






PaLM相关的内容可以看这里:
《PaLM: Scaling Language Modeling with Pathways——通过Pathways扩展语言模型》
这篇文章介绍了 PaLM 2,这是 Google 开发的一种新型语言模型,相较于其前身 PaLM,PaLM 2 在多语言处理、推理能力和计算效率方面都有显著提升。以下是文章的主要内容总结:
-
模型介绍:
-
PaLM 2 是基于 Transformer 架构的语言模型,通过多种训练目标的混合进行训练。
-
该模型在英语和多语言任务中表现出色,推理能力显著增强,并且在推理速度上更加高效。
-
-
模型改进:
-
计算优化:PaLM 2 验证了计算优化的重要性,发现模型大小和数据集大小应大致按 1:1 的比例扩展。
-
数据集改进:PaLM 2 使用了更多样化的多语言数据集,涵盖数百种语言和领域(如编程语言、数学等),并减少了数据重复以降低记忆效应。
-
架构和目标改进:模型采用了多种预训练目标,结合了 UL2 的强结果,提升了语言理解能力。
-
-
模型性能:
-
PaLM 2 在多种任务上显著优于 PaLM,包括自然语言生成、翻译和推理任务。
-
模型在多语言能力、代码生成和推理能力方面表现出色,特别是在真实世界的语言能力考试中表现优异。
-
-
负责任的使用:
-
PaLM 2 引入了控制标记,可以在推理时控制毒性输出,且不影响其他能力。
-
模型在负责任的人工智能评估中表现稳定,开发者可以通过控制标记来减少有害内容的生成。
-
-
评估结果:
-
PaLM 2 在语言能力考试、分类和问答、推理、代码生成、翻译、自然语言生成等任务上进行了广泛评估,表现出色。
-
模型在多语言问答、毒性分类等任务上也有显著改进。
-
-
未来展望:
-
文章指出,进一步扩展模型参数和数据集大小,以及改进架构和目标,将继续提升语言理解和生成能力。
-
PaLM 2 是一种高效、多功能的语言模型,在多语言处理、推理和生成任务中表现出色,并且在负责任的人工智能使用方面也有显著改进。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
我们介绍了 PaLM 2,这是一个新的最先进的语言模型,具有更好的多语言和推理能力,并且比其前身 PaLM 更高效。PaLM 2 是一个基于 Transformer 的模型,使用混合目标进行训练。通过对英语和多语言语言任务以及推理任务的广泛评估,我们证明了 PaLM 2 在不同模型大小下显著提高了下游任务的质量,同时与 PaLM 相比,推理速度更快、效率更高。这种改进的效率使得模型能够更广泛地部署,同时也能更快地响应,提供更自然的交互节奏。PaLM 2 展示了强大的推理能力,特别是在 BIG-Bench 和其他推理任务上相比 PaLM 有显著提升。PaLM 2 在一系列负责任的人工智能评估中表现出稳定的性能,并且能够在推理时控制毒性,而不会增加额外的开销或影响其他能力。总体而言,PaLM 2 在多样化的任务和能力上实现了最先进的性能。
在讨论 PaLM 2 系列时,区分预训练模型(各种大小)、这些模型的微调变体以及使用这些模型的用户产品非常重要。特别是,用户产品通常包括额外的预处理和后处理步骤。此外,底层模型可能会随着时间的推移而演变。因此,不应期望用户产品的性能与本报告中报告的结果完全一致。
目录
-
引言
-
扩展定律实验
-
2.1 扩展定律
-
2.2 下游指标评估
-
-
训练数据集
-
评估
-
4.1 语言能力考试
-
4.2 分类和问答
-
4.3 推理
-
4.4 编码
-
4.5 翻译
-
4.6 自然语言生成
-
4.7 记忆
-
-
负责任的使用
-
5.1 推理时控制
-
5.2 对开发者的建议
-
-
结论
-
作者、归属和致谢
附录 A 详细结果-
A.1 扩展定律
-
A.2 指令微调
-
A.3 多语言常识推理
-
A.4 编码
-
A.5 自然语言生成
附录 B 模型能力示例 -
B.1 多语言性
-
B.2 创意生成
-
B.3 编码
附录 C 语言能力考试
附录 D 负责任的人工智能 -
D.1 数据集分析
-
D.2 评估方法
-
D.3 对话使用
-
D.4 分类使用
-
D.5 翻译使用
-
D.6 问答使用
-
D.7 语言建模
-
D.8 测量质量标准
-
D.9 众包工作表
-
D.10 模型卡
-
1. 引言
自 Shannon(1951)通过下一个词预测估计语言中的信息以来,语言建模一直是一个重要的研究领域。建模始于基于 n-gram 的方法(Kneser 和 Ney,1995),但随着 LSTM(Hochreiter 和 Schmidhuber,1997;Graves,2014)的出现迅速进步。后来的工作表明,语言建模也导致了语言理解(Dai 和 Le,2015)。随着规模的增加和 Transformer 架构(Vaswani 等,2017)的出现,大型语言模型(LLMs)在过去几年中在语言理解和生成能力方面表现出色,在推理、数学、科学和语言任务中取得了突破性表现(Howard 和 Ruder,2018;Brown 等,2020;Du 等,2022;Chowdhery 等,2022;Rae 等,2021;Lewkowycz 等,2022;Tay 等,2023;OpenAI,)。这些进展的关键因素包括模型规模的扩大(Brown 等,2020;Rae 等,2021)和数据量的增加(Hoffmann 等,2022)。迄今为止,大多数 LLMs 遵循的标准配方是主要使用单语语料库和语言建模目标。
我们介绍了 PaLM 2,它是 PaLM(Chowdhery 等,2022)的继任者,统一了建模进展、数据改进和扩展见解。PaLM 2 结合了以下多样化的研究进展:
-
计算最优扩展:最近,计算最优扩展(Hoffmann 等,2022)表明,数据大小至少与模型大小一样重要。我们验证了这项研究,发现对于给定的训练计算量,数据和模型大小应大致按 1:1 的比例扩展,以实现最佳性能(与过去的趋势相比,过去模型扩展速度是数据集的 3 倍)。
-
改进的数据集混合:以前的大型预训练语言模型通常使用以英语文本为主的数据集(例如,Chowdhery 等(2022)中非代码数据的约 78%)。我们设计了一个更多语言和多样化的预训练混合,涵盖数百种语言和领域(例如,编程语言、数学和平行多语言文档)。我们表明,更大的模型可以处理更多不同的非英语数据集,而不会导致英语语言理解性能下降,并应用去重来减少记忆(Lee 等,2021)。
-
架构和目标改进:我们的模型架构基于 Transformer。过去的 LLMs 几乎完全使用单一的因果或掩码语言建模目标。鉴于 UL2(Tay 等,2023)的强劲结果,我们在此模型中使用不同预训练目标的调优混合,以训练模型理解语言的不同方面。
PaLM 2 系列中最大的模型 PaLM 2-L 比最大的 PaLM 模型小得多,但使用了更多的训练计算量。我们的评估结果表明,PaLM 2 模型在各种任务上显著优于 PaLM,包括自然语言生成、翻译和推理。这些结果表明,模型扩展并不是提高性能的唯一途径。相反,通过细致的数据选择和高效的架构/目标,可以解锁性能。此外,更小但更高质量的模型显著提高了推理效率,降低了服务成本,并使模型能够应用于更多的应用和用户。
PaLM 2 展示了显著的多语言语言、代码生成和推理能力,我们在图 2 和图 3 中展示了这些能力。更多示例可以在附录 B.1 中找到。PaLM 2 在现实世界的高级语言能力考试中表现显著优于 PaLM,并在所有评估的语言中通过了考试(见图 1)。对于某些考试,这是足以教授该语言的语言能力水平。在本报告中,生成的样本和测量的指标来自模型本身,没有任何外部增强,如 Google 搜索或翻译。
PaLM 2 包括控制标记,以在推理时控制毒性,与之前的工作相比,仅修改了一小部分预训练(Korbak 等,2023)。在 PaLM 2 预训练数据中注入了特殊的“金丝雀”标记序列,以改进跨语言的记忆测量(Carlini 等,2019,2021)。我们发现,PaLM 2 的平均逐字记忆率低于 PaLM,对于尾部语言,我们观察到,只有当数据在多个文档中重复多次时,记忆率才会高于英语。我们展示了 PaLM 2 在多语言毒性分类能力上的改进,并评估了潜在的下游使用中的危害和偏见。我们还包括对预训练数据中人物表示的分析。这些部分帮助下游开发者评估其特定应用环境中的潜在危害(Shelby 等,2023),以便他们可以在开发早期优先考虑额外的程序和技术保障。本报告的其余部分重点介绍了设计 PaLM 2 和评估其能力时的考虑因素。
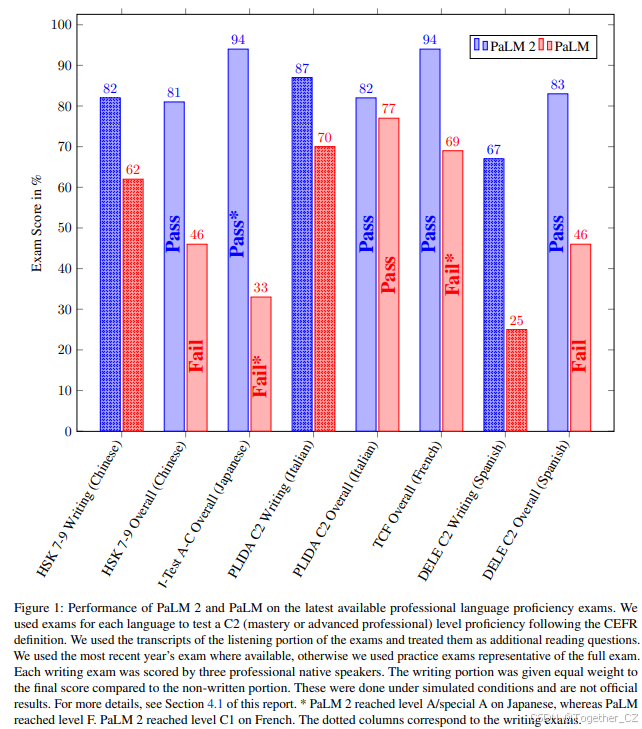
图1:PaLM 2和PaLM在最新可用的专业语言能力考试中的表现。我们使用每种语言的考试来测试C2(精通或高级专业)水平的能力,遵循CEFR(欧洲共同语言参考框架)的定义。我们使用了考试听力部分的文字稿,并将其作为额外的阅读题目。我们使用了最近一年的考试,如果没有可用的最新考试,则使用代表完整考试的模拟考试。每份写作考试由三位母语为相关语言的专业人士评分。写作部分与非写作部分在最终评分中权重相等。这些考试是在模拟条件下进行的,并非官方结果。更多细节请参见本报告的第4.1节。* PaLM 2在日语考试中达到了A/特别A级,而PaLM达到了F级。PaLM 2在法语考试中达到了C1级。虚线柱状图对应写作考试部分。


2. 扩展定律实验
扩展 Transformer 语言模型已成为实现最先进性能的流行方法。Kaplan 等(2020)研究了训练数据量(D)和模型大小(N)之间的关系,并得出了经验结论,即它遵循幂律,N 需要比 D 增长得更快。Hoffmann 等(2022)在此基础上进行了类似的研究,更好地调整了较小模型的超参数。他们的结果证实了 Kaplan 等(2020)的幂律结论;然而,他们得出了关于最佳比率的不同结果,表明 N 和 D 应大致按相同比例增长。
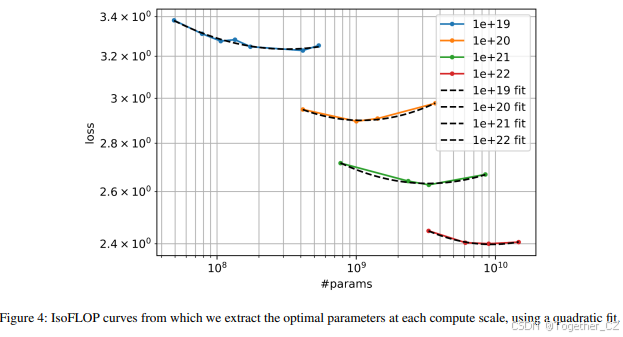
在本节中,我们独立推导了非常大模型的扩展定律。我们得出了与 Hoffmann 等(2022)相似的结论,即 D 和 N 应按相同比例增长。然后,我们探讨了扩展定律对下游指标的影响。需要注意的是,本节中的模型大小和总 FLOPs 仅用于扩展定律研究,并不反映 PaLM 2 模型中使用的模型大小和 FLOPs。
2.1 扩展定律
为了确定我们配置的扩展定律,我们遵循了Hoffmann等人(2022)的相同步骤。我们训练了多个不同规模的模型,使用了四种不同的计算预算:1×10^19、1×10^20、1×10^21和1×10^22 FLOPs。对于每个计算预算,我们使用启发式公式FLOPs ≈ 6ND(Kaplan等人,2020)来确定每个模型应训练的token数量。关键的是,我们使用了余弦学习率衰减,并确保每个模型的学习率在其最终训练token时完全衰减。
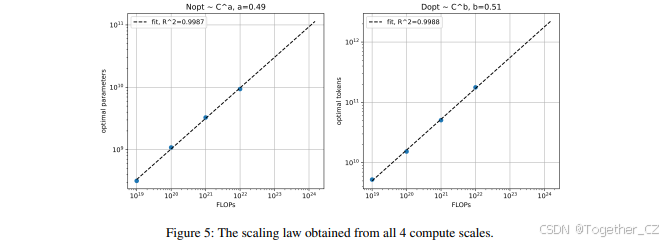
通过对每个模型的最终验证损失进行平滑处理,我们对每个等FLOPs区间进行了二次拟合(见图4)。这些二次拟合的最小值表示每个等FLOPs区间的预测最优模型大小(N)。最优的D是通过启发式FLOPs公式推导得出的。将这些最优N和最优D与FLOPs进行绘图(见图5),我们发现随着FLOPs预算的增加,D和N应以相同的比例增长。这与Hoffmann等人(2022)的结论非常相似,尽管他们的研究是在较小规模下进行的,并且使用了不同的训练数据混合。
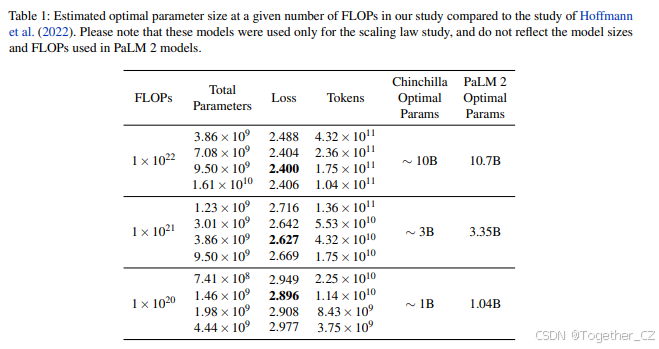
我们使用图5中的扩展定律计算了1×10^22、1×10^21和1×10^20 FLOPs的最优模型参数(D)和训练token数量(N)。然后,我们在相同的预训练数据混合上训练了从400M到15B的多个模型,最多达到1×10^22 FLOPs。最后,我们计算了每个模型在三个FLOPs点的损失。得到的训练损失及其相关的最优模型参数包含在表1中。我们可以观察到,最低的损失是由那些大致遵循给定FLOPs的最优模型参数(D)的模型实现的。请注意,该表中的模型大小和总FLOPs仅用于扩展定律研究,并不反映PaLM 2模型中使用的模型大小和FLOPs。更多细节请参见附录A.1。
2.2 下游指标评估
为了研究在固定计算预算下选择计算次优的参数和token数量对下游任务的影响,我们对表1中显示的1×10^22 FLOPs模型进行了下游评估,这些模型在某些情况下与计算最优性有较大偏差。
我们在附录中的表15中展示了不同规模模型的下游结果。下游指标表明,1×10^22 FLOPs模型的最优参数数量实际上约为9.5B,这与训练损失和扩展预测非常接近。然而,我们注意到训练损失并不是下游指标的完美代理。例如,9.5B模型在表1中显示出最低的损失,并且最接近最优模型,但在下游任务中略微逊色于16.1B模型。这表明,虽然扩展定律可以用于在给定FLOPs数量下实现最优训练损失,但这并不一定意味着在给定任务中实现最优性能。此外,除了最优训练损失外,还有其他几个考虑因素,如训练吞吐量和服务延迟,这些都会影响关于最优模型大小的决策。
3. 训练数据集
PaLM 2 的预训练语料库由多样化的来源组成:网页文档、书籍、代码、数学和对话数据。预训练语料库比用于训练 PaLM 的语料库大得多(Chowdhery 等,2022)。PaLM 2 在包含更高比例非英语数据的数据集上进行了训练,这对于多语言任务(例如翻译和多语言问答)是有益的,因为模型暴露于更广泛的语言和文化中。这使得模型能够学习每种语言的细微差别。
除了非英语单语数据外,PaLM 2 还在涵盖数百种语言的平行数据上进行了训练,其中一侧是英语。包含平行多语言数据进一步提高了模型理解和生成多语言文本的能力。它还将翻译的内在能力嵌入到模型中,这对于各种任务都很有用。表 21 列出了数百种语言中的前 50 种语言及其在多语言网页文档子语料库中的相关百分比。我们没有应用任何过滤来明确保留或删除任何语言。
我们采用了多种数据清理和质量过滤方法,包括去重、删除敏感的个人身份信息(PII)和过滤。尽管 PaLM 2 的英语数据比例低于 PaLM,但我们仍然观察到在英语评估数据集上的显著改进,如第 4 节所述。我们部分归因于 PaLM 2 混合数据中的更高数据质量。
对于一小部分预训练数据,我们添加了特殊控制标记,标记文本的毒性,使用固定版本的 Perspective API 的信号。我们在第 5 节中评估了在推理时控制标记作为控制方法的有效性。重要的是,我们的评估表明,控制标记不会对不相关任务的性能产生负面影响。我们在第 4.7 节中描述了为记忆评估注入的特殊多语言金丝雀,并在附录 D.1 中对预训练数据进行了负责任的人工智能分析。
PaLM 2 的训练显著增加了模型的上下文长度,超过了 PaLM。这一改进对于实现长对话、长距离推理和理解、摘要以及其他需要模型考虑大量上下文的任务至关重要。我们的结果表明,在不影响通用基准性能的情况下,增加模型的上下文长度是可能的,这些基准可能不需要更长的上下文。
4. 评估
我们评估了 PaLM 2 在人类设计的考试以及标准学术机器学习基准上的表现。对于考试,我们专注于标准语言能力考试,这些考试使我们能够评估 PaLM 2 在多种语言中的能力。在学术基准上,我们评估了 PaLM 2 在六大类任务上的表现,这些任务代表了 LLMs 的核心能力和应用:分类和问答、推理、编码、翻译和自然语言生成。多语言性和负责任的人工智能考虑是所有评估的共同线索。在每个部分中,我们使用专门的数据集来量化 PaLM 2 的多语言能力,并评估潜在的下游使用中的危害和偏见。我们还将记忆评估作为潜在隐私危害的一个方面进行了描述。
我们评估了 PaLM 2 的三个变体:小型(S)、中型(M)和大型(L)。除非另有说明,PaLM 2 指的是大型版本。由于模型检查点之间的结果存在一些差异,我们对 PaLM 2 的最后五个检查点的结果进行了平均,以便对大型模型进行更稳健的比较。通常,我们在少样本、上下文学习环境中评估模型,其中模型会给出一个简短的提示,并可选择提供任务的几个示例。除非另有说明,我们基于源和目标长度的 ≥99% 百分位数进行解码,并在数据集的测试分割上进行评估(如果可用)。我们观察到所有领域的质量都有显著提高。对潜在危害和偏见的评估优先考虑 PaLM 2(L),并且通常使用其他提示方法或使用 top-k 解码绘制多个样本来测量系统输出。
4.1 语言能力考试
对于人类语言能力考试,我们找到了一组与欧洲语言共同参考框架(CEFR)中最高语言能力等级C2相对应的考试。这类似于ACTFL中的S/D级别或ILR中的4/4+级别。我们进行了通用的指令微调,并未针对这些考试进行专门训练。我们找到了最近公开的过去或模拟考试,并在这些模型上模拟考试环境,给出预估分数。模型会接收到考试名称和一个问题或一组问题——没有使用少量示例。这些考试包括选择题和写作题,我们使用一组第三方评分者独立对写作考试的结果进行评分,满分为5分,5分是给予母语成年人的分数。我们没有使用考试的口语部分。对于听力考试,我们使用了可用的转录文本,并将其视为阅读考试的附加问题。最后,我们同等加权阅读和写作部分,并给出分数。然后根据官方指南给出通过/未通过的结果。请注意,这些不是官方成绩。更多细节请参见附录C。
我们在图1中展示了结果。PaLM 2在所有考试中均优于PaLM,并在每种语言中均达到及格分数,展示了其在所有评估语言中的语言能力。
4.2 分类与问答
分类和问答(QA)是已确立的自然语言理解任务,它们已成为评估大语言模型的常见测试平台。我们评估了PaLM 2在LLM文献中常用的数据集上的表现(Brown等,2020;Du等,2022;Chowdhery等,2022)。我们还纳入了评估PaLM 2多语言能力的任务。
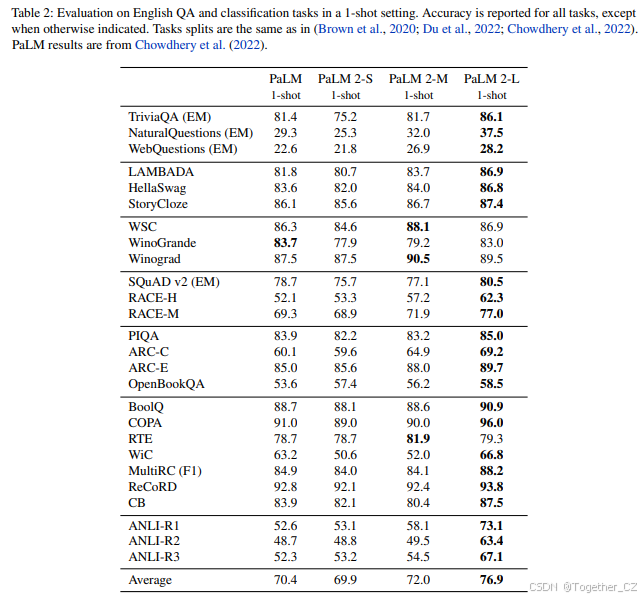
英语QA和分类任务 我们首先在先前工作中使用的一组标准英语问答和分类任务上评估PaLM 2的变体(Du等,2022;Brown等,2020;Chowdhery等,2022),包括:
-
开放域闭卷问答任务:TriviaQA(Joshi等,2017)、Natural Questions(Kwiatkowski等,2019)和WebQuestions(Berant等,2013)
-
完形填空和补全任务:LAMBADA(Paperno等,2016)、HellaSwag(Zellers等,2019)和StoryCloze(Mostafazadeh等,2016)
-
Winograd风格任务:Winograd(Levesque等,2012)和WinoGrande(Sakaguchi等,2021)
-
阅读理解:SQuAD v2(Rajpurkar等,2018)和RACE(Lai等,2017)
-
常识推理:PIQA(Bisk等,2020)、ARC(Clark等,2018)和OpenBookQA(Mihaylov等,2018)
-
SuperGLUE(Wang等,2019)
-
自然语言推理:Adversarial NLI(ANLI;Nie等,2020)
我们将PaLM 2的变体与PaLM 540B在一次性设置中进行比较,结果如表2所示。我们观察到,即使是最小的PaLM 2变体也能与更大的PaLM 540B模型竞争,而PaLM 2-M已经持续优于PaLM。我们强调PaLM 2-L在以下方面取得了显著进展:
• 在几乎所有任务上相比PaLM都有大幅提升。
• 在WSC和WinoGrande上表现相似,这两者都采用了Winograd模式。
• 在Adversarial NLI(ANLI)数据集上表现尤为突出,这些数据集对鲁棒性要求较高,ReCoRD常识推理数据集和RACE阅读理解数据集上也有显著提升。
我们在第4.6节中测量了与身份术语相关的问答表现中的潜在偏见,以及其他生成任务中的偏见。我们发现PaLM 2在关于社会身份的歧义问题上表现良好,并未观察到系统性的偏见模式,完整结果见附录D.6。
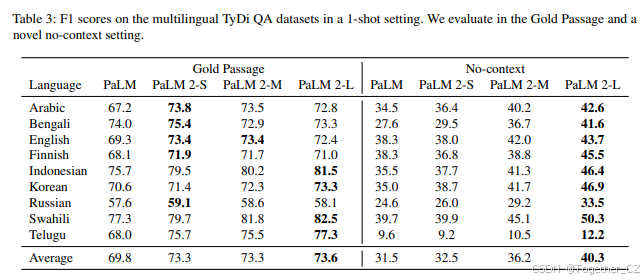
多语言QA 为了展示PaLM 2的多语言能力,我们在一次性设置中评估了多语言QA数据集TyDi QA(Clark等,2020)。我们还提出了一个更具挑战性的无上下文设置,模型必须仅基于其参数中存储的知识回答问题。结果如表3所示。
在所有设置中,PaLM 2的变体均优于PaLM。在Gold Passage设置中,PaLM 2变体之间的差异相对较小,表明所有模型都学习了鲁棒的多语言阅读理解能力。在更具挑战性的无上下文设置中,模型大小之间的性能差异更为明显。最大的PaLM 2明显优于所有对比模型。在这两种设置中,PaLM 2在数据有限的语言(如泰卢固语、斯瓦希里语和印尼语)以及非拉丁文字的语言(如阿拉伯语和韩语)上相比PaLM的提升尤为显著。
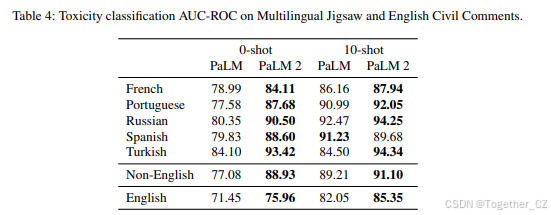
多语言毒性分类 我们将PaLM 2在毒性分类上的表现作为负责任AI实践中常见分类任务的代表进行评估。通过将Schick等(2021)的提示方法应用于零样本和少样本上下文,我们发现PaLM 2在英语毒性分类(Borkan等,2019)和使用Jigsaw多语言数据集(Jigsaw,2019b)的非英语示例上相比PaLM有所提升,但在西班牙语上表现略有下降。详细结果见附录D.4。
多语言能力 我们在附录B.1中提供了更多关于PaLM 2多语言能力的示例,并在D.3.2中评估了潜在危害和偏见。PaLM 2能够执行许多能力,如解释笑话、生成创意文本等,这些能力在之前的模型中仅限于英语。此外,它能够无缝地在不同语言的语域、方言和文字之间转换。
4.3 推理
大模型的推理能力、结合多段信息的能力以及进行逻辑推断的能力是其最重要的能力之一。我们在少样本设置中评估了PaLM 2在代表性推理数据集上的推理能力,包括WinoGrande(Sakaguchi等,2021)、ARC-C(Clark等,2018)、DROP(Dua等,2019)、StrategyQA(Geva等,2021)、CommonsenseQA(CSQA;Talmor等,2019)、XCOPA(Ponti等,2020)和BIG-Bench(BB)Hard(Suzgun等,2022)。我们与PaLM、GPT-4(OpenAI,2023b)以及每个数据集的最新技术(SOTA)进行了比较。我们使用了指令微调版本的PaLM 2(详见附录A.2的微调结果),除了多语言XCOPA数据集。
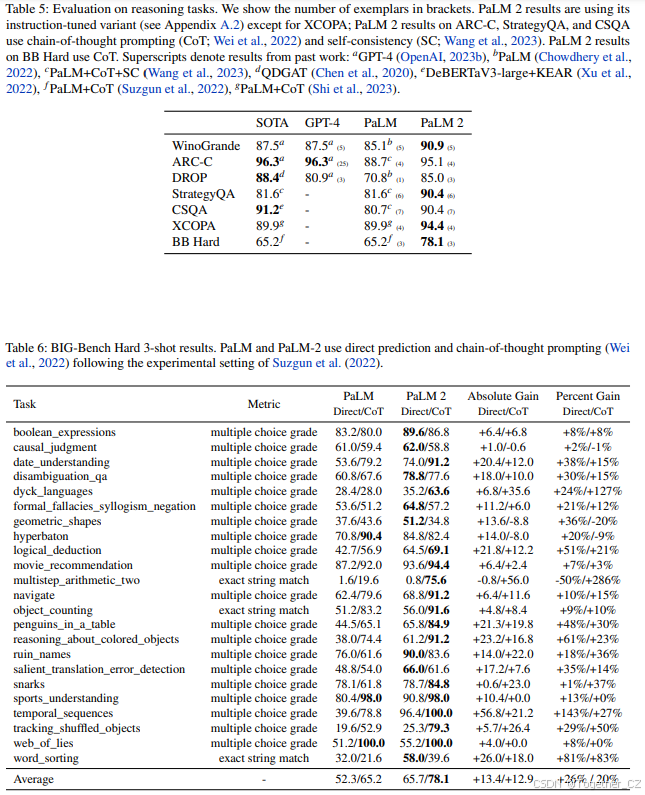
PaLM 2在所有数据集上均优于PaLM,并与GPT-4竞争。在多语言XCOPA数据集上,PaLM 2在代表性不足的语言(如斯瓦希里语、克丘亚语和海地语)上取得了特别显著的提升,即使没有使用思维链提示(Wei等,2022),也建立了新的技术标杆(详见附录A.3的详细结果)。在BIG-Bench Hard上,PaLM 2在每项任务上均优于PaLM,且通常优势显著。我们在下文中讨论了在具有挑战性的BIG-Bench Hard任务上的改进。
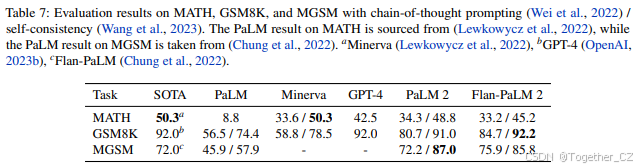
BIG-Bench Hard Beyond the Imitation Game Benchmark(BIG-bench;Srivastava等,2022)提供了一个大型协作套件,包含200多个任务,可用于探测LLM在多个领域和能力上的表现。BIG-Bench Hard(Suzgun等,2022)是23个BIG-Bench任务的子集,这些任务在撰写本文时表现最好的LLM低于人类评分者的平均水平。我们遵循Suzgun等(2022)的实验设置,使用少样本(直接)提示和思维链提示(Wei等,2022)。我们使用相同的3-shot提示,并为每个任务抽取250个示例,以生成总计6,511个示例。结果如表6所示。PaLM 2在这组具有挑战性的任务上相比PaLM取得了显著提升。在多项任务上,包括解决多步算术问题(multistep_arithmetic)、时间序列推理、回答关于某些事件发生时间的问题(temporal_sequences)以及使用Dyck语言进行层次推理(dyck_languages),PaLM 2相比PaLM提升了超过100%,展示了新的涌现能力。
数学推理 LLM在需要定量推理的任务上一直表现不佳,例如高中数学、科学和工程问题(Hendrycks等,2021;Cobbe等,2021)。最近,Minerva(Lewkowycz等,2022)通过在科学和数学内容上对PaLM进行微调,在定量推理任务上取得了显著进展。
我们在MATH(Hendrycks等,2021)上评估了PaLM 2,该数据集包含来自7个数学学科的高中竞赛的12,500个问题,GSM8K(Cobbe等,2021),一个包含8,500个小学数学文字题的数据集,以及MGSM(Shi等,2023),GSM8K的多语言版本,将部分示例翻译成十种类型多样的语言。我们将PaLM 2与PaLM、Minerva(Lewkowycz等,2022)、GPT-4(OpenAI,2023b)以及每个数据集的最新技术进行了比较。
对于MATH,我们遵循Lewkowycz等(2022)的方法,使用相同的4-shot思维链提示,并结合自一致性(Wang等,2023),利用64个样本路径。对于GSM8K,我们使用与(Wei等,2022)相同的8-shot思维链提示,并使用40个样本路径的自一致性。我们使用SymPy库(Meurer等,2017)来比较答案,并防止由于不同表面形式的等效答案导致的假阴性。对于MGSM,我们使用8-shot思维链提示和Shi等(2023)提供的语言内示例。
结果如表7所示。PaLM 2在所有数据集上均显著优于PaLM。在MATH上,PaLM 2与专门的Minerva模型的最新技术表现相当。在GSM8K上,PaLM 2优于Minerva和GPT-4,而在MGSM上,即使没有自一致性,它也超越了最先进的技术。
4.4 代码生成
代码语言模型是当今经济意义最重大且广泛部署的LLM之一;代码LM被部署在多种开发者工具中(Github,2021;Tabachnyk & Nikolov,2022),作为个人编程助手(OpenAI,2022;Hsiao & Collins,2023;Replit,2022),以及作为能干的工具使用代理(OpenAI,2023a)。为了在开发者工作流程中实现低延迟、高吞吐量的部署,我们通过在扩展的、代码密集的、多语言数据混合上继续训练PaLM 2-S模型,构建了一个小型、专门用于代码的PaLM 2模型。我们称该模型为PaLM 2-S*,它在代码任务上表现出显著改进,同时保留了在自然语言任务上的性能。我们在一组少样本代码任务上评估了PaLM 2-S的代码能力,包括HumanEval(Chen等,2021)、MBPP(Austin等,2021)和ARCADE(Yin等,2022)。我们还使用翻译成多种低资源语言版本的HumanEval测试了PaLM 2-S的多语言代码能力(Orlanski等,2023)。
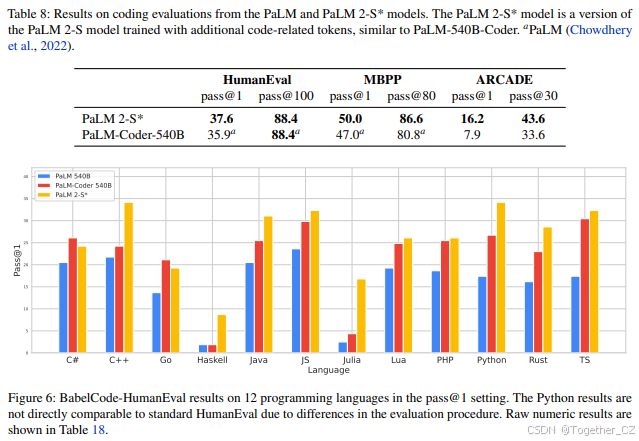
代码生成 我们在3个代码数据集上对PaLM 2进行了基准测试:HumanEval(Chen等,2021)、MBPP(Austin等,2021)和ARCADE(Yin等,2022)。HumanEval和MBPP是自然语言到代码的数据集,测试模型生成通过一组保留测试用例的自包含Python程序的能力。ARCADE是一个Jupyter Notebook补全任务,要求模型在给定文本描述和前面的Notebook单元格的情况下补全下一个单元格。与(Chen等,2021;Austin等,2021;Yin等,2022)一样,我们在pass@1和pass@k设置中对模型进行基准测试。我们对所有pass@1评估使用贪婪采样,对pass@k评估使用温度为0.8的核采样p = 0.95。所有样本都在代码沙箱中执行,访问少量相关模块,并与系统环境严格隔离。对于ARCADE,我们使用包含新策划的Notebook问题的新任务拆分,以避免评估数据泄露。
结果如表8所示。PaLM 2-S*在所有基准测试中均优于PaLM-540B-Coder,且通常优势显著(例如ARCADE),尽管它明显更小、更便宜且服务速度更快。
多语言评估 我们还使用BabelCode(Orlanski等,2023)评估了PaLM 2-S的多语言代码能力,该工具将HumanEval翻译成多种其他编程语言,包括高资源语言如C++、Java和Go,以及低资源语言如Haskell和Julia。PaLM 2的代码训练数据比PaLM的多语言性显著增强,我们希望这能在代码评估中带来显著收益。图6展示了PaLM 2-S的结果与原始PaLM模型的对比。我们在图7中展示了一个多语言程序生成的示例。
PaLM 2-S在除两种语言外的所有语言上均优于PaLM,在低资源语言如Julia和Haskell上的性能下降出乎意料地小;例如,PaLM 2-S在Haskell上比更大的PaLM-Coder-540B提升了6.3倍,在Julia上提升了4.7倍。值得注意的是,Java、JavaScript和TypeScript的性能实际上高于原始语言Python。
4.5 翻译
PaLM 2的一个明确设计选择是改进的翻译能力。在本节中,我们使用高质量机器翻译的推荐实践评估了句子级翻译质量,并测量了翻译错误可能导致的性别误判危害。

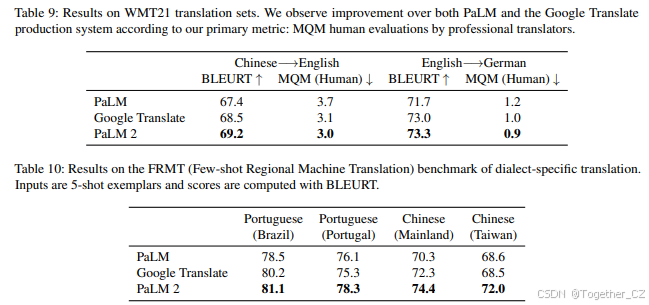
WMT21实验设置 我们使用最近的WMT 2021数据集(Akhbardeh等,2021)以防止训练/测试数据泄露,并便于与最先进技术进行比较。我们将PaLM 2与PaLM和Google翻译进行比较。对于PaLM和PaLM 2,我们使用5-shot示例提示模型;对于Google翻译,我们直接将源文本发送给模型,因为这是它期望的格式。
我们使用两种指标进行评估:
-
BLEURT(Sellam等,2020):我们使用BLEURT(Sellam等,2020)作为最先进的自动指标,而不是BLEU(Papineni等,2002),因为BLEU与人类质量判断的相关性较差,尤其是对于高质量翻译(Freitag等,2022)。
-
MQM(Freitag等,2021):为了计算多维质量指标(MQM),我们聘请了专业翻译人员(7名英语到德语,4名中文到英语),并使用文档上下文版本的MQM测量翻译质量,该版本模仿了Freitag等(2021)提出的设置,包括相同的错误类别、严重程度和错误权重方案。根据Freitag等(2021),我们分配了以下权重:每个主要错误5分,每个次要错误1分,每个次要标点错误0.1分。最终系统级得分是所有注释得分的平均值。
我们在表9中展示了中文到英语和英语到德语的MQM研究结果。MQM表示每段的平均错误数,数字越低表示结果越好。我们观察到PaLM 2在质量上相比PaLM和Google翻译都有所提升。
区域翻译实验设置 我们还报告了FRMT基准(Riley等,2023)上的少样本区域机器翻译结果。通过关注特定区域的方言,FRMT使我们能够衡量PaLM 2生成最适合每个地区的翻译的能力——这些翻译对每个社区来说都会感觉自然。我们在表10中展示了结果。我们观察到PaLM 2不仅优于PaLM,而且在所有地区也优于Google翻译。
潜在的性别误判危害 我们测量了PaLM 2在零样本翻译中可能导致性别误判危害的失败情况。在翻译成英语时,我们发现PaLM 2的表现稳定,相比PaLM在26种语言的最坏情况下的分解性能有小幅提升。在从英语翻译成13种语言时,我们评估了性别一致性和翻译质量。令人惊讶的是,我们发现即使在零样本设置中,PaLM 2在三种高资源语言(西班牙语、波兰语和葡萄牙语)的性别一致性上也优于PaLM和Google翻译。我们观察到在翻译成泰卢固语、印地语和阿拉伯语时,PaLM 2的性别一致性得分低于PaLM。结果和分析见附录D.5。
4.6 自然语言生成
由于其生成式预训练,自然语言生成(NLG)而非分类或回归已成为大语言模型的主要接口。尽管如此,模型的生成质量很少被评估,NLG评估通常集中在英语新闻摘要上。评估自然语言生成中的潜在危害或偏见也需要更广泛的方法,包括考虑对话使用和对抗性提示。我们在涵盖类型多样的语言的代表性数据集上评估了PaLM 2的自然语言生成能力:
• XLSum(Hasan等,2021),要求模型用同一语言总结新闻文章,语言包括阿拉伯语、孟加拉语、英语、日语、印尼语、斯瓦希里语、韩语、俄语、泰卢固语、泰语和土耳其语。
• WikiLingua(Ladhak等,2020),专注于从WikiHow生成逐步说明的章节标题,语言包括阿拉伯语、英语、日语、韩语、俄语、泰语和土耳其语。
• XSum(Narayan等,2018),要求模型生成新闻文章的第一句话,语言为英语。
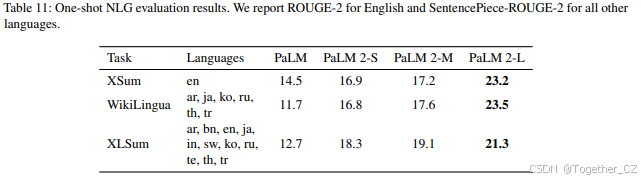
我们使用通用设置将PaLM 2与PaLM进行比较,并重新计算PaLM的结果。我们为每个数据集使用自定义的1-shot提示,包括指令、源文档及其生成的摘要、句子或标题。作为评估指标,我们使用ROUGE-2用于英语,使用SentencePiece-ROUGE-2(ROUGE的扩展,使用SentencePiece分词器处理非拉丁字符——在我们的案例中为mT5(Xue等,2021)分词器)用于所有其他语言。
我们专注于1-shot学习设置,因为输入可能很长。我们将极长的输入截断到最大输入长度的一半左右,以便指令和目标始终能适应模型的输入。我们贪婪地解码单个输出,并在示例分隔符(双换行符)处停止,或继续解码直到最大解码长度,该长度设置为目标长度的第99百分位。
我们在表11中展示了平均结果,并在附录A.5中展示了每种语言的结果。即使是最小版本的PaLM 2也优于PaLM,展示了其改进的多语言生成能力。PaLM 2-L在PaLM的NLG能力上取得了显著提升,从XSum上的59.4%到WikiLingua上的100.8%。
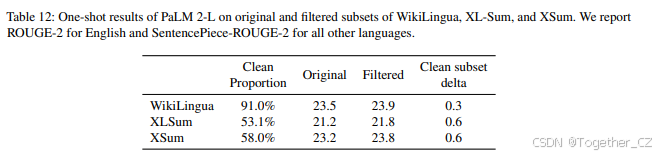
我们专注于上述生成任务,因为目标数据和训练数据的显著重叠会给模型在评估中带来不公平的优势。正增量提供了数据污染的证据,而负增量表明性能因数据污染而膨胀。我们在表12中展示了结果,并在附录A.5中展示了每种语言的结果。鉴于低正增量普遍存在,我们发现模型的性能可能并未因记忆目标而膨胀。
潜在危害和偏见 我们评估了PaLM 2在对话、生成式问答和开放式语言建模中的潜在危害和偏见。我们专注于有毒语言和强化排他性规范的偏见,并在附录D中提供了关于我们的方法、局限性和结果的进一步讨论。数据集包括:
• ParlAI对话安全(Dinan等,2019),包含标准和对抗性数据集,语言为英语。
• 多语言代表性偏见,测量与身份术语相关的有毒语言危害和偏见,语言包括阿拉伯语、中文(简体)、捷克语、荷兰语、法语、德语、印地语、意大利语、日语、韩语、葡萄牙语、俄语、西班牙语和瑞典语——扩展自(Chung等,2022;Chowdhery等,2022)。
• BBQ偏见基准用于QA(Parrish等,2021),适应于生成式QA上下文,语言为英语。
• RealToxicityPrompts(Gehman等,2020),测量语言建模中的有毒语言危害,语言为英语。
在语言建模和开放式生成(没有提示近似预期的下游使用)中,我们发现PaLM 2相比PaLM在语言建模任务中的有毒语言危害有所减少,在ParlAI对话安全中的对话语言建模中略有下降。更多细节见附录D.7。
在对话使用中,我们发现像(Glaese等,2022)中那样提示PaLM 2可以显著减少有毒语言危害的水平,相比在去上下文化的语言建模任务中观察到的情况。我们在ParlAI对话安全和新的多语言代表性偏见评估中都观察到了这一点。我们还分析了跨语言、数据集和提示引用身份术语的潜在有毒语言危害。当按语言分解时,我们发现有毒响应的百分比在最佳情况下为0%到3.5%,而在最坏情况下为1%到17.9%(英语、德语和葡萄牙语)。同样,当按身份术语分解时,我们发现潜在有毒语言危害在不同语言之间存在偏见。例如,引用“黑人”和“白人”身份群体的查询在英语、德语和葡萄牙语中比其他语言产生更高的毒性率,引用“犹太教”和“伊斯兰教”的查询也更容易产生有毒响应。在我们测量的其他语言中,对话提示方法似乎更有效地控制了有毒语言危害。完整分析见附录D.3。
在生成式问答上下文中,我们发现PaLM 2在关于社会身份的歧义问题上表现良好(91.4%的准确率),但3%的所有歧义问题会产生某种形式的代表性危害,通过强化社会偏见(Parrish等,2021)。我们没有观察到系统性的偏见模式,但在附录D.6中包含了额外的定性分析,展示了幻觉(Ji等,2023)如何可能产生以前在分类和回归偏见测量中未测量的显著代表性危害风险。
4.7 记忆
当机器学习模型泄露特定于个人的信息时,就会发生隐私泄露,根据下游使用情况,这可能导致一系列社会技术危害,尤其是当这些信息敏感时(Shelby等,2023)。众所周知,最先进的大语言模型会从其训练语料库中记忆长段文本(Carlini等,2021),即使只对训练语料库进行一次训练(Chowdhery等,2022),或者即使采用了数据去重(Lee等,2021)或输出过滤(Ippolito等,2022)等缓解措施。在这里,我们量化了PaLM 2记忆长段训练数据的程度,作为下游隐私危害潜力的一个代理。
与Carlini等(2022)和Chowdhery等(2022)类似,我们在提示的训练数据提取上测试了记忆。为此,我们采样训练序列并将其拆分为由前P个标记组成的前缀和由最后S个标记组成的后缀。为了评估记忆,我们使用前缀(提示)查询语言模型,并将生成与后缀匹配。我们使用贪婪解码生成后缀。
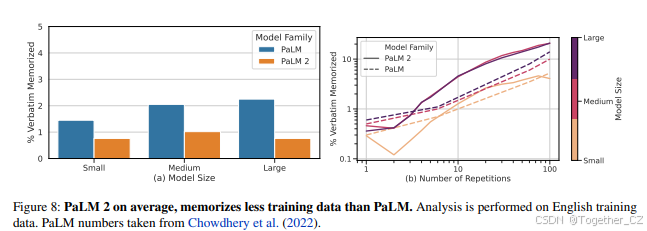
逐字记忆 我们首先评估了PaLM 2与PaLM在共享的英语预训练数据上的训练数据提取率。为此,我们遵循与Chowdhery等(2022)类似的协议,从该共享数据中采样10,000个唯一文档。然后,我们用每个文档的前P = 50个标记提示模型,目标后缀为接下来的S = 50个标记。在我们的分析中,我们使用了三个不同规模的可比模型大小,“小”、“中”和“大”,分别用于PaLM和PaLM 2。在图8(a)中,我们比较了每个模型家族的记忆率,发现PaLM 2平均记忆的数据显著减少。对于PaLM 2,我们观察到中型模型的记忆率最高。尽管如此,该模型记忆的序列数量仍显著少于PaLM家族中记忆最少的模型。
接下来,我们基于每个序列被模型看到的次数进行了更细粒度的分析;这被证明对记忆可能性有显著影响(Carlini等,2019;Lee等,2021)。尽管训练数据在文档级别上进行了近似去重,但较小的n-gram经常重复。我们计算了训练数据中每个唯一100标记序列的重复次数。然后,我们为各种重复次数(范围[1,100])采样最多10,000个序列。图8(b)展示了结果。我们观察到,当文档仅重复几次时,PaLM 2的记忆量远少于PaLM。然而,当n-gram重复次数超过几次时,PaLM 2记忆序列的可能性要高得多。我们假设这可能是去重的副作用;因为重复的n-gram现在更稀有且出现在更独特的上下文中,这可能导致我们观察到的更高记忆可能性。
通过canary改进记忆分析 训练数据提取提供了对训练分布中平均样本记忆的表征。相比之下,canary通过构造代表了罕见或“异常”数据点。因此,它们提供了不同的记忆视角,可能无法通过训练数据提取捕捉:它们揭示了记忆在远离自然训练分布的数据中如何表现的问题。我们遵循与Carlini等(2019);Jagielski等(2022)类似的设置;因为PaLM 2是在多语言数据上训练的,我们还注意设计在其源语言中罕见的canary。
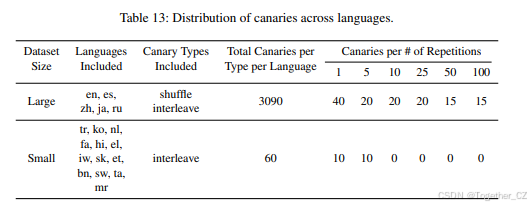
在我们的设计中,我们寻求在使canary显得异常的同时保留训练数据的特定特征之间取得平衡。一方面,异常数据点与自然数据共享的相似性很少,这可能导致模型记忆它们而不是泛化。另一方面,由于canary注入频率非常低,它们可能需要在某种程度上与自然数据相似——否则模型可能直接忽略它们。在光谱的一端,我们可以通过完全随机采样标记来设计canary作为完全异常;在另一端,我们可以对现有数据进行最小更改。我们提出了两种提供中间地带的canary类型:交错canary,它从预训练数据中获取两个文档,并以相同的相对顺序交错N = 50个标记的批次,从而保留一些语言特性;以及洗牌canary,它洗牌单个真实训练文档的所有标记,以删除与其序列级顺序相关的任何信息。我们从每种语言中采样文档,只要它们≥ 500个标记长。语言根据其在预训练数据中的总标记数分为“大”和“小”两类,每个类别的canary分布如表13所示。我们确保注入的canary总数较少,以最小化对下游性能的影响。请注意,每个canary都是其训练数据的随机样本。我们重复了一部分canary,因为重复对记忆提取有显著影响(Carlini等,2019;Lee等,2021)。
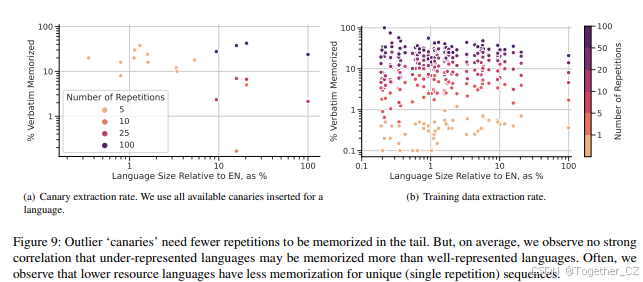
尾部记忆 尽管多语言性为PaLM 2带来了许多好处,但它也带来了新的记忆风险:数据通常更稀缺且质量较差(Kreutzer等,2022)。由于它们位于整体数据分布的尾部,模型可能会记忆这些数据(Feldman,2019)。在这里,我们分析了这些尾部语言的记忆风险。为此,我们使用上述相同的训练数据提取程序,为每种语言的每个重复箱采样最多2,000个序列。除此之外,我们还进行了canary提取,为此我们使用P = 60和S = 30,以唯一区分交错canary与生成它们的文档。
我们在图9(a)中的结果显示,记忆可能在尾部语言中恶化。特别是,我们观察到,在文档较少的数据源中,这些异常canary需要较少的重复次数即可成功提取。然而,我们在图9(b)中观察到,在真实训练数据上,情况往往并非如此。我们发现语言规模与训练数据提取率之间没有强相关性——事实上,我们观察到在代表性不足的语言中,对于唯一(单次重复)序列的记忆率通常较低。然而,当尾部语言的序列高度重复时,有时会出现显著更高的记忆率。
讨论 记忆分析提供了一个系统性的研究,可以揭示下游使用中的潜在隐私风险。重要的是,我们发现与PaLM相比,PaLM 2在平均逐字记忆上显著减少,尤其是在预训练数据中重复次数少于三次的数据上。我们注意到这些记忆率是估计值,并不能完全表征成功攻击者通过访问PaLM 2可能恢复的内容。对于通过下游使用的攻击,威胁情况将有所不同,因为下游开发者可以使用额外的程序和技术保障措施来防止提取攻击。对于特定的攻击目标,真实的攻击者可能还能够利用额外的上下文信息,如侧信道信息。未来的工作可以扩展记忆评估,以衡量在对话或摘要等使用中的潜在隐私危害和攻击。
4.8 总结
在本节中,我们详细评估了PaLM 2在多个任务和语言上的表现,包括语言能力考试、分类与问答、推理、代码生成、翻译、自然语言生成以及记忆。总体而言,PaLM 2在大多数任务上均显著优于其前身PaLM,并在多语言能力、推理和代码生成等方面展示了新的技术突破。尽管在某些特定语言或任务上存在一些局限性,PaLM 2的整体表现表明其在处理复杂、多样化的自然语言任务上具有强大的潜力。未来的研究可以进一步探索如何优化模型在低资源语言上的表现,以及如何更好地缓解模型在生成任务中的潜在偏见和危害。
5. 负责任的使用
评估语言模型中的风险具有挑战性,因为它们具有通用能力,并且有许多潜在的下游用途(Jacobs 和 Wallach,2021;Weidinger 等,2021)。重要的是要认识到,本文中评估的模型是预训练模型(各种大小)。这些模型的微调变体,特别是使用这些模型的用户产品,通常包括额外的预处理和后处理步骤。此外,底层模型可能会随着时间的推移而演变。因此,不应期望用户产品的性能与本报告中报告的结果完全一致。
Google 的人工智能原则(Google,2018)于 2018 年发布,概述了我们的目标和我们不会追求的应用,并且我们制定了生成模型特定的政策(Google,)。我们不会追求的应用列表预计会随着我们经验的加深和技术的演变而发展,包括:
-
可能导致或很可能导致整体危害的技术。如果存在重大危害风险,我们只有在认为收益大大超过风险的情况下才会继续,并将纳入适当的安全约束。
-
武器或其他主要目的或实施是造成或直接促进人员伤害的技术。
-
收集或使用信息进行违反国际公认规范的监视的技术。
-
目的违反国际法和人权广泛原则的技术。
所有使用 PaLM 2 构建的 Google 应用程序都会经过一组训练有素的伦理专家的审查,以评估其整体社会效益。建议采取缓解措施以解决任何漏洞,并进行严格的测试和生产监控,以识别任何问题或新兴趋势。使用条款政策(Google,)概述了模型的负责任使用。类似的政策适用于从 PaLM 2 预训练模型派生的 API,并附加了缓解措施,例如(Google,)。由于语言模型从广泛的信息中学习,这些信息可以反映和传播不公平的现实世界偏见和刻板印象,这些不公平的偏见和刻板印象有时会以有害内容的形式出现在其输出中。语言模型还可以提供不准确、误导或错误的信息,同时表现得自信(也称为“幻觉”)。这些以及潜在的隐私侵犯,是任何预训练语言模型(包括 PaLM 2)的已知风险。与任何变革性技术一样,我们将继续评估和改进我们对这些模型风险的理解,以及提高其安全性的缓解措施。
在本节的其余部分,我们讨论了关于 PaLM 2 负责任使用的下游开发者的考虑。在第 5.1 节中,我们探讨了使用控制标记进行推理时控制毒性危害的示例。第 5.2 节概述了对开发者的考虑,附录 D 讨论了各种负责任的人工智能预训练数据分析和基准性能。
5.1 推理时控制
在预训练数据的一小部分中,我们添加了特殊的控制标记,用于标注文本的毒性水平。在本节中,我们测量了基于控制标记的条件化对语言建模和对话语言建模中有毒语言危害评估的影响,并与提示方法进行了比较。
语言建模
基于Gehman等人(2020)的实验设置,本评估重点在于测量对毒性退化的控制。我们从Gehman等人(2020)中采样了50k个提示,并使用数据集中的毒性分数筛选出毒性概率<0.5的输入提示。然后,我们使用贪婪解码为每个38k提示从模型中采样单个响应,而不是像之前的工作(Chowdhery等,2022;Rae等,2021)那样使用top-p或top-k采样多次。这种方法使得在模型训练期间能够进行连续评估,并比较不同大小样本的指标。关于这种评估方法与更计算密集的多次采样变体的对比分析,请参见D.7。对于所有PaLM 2评估,我们使用Perspective API的版本来避免信号随时间改进而导致的漂移(Pozzobon等,2023)。
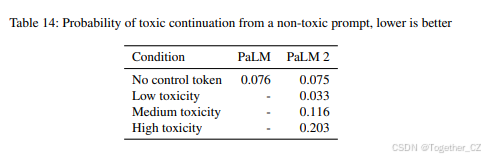
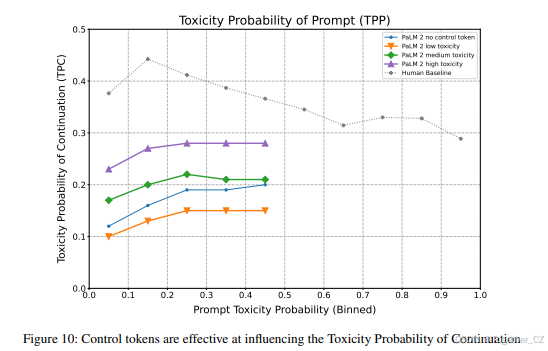
我们观察到,在推理时添加控制标记对生成毒性延续(毒性概率≥0.5)的概率有显著影响。对于非毒性输入提示,控制标记在控制生成方面是有效的,可以用于降低毒性延续的概率,也可以用于增加它。我们还展示了这种效果在非毒性提示的输入毒性分层中保持一致。这与Korbak等人(2023)的结果一致,他们发现条件化训练是一种有效的可控生成方法,在预训练和微调中通过120M参数模型的多次消融实验验证了这一点。重要的是,我们在PaLM 2中的方法仅应用于一小部分预训练标记。
对话语言建模和对话使用
我们还测量了在对话语言建模和对话使用中基于控制标记的条件化的影响。我们使用了Dinan等人(2019)的标准和对抗性数据集,并基于单次采样分析结果。关于方法和相关分析的描述,请参见附录D.3和D.7.1。
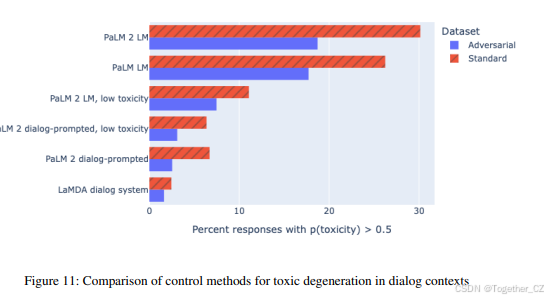
在对话语言建模中,我们发现PaLM 2提供了一种有效的推理时控制方法,将标准数据集中的毒性响应比例从30%降低到12%,在对抗性数据集中从18%降低到7%。对于对话使用,我们意外地发现,仅使用对话提示比控制标记在减少毒性生成方面更有效。即使在标准数据集上也是如此,该数据集旨在测量与预训练中使用Perspective API信号标注方法更接近的显式毒性形式。我们确实看到在对话提示上叠加控制标记带来的小幅提升,但仅限于标准数据集,因为对抗性数据集旨在测量与预训练时标注的不同结构。
最后,我们与专门的对话系统LaMDA(Thoppilan等,2022)的版本进行了比较,并指出专门的下游缓解方法仍然比通用的推理时缓解方法更有效。这凸显了针对毒性以外的多种结构的应用特定缓解方法的持续重要性,包括额外的微调、过滤不期望响应的专用机制、使用分类器分数的采样排序方法以及分类器在环控制解码。
尽管在大规模上对预训练数据进行系统性消融实验具有挑战性,但我们注意到在其他评估结果中没有明显的对齐代价或惩罚,可能是因为标注的预训练数据比例较小。
未来工作的一个有前景的领域是研究预训练干预措施,这些措施可以在通用下游适应阶段(例如指令微调)中增强可操控性能力,或者针对难以在下游缓解的潜在危害(例如泄露个人身份信息,以及对“越狱”提示方法的对抗性查询的鲁棒性)。这些方法可能实现类似的可控生成优势,同时提供更强的控制水平和更灵活的维度可控性。
5.2 对开发者的建议
我们建议开发者查阅负责任开发的指南和工具。关于语言模型使用中的伦理考量的更多讨论,请参见Chowdhery等人(2022)。我们注意到,尽管本文中对PaLM 2的评估提供了模型在用于构建下游系统时可能表现如何的信号,但特定应用的分析和潜在危害的评估至关重要。
所有下游开发者都应考虑其应用特定背景下的潜在危害和偏见(Shelby等,2023),特别是因为解码策略和提示的变化可能对生成的响应产生重大影响。虽然我们注意到对话提示在减少毒性生成方面的有效性,但我们强调这些结果可能无法推广到其他形式的代表性危害,或其他提示方法或使用场景。
我们还鼓励应用开发者考虑最近的研究,这些研究展示了新方法在更精确测量应用特定危害方面的潜力(Mozes等,2023;OpenAI,2023b)。
6. 结论
PaLM 2 是一个新的最先进模型,显著优于 PaLM,同时在推理时使用的计算量显著减少。PaLM 2 在广泛的不同任务上取得了进展,从英语和多语言语言理解到推理。通过 PaLM 2,我们独立验证了 Hoffmann 等(2022)的扩展定律;我们表明,训练标记应与模型参数的数量大致按相同比例增长。
我们还发现,改进架构和更多样化的模型目标在性能提升中很重要。最后,我们发现数据混合是最终模型的关键组成部分。在这个规模上,尽管翻译对只是混合数据的一小部分,但它使模型能够与生产翻译服务相媲美。因此,我们发现,与修改模型架构以提高推理效率相比,投入更多计算来训练更小的模型通常更有效。实际上,我们发现,对于固定的推理和训练预算,训练一个更小的模型并使用更多的标记通常更有效。
我们相信,随着模型参数和数据集大小及质量的进一步扩展,以及架构和目标的改进,语言理解和生成将继续取得进展。
7. 作者、归属和致谢
(此处省略作者、归属和致谢部分,因其为具体人名和团队信息,不影响技术内容的翻译。)
附录 A 详细结果
A.1 扩展定律
在这里,我们简要描述了用于构建图 4、图 5 和表 1 中扩展定律曲线的方法。遵循(Hoffmann 等,2022),我们通过训练具有不同参数和标记计数的模型,为四个计算规模(1×10^19、1×10^20、1×10^21 和 1×10^22 FLOPs)构建了等 FLOP 曲线。对于每个计算规模,我们对最终验证损失值进行二次曲线拟合,并插值最小值(如图 4 所示)。给定这四个最小参数计数的估计值,我们拟合了图 5 中所示的幂律曲线,以预测更大规模的最佳参数和标记计数。由于我们在这些实验中共享嵌入层和输出层之间的参数,我们使用总参数计数来估计总 FLOPs(如表 1 中的 6×N×D),但我们发现非嵌入参数计数(不包括输出层)在估计最佳参数计数时拟合得更好(例如图 4)。请注意,我们还能够通过“留一法”估计器对预测的误差条进行预测,通过仅使用 4 个点中的 3 个来估计扩展系数。
我们还评估了不同大小的模型在第 4.2 节中描述的下游任务上的表现,使用单一计算规模(1×10^22 FLOPs)。我们在表 15 中展示了结果。
A.2 指令微调
Flan 数据集(Chung 等,2022;Longpre 等,2023)包含超过 1,800 个任务,每个任务至少有 20 个指令模板(10 个零样本模板,10 个少样本模板)。在 Flan 数据集上进行微调提高了模型遵循指令的能力,并在未见任务上取得了更好的性能。我们采用了 Chung 等(2022);Longpre 等(2023)中描述的一般微调配方。我们在表 16 中展示了结果。我们观察到在 Chung 等(2022)中的评估基准上的一致改进。
A.3 多语言常识推理
我们评估了 PaLM 和 PaLM-2 在多语言常识推理数据集 XCOPA(Ponti 等,2020)上的表现。我们使用 Shi 等(2023)手动制作的 4-shot 提示重现了他们的结果,并报告了他们在使用链式思维提示(Wei 等,2022)时的结果,这导致了比标准提示设置更强的改进。
我们观察到,PaLM 2 在标准提示设置中显著优于 PaLM,并且在资源较少的语言(如斯瓦希里语、克丘亚语和海地语)上取得了特别显著的改进。此外,PaLM 2 在标准提示设置中的表现优于使用链式思维提示的 PaLM,展示了底层模型在多语言推理能力上的强大表现。
A.4 编码
我们在表 18 中展示了 BabelCode(Orlanski 等,2023)的原始 pass@1 结果。
A.5 自然语言生成
我们在表 19 中展示了每种语言的 NLG 结果。我们在表 20 中展示了过滤数据上的每种语言结果。
附录 B 模型能力示例
我们展示了展示 PaLM-2 能力的示例模型输出。大多数示例使用了经过指令微调的 PaLM-2 变体。
B.1 多语言性
解释笑话:PaLM(Chowdhery 等,2022)展示了用英语解释笑话的能力。我们展示了 PaLM 2 在多语言环境中展示笑话理解能力。我们在零样本设置中指示 PaLM 2,并在图 12 中提供了示例。
解释翻译歧义:PaLM 2 展示了更细致的翻译能力,并能够解释翻译背后的原理。在图 13 中,我们提供了 PaLM 2 纠正德语和斯瓦希里语中习语翻译的示例。在这两种情况下,PaLM 2 都能够解释潜在的含义并提供更合适的翻译。
翻译成方言:除了在不同语言之间翻译外,PaLM 2 还可以在不同方言之间进行转换。方言和地区变体在世界各地的语言中很常见,说话者通常根据社交环境在标准和方言形式之间切换。在第 4.5 节中,我们评估了 PaLM 2 在区域感知翻译上的表现。我们在图 14 中展示了在不同方言之间进行零样本翻译的示例。PaLM 2 能够正确识别方言特定术语,并用另一种语言变体中的等效术语替换它们。
扩展缩写和纠正拼写错误:我们展示了 PaLM 2 在多语言环境中使文本更符合语法的能力。我们在零样本设置中指示 PaLM 2 扩展缩写并纠正不同语言的文本。我们仅提供了一个简短的英语指令,并未指定目标语言。我们在图 15 中突出显示了示例。
将正式文本转换为口语聊天文本:文本的另一个方面是其语域或风格。说话者通常根据社交环境在不同语域之间切换。我们展示了 PaLM 2 在不同语言中的风格转换能力。我们指示 PaLM 2 将正式文本重写为聊天对话中使用的更非正式文本。我们提供了两个同语言示例,并未指定语言。我们在图 16 中展示了示例。
转写为新脚本:转写是指将一种书写系统中的语言转换为另一种书写系统的过程。许多语言使用多种书写系统,其中拉丁字母是世界上使用最广泛的书写系统(Daniels 和 Bright,1996;van Esch 等,2022)。我们在零样本设置中指示 PaLM 2 转写为拉丁字母。我们在图 17 中展示了示例。
B.2 创意生成
我们展示了不同语言中的创意生成能力示例。在图 18 中,我们要求 PaLM 2 基于亚美尼亚名称设计一个儿童游戏。PaLM 2 捕捉到了亚美尼亚名称中的提示,并生成了一个满足查询意图的现实设计。在图 19 中,我们要求 PaLM 2 用台湾话写一篇演讲。尽管台湾话在预训练数据中代表性不足,PaLM 2 仍然生成了一篇流利的演讲。在图 20 中,我们要求 PaLM 2 用德语和当地方言进行简单解释。尽管方言较少被书面使用,两种回答都适合目标受众,流利且自然。在图 21、22 和 23 中,我们要求 PaLM 2 用波斯语写一封电子邮件,并以不同方式修改它。在图 24 中,我们要求 PaLM 2 用塔吉克语写一篇论文,并将其翻译成波斯语。在图 25 中,我们要求 PaLM 2 生成一个 Thirukkural 或 Kural,这是泰米尔语中的一种短诗形式,由七个词组成。这些示例展示了 PaLM 2 能够以不同形式生成适当的文本,并根据不同标准在不同语言中进行修改。
B.3 编码
我们展示了 PaLM 2 编码能力的示例。在图 26 中,我们展示了 PaLM 2 设计一个简单网站的示例。PaLM 2 在多语言环境中也展示了编码能力。图 27 展示了 PaLM 2 用韩语逐行注释修复错误的示例。图 28 提供了一个示例,其中 PaLM 2 用马拉雅拉姆语生成一个函数和使用示例,并附带注释。



















 2762
2762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











