






这篇文章的核心内容是针对 Mamba 模型的量化研究,提出了一种名为 MambaQuant 的后训练量化(PTQ)框架。以下是文章的主要研究内容和贡献的凝练概括:
研究背景与动机
-
Mamba 是一种高效的序列模型,与 Transformer 相当,在处理长序列任务上表现出色,但其模型大小限制了在边缘设备上的应用。
-
量化是减少模型大小和计算延迟的有效手段,但在 Mamba 模型上的应用尚未得到充分探索。现有的量化方法(如 Hadamard 变换)在 Mamba 模型上效果不佳,主要原因是 Mamba 的数据分布具有显著的异常值和重尾特性,且其独特的并行扫描(PScan)操作进一步放大了这些异常值。
研究方法
文章提出了 MambaQuant,一个专为 Mamba 模型设计的后训练量化框架,通过以下两种核心方法解决量化中的方差不一致问题:
-
KLT 增强旋转(离线模式)
-
利用 Karhunen-Loève 变换(KLT)对 Hadamard 矩阵进行增强,使旋转矩阵能够适应不同通道的数据分布,从而平衡通道间的方差。
-
通过特征分解协方差矩阵,KLT 能够使数据在旋转后具有统一的方差,从而简化量化过程。
-
-
Smooth-Fused 旋转(在线模式)
-
在 Hadamard 变换前引入平滑操作,通过平滑参数统一通道方差。
-
平滑参数被巧妙地融合到模型权重中,避免了额外的内存和计算开销。
-
实验结果
-
视觉任务:在 ImageNet 和 UCF-101 数据集上,MambaQuant 在 W8A8(8 位权重和激活)配置下,量化后的准确率与浮点模型相比仅下降不到 1%;在 W4A8(4 位权重和 8 位激活)配置下,准确率下降约 1%。
-
语言任务:在多个标准语言任务数据集(如 ARC-E、ARC-C、PIQA 等)上,MambaQuant 在 W8A8 配置下几乎不损失准确率;在 W4A8 配置下,相比其他方法显著提高了准确率。
-
消融实验:验证了 KLT 增强旋转和平滑融合旋转的有效性。KLT 增强旋转显著优于直接的 Hadamard 旋转,而平滑融合旋转进一步提升了量化精度。
结论与贡献
-
MambaQuant 是首个针对 Mamba 模型的全面量化框架,能够有效解决 Mamba 模型在量化过程中的方差不一致问题。
-
该方法在视觉和语言任务上均优于现有量化方法,显著降低了量化带来的精度损失。
-
MambaQuant 为 Mamba 模型在资源受限环境中的部署提供了高效的解决方案,并为后续研究提供了新的方向。
代码开源
文章开源了相关代码,以促进 Mamba 模型量化领域的进一步研究和应用。
这篇文章的核心贡献在于提出了一种针对 Mamba 模型的量化框架,通过创新的旋转方法解决了量化过程中的关键挑战,为高效部署 Mamba 模型提供了新的思路。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
Mamba 是一种高效的序列模型,与 Transformer 竞争,并显示出作为各种任务基础架构的显著潜力。量化通常用于神经网络以减少模型大小和计算延迟。然而,对 Mamba 应用量化仍然未被充分研究,现有的量化方法(在 CNN 和 Transformer 模型中效果良好)似乎对 Mamba 模型并不适用(例如,Quarot 在 Vim-T<sup>†</sup> 上即使在 W8A8 下也遭受了 21% 的准确率下降)。我们率先探索了这一问题,并识别出几个关键挑战。首先,在门控投影、输出投影和矩阵乘法中存在显著的异常值。其次,Mamba 独特的并行扫描(PScan)进一步放大了这些异常值,导致数据分布不均匀且呈现重尾特性。第三,即使应用了 Hadamard 变换,权重和激活在通道间的方差仍然不一致。为此,我们提出了 MambaQuant,一个后训练量化(PTQ)框架,包括:1)Karhunen-Loève 变换(KLT)增强的旋转,使旋转矩阵能够适应不同的通道分布;2)Smooth-Fused 旋转,用于平衡通道方差,并可将额外参数合并到模型权重中。实验表明,MambaQuant 可以将权重和激活量化为 8 位,同时在基于 Mamba 的视觉和语言任务中准确率损失不到 1%。据我们所知,MambaQuant 是第一个针对 Mamba 系列的全面 PTQ 设计,为该领域的进一步发展铺平了道路。
1 引言
Mamba(Gu & Dao, 2023)是一种现代序列模型,能够与 Transformer(Vaswani et al., 2017)竞争,尤其是在处理极长序列方面表现出色。该模型的设计灵感来源于结构化状态空间模型(S4)(Gu et al., 2021),并整合了循环、卷积和连续时间模型的特性,以有效捕捉长期周期性依赖关系。在 S4 范式的基础上,Mamba 带来了多项显著改进,尤其是在处理时变操作方面。这些改进使得长数据序列的处理既高效又有效,使 Mamba 成为视觉(Zhu et al., 2024; Liu et al., 2024)、语言(Gu & Dao, 2023; Li et al., 2024)和多模态任务(Zhao et al., 2024)的有前途的基础架构。
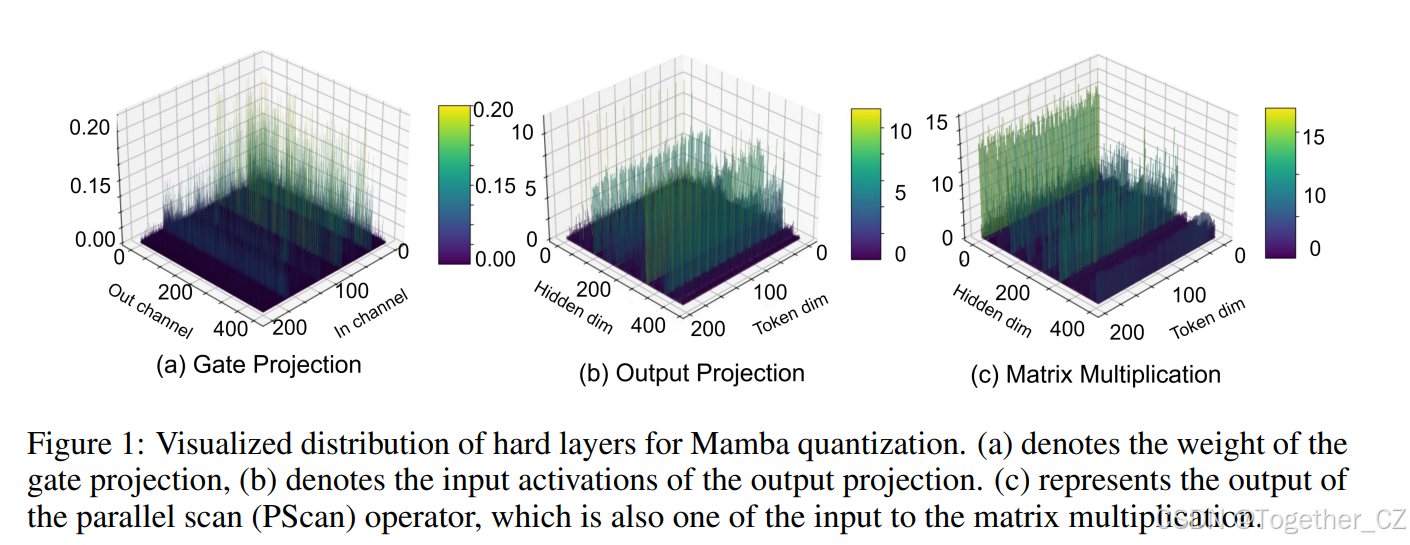
图 1:Mamba 量化中硬层的可视化分布。
(a) 表示门控投影的权重,(b) 表示输出投影的输入激活,(c) 表示并行扫描(PScan)操作的输出,这也是矩阵乘法的输入之一。
量化是将深度神经网络(DNNs)部署到计算资源有限且需要实时处理的环境中的关键技术。该过程涉及将神经网络的权重和激活从高精度(例如,32 位浮点数)转换为低精度(例如,8 位整数),以减少内存使用、计算负担和能耗。尽管量化已成功应用于卷积神经网络(Krishnamoorthi, 2018; Liu et al., 2023)和基于 Transformer 的大型语言模型(T-LLMs)(Du et al., 2024; Yuan, 2024),但在 Mamba 系列中的应用尚未得到系统分析或研究。
为了建立 Mamba 模型的全面量化方法,我们首先检查了涉及的潜在约束和挑战:❶ Mamba 模型的权重和激活中存在显著的异常值。我们在 Mamba-LLM(Gu & Dao, 2023)的语言任务的门控投影层(图 1(a))中观察到权重中存在异常值。我们还发现某些输入到线性层的激活在通道维度上表现出显著的方差,这在 Vim(Xu et al., 2024)的视觉任务的输出投影层(图 1(b))中尤为明显。❷ 并行扫描(PScan)进一步放大了激活中的异常值。为了在每个时间戳获得隐藏状态,PScan 操作符(Smith et al., 2022)会连续执行固定参数矩阵的自乘。在这种情况下,通道中值较高的部分会被放大,而值较低的部分则会被削弱。这种明显的数值差异直接扩展到激活(例如,图 1(c) 中的矩阵乘法的输入变量)。
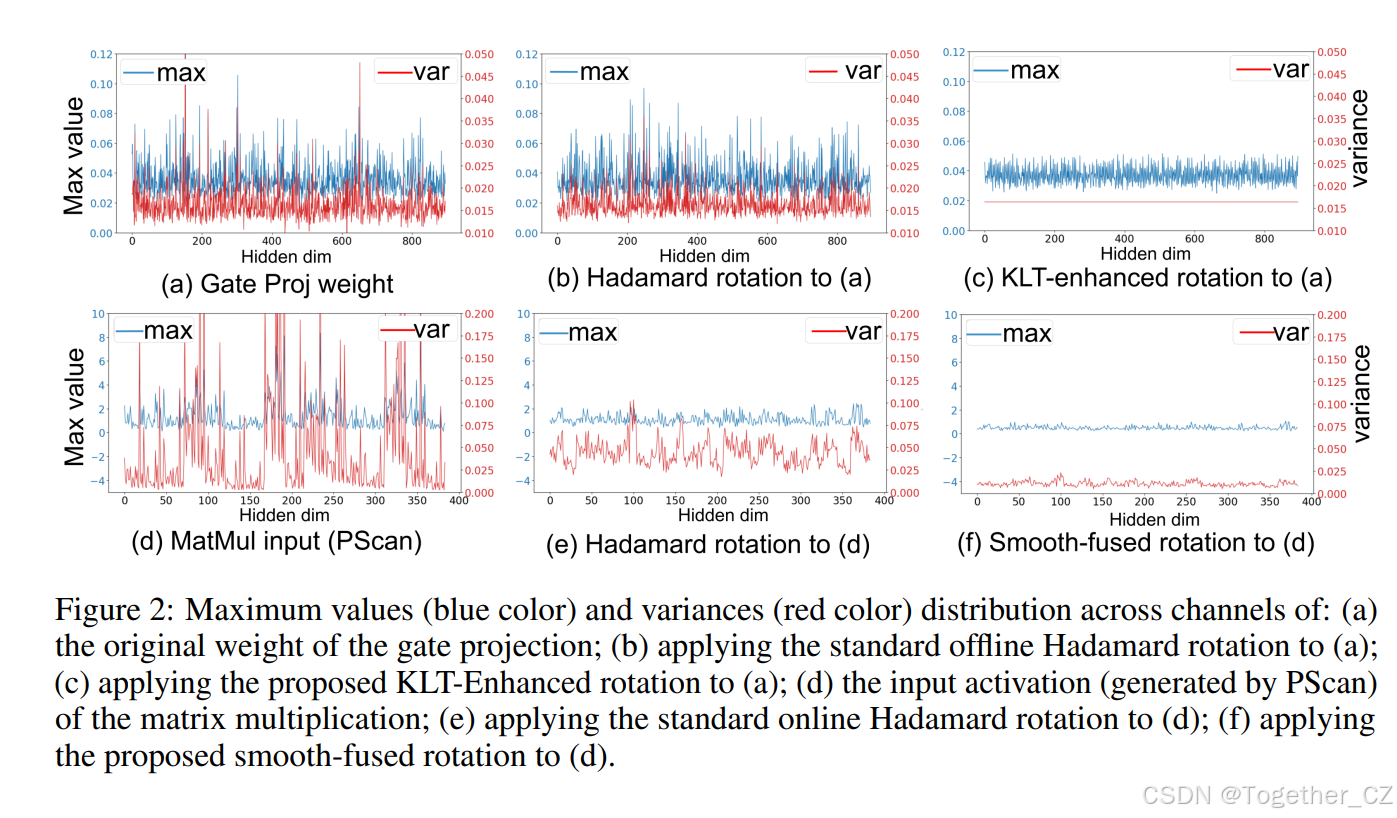
鉴于 Mamba 和 Transformer 都是具有全连接层的序列模型,需要进行量化,我们的初步解决方案是探索在 Transformer 基础大型语言模型(T-LLMs)中被证明有效的技术。最近,基于 Hadamard 的方法(Tseng et al., 2024)因其能够统一最大值和等效变换特性,在 T-LLMs 的量化中取得了显著成功。例如,QuaRot(Ashkboos et al., 2024b)将 LLAMA2-70B 量化到 4 位,保持了 99% 的零样本性能。然而,直接将这种方法应用于 Mamba 模型会导致显著的准确率下降(例如,在 Vim(Xu et al., 2024)上即使在 8 位下平均准确率也下降了超过 12%)。我们的分析表明,Hadamard 变换未能实现通道方差的对齐,如图 2(b)(e) 所示。不一致的方差不可避免地导致量化数据的数值分布不均匀,从而降低了准确率。
为了实现 Mamba 的量化,我们提出了 MambaQuant,这是一个针对 Mamba 模型的有效且高效的后训练量化(PTQ)框架。MambaQuant 的核心概念是解决 Hadamard 变换引起的通道方差不一致的问题,从而促进 Mamba 的量化。具体来说,MambaQuant 根据是否将旋转矩阵整合到权重中,考虑了两种不同的情况:离线模式(不整合)和在线模式(整合)。(1) 我们在离线模式中提出了 Karhunen-Loève 变换(KLT)增强的旋转。这种技术将 Hadamard 矩阵与 KLT 矩阵相乘,使旋转矩阵能够适应不同的通道分布。(2) 我们引入了在线模式中的 Smooth-Fused 旋转。这种方法在 Hadamard 变换之前进行平滑处理。额外的平滑参数灵活地整合到 Mamba 块的权重中,以避免额外的内存空间和推理步骤的成本。因此,量化数据的最大值和方差在通道维度上得到了充分的归一化(即,离线模式下它们是一致的,在线模式下它们是紧密对齐的,如图 2(c)(e) 所示)。
实验表明,MambaQuant 在不同 Mamba 模型系列的各种任务上均优于现有方法,包括 Vim(Zhu et al., 2024)和 Mamba-ND(Li et al., 2024)的视觉任务,以及 Mamba-LLM(Gu & Dao, 2023)的语言任务。MambaQuant 可以将权重和激活量化为 8 位,同时在所有模型中仅略有准确率下降(不到 1%)。此外,它可以将权重量化为 4 位,同时在视觉任务中仅略有准确率下降(约 1%),并且在语言任务中与现有方法相比实现了显著的准确率提升。最后,我们的贡献可以总结如下:
-
我们识别出 Mamba 在量化过程中主要面临挑战,即显著的异常值,这些异常值甚至被 PScan 进一步放大。我们的分析表明,Hadamard 变换由于通道方差不一致而无法有效解决这些问题。
-
我们提出了 MambaQuant。对于离线模式,我们引入了 KLT 增强旋转以平衡通道方差。对于在线模式,我们引入了 Smooth-Fused 旋转以归一化通道方差。离线和在线变换都可以在量化过程之前实现更均匀的分布。
-
据我们所知,MambaQuant 是第一个针对 Mamba 系列的全面 PTQ 框架。它可以高效地将权重和激活量化为 8 位,同时在基于 Mamba 的视觉和语言任务中准确率损失不到 1%。
-
作为 Mamba 系列量化领域的开创性研究,我们发布了代码,希望促进该领域的进一步研究并推动该领域的发展。
2 相关工作
Mamba 模型
Mamba(Gu & Dao, 2023)是一种选择性结构化状态空间模型,显著提高了状态空间模型(SSM)在处理序列数据方面的性能。它将结构化状态空间模型(S4)(Gu et al., 2021)中的参数转换为可学习的函数,并提出了并行扫描方法。通过克服卷积神经网络(CNNs)的局部感知限制和 Transformer(Vaswani et al., 2017)的二次计算复杂度,基于 Mamba 的网络(Xu et al., 2024)被广泛应用于各种任务。例如,原始 Mamba(Gu & Dao, 2023)在语言建模、音频生成和 DNA 序列预测方面表现出与 Transformer 相当的性能。Vision Mamba(Vim)(Zhu et al., 2024)首次将 Mamba 引入计算机视觉领域,采用双向 SSM 进行全局建模,并引入位置嵌入以实现位置感知理解。随后,VMamba(Liu et al., 2024)提出了交叉扫描模块,以解决方向敏感性挑战。LocalMamba(Huang et al., 2024)通过引入局部归纳偏差进一步提高了性能,而 PlainMamba(Huang et al., 2024)设计为非层次结构,以增强不同尺度之间的整合。Mamba-ND(Li et al., 2024)通过简单地交替序列顺序,有效地将 Mamba 扩展到包括图像和视频在内的多模态数据。尽管这些模型的计算需求降低且性能出色,但模型的较大尺寸仍然限制了它们在边缘设备上的应用。
量化方法
量化是一种有效的模型压缩技术。当前的方法可以分为量化感知训练(QAT)和后训练量化(PTQ)。由于 QAT 通常需要对所有参数进行训练,这对于大型模型来说是一个挑战,因此 PTQ 更受研究关注。PTQ 将预训练模型的全精度变量量化为低比特整数,从而减少内存消耗并提高推理速度。例如,在 Vision Transformer(Dosovitskiy, 2020)领域,FQ-ViT(Lin et al., 2021)首次引入了全面的量化方案,采用 2 的幂因子和 Log2 量化器用于层归一化和注意力映射。RepQ-ViT(Li et al., 2023)进一步解决了层归一化和 SoftMax 操作后激活的极端分布问题。在大型语言模型(LLMs)领域,GPTQ(Frantar et al., 2022)引入了一种基于近似二阶信息的逐层量化技术,将权重量化到 3-4 位,同时几乎不损失准确率。为了抑制激活中的异常值,SmoothQuant(Xiao et al., 2022)采用了平滑参数,将量化激活的难度转移到权重上。最近,QuaRot(Ashkboos et al., 2024b)采用了类似的方法,结合了 QuIP(Chee et al., 2024)中的旋转和 SliceGPT(Ashkboos et al., 2024a)中的计算不变性,将 PTQ 推向了一个新的水平。尽管这些方法在 Transformer 基础的大型语言模型中表现良好,但它们在 Mamba 模型中并不适用。据我们所知,我们的方法是第一个专门针对 Mamba 模型的 PTQ 解决方案,适用于基于 Mamba 的视觉和语言任务。
3 预备知识
3.1 状态空间模型

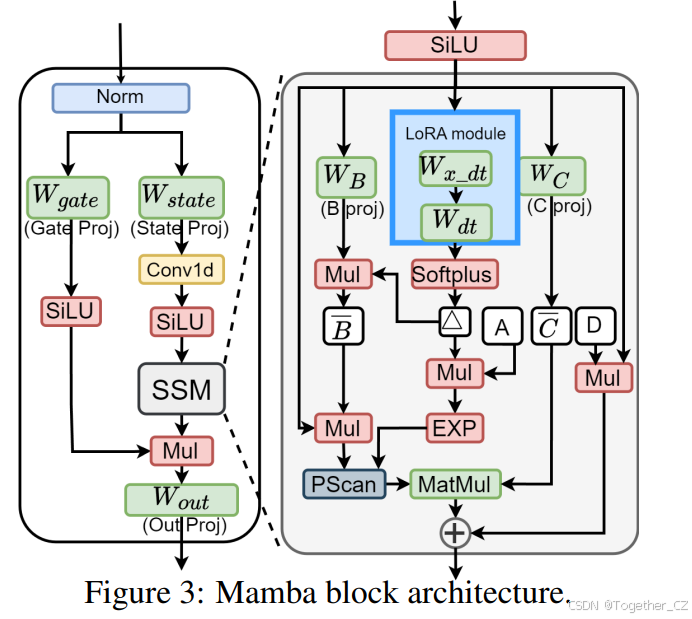
3.2 Mamba 架构
由于 LTI 系统的使用,模型参数保持不变,这在表示变化输入时会降低性能。为了解决这一问题,Mamba(Gu & Dao, 2023)提出了选择性 SSM(Gu et al., 2021)的实现,将部分参数定义为特定输入序列的函数:

3.3 量化
量化通常是为了从高精度变量(例如,16 位浮点数)获得低精度表示(例如,4 位整数)。对于要量化的张量 x,可以按照以下方式均匀量化为 b-位(Jacob et al., 2018):

4 方法
4.1 Hadamard 变换效果不佳
Hadamard 变换是一种有前途的 LLMs 量化方法,因其在处理异常值方面的有效性以及计算简单快速而受到认可。它通过与均匀分布的矩阵相乘,使每个通道的极值更加接近(Tseng et al., 2024)。此外,由于其正交性,Hadamard 矩阵可以很好地整合到模型权重中,同时确保计算的一致性。
Hadamard 矩阵是具有正交行和列的方阵,每个元素要么是 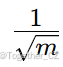 ,要么是 −
,要么是 −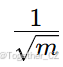 (m 是 Hadamard 矩阵的阶数)。通过与这样的均匀分布矩阵相乘,每个行对给定通道的贡献相对相等,从而使通道的极值更加接近。此外,由于其正交性,Hadamard 矩阵可以很好地整合到模型权重中,同时确保计算的一致性。
(m 是 Hadamard 矩阵的阶数)。通过与这样的均匀分布矩阵相乘,每个行对给定通道的贡献相对相等,从而使通道的极值更加接近。此外,由于其正交性,Hadamard 矩阵可以很好地整合到模型权重中,同时确保计算的一致性。
我们最初尝试将这种方法直接应用于 Mamba 模型,特别是门控投影、输出投影和矩阵乘法层。然而,Hadamard 变换在归一化 Mamba 架构中具有显著异常值的硬层(如图 1 所示)方面并不足够有效,如图 2(b)(e) 所示。
为了深入分析这一问题,我们发现 Hadamard 变换未能有效对齐量化变量的通道方差,从而忽略了不同通道之间的分布一致性。具体来说,给定一个均值为零的矩阵 X(权重或激活),其维度为 n×m,以及一个 Hadamard 变换矩阵 H,维度为 m×m,变换后的矩阵 XH 的协方差矩阵 CXH 可以表示为:

因此,尽管 Hadamard 变换在处理异常值方面表现出色,但由于其无法对齐通道方差,导致在 Mamba 模型的量化中效果不佳。
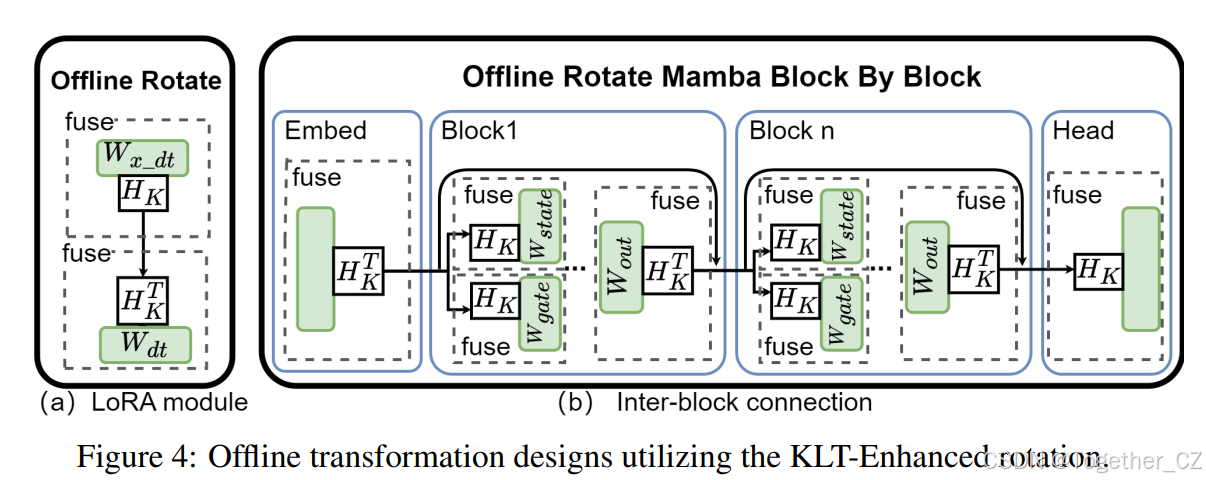
4.2 离线变换中的 KLT 增强旋转
为了克服第 4.1 节中提到的限制,我们引入了 Karhunen-Loève 变换(KLT)(Dony et al., 2001)来平衡通道方差。KLT 能够识别数据中的主成分,并将数据投影到这些成分上,通过关注最大方差的方向来保留最关键的信息。实际上,Mamba 权重和激活的每个通道的均值通常接近于零,满足 KLT 的适用条件。具体来说,我们通过对校准数据的协方差矩阵 CX 进行特征分解来应用 KLT:

通过这种方式,每个通道的方差变得相同,从而简化了量化过程。这种变换不仅平衡了不同通道之间的方差,还保留了 Hadamard 矩阵的独特性质,即其平衡最大值的能力。我们还在附录 A.4 中提供了详细的步骤,以实现 KLT 旋转后接 Hadamard 旋转的方差平衡公式。实际上,KLT 是通过使用校准数据离线完成的,以避免额外的计算成本,但它可以很好地泛化到更广泛的输入(详细内容见附录 A.7)。
为了应用这种 KLT 增强的旋转矩阵,我们修改了 QuaRot(Ashkboos et al., 2024b)中的离线变换,以适应 Mamba 结构。如图 4 所示,我们在 LoRA 模块和块间连接(输出投影、门控投影和状态投影被变换的地方)中采用了这种策略。
4.3 在线变换中的 Smooth-Fused 旋转
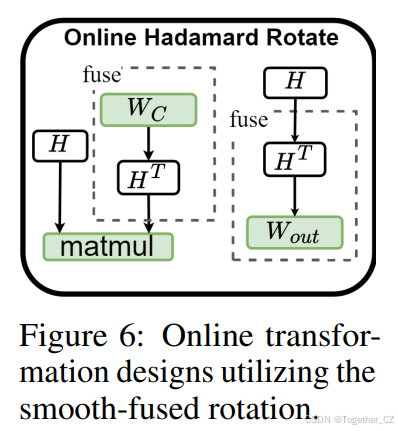
为了缓解第 4.1 节中讨论的 Hadamard 旋转的不足,我们在执行旋转之前引入了平滑技术。采用这种方法的动机是通过平滑向量来统一通道方差。通常,平滑因子可以吸收进邻近层中,用于 T-LLMs 的量化(Xiao et al., 2022; Shao et al., 2023)。这种操作有效地避免了因引入额外参数而产生的额外内存分配和计算开销的需求。然而,这种方法并不适用于 Mamba 模块,因为存在非线性的 SiLU 操作和 PScan 的复杂循环结构。因此,我们针对输出投影和矩阵乘法分别提出了两种不同的设计。
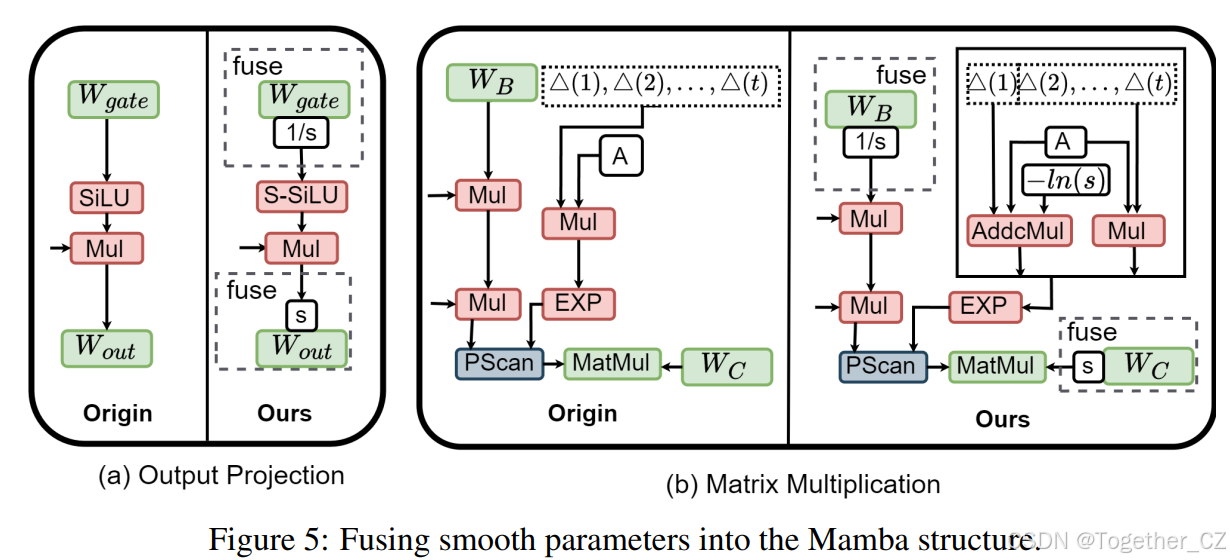
对于输出投影层:我们改进了传统的 SiLU 激活函数,采用 Smooth SiLU(S-SiLU)(Hu et al., 2024)以满足平滑融合量化的需要:


5 实验
模型和数据集。我们通过三个代表性的基于 Mamba 的应用来评估我们提出的 MambaQuant 框架的量化能力:Mamba(Gu & Dao, 2023)、Vim(Zhu et al., 2024)和 Mamba-ND(Li et al., 2024)。我们在视觉和语言任务上评估了量化 Mamba 模型的性能。对于视觉任务,我们在图像分类数据集 ImageNet(Russakovsky et al., 2015)和视频分类数据集 UCF-101(Soomro et al., 2012)上进行了测试。在语言领域,我们在五个标准数据集上进行了评估:ARC-E(Boratko et al., 2018)、ARC-C(Clark et al., 2018)、PIQA(Bisk et al., 2020)、Winogrande(Sakaguchi et al., 2021)和 HellaSwag(Zellers et al., 2019),并报告了这些数据集上的平均性能。我们使用准确率(Acc)作为评估测试结果的指标。
基线和实现细节。为了进行比较,我们对 Mamba 模型应用了不同的量化设置,并报告了在两种配置下的性能:W8A8(8 位权重和激活)和 W4A8(4 位权重和 8 位激活)。此外,我们将我们的方法与不同的量化方法进行了比较,包括最近邻舍入(RTN)方法、SmoothQuant(Xiao et al., 2022)、GPTQ(Frantar et al., 2022)用于权重和 RTN 用于激活(GPTQ+RTN),以及 QuaRot(Ashkboos et al., 2024b)。对于视觉任务,我们采用了静态量化方法。图像分类的校准数据是从 ImageNet(Russakovsky et al., 2015)测试集中随机采样的 128 张图像,而视频分类的校准数据则来自 UCF-101(Soomro et al., 2012)测试集。相比之下,对于语言任务,我们采用了动态量化,以更好地适应推理期间变化的输入结构。
5.1 总体结果
表 1:不同量化设置下视觉 Mamba 模型的比较结果。 Vim 模型和 Mamba-2d 模型在 ImageNet 上进行测试,Mamba-3d 模型在 UCF-101 上进行测试。† 表示在 Vim 上微调的模型。‡ 表示基于官方权重的结果。
| 视觉 Mamba | Mamba-ND | 位宽 | 方法 | Vim-T | Vim-T† | Vim-S | Vim-S† | Vim-B | mamba-2d S | Mamba-2d B | Mamba-3d |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FP16 | 76.1 | 78.3 | 80.5 | 81.6 | 80.3‡ | 81.7 | 83.0 | 89.6 | |||
| RTN | 37.4 | 32.4 | 68.8 | 68.8 | 52.2 | 80.3 | 82.2 | 87.9 | |||
| GPTQ+RTN | 37.7 | 32.5 | 68.9 | 70.5 | 52.2 | 80.4 | 82.2 | 87.8 | |||
| SmoothQuant | 37.7 | 32.3 | 68.7 | 72.9 | 52.1 | 80.3 | 82.2 | 87.9 | |||
| QuaRot | 59.3 | 57.4 | 73.8 | 75.5 | 73.8 | 80.8 | 82.3 | 88.0 | |||
| W8A8 | 我们的 | 75.6 | 77.8 | 80.3 | 81.4 | 80.1 | 81.2 | 82.8 | 89.0 | ||
| RTN | 26.3 | 25.0 | 66.1 | 70.0 | 46.2 | 40.6 | 78.8 | 86.1 | |||
| GPTQ+RTN | 30.4 | 27.9 | 66.5 | 70.6 | 47.7 | 60.3 | 78.9 | 86.8 | |||
| SmoothQuant | 27.0 | 26.0 | 66.4 | 70.2 | 46.7 | 59.7 | 80.2 | 86.9 | |||
| QuaRot | 52.7 | 48.5 | 72 | 74.0 | 72.8 | 80.1 | 82.0 | 86.9 | |||
| W4A8 | 我们的 | 72.1 | 73.7 | 79.4 | 80.4 | 79.8 | 80.4 | 81.9 | 88.4 |
视觉模型性能比较
表 1 展示了不同量化设置下各种 Mamba 视觉模型的结果,包括 Vision Mamba 和 Mamba-ND。评估的量化配置包括 W8A8(8 位权重和激活)和 W4A8(4 位权重和 8 位激活)。表中比较了多种量化方法的性能,包括 RTN、GPTQ+RTN、SmoothQuant、QuaRot 和我们提出的方法(“我们的”)。我们的方法在不同 Mamba 模型变体上均优于基线技术。在 W8A8 配置下,我们的方法的性能与浮点基线准确率相差不到 1 个百分点。在更严格的 W4A8 设置下,我们的方法显著优于其他竞争方法,这些方法的准确率下降更为明显。这些结果表明,我们的方法在量化设置下为 Vim 和 Mamba-ND 模型提供了更强大的解决方案。这些结果表明,我们的方法在减少精度方面更具弹性,为部署 Mamba 模型提供了一种实用且有效的量化解决方案。
语言模型性能比较
表 2 展示了 Mamba 模型在语言任务上的量化结果。评估的模型范围从 Mamba-370m 到 Mamba-2.8b。表中比较了不同模型大小下几种量化方法的准确率,包括 RTN、GPTQ+RTN、SmoothQuant、QuaRot 和我们的方法。在更具挑战性的 W4A8 配置下,我们的方法始终显著优于基线技术,平均准确率提升显著。这些结果表明,我们的量化方法在语言模型任务中具有鲁棒性和效率。所有实验结果均在附录 A.6 中提供。
5.2 消融研究
表 3:KLT 增强旋转的消融实验。
| 位宽 | 方法 | Vim-T† | Mamba-790m | 位宽 | 方法 | Vim-T† | Mamba-790m |
|---|---|---|---|---|---|---|---|
| FP16 | 78.3 | 54.8 | FP16 | 78.3 | 54.8 | ||
| 基线 (RTN) | 32.4 | 44.2 | 基线 (RTN) | 25.0 | 35.4 | ||
| Hadamard 旋转 | 33.9 (+1.5) | 50.8 (+6.6) | Hadamard 旋转 | 25.1 (+0.1) | 40.2 (+4.8) | ||
| W8A8 | W4A8 | ||||||
| KLT-增强旋转 | 47.7 (+15.3) | 51.3 (+7.1) | KLT-增强旋转 | 38.9 (+3.9) | 42.3 (+6.9) |
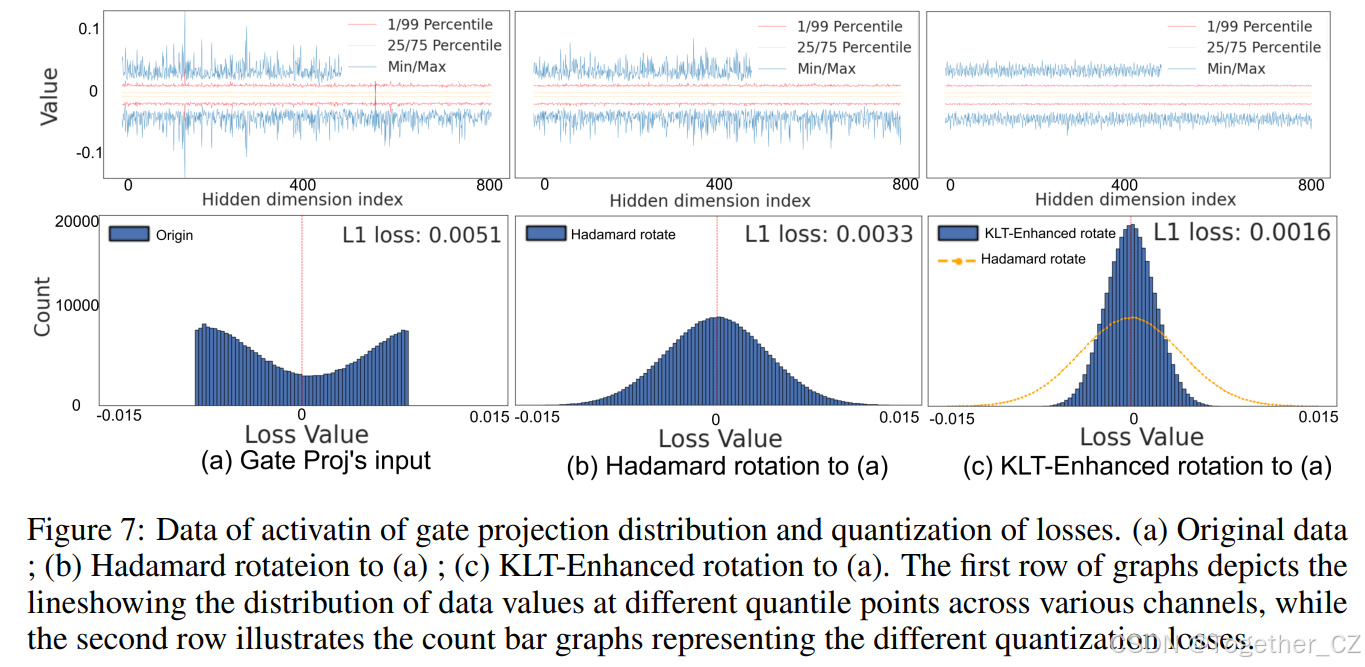
图 7:门控投影数据的激活分布和量化损失。
(a) 原始数据;(b) Hadamard 旋转后的数据;(c) KLT 增强旋转后的数据。第一行的图表显示了不同通道在各个分位点的数据值分布,第二行的柱状图表示 4 位 per-tensor 方法的量化损失分布。在柱状图中,横轴表示量化损失的大小,纵轴表示数据点的计数。子图 (a)、(b) 和 (c) 分别显示了原始数据、Hadamard 旋转数据和 KLT 增强旋转数据的量化损失。与仅使用 Hadamard 旋转相比,我们的方法在平滑量化和减少通道间的量化损失方面表现更好。此外,我们的方法将量化损失的 L1 范数减少了近一半。
表 4:Smooth-Fused 旋转的消融实验。
| 位宽 | 方法 | Vim-T† | Mamba-790m | 位宽 | 方法 | Vim-T† | Mamba-790m |
|---|---|---|---|---|---|---|---|
| FP16 | 78.3 | 54.6 | FP16 | 78.3 | 58.6 | ||
| 基线 (KLT-增强旋转) | 47.7 | 51.3 | 基线 (KLT-增强旋转) | 38.9 | 42.3 | ||
| Hadamard 旋转 | 69.7 (+22.0) | 51.8 (+0.5) | Hadamard 旋转 | 62.0 (+23.1) | 43.0 (+0.7) | ||
| W8A8 | W4A8 | ||||||
| Smooth-Fused 旋转 | 77.8 (+30.1) | 53.3 (+2.0) | Smooth-Fused 旋转 | 73.7 (+34.8) | 45.8 (+3.5) |
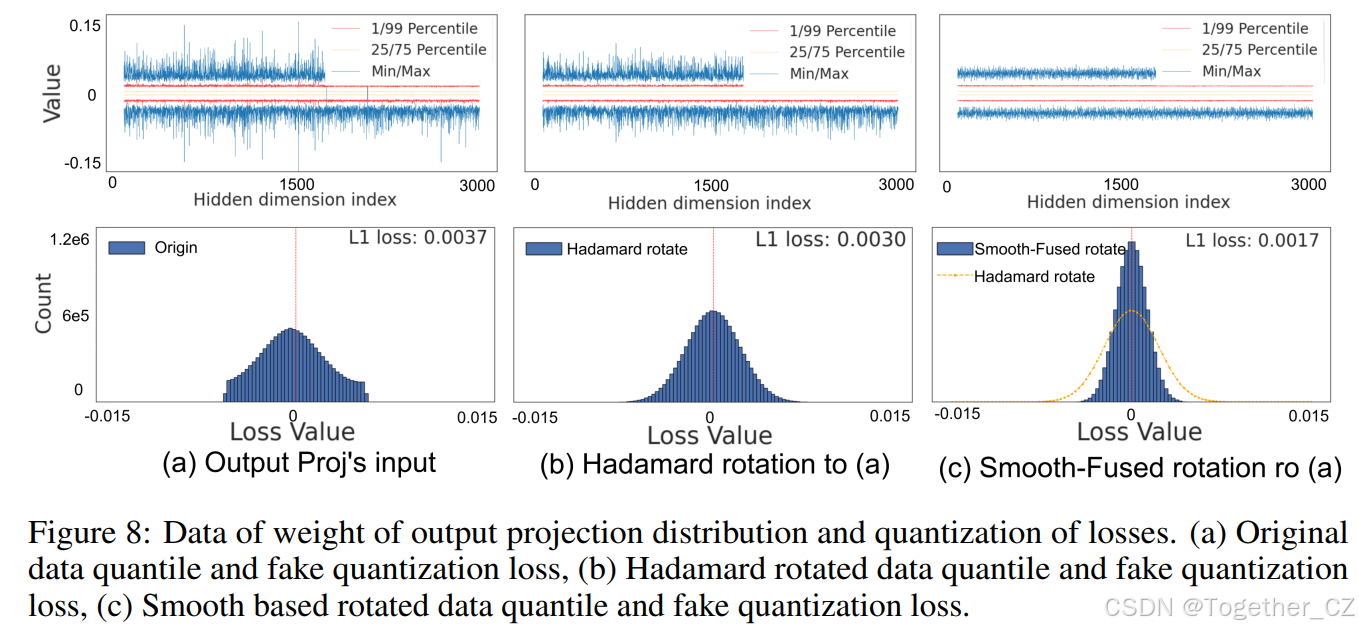
图 8:输出投影权重的数据分布和量化损失。
(a) 原始数据的分位数和假量化损失;(b) Hadamard 旋转后的数据分位数和假量化损失;(c) 基于平滑的旋转数据分位数和假量化损失。
表 3 表明,尽管我们提出的 KLT 增强旋转在提高量化精度方面非常有效,但与浮点精度相比仍存在差距。 我们随后应用了第 4.3 节中描述的方法,专注于敏感的 matmul 和输出投影层。表 4 中的消融结果比较了直接使用在线 Hadamard 旋转和平滑融合旋转的效果。我们发现,平滑融合旋转可以显著提高量化精度。在 W4A8 量化配置下,Vim T† 模型中,平滑融合旋转方法的准确率比直接使用在线 Hadamard 旋转方法高出 11.7%。
内存占用和计算成本
在第 4.3 节中,我们引入了平滑尺度参数来优化量化过程,由于每个量化通道仅用一个标量表示,因此对整体模型大小的影响微乎其微。此外,该方法引入了在线 Hadamard 旋转技术(Ashkboos et al., 2024b),其计算速度类似于快速傅里叶变换(FFT),对推理速度的影响极小。以 Mamba-2.8B 模型为例,平滑尺度仅增加了 329k 参数,对于长度为 1024 的标记序列,计算量增加了 25.6 GFLOPs,而基线为 2.8 TFLOPs。这相当于参数大小增加了 0.01%,计算成本增加了 0.91%。
6 结论
在本文中,我们专注于将量化技术引入 Mamba 模型领域。首先,我们发现 Mamba 的门控投影、输出投影和矩阵乘法中存在显著的异常值,而独特的 PScan 操作进一步放大了这些数值差异。其次,我们发现广泛应用于 Transformer 量化的 Hadamard 变换方法在量化这些硬层时表现不佳。我们的分析表明,这种方法未能充分对齐通道方差,从而导致数据分布不均匀,给量化过程带来挑战。为了克服这一限制,我们提出了 MambaQuant,这是一个专为 Mamba 模型设计的全面后训练量化框架。该策略的核心思想是通过使 Hadamard 变换能够均匀化每个通道的方差来增强 Mamba 的量化性能。具体而言,我们引入了 Karhunen-Loève 变换,使旋转矩阵能够适应不同的通道分布。我们还引入了一种平滑方法来统一通道方差,同时将额外的参数融合到模型权重中,以避免额外的开销。我们的 MambaQuant 方法在基于 Mamba 的视觉和语言任务中均优于现有方法,使 Mamba 模型更适合在资源受限的环境中部署。作为 Mamba 系列量化领域的开创性研究,我们发布了代码,希望促进该领域的进一步研究并推动该领域的发展。



















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











