






这篇文章介绍了HuBERT(Hidden-Unit BERT),一种自监督语音表示学习方法。HuBERT通过掩码预测连续输入的隐藏单元聚类分配来进行预训练,解决了语音信号中多个声音单元、缺乏词典和单元边界不明确的问题。其核心思想是利用离线聚类步骤生成噪声标签,并仅对掩码区域应用预测损失,迫使模型学习未掩码输入的高级表示,从而推断掩码输入的目标。
HuBERT在Librispeech(960小时)和Libri-light(60,000小时)数据集上进行了预训练,并在多个微调子集(10分钟、1小时、10小时、100小时和960小时)上与最先进的wav2vec 2.0模型进行了比较,结果显示HuBERT在大多数情况下性能相当或有所提升。特别是,使用10亿参数的HuBERT模型在更具挑战性的dev-other和test-other子集上,相对WER分别减少了19%和13%。
文章还详细介绍了HuBERT的实现细节,包括模型架构、预训练和微调过程,并进行了多项消融研究,分析了不同聚类方法、掩码策略和超参数对模型性能的影响。最终,HuBERT展示了其在低资源和高资源设置下的优越性能,并表明通过迭代细化聚类分配,学习到的表示质量显著提高。
HuBERT通过自监督学习方法,显著提升了语音表示的质量,并在多个语音识别任务中取得了最先进的性能。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
官方发布了相关的预训练模型,如下:
| Model | Pretraining Data | Finetuning Dataset | Model | Quantizer |
|---|---|---|---|---|
| HuBERT Base (~95M params) | Librispeech 960 hr | No finetuning (Pretrained Model) | download | L9 km500 |
| HuBERT Large (~316M params) | Libri-Light 60k hr | No finetuning (Pretrained Model) | download | |
| HuBERT Extra Large (~1B params) | Libri-Light 60k hr | No finetuning (Pretrained Model) | download | |
| HuBERT Large | Libri-Light 60k hr | Librispeech 960 hr | download | |
| HuBERT Extra Large | Libri-Light 60k hr | Librispeech 960 hr | download |
模型加载实现如下:
ckpt_path = "/path/to/the/checkpoint.pt"
models, cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task([ckpt_path])
model = models[0]模型训练操作流程如下:
1、数据准备
按照./simple_kmeans中的步骤创建以下文件:
{train,valid}.tsv:波形列表文件{train,valid}.km:帧对齐的伪标签文件dict.km.txt:一个虚拟字典
标签率与用于聚类的特征帧率相同,默认情况下,MFCC特征的标签率为100Hz,HuBERT特征的标签率为50Hz。
2、预训练HuBERT模型
假设{train,valid}.tsv保存在/path/to/data,{train,valid}.km保存在/path/to/labels,标签率为100Hz。
要训练一个基础模型(12层Transformer),请运行:
$ python fairseq_cli/hydra_train.py \
--config-dir /path/to/fairseq-py/examples/hubert/config/pretrain \
--config-name hubert_base_librispeech \
task.data=/path/to/data task.label_dir=/path/to/labels task.labels='["km"]' model.label_rate=1003、使用CTC损失微调HuBERT模型
假设{train,valid}.tsv保存在/path/to/data,其对应的字符文本{train,valid}.ltr保存在/path/to/trans。
要微调一个预训练的HuBERT模型(位于/path/to/checkpoint),请运行:
$ python fairseq_cli/hydra_train.py \
--config-dir /path/to/fairseq-py/examples/hubert/config/finetune \
--config-name base_10h \
task.data=/path/to/data task.label_dir=/path/to/trans \
model.w2v_path=/path/to/checkpoint4、解码HuBERT模型
假设test.tsv和test.ltr是待解码的分割的波形列表和文本,保存在/path/to/data,微调后的模型保存在/path/to/checkpoint。我们支持三种解码模式:
- Viterbi解码:无语言模型的贪婪解码
- KenLM解码:使用arpa格式的KenLM n-gram语言模型进行解码
- Fairseq-LM解码:使用Fairseq神经语言模型进行解码
5、Viterbi解码
task.normalize需要与微调时使用的值一致。解码结果将保存在/path/to/experiment/directory/decode/viterbi/test。
$ python examples/speech_recognition/new/infer.py \
--config-dir /path/to/fairseq-py/examples/hubert/config/decode \
--config-name infer_viterbi \
task.data=/path/to/data \
task.normalize=[true|false] \
decoding.exp_dir=/path/to/experiment/directory \
common_eval.path=/path/to/checkpoint \
dataset.gen_subset=test6、KenLM / Fairseq-LM解码
假设发音词典和n-gram语言模型分别保存在/path/to/lexicon和/path/to/arpa。解码结果将保存在/path/to/experiment/directory/decode/kenlm/test。
$ python examples/speech_recognition/new/infer.py \
--config-dir /path/to/fairseq-py/examples/hubert/config/decode \
--config-name infer_kenlm \
task.data=/path/to/data \
task.normalize=[true|false] \
decoding.exp_dir=/path/to/experiment/directory \
common_eval.path=/path/to/checkpoint \
dataset.gen_subset=test \
decoding.decoder.lexicon=/path/to/lexicon \
decoding.decoder.lmpath=/path/to/arpa上述命令使用默认的解码超参数,这些参数可以在examples/speech_recognition/hydra/decoder.py中找到。这些参数可以从命令行进行配置。例如,要使用大小为500的beam进行搜索,可以在上述命令后添加decoding.decoder.beam=500。重要参数包括:
decoding.decoder.beamdecoding.decoder.beamthresholddecoding.decoder.lmweightdecoding.decoder.wordscoredecoding.decoder.silweight
要使用Fairseq LM进行解码,请使用--config-name infer_fsqlm,并相应地更改词典和LM的路径。
摘要
自监督语音表示学习面临三个独特的问题:(1)每个输入话语中存在多个声音单元;(2)预训练阶段没有输入声音单元的词典;(3)声音单元具有可变长度,且没有明确的分段。为了解决这些问题,我们提出了隐藏单元BERT(HuBERT)方法,用于自监督语音表示学习。该方法利用离线聚类步骤为BERT类预测损失提供对齐的目标标签。我们方法的一个关键要素是仅对掩码区域应用预测损失,这迫使模型从连续输入中学习结合声学和语言模型的表示。HuBERT主要依赖于无监督聚类步骤的一致性,而不是分配的聚类标签的内在质量。从100个聚类的简单k-means教师模型开始,通过两次聚类迭代,HuBERT模型在Librispeech(960小时)和Libri-light(60,000小时)基准测试中,在10分钟、1小时、10小时、100小时和960小时的微调子集上,与最先进的wav2vec 2.0性能相当或有所提升。使用10亿参数模型,HuBERT在更具挑战性的dev-other和test-other评估子集上,相对WER分别减少了19%和13%。
关键词
自监督学习,BERT
I 引言
许多研究项目的目标是通过听力和互动来学习语音和音频表示,类似于婴儿学习他们的第一语言。高保真语音表示包括口语内容的解耦方面以及非词汇信息,例如说话者身份、情感、犹豫、中断等。此外,要达到完整的情境理解,还需要对与语音信号交织和重叠的结构化噪声进行建模,例如笑声、咳嗽、咂嘴、背景车辆引擎声、鸟鸣或食物嘶嘶声。
对这种高保真表示的需求推动了语音和音频自监督学习的研究,其中设计的前置任务的学习过程的目标来自输入信号本身。自监督语音表示学习的前置任务示例包括区分时间上接近的特征与远距离特征[1, 2, 3]、音频特征的下一步预测[4]、给定未掩码上下文的音频特征掩码预测[5, 6]。此外,自监督学习方法在训练过程中不依赖任何语言资源,允许它们学习通用表示,因为标签、注释和仅文本材料忽略了输入信号中的丰富信息。
在没有依赖大量标注数据的情况下学习语音表示对于工业应用和覆盖新语言和领域的产品至关重要。当前快速发展的AI行业中,收集覆盖每个场景的大规模标注数据集所需的时间是真正的瓶颈,而上市时间对产品成功起着关键作用。构建涵盖仅口语方言和语言的更具包容性的应用程序是减少对语言资源依赖的另一个重要好处。鉴于这些语言和方言的非标准拼写规则,许多语言和方言几乎没有或根本没有资源。
伪标签(PL),也称为自训练,属于半监督学习技术家族,自20世纪90年代中期以来一直是利用未标注语音和音频的主导方法[7, 8, 9, 10]。PL从一些监督数据开始,训练一个特定下游任务的“教师”模型。然后使用教师模型为未标注数据生成伪标签。接下来,使用结合了监督数据和教师标注数据的训练学生模型,可以使用标准交叉熵[9]损失或对比损失[11]来处理教师生成标签中的噪声。伪标签过程可以重复多次,以迭代改进教师标签质量[12]。
尽管伪标签技术取得了巨大成功,但自监督表示具有两个独特优势:(1)伪标签方法迫使学生模型仅仅模仿教师模型,而教师模型的监督数据规模和提供的注释质量有限。另一方面,自监督前置任务迫使模型通过将更多信息压缩到学习到的潜在表示中来表示整个输入信号。(2)在伪标签中,教师模型的监督数据迫使整个学习过程针对单一的下游任务。相反,自监督特征在多种下游应用中表现出更好的泛化能力。
计算机视觉(CV)[13, 14, 15]和自然语言处理(NLP)[16, 17, 18]应用中的自监督学习取得了令人印象深刻的成功。学习离散输入序列的表示,例如在自然语言处理(NLP)应用中,使用掩码预测[19, 20]或输入序列的部分混淆自回归生成[18, 21]。对于连续输入,例如在计算机视觉(CV)应用中,表示通常通过实例分类学习,其中每个图像及其增强被视为一个单一的输出类,以拉近[14, 15]或与其他负样本对比[22]。
语音信号与文本和图像不同,它们是连续值序列。语音识别领域的自监督学习面临来自CV和NLP的独特挑战。首先,每个输入话语中存在多个声音,打破了许多CV预训练方法中使用的实例分类假设。其次,在预训练期间,没有可用的离散声音单元词典,如NLP应用中使用的单词或词片段,这阻碍了预测损失的使用。最后,声音单元之间的边界未知,这使得掩码预测预训练变得复杂。
在本文中,我们介绍了隐藏单元BERT(HuBERT),它受益于离线聚类步骤,为BERT类预训练生成噪声标签。具体来说,BERT模型消耗掩码的连续语音特征,以预测预先确定的聚类分配。预测损失仅应用于掩码区域,迫使模型学习未掩码输入的良好高级表示,以正确推断掩码输入的目标。直观地说,HuBERT模型被迫从连续输入中学习声学和语言模型。首先,模型需要将未掩码输入建模为有意义的连续潜在表示,这对应于经典的声学建模问题。其次,为了减少预测误差,模型需要捕捉学习到的表示之间的长程时间关系。推动这项工作的关键见解是目标一致性的重要性,而不仅仅是它们的正确性,这使得模型能够专注于建模输入数据的顺序结构。我们的方法从自监督视觉学习的DeepCluster方法中汲取灵感[23];然而,HuBERT受益于语音序列上的掩码预测损失,以表示其顺序结构。
当HuBERT模型在标准的Librispeech 960小时[24]或Libri-Light 60k小时[25]上进行预训练时,它在所有10分钟、1小时、10小时、100小时和960小时的微调子集上,与最先进的wav2vec 2.0[6]性能相当或有所提升。我们展示了使用HuBERT预训练的三种模型规模的系统结果:Base(90M参数)、Large(300M)和X-Large(1B)。X-Large模型在Libri-Light 60k小时上预训练时,在dev-other和test-other评估子集上,相对于Large模型,相对WER分别提高了19%和13%。
II 方法
A. 学习HuBERT的隐藏单元
在半监督学习中,基于文本和语音对的声学模型通过强制对齐为每个帧提供伪音素标签。相反,自监督表示学习设置仅访问语音数据。然而,简单的离散潜在变量模型,如k-means和高斯混合模型(GMMs),推断出的隐藏单元与底层声学单元表现出非平凡的相关性[26](见表V)。更高级的系统可以使用更好的图形模型[27, 28]或使用更强大的神经网络模型参数化分布[29, 30, 31, 32, 33],以实现更好的声学单元发现性能。

图1:HuBERT方法预测由一次或多次k均值聚类迭代生成的掩蔽帧(图中的y2、y3、y4)的隐藏聚类分配。

B. 通过掩码预测进行表示学习

在另一个极端,当α=1时,损失仅在掩码时间步上计算,模型必须从上下文中预测未见帧的目标,类似于语言建模。它迫使模型学习未掩码段的声学表示和语音数据的长程时间结构。我们假设α=1的设置对聚类目标的质量更具鲁棒性,这在我们的实验中得到了验证(见表V)。
C. 使用聚类集成进行学习

此外,集成之所以有趣,是因为它可以与乘积量化(PQ)[39]结合使用,其中特征空间被划分为多个子空间,每个子空间分别量化。PQ允许对高维特征和异构特征进行有效的欧几里得距离量化,例如k-means,其尺度在子空间之间显著不同。在这种情况下,目标空间的理论大小是所有码本大小的乘积。
D. 聚类分配的迭代细化
除了使用聚类集成外,另一个改进表示的方向是在整个学习过程中细化聚类分配。由于我们期望预训练模型提供的表示比原始声学特征(如MFCC)更好,我们可以通过在学习的潜在表示上训练离散潜在模型来创建新的聚类。然后,学习过程继续使用新发现的单元。
E. 实现
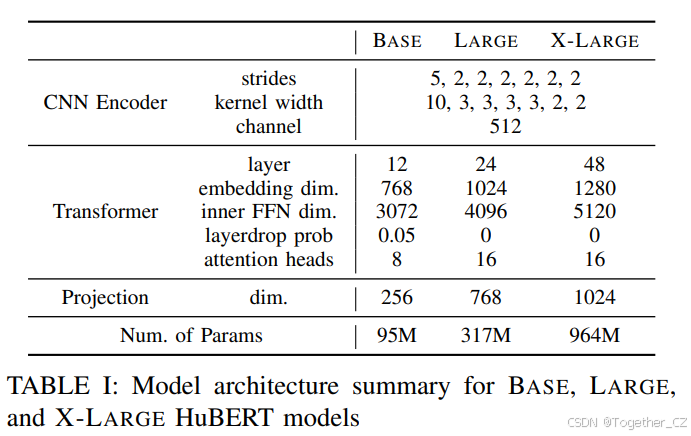
我们的预训练模型遵循wav2vec 2.0架构[6],包括卷积波形编码器、BERT编码器[19]、投影层和码嵌入层。我们考虑了HuBERT的三种不同配置:Base、Large和X-Large。前两种配置与wav2vec 2.0 Base和Large的架构密切相关。X-Large架构将模型大小扩展到约10亿参数,类似于[40]中的Conformer XXL模型。波形编码器对于所有三种配置都是相同的,由七个512通道层组成,步幅为[5, 2, 2, 2, 2, 2],核宽度为[10, 3, 3, 3, 3, 2, 2]。BERT编码器由许多相同的transformer块组成,其参数与随后的投影层参数一起在表I中指定。

在HuBERT预训练之后,我们使用连接主义时序分类(CTC)[41]损失对整个模型权重进行ASR微调,除了卷积音频编码器保持冻结。投影层被移除并替换为随机初始化的softmax层。CTC目标词汇包括26个英文字母、一个空格标记、一个撇号和一个特殊的CTC空白符号。
III 相关工作
我们根据训练目标将最近的自监督语音表示学习研究进行分组讨论。最早的工作通过假设语音的生成模型来学习表示,其中潜在变量假设捕获相关的音素信息。这些模型的训练相当于似然最大化。不同的潜在结构已被应用于编码先验假设,例如连续[29]、离散[31, 42]或顺序[28, 30, 32, 33, 43]。
基于预测的自监督学习最近引起了越来越多的兴趣,其中模型被赋予预测未见区域内容[44, 45, 46, 47, 48, 49, 50]或对比目标未见帧与随机采样的帧[1, 2, 3, 6]的任务。一些模型结合了预测和对比损失[5, 51]。这些目标通常可以解释为互信息最大化[52]。其他目标不属于这些类别,例如[53]。
这项工作与DiscreteBERT[51]最为相关:HuBERT和DiscreteBERT都预测掩码区域的离散目标。然而,有几个关键区别。首先,HuBERT不将量化单元作为输入,而是将原始波形作为输入,以尽可能多地传递信息给transformer层,这在[6]中被证明是重要的。此外,在实验部分,我们展示了我们的模型在简单k-means目标下可以比DiscreteBERT取得更好的性能,后者使用vq-wav2vec[5]学习的单元。其次,我们还提出了许多提高教师质量的技术,而不是像DiscreteBERT那样使用单一的固定教师。
HuBERT也与wav2vec 2.0[6]相关。然而,后者采用了对比损失,需要仔细设计从何处采样负帧,一个辅助多样性损失以鼓励离散单元的使用,并需要适当的Gumbel-softmax温度退火计划。此外,它仅探索量化波形编码器输出,由于卷积编码器的容量有限,这可能不是最佳特征,正如我们在消融研究中所示(见图2)。具体来说,我们提出的方法通过将声学单元发现步骤与掩码预测表示学习阶段分离,采用了更直接的预测损失,并在不同微调规模上实现了与wav2vec 2.0相当或更好的最先进结果。
最后,迭代细化目标标签的想法类似于半监督ASR的迭代伪标签[12, 54],它利用改进的学生模型为下一轮训练生成更好的伪标签。HuBERT方法可以看作是将这种方法扩展到带有掩码预测损失的自监督设置。
IV 实验细节
A. 数据
对于无监督预训练,我们使用完整的960小时LibriSpeech音频[24]或60,000小时Libri-light音频[25],两者均来自LibriVox项目,该项目包含由互联网志愿者录制的版权免费英语有声读物。对于监督微调,我们考虑了五个不同的分区:Libri-light 10分钟、1小时、10小时分割以及LibriSpeech 100小时(train-clean-100)和960小时(train-clean-100、train-clean-360、train-other-500合并)分割。三个Libri-light分割是LibriSpeech训练分割的子集,每个分割包含train-clean-*的一半音频和train-other-500的另一半音频。
B. 无监督单元发现
为了展示所提出方法在利用低质量聚类分配方面的有效性,我们默认考虑k-means算法[55]进行声学单元发现。它是最简单的单元发现模型之一,可以被视为对每个声学单元建模各向同性高斯分布,方差相同。为了生成960小时LibriSpeech训练集上第一次HuBERT训练的标签,我们在39维MFCC特征上运行k-means聚类,该特征包括13个系数及其一阶和二阶导数。
为了为后续迭代生成更好的目标,我们在前一次迭代中预训练的HuBERT模型的中间transformer层提取的潜在特征上运行k-means聚类,聚类数为500。由于transformer输出处的特征维度远高于MFCC特征(HuBERT Base为768维),我们无法将整个960小时训练集加载到内存中。因此,我们随机采样10%的数据来拟合k-means模型。
我们使用scikit-learn[56]包中实现的MiniBatchKMeans算法进行聚类,该算法一次拟合一个小批量的样本。我们设置小批量大小为10,000帧。使用k-means++[57]和20次随机初始化以获得更好的初始化。
C. 预训练
我们在32个GPU上对960小时LibriSpeech音频进行两次迭代训练Base模型,每个GPU的最大批量大小为87.5秒音频。第一次迭代训练250k步,第二次迭代使用第一次迭代模型第6个transformer层输出的聚类标签训练400k步。训练100k步大约需要9.5小时。
接下来,我们在128和256个GPU上分别对60,000小时Libri-light音频进行一次迭代训练HuBERT Large和X-Large模型,训练400k步。由于内存限制,批量大小减少到每个GPU 56.25和22.5秒音频。我们没有从MFCC特征聚类重新开始迭代过程,而是从第二次迭代Base HuBERT的第9个transformer层提取特征进行聚类,并使用这些标签训练这两个模型。因此,这两个模型也可以被视为第三次迭代模型。
对于所有HuBERT配置,掩码跨度设置为l=10,并且p=8%的波形编码器输出帧被随机选择为掩码起始,除非另有说明。我们使用Adam[58]优化器,β=(0.9,0.98),学习率在前8%的训练步骤中线性从0上升到峰值学习率,然后线性衰减回零。Base/Large/X-Large模型的峰值学习率分别为5e-4/1.5e-3/3e-3。
D. 监督微调和解码
我们在8个GPU上对第IV-A节中描述的标注分割进行每个模型的微调。Base/Large/X-Large模型每个GPU的批量大小分别为最多200/80/40秒音频。在微调期间,卷积波形音频编码器参数保持冻结。与wav2vec 2.0一样,我们引入了一个_freeze-step_超参数来控制transformer参数冻结的微调步骤数,并且仅训练新的softmax矩阵。我们使用dev-other子集上的词错误率(WER)作为模型选择的准则,对每个模型大小和微调分割组合的峰值学习率([1e-5, 1e-4])、学习率计划(线性上升和衰减的步骤百分比)、微调步骤数、冻结步骤和波形编码器输出掩码概率进行扫描。
我们使用wav2letter++[59]束搜索解码器(在Fairseq[60]中包装)进行语言模型融合解码,该解码器优化:

E. 目标质量的度量

考虑三个度量:
-
音素纯度(Phn Pur.):

-
聚类纯度(Cls Pur.):

-
音素归一化互信息(PNMI):
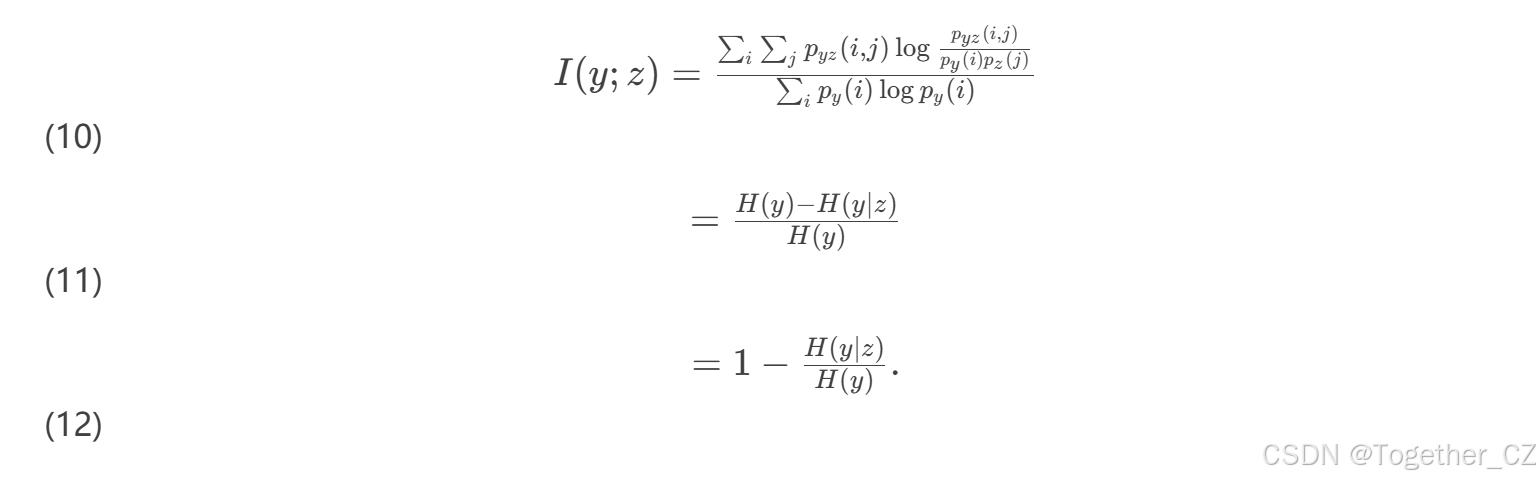
PNMI是一个信息论度量,测量在观察k-means标签z后,音素标签y的不确定性消除的百分比。较高的PNMI也表示更好的k-means聚类质量。
V 结果
A. 主要结果:低资源和高资源设置
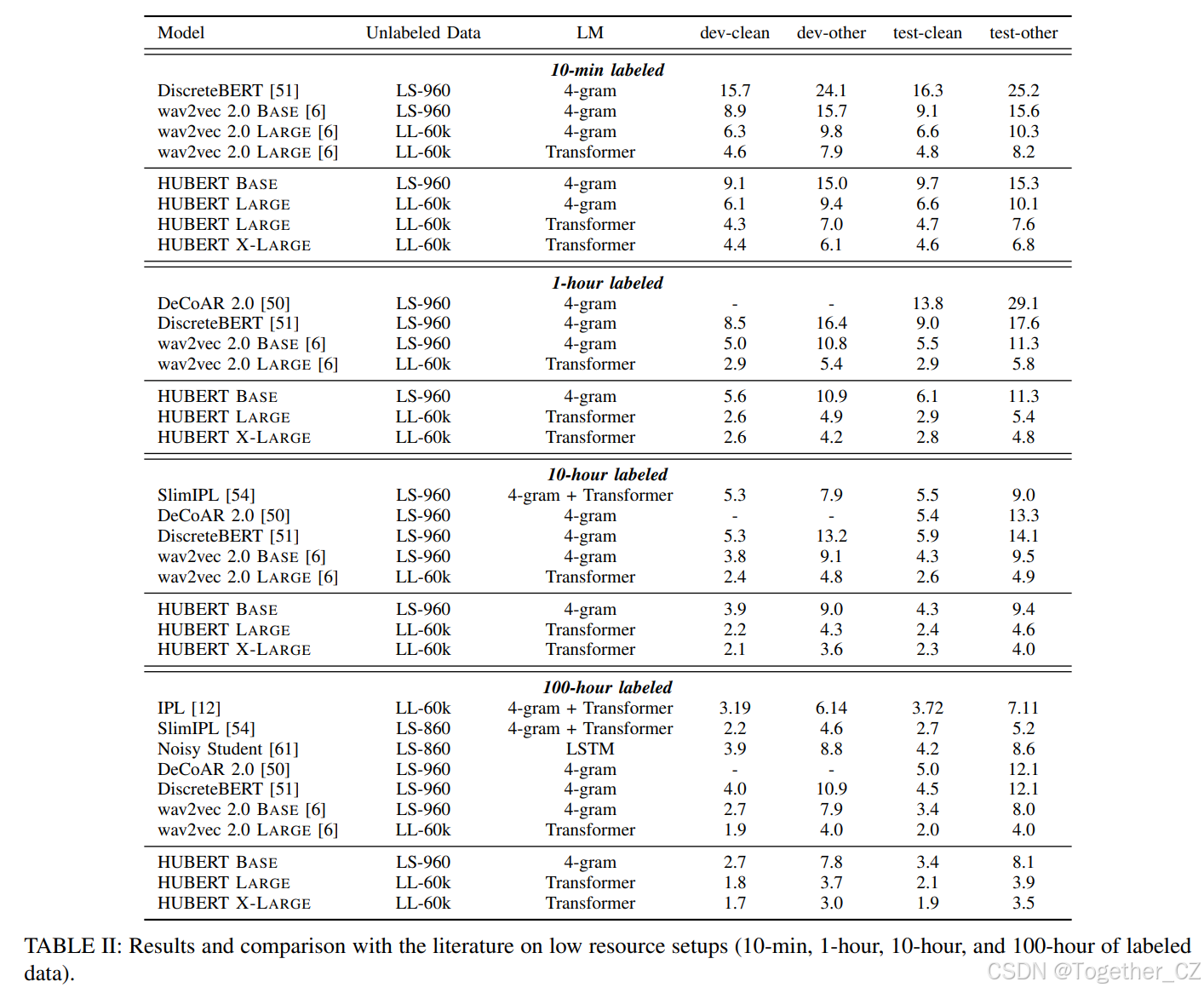
表II展示了低资源设置的结果,其中预训练模型在10分钟、1小时、10小时或100小时的标注数据上进行微调。我们与文献中的半监督(迭代伪标签(IPL)[12]、slimIPL[54]、噪声学生[61])和自监督方法(DeCoAR 2.0[50]、DiscreteBERT[51]、wav2vec 2.0[6])进行了比较。增加未标注数据量和增加模型大小可以提高性能,展示了所提出的HuBERT自监督预训练方法的可扩展性。在仅有10分钟标注数据的极低资源设置中,HuBERT Large模型在test-clean集上可以达到4.7%的WER,在test-other集上可以达到7.6%的WER,分别比最先进的wav2vec 2.0 Large模型低0.1%和0.6%的WER。通过进一步将模型大小扩展到10亿参数,HuBERT X-Large模型可以在test-clean和test-other上进一步将WER降低到4.6%和6.8%。HuBERT的优越性在具有不同标注数据量的设置中持续存在,唯一的例外是在100小时标注数据上微调时,HuBERT Large在test-clean上的WER比wav2vec 2.0 large高0.1%,HuBERT Base在test-other上的WER比wav2vec 2.0 Base高0.1%。此外,HuBERT在所有设置中都比DiscreteBERT有显著优势,尽管两者都使用几乎相同的目标——掩码预测发现的单元。显著的性能差距表明了两点。首先,使用波形作为模型输入对于避免量化过程中的信息丢失至关重要。其次,虽然vq-wav2vec[5](DiscreteBERT用于训练的单元)可能比MFCC特征的k-means聚类发现更好的单元,但所提出的迭代细化受益于不断改进的HuBERT模型,并最终学习到更好的单元。我们将在消融研究部分验证这些陈述。
我们在完整的960小时Librispeech数据上微调HuBERT模型,并与文献进行比较,结果如表III所示。使用额外未配对语音的先前研究分为:
-
自训练:首先在标注数据上训练ASR以注释未标注语音,然后结合黄金和ASR注释的文本-语音对进行监督训练。
-
预训练:首先使用未标注语音进行模型预训练,然后在标注数据上使用监督训练目标进行微调。
-
预训练 + 自训练:首先进行预训练和微调模型,然后使用它注释未标注语音,结合监督数据进行自训练。
HuBERT优于最先进的监督和自训练方法,并与文献中两个最佳预训练结果相当;两者都基于wav2vec 2.0对比学习。相比之下,它落后于结合预训练和自训练的方法。然而,正如[63]和[40]中所观察到的,我们预计HuBERT在结合自训练后可以实现可比或更好的性能,因为预训练的HuBERT模型与这些方法用于伪标签的预训练模型相当或更好。
B. 分析:K-means稳定性
为了更好地理解为什么掩码预测发现的单元有效,我们进行了一系列分析和消融研究。我们从探讨k-means聚类算法在不同数量的聚类和不同大小的训练数据下的稳定性开始。考虑两个特征:39维MFCC特征和第一次迭代HuBERT-Base模型第6个transformer层输出的768维特征。这两个特征分别用于第一次和第二次HuBERT训练的聚类分配。
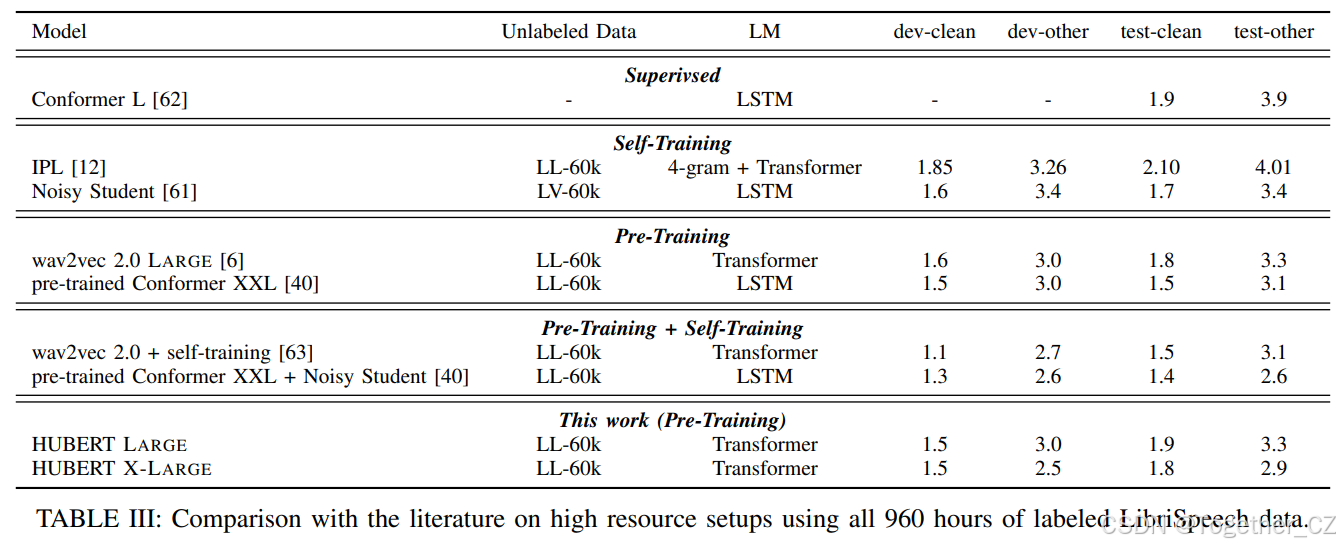
对于k-means聚类,我们考虑K={100,500}聚类,并在从LibriSpeech训练分割中采样的{1, 10, 100}小时语音上进行拟合。每个超参数和特征的组合训练10次,并在开发集(结合LibriSpeech的dev-clean和dev-other)上报告监督PNMI度量的均值和标准差,结果如表IV所示。结果表明,k-means聚类在给定不同超参数和特征的情况下是相当稳定的,标准差较小。此外,增加用于拟合k-means模型的数据量通常会提高PNMI,但增益仅为0.012,表明即使相对于特征矩阵大小,CPU内存有限,使用k-means进行单元发现也是可行的。最后,当对HuBERT特征进行聚类时,PNMI得分远高于对MFCC特征进行聚类,且在500个聚类时差距更大,表明迭代细化显著提高了聚类质量。
C. 分析:跨层和迭代的聚类质量
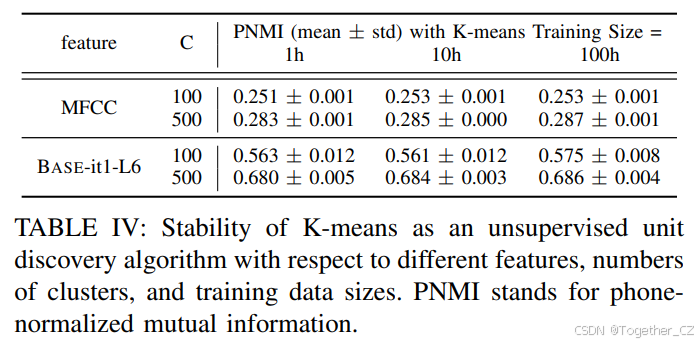
接下来,我们研究每次迭代的HuBERT模型的每个层在用于聚类生成训练目标时的表现。考虑第IV-C节中描述的两个Base HuBERT模型,分别称为Base-it1和Base-it2。有26个特征,分别代表12个transformer层加上第一个transformer层的输入(表示为“Layer 0”)。对于每个特征,我们在从LibriSpeech训练数据中随机采样的100小时子集上拟合三个k-means模型(K={100,500,1000}聚类)。
教师质量在聚类纯度、音素纯度和音素归一化互信息(PNMI)上的度量如图2所示。作为基线,MFCC在K=100时达到(聚类纯度,音素纯度,PNMI)=(0.099, 0.335, 0.255),在K=500时达到(0.031, 0.356, 0.287)。
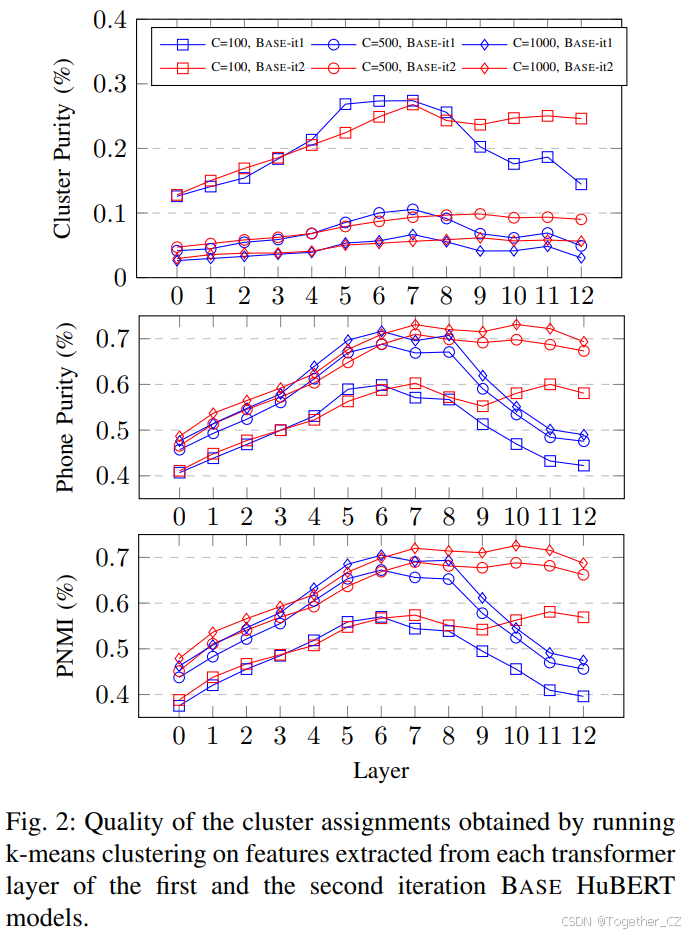
图2:在第一轮和第二轮BASE HuBERT模型的每个Transformer层中提取特征上运行k均值聚类所获得的聚类分配的质量。
Base-it1和Base-it2特征在所有三个度量上都显著优于MFCC,且具有相同数量的聚类。另一方面,最好的Base-it2特征在音素纯度和PNMI上优于最好的Base-it1,但在聚类纯度上略差。最后,我们观察到Base-it1和Base-it2的不同层趋势:虽然Base-it2模型特征通常随着层的增加而改进,但Base-it1在第6层附近的中层特征最好。有趣的是,Base-it1的最后几层质量显著下降,可能是因为它是在质量较差的目标分配上训练的,因此最后几层学会了模仿其不良标签行为。
D. 消融:预测掩码帧的重要性
我们在以下部分中进行了一系列消融研究,以了解预训练目标、聚类质量和超参数如何影响性能。消融研究的模型预训练100k步,并在10小时libri-light分割上使用固定超参数进行微调。如果未另行说明,则使用C=100的MFCC基k-means单元。我们使用固定解码超参数的n-gram语言模型报告dev-other集上的WER。
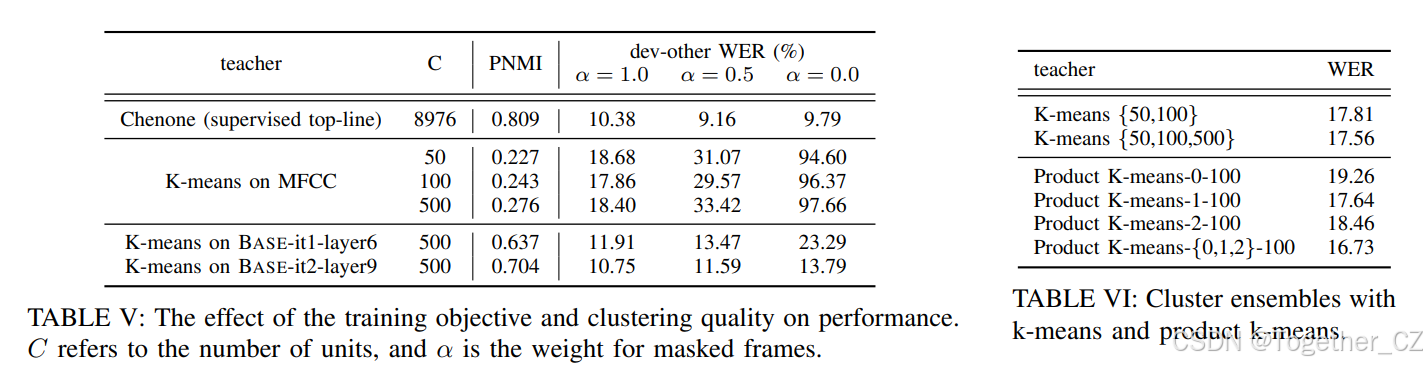
为了理解我们提出的仅预测掩码帧的重要性,我们比较了三种条件:1)预测掩码帧,2)预测所有帧,3)预测未掩码帧,分别通过将α设置为1.0、0.5和0.0来模拟。我们比较了从聚类MFCC教师学习的三个k-means模型(50、100、500个聚类),一个从聚类HuBERT-Base-it1第6个transformer层特征学习的模型,以及从基于字符的HMM模型(chenone)[64]强制对齐获得的监督标签。
表V中的结果表明,当从不良聚类分配中学习时,仅从掩码区域计算损失可以实现最佳性能,而包含未掩码损失会导致WER显著增加。然而,随着聚类质量的提高,模型在计算未掩码帧上的损失时会受到较小的影响(Base-it1-layer6),甚至可以在chenone的情况下实现更好的性能。
E. 消融:聚类集成的效果
为了理解结合多个k-means模型生成目标的效果,我们考虑了两种设置。第一种设置具有表V中列出的不同数量的聚类k-means模型,表示为KM-{50,100,500}。第二种设置具有在拼接的MFCC特征上训练的k-means模型,窗口大小为三;因此,每个输入特征表示为117维向量。在这种情况下,我们对拼接的特征应用乘积量化,其中维度被划分为零阶、一阶和二阶导数的系数,每个39维子空间量化为100个条目的码本。我们将这些码本表示为Product k-means-{0,1,2}-100。通过比较表V和表VI的结果,可以清楚地看出,使用集成比单个k-means聚类可以实现更好的性能。
F. 消融:超参数的影响
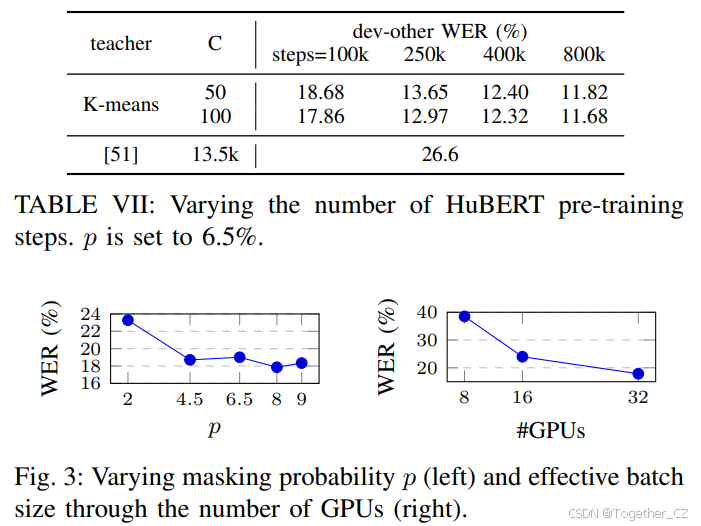
图3和表VII研究了超参数如何影响HuBERT预训练。结果表明:(1)选择为掩码起始的帧比例在p=8%时最优;(2)增加批量大小可以显著提高性能;(3)训练时间更长对C={50, 100}的k-means模型始终有帮助,最佳模型达到11.68%的WER。这些发现与BERT类模型[20]的结果一致。此外,我们在表VII中包含了与DiscreteBERT[51]的可比结果,后者将相同的MFCC特征量化为13.5k个单元,既作为BERT模型的输出也作为输入。除了使用连续语音输入而不是离散单元外,我们假设HuBERT显著优于DiscreteBERT,因为其较少的k-means聚类(100或500)有助于捕捉广泛的音素概念,而不会深入到说话者间/内的变化。
VI 结论
本文介绍了HuBERT,一种依赖于预测连续输入掩码段的k-means聚类分配的语音表示学习方法。在Librispeech 960小时和60,000小时Libri-light预训练设置上,HuBERT在所有10分钟、1小时、10小时、100小时和960小时的微调子集上与最先进的系统相当或有所提升。此外,通过使用前一次迭代的潜在表示进行k-means聚类分配的迭代细化,学习到的表示质量显著提高。最后,HuBERT很好地扩展到10亿参数的transformer模型,在test-other子集上相对WER减少了13%。对于未来的工作,我们计划改进HuBERT训练过程,使其包含单一阶段。此外,鉴于其表示的高质量,我们将考虑使用HuBERT预训练表示进行多个下游识别和生成任务,而不仅仅是ASR。



















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











