GPU内存使用量较低(8.239GB)。
定性评估
4.3.1 案例研究
我们在https://mimictalk.github.io提供了演示视频。我们还采用了几个案例研究来展示更好的性能。具体来说,(1)我们的_SD混合适应在训练/样本效率上优于先前的身份特定方法_;(2)我们的_ICS-A2M模型预测了风格一致的面部运动_。
SD混合适应的训练/样本效率 为了评估我们的SD混合适应的训练和样本效率,我们进行了Tang et al., 2022提供的奥巴马总统说话视频的案例研究。对于训练效率,如图4(a)所示,我们在180秒长的视频片段上进行模型适应,并使用剩余的10秒片段作为验证集。我们的SD混合适应享受了快速收敛和良好的性能,优于身份特定基线。对于样本效率,我们在图4(b)中可视化了不同训练数据量下的CSIM结果。可以观察到,随着训练数据量的增加,CSIM分数有所提高。此外,我们的方法在使用仅三分之一的数据(60秒)时,达到了与使用180秒数据训练的身份特定基线相当的性能。
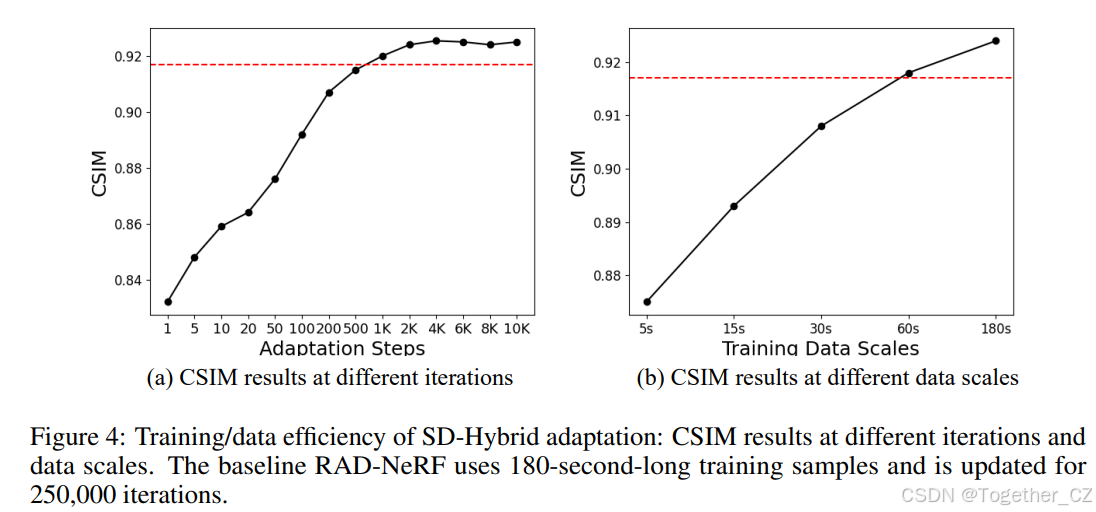
图4:SD混合适应的训练/数据效率:不同迭代次数和数据量下的CSIM结果。基线方法RAD-NeRF使用180秒长的训练样本,并更新250,000次迭代
ICS-A2M模型的一致说话风格运动预测 给定一个短参考视频作为说话风格提示,我们的ICS-A2M模型可以准确模仿其说话风格(如微笑或鸭嘴)。我们在https://mimictalk.github.io/static/videos/demo_ics_a2m.mp4提供了演示视频以更好地展示。我们还进行了与StyleTalk(Ma et al., 2023)的对比平均意见得分(CMOS)测试,以定性评估说话风格的准确性。如表3所示,我们的方法在说话风格控制和身份相似性方面表现更好。请参阅附录C.3以获取详细的用户研究设置。

4.3.2 用户研究
我们进行了平均意见得分(MOS)测试,以评估生成样本的感知质量,评分范围为1到5。根据Chen et al., 2020,参与者需要从三个方面对视频进行评分:(1)身份相似性,(2)视觉质量,和(3)唇同步。详细设置见附录C.3。结果如表2所示。我们有以下观察结果:(1)我们的方法在唇同步和身份相似性/视觉质量方面优于SOTA身份依赖方法(RAD-NeRF、GeneFace和ER-NeRF)。MOS结果证明了所提出的MimicTalk框架的有效性。
4.3.3 消融研究
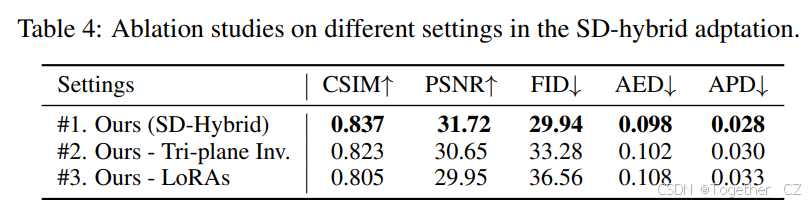
SD混合适应 我们在SD混合适应中测试了两种设置:(1)不进行三平面反演以微调个性化的三平面,(2)不在模型中注入LoRAs。如表4的第2行和第3行所示,同时使用这两种技术在身份相似性(CSIM)、视觉质量(FID)和几何准确性(AED和APD)方面表现最佳。
ICS-A2M模型 我们还分析了ICS-A2M中的三种设置:(1)将流匹配模型替换为确定性变换器,如表5的第2行所示,这导致运动重建质量较差和同步得分较低;(2)将上下文风格控制替换为手工风格向量(Wu et al., 2021)或学习风格编码器(StyleTalk,Ma et al., 2023),如表5的第3行和第4行所示,这导致运动重建质量较差,证明ICL说话风格模仿可以防止将风格压缩为全局编码所导致的信息丢失;(3)在训练过程中移除同步损失,如表5的第5行所示,这导致显著的感知唇同步性能下降。
表5:ICS-A2M模型在不同设置下的消融研究。L2Landmark表示68个3D关键点的L2重建误差,LSync表示由(Chung和Zisserman, 2017)以及(Ye等, 2023)提供的音频-表情同步对比损失
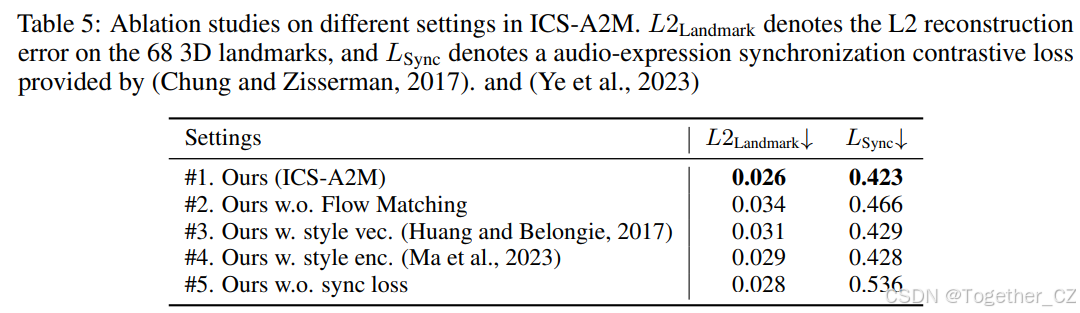
图4:SD混合适应的训练/数据效率:不同迭代次数和数据量下的CSIM结果。基线RAD-NeRF使用180秒长的训练样本,并更新250000次迭代。
5 结论
在本文中,我们提出了MimicTalk,一个高效且富有表现力的个性化说话人脸生成框架。我们首先提出了将预训练的3D身份无关模型适应到个性化数据集的想法,以继承其泛化性并实现快速训练。SD混合适应管道帮助通用模型学习目标人物的静态和动态特征,从而在身份相似性方面优于先前的身份依赖基线。此外,所提出的ICS-A2M模型是首个实现上下文说话风格控制的面部运动生成器,有助于在生成的视频中产生富有表现力的面部运动。由于篇幅限制,我们在第E节中提供了影响声明,并在附录D中讨论了局限性和未来工作。
附录
附录A:不同方法的比较
对于身份依赖的说话人脸渲染器,所有先前的方法如RAD-NeRF(Tang et al., 2022)、GeneFace(Ye et al., 2023)和ER-NeRF(Li et al., )都遵循每个身份每个训练的范式,这意味着他们必须为每个未见过的身份从头开始学习一个模型,这非常耗时,并且由于训练数据规模小,模型的泛化能力有限。相比之下,我们的方法是首个将预训练的通用一次性3D说话人脸模型适应到目标身份的工作。得益于使用LoRA和三平面反演,我们的方法可以在2000次迭代内收敛(比RAD-NeRF快47倍),并享受更好的泛化性、样本效率和训练效率,因为使用了通用的骨干。
对于音频驱动的TFG中的音频到运动模型,大多数先前的工作如SadTalker(Zhang et al., 2023)和StyleTalk(Ma et al., 2023)使用确定性映射来建模音频到运动的转换,无法实现说话风格控制。相比之下,我们的方法首次引入了流匹配用于音频到运动任务,并实现了上下文说话风格控制。
附录B:模型细节
B.1 身份无关渲染器的网络结构
我们在图5中提供了身份无关渲染器的详细网络结构。
B.2 LoRAs在SD混合适应中的细节

B.3 上下文风格化的音频到运动模型的细节
B.3.1 音频引导的运动填充任务
在图7中,我们展示了音频引导的运动填充任务的训练和推理过程的可视化。该任务需要成对的音频-运动样本,这些样本可以从说话人脸数据集中轻松提取并作为训练数据使用。在训练过程中,我们在运动轨迹中随机掩码几个片段,并鼓励模型基于完整的音频轨道和未掩码的运动上下文重建这些片段。这种训练方法使模型能够学习模仿上下文中提供的说话风格。
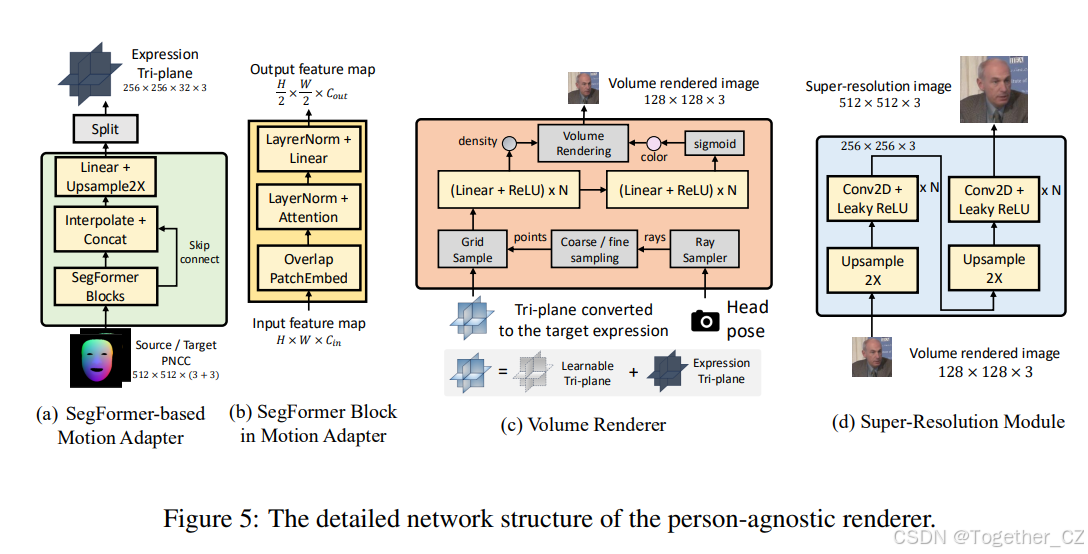
图5:身份无关渲染器的详细网络结构。
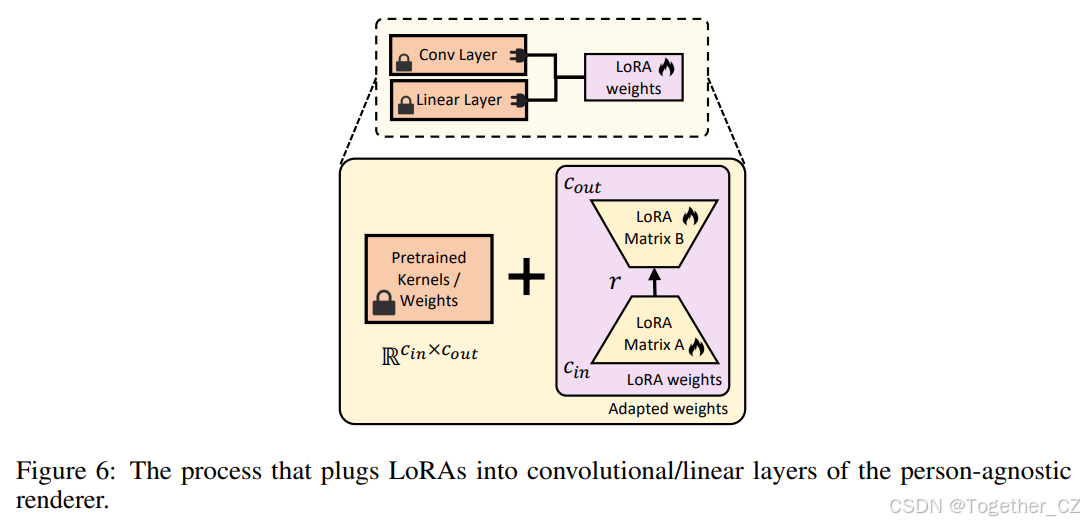
图6:将LoRAs插入到卷积/线性层的身份无关渲染器的过程。
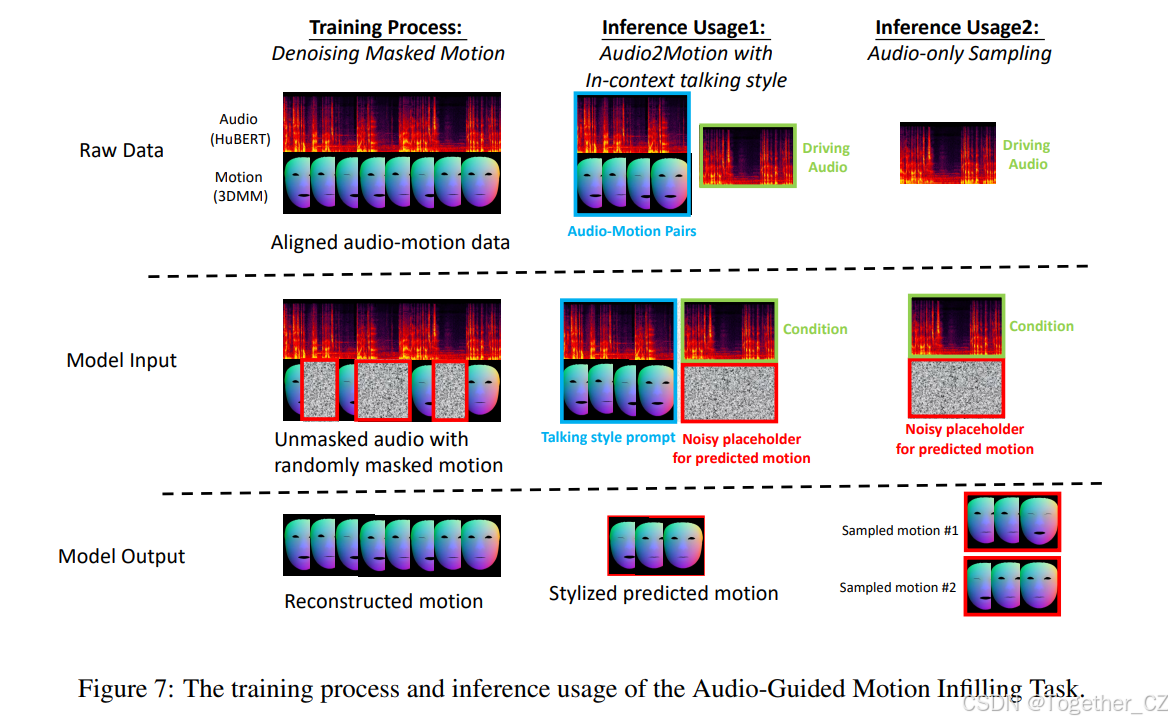
图7:音频引导的运动填充任务的训练过程和推理使用。
B.3.2 流匹配的预备知识
我们考虑将数据点xt的生成过程公式化为常微分方程(ODE):

附录C:实验细节
在以下部分中,我们介绍了MimicTalk的模型配置和训练细节。
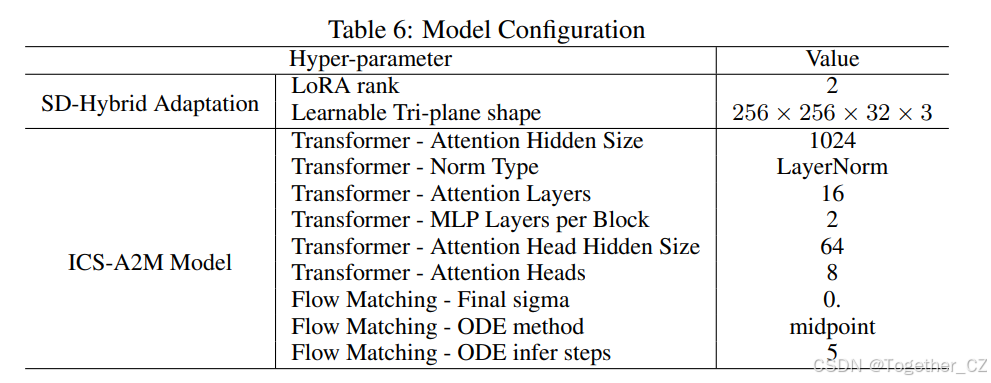
C.1 模型配置
我们在表6中提供了模型配置的详细超参数设置。
C.2 训练细节
我们使用了Ye et al., 2024的官方实现中提供的预训练一次性身份无关渲染器。对于SD混合适应,我们在1个Nvidia A100 GPU上训练模型,批量大小为1,需要约8GB的GPU内存。令人惊讶的是,我们的方法在仅2000次迭代内就取得了比现有身份特定基线更好的结果,耗时约0.26小时,比RAD-NeRF快47倍。
关于ICS-A2M模型,我们在4个Nvidia A100 GPU上训练,每个GPU的批量大小为20000个梅尔帧。基于流匹配的ICS-A2M模型训练了500000次迭代,耗时80小时。
C.3 详细的用户研究设置
对于表2中的平均意见得分(MOS)测试,我们选择了5个音频片段和10个训练身份(如Tang et al., 2022和Ye et al., 2023所使用的)来构建每个方法的50个说话人像视频样本。每个视频由20名参与者评分。我们进行了身份相似性、视觉质量和唇同步的MOS评估。对于MOS,每个测试者被要求在1-5的李克特量表上对视频进行主观评分。对于身份相似性,我们告诉参与者_"只关注源图像中的身份与视频中的身份的相似性";对于视觉质量,我们告诉参与者"关注整体视觉质量,包括图像保真度和相邻帧之间的平滑过渡";对于唇同步,我们告诉参与者"只关注语义层面的音频唇同步,忽略视觉质量"_。
对于表3中的对比平均得分(CMOS)测试,我们首先在10个身份的10秒长视频上训练了10个身份特定渲染器。我们随机选择了5个域外音频片段来驱动每个渲染器。因此,每个设置有50个结果视频。我们在用户研究中包括了20名参与者。每个测试者被要求在-3到+3的李克特量表上对两个配对视频进行主观评分(例如,第一个视频始终为0.0,第二个视频为+3表示测试者强烈偏好第二个视频)。为了检查(唇同步、姿势同步、表现力)方面,我们告诉参与者_"只关注(唇同步、姿势同步、表现力),忽略其他两个因素。"_
附录D:局限性和未来工作
在本节中,我们讨论了所提出方法的局限性,并计划在未来的工作中如何处理这些局限性。首先,在本文中,我们的主要关注点是面部区域。相比之下,头发和躯干区域的刚性建模相对简单,偶尔会产生伪影。我们计划采用条件视频扩散模型(如Hu et al., 2023)来增强头发和躯干区域的自然性。其次,我们可以考虑更多的条件,如眼球运动和手势。最后,推理速度(在1个A100上为15 FPS)可以通过引入更高效的网络结构(如高斯Splatting)来提高。
附录E:更广泛的影响
在本节中,我们讨论了快速发展的说话人脸生成技术可能带来的伦理影响,以及我们为解决这些担忧所采取的措施。
MimicTalk促进了高效且富有表现力的个性化说话人脸合成。随着说话人脸生成技术的发展,合成说话人像视频变得非常容易。在适当的使用下,这项技术可以促进虚拟偶像和客户服务等实际应用,提升用户体验并使人类生活更加便利。然而,说话人脸生成方法可能被滥用于深度伪造相关用途,引发伦理担忧。我们高度致力于解决这些滥用问题。为此,我们计划在MimicTalk的许可证中包含几项限制。具体来说,
-
我们将在MimicTalk合成的视频中添加可见水印,以便公众可以轻松识别合成视频的虚假性。
-
合成的视频应仅用于教育或其他合法用途(如在线课程),任何滥用将通过我们提出的方法进行追踪并承担责任。
-
我们还将向合成视频中注入不可见水印,以存储视频制作者的信息,以便视频制作者必须对合成视频可能带来的潜在风险负责。



















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











