






这篇文章介绍了ELECTRA,一种新的预训练语言模型方法,旨在提高计算效率并提升下游任务的性能。以下是文章的主要内容总结:
1. 背景与问题
-
现有的预训练方法(如BERT)使用掩码语言建模(MLM),即掩码部分输入标记并训练模型预测这些标记。虽然有效,但MLM只从15%的标记中学习,计算效率较低。
-
文章提出了一种更高效的预训练任务:替换标记检测。
2. ELECTRA的核心思想
-
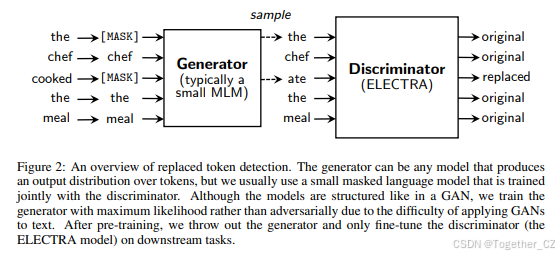
替换标记检测:不掩码输入,而是用生成器生成的合理替代标记替换部分输入标记,然后训练判别器区分哪些标记是原始标记,哪些是替换标记。
-
生成器与判别器:生成器是一个小型MLM模型,生成替代标记;判别器是主模型,负责区分原始标记和替换标记。
-
联合训练:生成器和判别器联合训练,生成器通过最大似然训练,判别器通过二元分类任务训练。
3. 优势
-
计算效率更高:ELECTRA从所有输入标记中学习,而不仅仅是掩码的部分,因此比MLM更高效。
-
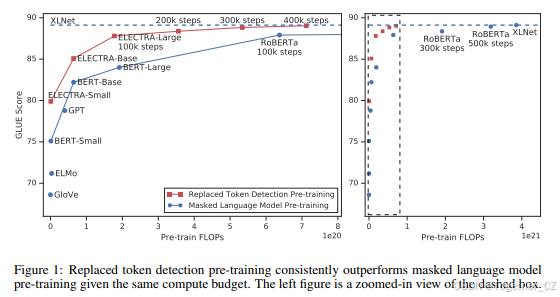
性能更好:在相同的计算资源下,ELECTRA在下游任务(如GLUE和SQuAD)上的表现优于BERT、GPT、RoBERTa和XLNet。
-
适用于小型模型:ELECTRA-Small在单个GPU上训练4天,性能优于GPT和同等大小的BERT模型。
4. 实验与结果
-
小型模型:ELECTRA-Small在GLUE上比BERT-Small高出5分,甚至优于更大的GPT模型。
-
大型模型:ELECTRA-Large在使用1/4计算资源的情况下,性能与RoBERTa和XLNet相当,并在相同计算资源下优于它们。
-
效率分析:ELECTRA的增益主要来自于从所有标记中学习,而不是仅从掩码标记中学习。
5. 相关工作
-
ELECTRA与自监督学习、生成对抗网络(GAN)和对比学习方法相关,但其生成器通过最大似然训练,而不是对抗性训练。
6. 结论
-
ELECTRA提出了一种更高效的预训练任务,通过替换标记检测显著提高了计算效率和下游任务性能。该方法特别适合资源有限的研究和应用场景。
7. 附录
-
提供了预训练和微调的详细超参数设置、GLUE任务的详细描述、FLOPs的计算方法以及对抗性训练的尝试。
ELECTRA通过替换标记检测任务,提供了一种更高效且性能优越的预训练方法,特别适合在计算资源有限的情况下使用。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
掩码语言建模(MLM)预训练方法(如BERT)通过将部分标记替换为[MASK]来破坏输入,然后训练模型以重建原始标记。虽然这些方法在下游NLP任务中表现良好,但它们通常需要大量的计算资源才能有效。作为替代方案,我们提出了一种更高效的预训练任务,称为替换标记检测。与掩码输入不同,我们的方法通过从小型生成器网络中采样合理的替代标记来破坏输入。然后,我们训练一个判别模型来预测每个标记是否被生成器样本替换,而不是训练模型预测被破坏标记的原始身份。大量实验表明,这种新的预训练任务比MLM更高效,因为该任务定义在所有输入标记上,而不仅仅是被掩码的一小部分。因此,在相同的模型大小、数据和计算资源下,我们的方法学习的上下文表示显著优于BERT。对于小型模型,这种优势尤为明显;例如,我们在一个GPU上训练了4天的模型,在GLUE自然语言理解基准上优于GPT(GPT使用了30倍的计算资源)。我们的方法在大规模场景下也表现良好,在使用不到1/4的计算资源的情况下,性能与RoBERTa和XLNet相当,并在使用相同计算资源时优于它们。
1 引言
当前最先进的语言表示学习方法可以被视为学习去噪自编码器(Vincent et al., 2008)。它们从未标记的输入序列中选择一小部分(通常为15%),掩码这些标记的身份(如BERT;Devlin et al., 2019)或对这些标记的注意力(如XLNet;Yang et al., 2019),然后训练网络以恢复原始输入。尽管由于学习双向表示,这些掩码语言建模(MLM)方法比传统的语言模型预训练更有效,但它们带来了巨大的计算成本,因为网络仅从每个示例的15%的标记中学习。
作为替代方案,我们提出了替换标记检测,这是一种预训练任务,模型在其中学习区分真实输入标记与合理但合成的替代标记。与掩码不同,我们的方法通过从提议分布中采样替换部分标记来破坏输入,该提议分布通常是一个小型掩码语言模型的输出。这种破坏过程解决了BERT中的一个不匹配问题(尽管XLNet中没有),即网络在预训练期间看到人工的[MASK]标记,但在下游任务微调时却看不到。然后,我们将网络预训练为一个判别器,预测每个标记是原始标记还是替换标记。相比之下,MLM将网络训练为生成器,预测被破坏标记的原始身份。我们的判别任务的一个关键优势是,模型从所有输入标记中学习,而不仅仅是从被掩码的一小部分中学习,从而使其计算效率更高。尽管我们的方法让人联想到训练GAN的判别器,但我们的方法并不是对抗性的,因为生成器是通过最大似然训练的,这是由于将GAN应用于文本的困难(Caccia et al., 2018)。
我们将我们的方法称为ELECTRA,意为“高效学习准确分类标记替换的编码器”。与之前的工作一样,我们将其应用于预训练Transformer文本编码器(Vaswani et al., 2017),这些编码器可以在下游任务上进行微调。通过一系列消融实验,我们表明,从所有输入位置学习使得ELECTRA的训练速度比BERT快得多。我们还表明,ELECTRA在完全训练后在下游任务上实现了更高的准确性。
当前大多数预训练方法需要大量的计算资源才能有效,这引发了对其成本和可访问性的担忧。由于更多的计算资源几乎总是会带来更好的下游准确性,我们认为预训练方法的一个重要考虑因素应该是计算效率以及绝对的下游性能。从这个角度来看,我们训练了不同大小的ELECTRA模型,并评估了它们的下游性能与计算需求的关系。特别是,我们在GLUE自然语言理解基准(Wang et al., 2019)和SQuAD问答基准(Rajpurkar et al., 2016)上进行了实验。在相同的模型大小、数据和计算资源下,ELECTRA显著优于基于MLM的方法,如BERT和XLNet(见图1)。例如,我们构建了一个ELECTRA-Small模型,可以在1个GPU上训练4天。ELECTRA-Small在GLUE上比同等大小的BERT模型高出5分,甚至优于更大的GPT模型(Radford et al., 2018)。我们的方法在大规模场景下也表现良好,我们训练的ELECTRA-Large模型在性能上与RoBERTa(Liu et al., 2019)和XLNet(Yang et al., 2019)相当,尽管参数更少且使用了1/4的计算资源进行训练。进一步训练ELECTRA-Large得到了一个更强大的模型,在GLUE上优于ALBERT(Lan et al., 2019),并在SQuAD 2.0上创下了新的最先进水平。总的来说,我们的结果表明,区分真实数据与具有挑战性的负样本的判别任务比现有的生成方法在语言表示学习中更具计算效率和参数效率。
2 方法
我们首先描述了替换标记检测预训练任务;图2提供了概述。我们在第3.2节中提出并评估了该方法的几种建模改进。
替换标记检测
在替换标记检测中,我们通过从生成器网络中采样替换部分标记来破坏输入。生成器可以是任何生成标记输出分布的模型,但我们通常使用一个小型的掩码语言模型,该模型与判别器联合训练。尽管模型的结构类似于GAN,但由于将GAN应用于文本的困难,我们通过最大似然训练生成器,而不是对抗性训练。预训练后,我们丢弃生成器,仅在下游任务上微调判别器(即ELECTRA模型)。
生成器与判别器的联合训练
我们通过联合训练生成器和判别器来优化以下损失函数:

3 实验
实验设置
我们在通用语言理解评估(GLUE)基准(Wang et al., 2019)和斯坦福问答(SQuAD)数据集(Rajpurkar et al., 2016)上进行了评估。GLUE包含多种任务,涵盖文本蕴含(RTE和MNLI)、问答蕴含(QNLI)、释义(MRPC)、问题释义(QQP)、文本相似性(STS)、情感(SST)和语言可接受性(CoLA)。有关GLUE任务的更多详细信息,请参见附录C。我们的评估指标是STS的Spearman相关性、CoLA的Matthews相关性以及其他GLUE任务的准确性;我们通常报告所有任务的平均分数。对于SQuAD,我们评估了1.1版本(模型选择回答问题的文本跨度)和2.0版本(某些问题无法通过文章回答)。我们使用标准的评估指标:精确匹配(EM)和F1分数。对于大多数实验,我们使用与BERT相同的数据进行预训练,该数据包括来自Wikipedia和BooksCorpus的33亿个标记(Devlin et al., 2019)。然而,对于我们的Large模型,我们使用了XLNet的预训练数据(Yang et al., 2019),该数据通过包括来自ClueWeb(Callan et al., 2009)、CommonCrawl和Gigaword(Parker et al., 2011)的数据,将BERT数据集扩展到330亿个标记。所有预训练和评估都在英文数据上进行,尽管我们认为将我们的方法应用于多语言数据将是有趣的。
我们的模型架构和大多数超参数与BERT相同。对于GLUE的微调,我们在ELECTRA之上添加了简单的线性分类器。对于SQuAD,我们在ELECTRA之上添加了XLNet的问答模块,该模块比BERT的模块稍微复杂一些,因为它联合而不是独立地预测起始和结束位置,并为SQuAD 2.0添加了“可回答性”分类器。我们的一些评估数据集很小,这意味着微调模型的准确性可能会因随机种子而有很大差异。因此,我们报告了从同一预训练检查点进行的10次微调运行的中位数。除非另有说明,结果是在开发集上。有关进一步的训练细节和超参数值,请参见附录。
模型扩展
我们通过提出和评估模型的几种扩展来改进我们的方法。除非另有说明,这些实验使用与BERT-Base相同的模型大小和训练数据。
权重共享
我们提出通过共享生成器和判别器之间的权重来提高预训练的效率。如果生成器和判别器大小相同,则可以共享所有Transformer权重。然而,我们发现使用较小的生成器更高效,在这种情况下,我们仅共享生成器和判别器的嵌入(包括标记嵌入和位置嵌入)。在这种情况下,我们使用判别器隐藏状态大小的嵌入。生成器的“输入”和“输出”标记嵌入始终像BERT中一样绑定。
我们比较了生成器和判别器大小相同时的权重绑定策略。我们训练这些模型500k步。GLUE分数分别为:无权重绑定83.6,绑定标记嵌入84.3,绑定所有权重84.4。我们假设ELECTRA受益于绑定标记嵌入,因为掩码语言建模在学习这些表示方面特别有效:虽然判别器仅更新输入中存在的标记或由生成器采样的标记,但生成器的词汇表上的softmax密集更新所有标记嵌入。另一方面,绑定所有编码器权重几乎没有带来改进,同时带来了生成器和判别器必须大小相同的显著缺点。基于这些发现,我们在本文的进一步实验中使用绑定嵌入。
较小的生成器
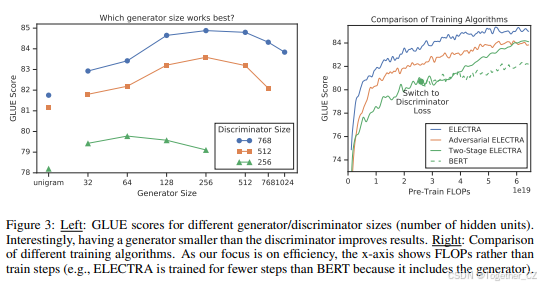
如果生成器和判别器大小相同,训练ELECTRA的每一步计算量将大约是仅使用掩码语言建模训练的两倍。我们建议使用较小的生成器来减少这一因素。具体来说,我们通过减小层大小来使模型更小,同时保持其他超参数不变。我们还探索了使用极其简单的“单字”生成器,该生成器根据训练语料库中的频率采样假标记。不同大小的生成器和判别器的GLUE分数如图3左侧所示。所有模型都训练了500k步,这使得较小的生成器在计算上处于劣势,因为它们每训练步需要的计算量较少。然而,我们发现生成器大小为判别器的1/4-1/2时,模型效果最好。我们推测,生成器太强可能会给判别器带来过于困难的任务,从而阻止其有效学习。特别是,判别器可能不得不使用其许多参数来建模生成器,而不是实际的数据分布。本文的进一步实验使用给定判别器大小的最佳生成器大小。
训练算法
最后,我们探索了ELECTRA的其他训练算法,尽管这些算法最终没有改善结果。提出的训练目标联合训练生成器和判别器。我们尝试了以下两阶段训练过程:
-
仅使用
 训练生成器n步。
训练生成器n步。 -
使用生成器的权重初始化判别器的权重。然后使用
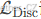 训练判别器n步,保持生成器的权重冻结。
训练判别器n步,保持生成器的权重冻结。
请注意,此过程中的权重初始化要求生成器和判别器大小相同。我们发现,如果没有权重初始化,判别器有时会完全无法学习,可能因为生成器一开始就领先判别器太多。另一方面,联合训练自然地为判别器提供了一个课程,生成器一开始较弱,但在训练过程中逐渐变强。我们还探索了像GAN一样对抗性训练生成器,使用强化学习来适应生成器的离散采样操作。有关详细信息,请参见附录F。
结果如图3右侧所示。在两阶段训练期间,下游任务性能在从生成目标切换到判别目标后显著提高,但最终没有超过联合训练。尽管仍然优于BERT,我们发现对抗性训练的表现不如最大似然训练。进一步的分析表明,这种差距是由两个问题引起的。首先,对抗性生成器在掩码语言建模方面表现较差;它在掩码语言建模上的准确率为58%,而最大似然训练的生成器为65%。我们认为,较差的准确性主要是由于在生成文本的大动作空间中,强化学习的样本效率较低。其次,对抗性训练的生成器产生了一个低熵的输出分布,其中大部分概率质量集中在单个标记上,这意味着生成器样本的多样性不足。这两个问题在之前的文本GAN研究中都有观察到(Caccia et al., 2018)。
小型模型
作为本工作的一个目标是提高预训练的效率,我们开发了一个可以在单个GPU上快速训练的小型模型。从BERT-Base的超参数开始,我们缩短了序列长度(从512到128),减少了批量大小(从256到128),减小了模型的隐藏维度大小(从768到256),并使用了较小的标记嵌入(从768到128)。为了进行公平比较,我们还使用相同的超参数训练了一个BERT-Small模型。我们训练BERT-Small 1.5M步,因此它使用的训练FLOPs与训练1M步的ELECTRA-Small相同。除了BERT,我们还比较了两种基于语言建模的资源密集型预训练方法:ELMo(Peters et al., 2018)和GPT(Radford et al., 2018)。我们还展示了与BERT-Base大小相当的ELECTRA-Base模型的结果。
结果如表1所示。有关更多结果,包括使用更多计算资源训练的更强的小型和基础模型,请参见附录D。ELECTRA-Small在其大小下表现非常出色,在使用更多计算资源和参数的其他方法中获得了更高的GLUE分数。例如,它比同等大小的BERT-Small模型高出5分,甚至优于更大的GPT模型。ELECTRA-Small几乎完全收敛,即使训练时间更短(少至6小时)的模型仍然表现良好。虽然从较大的预训练Transformer中蒸馏出的小型模型也可以获得良好的GLUE分数(Sun et al., ; Jiao et al., 2019),但这些模型首先需要花费大量计算资源来预训练较大的教师模型。结果还表明,ELECTRA在中等大小下表现出色;我们的ELECTRA-Base模型显著优于BERT-Base,甚至优于BERT-Large(GLUE得分为84.0)。我们希望ELECTRA在相对较少的计算资源下实现强大结果的能力,将使开发和应用预训练模型在NLP中更加普及。
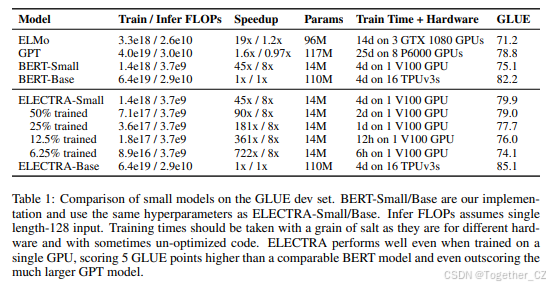
大型模型
我们训练了大型ELECTRA模型,以衡量替换标记检测预训练任务在当前最先进的预训练Transformer的大规模场景下的有效性。我们的ELECTRA-Large模型与BERT-Large大小相同,但训练时间更长。特别是,我们训练了一个400k步的模型(ELECTRA-400K;大约是RoBERTa预训练计算量的1/4)和一个1.75M步的模型(ELECTRA-1.75M;与RoBERTa的计算量相似)。我们使用批量大小2048和XLNet的预训练数据。我们注意到,尽管XLNet的数据与用于训练RoBERTa的数据相似,但比较并不完全直接。作为基线,我们使用与ELECTRA-400K相同的超参数和训练时间训练了我们自己的BERT-Large模型。
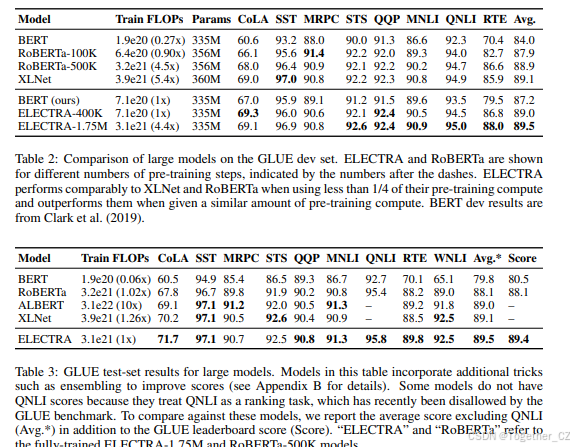
GLUE开发集上的结果如表2所示。ELECTRA-400K的性能与RoBERTa和XLNet相当。然而,训练ELECTRA-400K所需的计算量不到RoBERTa和XLNet的1/4,这表明ELECTRA的样本效率增益在大规模场景下仍然有效。更长时间的训练(ELECTRA-1.75M)产生了一个在大多数GLUE任务上优于它们的模型,同时仍然需要更少的预训练计算量。令人惊讶的是,我们的基线BERT模型得分明显低于RoBERTa-100K,这表明我们的模型可能受益于更多的超参数调整或使用RoBERTa的训练数据。ELECTRA的增益在GLUE测试集上仍然有效(见表3),尽管由于模型使用的额外技巧,这些比较不太直接(见附录B)。
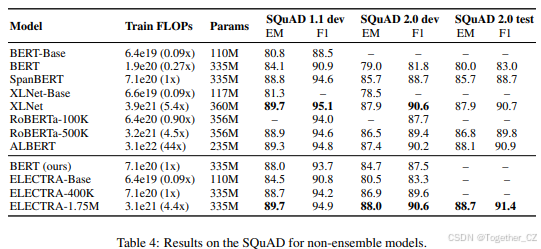
SQuAD上的结果如表4所示。与GLUE结果一致,ELECTRA在相同的计算资源下优于基于掩码语言建模的方法。例如,ELECTRA-400K优于RoBERTa-100k和我们的BERT基线,后者使用了相似的预训练计算量。ELECTRA-400K的性能也与RoBERTa-500K相当,尽管使用了不到1/4的计算量。不出所料,更长时间的训练进一步提高了结果:ELECTRA-1.75M在SQuAD 2.0基准上得分高于之前的模型。ELECTRA-Base也取得了强劲的结果,显著优于BERT-Base和XLNet-Base,甚至根据大多数指标超过了BERT-Large。ELECTRA在SQuAD 2.0上的表现通常优于1.1。也许替换标记检测(模型在其中区分真实标记与合理的假标记)特别适用于SQuAD 2.0的可回答性分类,其中模型必须区分可回答的问题与假的不可回答的问题。
效率分析
我们提出,将训练目标定义在一小部分标记上使得掩码语言建模效率低下。然而,这并不完全明显。毕竟,模型仍然接收到大量的输入标记,尽管它只预测一小部分被掩码的标记。为了更好地理解ELECTRA的增益来自何处,我们比较了一系列其他预训练目标,这些目标被设计为BERT和ELECTRA之间的“垫脚石”。
-
ELECTRA 15%:该模型与ELECTRA完全相同,只是判别器损失仅来自输入中被掩码的15%的标记。换句话说,判别器损失LDisc中的和是在m上而不是从1到n。
-
替换MLM:该目标与掩码语言建模相同,只是被掩码的标记不是替换为
[MASK],而是替换为生成器模型中的标记。该目标测试ELECTRA的增益在多大程度上来自于解决预训练期间暴露[MASK]标记但在微调期间不暴露的不匹配问题。 -
全标记MLM:与替换MLM一样,被掩码的标记替换为生成器样本。此外,模型预测输入中所有标记的身份,而不仅仅是被掩码的标记。我们发现,使用显式复制机制训练该模型可以提高结果,该机制使用sigmoid层为每个标记输出复制概率D。模型的输出分布将D权重放在输入标记上,加上1−D乘以MLM softmax的输出。该模型本质上是BERT和ELECTRA的组合。请注意,如果没有生成器替换,模型将简单地学习从词汇表中预测
[MASK]标记,并为其他标记复制输入。
结果如表5所示。首先,我们发现ELECTRA极大地受益于在所有输入标记上定义的损失,而不仅仅是一小部分:ELECTRA 15%的表现比ELECTRA差得多。其次,我们发现BERT的性能由于[MASK]标记的预训练-微调不匹配而受到轻微损害,因为替换MLM略微优于BERT。我们注意到,BERT(包括我们的实现)已经包含了一个技巧来帮助解决预训练/微调不匹配问题:被掩码的标记10%的时间替换为随机标记,10%的时间保持不变。然而,我们的结果表明,这些简单的启发式方法不足以完全解决问题。最后,我们发现全标记MLM(生成模型在所有标记上而不是一小部分上做出预测)缩小了BERT和ELECTRA之间的大部分差距。总的来说,这些结果表明,ELECTRA的大部分改进可以归因于从所有标记中学习,而较小部分可以归因于缓解预训练-微调不匹配。
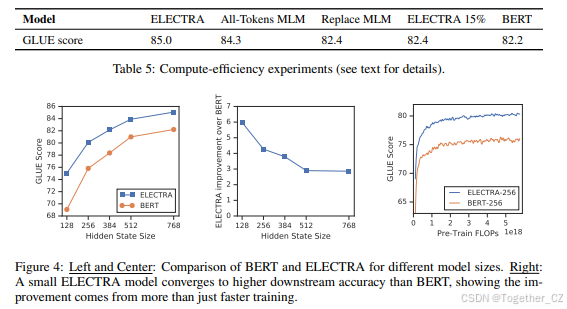
ELECTRA相对于全标记MLM的改进表明,ELECTRA的增益不仅仅来自于更快的训练。我们通过比较不同模型大小的BERT和ELECTRA进一步研究了这一点(见图4,左)。我们发现,随着模型变小,ELECTRA的增益变得更大。小型模型完全收敛(见图4,右),表明ELECTRA在完全训练后实现了比BERT更高的下游准确性。我们推测,ELECTRA比BERT更具参数效率,因为它不必在每个位置建模所有可能标记的完整分布,但我们认为需要更多的分析来完全解释ELECTRA的参数效率。
4 相关工作
NLP的自监督预训练。自监督学习已被用于学习词表示(Collobert et al., 2011; Pennington et al., 2014)和最近通过语言建模等目标学习词的上下文表示(Dai & Le, 2015; Peters et al., 2018; Howard & Ruder, 2018)。BERT(Devlin et al., 2019)在掩码语言建模任务上预训练了一个大型Transformer(Vaswani et al., 2017)。BERT有许多扩展。例如,MASS(Song et al., 2019)和UniLM(Dong et al., 2019)通过添加自回归生成训练目标扩展了BERT以用于生成任务。ERNIE(Sun et al., )和SpanBERT(Joshi et al., 2019)掩码连续的标记序列以改进跨度表示。这个想法可能与ELECTRA互补;我们认为使ELECTRA的生成器自回归并添加“替换跨度检测”任务将是有趣的。与掩码输入标记不同,XLNet(Yang et al., 2019)掩码注意力权重,使得输入序列以随机顺序自回归生成。然而,这种方法与BERT一样效率低下,因为XLNet仅以这种方式生成15%的输入标记。与ELECTRA一样,XLNet可能通过不要求[MASK]标记来缓解BERT的预训练-微调不匹配,尽管这并不完全清楚,因为XLNet在预训练期间使用两个“流”的注意力,但在微调期间只使用一个。最近,诸如TinyBERT(Jiao et al., 2019)和MobileBERT(Sun et al., )等模型表明,BERT可以有效地蒸馏为较小的模型。相比之下,我们更关注预训练速度而不是推理速度,因此我们从零开始训练ELECTRA-Small。
生成对抗网络:GANs(Goodfellow et al., 2014)在生成高质量合成数据方面非常有效。Radford et al. (2016) 提出在下游任务中使用GAN的判别器,这与我们的方法类似。GANs已应用于文本数据(Yu et al., 2017; Zhang et al., 2017),尽管最先进的方法仍然落后于标准的最大似然训练(Caccia et al., 2018; Tevet et al., 2018)。尽管我们没有使用对抗性学习,但我们的生成器特别让人联想到MaskGAN(Fedus et al., 2018),它训练生成器填充从输入中删除的标记。
对比学习:广义上,对比学习方法将观察到的数据点与虚构的负样本区分开来。它们已应用于许多模态,包括文本(Smith & Eisner, 2005)、图像(Chopra et al., 2005)和视频(Wang & Gupta, 2015; Sermanet et al., 2017)数据。常见的方法学习嵌入空间,其中相关的数据点相似(Saunshi et al., 2019)或模型将真实数据点排在负样本之上(Collobert et al., 2011; Bordes et al., 2013)。ELECTRA特别与噪声对比估计(NCE)(Gutmann & Hyvarinen, 2010)相关,它也训练一个二元分类器来区分真实和假数据点。
Word2Vec(Mikolov et al., 2013)是最早的NLP预训练方法之一,它使用对比学习。事实上,ELECTRA可以被视为带有负采样的连续词袋(CBOW)的大规模扩展版本。CBOW还根据周围上下文预测输入标记,负采样将学习任务重新表述为关于输入标记是否来自数据或提议分布的二元分类任务。然而,CBOW使用词袋向量编码器而不是Transformer,并使用从单字标记频率派生的简单提议分布,而不是学习的生成器。
5 结论
我们提出了替换标记检测,这是一种新的自监督任务,用于语言表示学习。关键思想是训练一个文本编码器,以区分输入标记与由小型生成器网络生成的高质量负样本。与掩码语言建模相比,我们的预训练目标更具计算效率,并在下游任务上表现更好。即使使用相对较少的计算资源,它也能很好地工作,我们希望这将使开发和应用预训练文本编码器对计算资源较少的研究人员和从业者更加普及。我们还希望未来关于NLP预训练的研究不仅考虑绝对性能,还考虑效率,并像我们一样在报告评估指标的同时报告计算使用量和参数数量。
附录A:预训练细节
以下细节适用于我们的ELECTRA模型和BERT基线。我们主要使用与BERT相同的超参数。我们将判别器目标在损失中的权重λ设置为50。我们使用动态标记掩码,掩码位置在训练过程中动态决定,而不是在预处理时决定。此外,我们没有使用原始BERT论文中提出的下一句预测目标,因为最近的研究表明它不会提高分数(Yang et al., 2019; Liu et al., 2019)。对于我们的ELECTRA-Large模型,我们使用了更高的掩码比例(25%而不是15%),因为我们注意到生成器在15%掩码时达到了高准确率,导致替换的标记非常少。我们为Base和Small模型搜索了最佳学习率,范围在[1e-4, 2e-4, 3e-4, 5e-4]之间,并在早期实验中从[1, 10, 20, 50, 100]中选择了λ。除此之外,我们没有进行超参数调优,除了第3.2节中的实验。完整的超参数集列在表6中。
附录B:微调细节
对于Large模型,我们主要使用了Clark et al. (2019)的超参数。然而,在注意到RoBERTa(Liu et al., 2019)使用了更多的训练轮数(最多10轮而不是3轮)后,我们为每个任务搜索了最佳训练轮数,范围在[10, 3]之间。对于SQuAD,我们将训练轮数减少到2,以与BERT和RoBERTa保持一致。对于Base模型,我们搜索了学习率,范围在[3e-5, 5e-5, 1e-4, 1.5e-4]之间,以及分层学习率衰减,范围在[0.9, 0.8, 0.7]之间,但除此之外使用了与Large模型相同的超参数。我们发现小型模型受益于更大的学习率,并搜索了最佳学习率,范围在[1e-4, 2e-4, 3e-4, 5e-3]之间。除了训练轮数外,我们为所有任务使用了相同的超参数。相比之下,之前关于GLUE的研究,如BERT、XLNet和RoBERTa,分别搜索了每个任务的最佳超参数。我们预计,如果我们进行相同类型的额外超参数搜索,我们的结果会略有改善。完整的超参数集列在表7中。
遵循BERT的做法,我们没有在开发集结果中显示WNLI GLUE任务的结果,因为使用标准的微调分类器方法很难击败多数分类器。对于GLUE测试集结果,我们应用了许多GLUE排行榜提交中使用的标准技巧,包括RoBERTa(Liu et al., 2019)、XLNet(Yang et al., 2019)和ALBERT(Lan et al., 2019)。具体来说:
-
对于RTE和STS,我们使用中间任务训练(Phang et al., 2018),从经过MNLI微调的ELECTRA检查点开始。对于RTE,我们发现将其与较低的学习率2e-5结合使用是有帮助的。
-
对于WNLI,我们遵循Liu et al. (2019)中描述的技巧,使用规则提取代词的候选先行词,并训练模型为正确的先行词打分。然而,与Liu et al. (2019)不同,评分函数不是基于MLM概率。相反,我们微调ELECTRA的判别器,使其在正确的先行词替换代词时为正确先行词的标记分配高分。例如,如果Winograd模式是“奖杯无法放入行李箱,因为它太大了”,我们训练判别器,使其在“奖杯无法放入行李箱,因为奖杯太大了”中为“奖杯”分配高分,而在“奖杯无法放入行李箱,因为行李箱太大了”中为“行李箱”分配低分。
-
对于每个任务,我们集成了从同一预训练检查点初始化的30个不同随机种子微调的最佳10个模型。
虽然这些技巧确实提高了分数,但它们使得进行清晰的科学比较更加困难,因为它们需要额外的工作来实现,需要大量的计算资源,并且使结果不那么直接可比。
附录C:GLUE任务详情
我们提供了GLUE基准任务的进一步详细信息:
-
CoLA:语言可接受性语料库(Warstadt et al., 2018)。任务是确定给定句子是否合乎语法。数据集包含来自语言学理论书籍和期刊文章的8.5k个训练示例。
-
SST:斯坦福情感树库(Socher et al., 2013)。任务是确定句子的情感是积极还是消极。数据集包含来自电影评论的67k个训练示例。
-
MRPC:微软研究释义语料库(Dolan & Brockett, 2005)。任务是预测两个句子是否语义等价。数据集包含来自在线新闻来源的3.7k个训练示例。
-
STS:语义文本相似性(Cer et al., 2017)。任务是预测两个句子在1-5尺度上的语义相似性。数据集包含来自新闻标题、视频和图像字幕以及自然语言推理数据的5.8k个训练示例。
-
QQP:Quora问题对(Iyer et al., 2017)。任务是确定一对问题是否语义等价。数据集包含来自社区问答网站Quora的364k个训练示例。
-
MNLI:多体裁自然语言推理(Williams et al., 2018)。给定前提句子和假设句子,任务是预测前提是否蕴含假设、与假设矛盾或两者都不是。数据集包含来自十个不同来源的393k个训练示例。
-
QNLI:问题自然语言推理;从SQuAD构建(Rajpurkar et al., 2016)。任务是预测上下文句子是否包含问题句子的答案。数据集包含来自维基百科的108k个训练示例。
-
RTE:识别文本蕴含(Giampiccolo et al., 2007)。给定前提句子和假设句子,任务是预测前提是否蕴含假设。数据集包含来自一系列年度文本蕴含挑战的2.5k个训练示例。
附录D:GLUE的进一步结果
我们在GLUE测试集上报告了ELECTRA-Base和ELECTRA-Small的结果,如表8所示。此外,我们通过使用XLNet数据而不是wikibooks并训练更长时间(466训练步)来推动Base和Small模型的极限;这些模型在表中称为ELECTRA-Base++和ELECTRA-Small++。对于ELECTRA-Small++,我们还将序列长度增加到512;除此之外,超参数与表6中列出的相同。最后,表中包含了ELECTRA-1.75M的结果,没有使用附录B中描述的技巧。与论文中的开发集结果一致,ELECTRA-Base优于BERT-Large,而ELECTRA-Small在平均分数上优于GPT。不出所料,++模型表现更好。小型模型的分数甚至接近TinyBERT(Jiao et al., 2019)和MobileBERT(Sun et al., 2019b)。这些模型通过复杂的蒸馏过程从BERT-Base中学习。另一方面,我们的ELECTRA模型是从零开始训练的。鉴于蒸馏BERT的成功,我们相信通过蒸馏ELECTRA可以构建更强大的小型预训练模型。ELECTRA在CoLA上特别有效。在CoLA中,目标是区分语言上可接受的句子和不合语法的句子,这与ELECTRA的预训练任务(识别假标记)非常匹配,这或许解释了ELECTRA在该任务上的优势。
附录E:FLOPs计数
我们选择以浮点运算(FLOPs)来衡量计算使用量,因为它是一个与特定硬件、低级优化等无关的度量。然而,值得注意的是,在某些情况下,抽象掉硬件细节是一个缺点,因为以硬件为中心的优化可能是模型设计的关键部分,例如ALBERT(Lan et al., 2019)通过绑定权重从而减少TPU工作器之间的通信开销获得的速度提升。我们使用了TensorFlow的FLOP计数功能,并通过手动计算检查了结果。我们做了以下假设:

附录F:对抗性训练
这里我们详细介绍了尝试对抗性训练生成器而不是使用最大似然的方法。特别是,我们训练生成器G以最大化判别器损失LDisc。由于我们的判别器与GAN的判别器并不完全相同(见第2节的讨论),这种方法实际上是Adversarial Contrastive Estimation(Bose et al., 2018)的一个实例,而不是Generative Adversarial Training。由于生成器的离散采样,无法通过判别器反向传播来对抗性训练生成器(例如,像在图像上训练的GAN那样),因此我们改用强化学习。


附录G:评估ELECTRA作为掩码语言模型
本节详细介绍了一些初步实验,评估ELECTRA作为掩码语言模型的表现。使用与主论文稍有不同的符号,给定上下文c,即一个文本序列,其中一个标记x被掩码,判别器损失可以写为:

附录H:负面结果
我们简要描述了一些在初步实验中看起来没有前景的想法:
-
我们最初尝试通过策略性地掩码标记(例如,更频繁地掩码稀有标记,或训练一个模型来猜测如果标记被掩码,BERT会难以预测哪些标记)来提高BERT的效率。这比常规BERT带来了相当小的加速。
-
鉴于ELECTRA似乎受益于(在某种程度上)较弱的生成器(见第3.2节),我们探索了提高生成器输出softmax的温度或禁止生成器采样正确标记。这些都没有改善结果。
-
我们尝试添加句子级对比目标。对于这个任务,我们保留了20%的输入句子不变,而不是用生成器对其进行噪声处理。然后,我们向模型添加了一个预测头,预测整个输入是否被破坏。令人惊讶的是,这略微降低了下游任务的分数。



















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











