






论文提出了一种名为FlightVGM的FPGA加速器,专门用于高效推理视频生成模型(VGM)。FlightVGM通过在线稀疏化和混合精度计算,显著提升了VGM在FPGA上的性能和能效,超越了现有的GPU和FPGA加速器。以下是文章的核心内容总结:
研究背景
-
视频生成模型(VGM):VGM是一种多模态大模型,能够根据提示生成高质量视频。然而,由于其采用扩散变换器(DiT)结构,计算密集度高,导致在通用硬件(如GPU)上效率低下。
-
稀疏化和混合精度:稀疏化和混合精度是加速计算密集型模型的常用方法,但在FPGA上实现高效的稀疏VGM加速仍面临挑战,包括激活冗余、DSP性能不足以及在线压缩的低利用率。
FlightVGM的核心贡献
-
时空在线激活稀疏化架构
-
提出了一种时空稀疏化方法,利用视频帧在时间和空间维度上的相似性,动态减少冗余计算。
-
通过稀疏化单元(SU)和恢复单元(RU),实现了低开销的在线稀疏化和激活恢复,将计算成本降低了3.17倍。
-
-
混合精度DSP58扩展架构
-
针对FPGA的DSP58单元,设计了一种浮点-定点混合精度架构(DSP-E),支持FP16和INT8计算。
-
通过优化DSP资源分配,将峰值计算性能(PCP)提高了3.26倍,解决了现有FPGA在混合精度下性能不足的问题。
-
-
动态-静态自适应调度方法
-
提出了一种结合动态和静态调度的自适应调度方法,根据实际工作负载调整操作执行顺序。
-
通过权重预加载和优先级调度机制,将计算利用率提高了2.75倍,显著减少了在线稀疏化带来的开销。
-
实验结果
-
性能提升:在AMD V80 FPGA上实现后,FlightVGM在多个稀疏VGM工作负载上的性能超过了NVIDIA 3090 GPU的1.30倍,能效提高了4.49倍。
-
与SOTA加速器对比:与现有的基于Transformer的FPGA加速器(如HiSpMV和FlightLLM)相比,FlightVGM在性能和能效上分别实现了7.69倍和3.52倍的提升。
-
模型准确性:在混合精度和激活稀疏化优化下,FlightVGM的模型准确性与原始模型几乎相同,平均损失仅为0.008。
结论
FlightVGM通过在线稀疏化和混合精度计算,成功解决了FPGA加速VGM时面临的性能瓶颈,实现了比GPU更高的吞吐量和能效。该研究为未来在FPGA上加速计算密集型多模态模型提供了新的思路和技术路径。
创新点和意义
-
首次针对VGM的FPGA加速器:FlightVGM是首个专门针对视频生成模型的FPGA加速器,填补了这一领域的空白。
-
高效利用硬件资源:通过时空稀疏化和混合精度设计,充分利用了FPGA的硬件资源,显著提升了计算效率。
-
动态调度机制:提出的动态-静态自适应调度方法有效解决了在线稀疏化带来的调度挑战,提高了计算利用率,具有广泛的适用性。
以上是本文的核心内容总结,展示了FlightVGM在加速视频生成模型方面的创新性和高效性。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要: 视频生成模型(VGM)作为多模态大模型的代表,彻底改变了视频内容创作的生产力。由于采用了扩散变换器(即DiT)结构,VGMs是计算密集型的。稀疏化是加速计算密集型模型的常用方法,但稀疏化的VGMs无法充分利用GPU的有效吞吐量(即TOPS 1)。FPGAs是加速稀疏深度学习模型的良好候选,但现有的FPGA加速器在VGMs上仍然面临低吞吐量(<2TOPS)的问题,与GPU的峰值计算性能(PCP)(>21×)存在显著差距。为了实现比GPU更高的吞吐量,FPGA加速稀疏VGMs仍然面临以下挑战:激活中的大量冗余、混合精度下DSP的低性能以及静态编译用于在线压缩的低利用率。为解决这些挑战,我们提出了FlightVGM,这是第一个用于高效VGM推理的FPGA加速器,具有激活稀疏化和混合精度。在FlightVGM中,我们的动机源于VGMs在不同维度和层中表现出不同的压缩偏好。为了利用视频帧在时间和空间维度上的相似性,我们提出了一个时空在线激活稀疏化架构,将计算成本降低了3.17倍。为了在VGMs的准确性和效率之间提供良好的权衡,我们在线性层中使用定点精度,并保留浮点精度用于注意力层。然后,我们在AMD V80 FPGA上提出了一个浮点-定点混合精度DSP58扩展架构,将PCP提高了3.26倍。最后,为了使FlightVGM能够适应各种工作负载,我们提出了一个动态-静态结合的自适应调度方法,用于低开销在线稀疏化,将计算利用率提高了2.75倍。在AMD V80 FPGA上实现后,FlightVGM在各种稀疏VGM工作负载上的性能超过了NVIDIA 3090 GPU的1.30倍,能效提高了4.49倍。
CCS概念: • 硬件 → 硬件加速器;
• 计算机系统组织 → 可重构计算。
关键词: 视频生成模型,FPGA,加速
ACM参考格式: Jun Liu, Shulin Zeng, Li Ding, Widyadewi Soedarmadji, Hao Zhou, Zehao Wang, Jinhao Li, Jintao Li, Yadong Dai, Kairui Wen, Shan He, Yaqi Sun, Yu Wang, and Guohao Dai. 2025. FlightVGM: Efficient Video Generation Model Inference with Online Sparsification and Hybrid Precision on FPGAs. In Proceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays (FPGA '25), February 27-March 1, 2025, Monterey, CA, USA. ACM, New York, NY, USA, 12 pages. FlightVGM: Efficient Video Generation Model Inference with Online Sparsification and Hybrid Precision on FPGAs | Proceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays
1. 引言
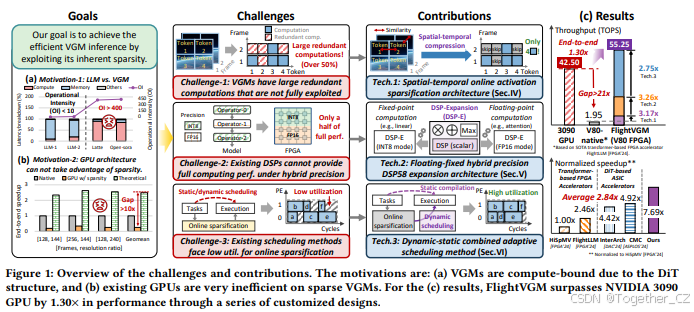
最近,视频生成模型(VGMs)在人工智能生成内容(AIGC)领域受到了广泛关注。继大型语言模型(LLMs)出现之后,VGMs被视为通往通用人工智能(AGI)道路上的第二个里程碑。VGMs可以根据适当的提示为用户提供满足其需求的创意视频。OpenAI于2024年2月发布的Sora模型是第一个能够生成一分钟高保真视频的VGM模型。谷歌、字节跳动和快手等科技公司也分别推出了包括Veo、Dreamina、Kling等在内的一系列VGMs。主流VGMs基于扩散变换器(即DiT)结构开发,随着数据量的增加,其能力也越强。与基于变换器的LLMs的内存密集型特性不同,基于DiT的VGMs是计算密集型的。这是因为DiT结构引入了多个计算密集型操作。例如,DiT中的线性层(包括QKVO投影和前馈网络FFN)有一个额外的批次维度。如图2所示,一个DiT块包括一个时间变换器和一个空间变换器。前者探索视频中不同帧之间的关系,而后者探索同一帧中不同块之间的关系。对于空间/时间变换器,时间/空间维度被视为批次,大小在数十到数百之间。图1(a)显示,VGMs的操作强度(即FLOPs/Byte)是LLMs的40倍以上。稀疏化被广泛用于加速计算密集型深度学习模型,但稀疏化的VGMs难以充分利用GPU的性能(即TOPS)。由于激活中的内在相似性,VGMs在激活中存在显著的冗余,这些冗余在时间和空间维度上同时存在。GPU采用单指令多线程(SIMT)架构,因此适合高度并行化的场景。然而,激活中的稀疏性引入了不规则的内存访问和同步处理,导致GPU上的开销不可忽视。图1(b)显示,在VGMs的不同视频尺寸下,NVIDIA 3090 GPU的实际加速与理论加速之间存在高达10倍的差距。FPGAs是加速稀疏深度学习模型的良好候选。然而,由于峰值计算性能(PCP)的显著差异,FPGA的吞吐量与GPU之间仍然存在较大差距。以最新的AMD V80 FPGA为例,它仅提供6.5TOPS的FP16 PCP,而NVIDIA 3090 GPU提供142TOPS的FP16 PCP。我们在V80 FPGA上评估了最先进的(SOTA)基于变换器的FPGA加速器(即FlightLLM),其吞吐量为<2TOPS,FP16 PCP为6.5TOPS。图1(c)显示,FlightLLM的吞吐量与NVIDIA 3090 GPU(~43TOPS)之间存在>21倍的差距。为了充分发挥FPGA加速稀疏VGMs的潜力,仍需解决以下挑战:
挑战1: VGMs存在大量未充分利用的冗余计算。激活的相似性同时存在于时间和空间维度中。然而,现有的SOTA基于DiT的加速器仅利用了VGMs中的一部分相似性(即时间或空间),导致稀疏度低于46.44%。图1(b)显示,在如此低的稀疏度下运行时,GPU上稀疏VGMs的吞吐量甚至比密集VGMs更差。
挑战2: DSP基础处理引擎在混合精度下无法提供完整的计算性能。VGM的不同层对计算精度的敏感性不同。例如,VGMs倾向于在线性操作中使用INT8,在注意力图操作中使用FP16。然而,AMD V80 FPGA上的DSP58只能配置为FP16或INT8模式,从而导致固定-浮点分离的处理引擎(PE)设计,严重浪费资源。
挑战3: 现有的调度方法在在线稀疏化方面面临低计算利用率。现有的调度方法包括静态调度和动态调度。静态调度方法依赖于离线操作延迟预测,而在线稀疏化中无法获得。动态调度方法由于FPGA上嵌入式CPU的性能有限以及稀疏DiT结构的复杂性,会带来不可接受的额外开销。由于VGMs中的冗余存在于不断变化的视频中,现有的调度方法无法高效处理运行时动态变化的稀疏激活,导致稀疏VGMs的计算利用率低下。
为解决这些挑战,我们提出了FlightVGM,这是一个基于FPGA的加速器,用于高效的VGM推理,具有在线稀疏化和混合精度,且不会降低视频质量。本文的主要贡献总结如下:
-
据我们所知,这是第一个加速视频生成模型的FPGA加速器,其性能和能效均超过了GPU。
-
我们提出了一个时空在线激活稀疏化架构,用于挑战1。FlightVGM引入了定制的稀疏化和恢复单元,以利用时空相似性动态修剪激活,与原始VGMs相比,将开销降低了3.17倍。
-
我们提出了一个浮点-定点混合精度DSP58扩展架构,用于挑战2。在AMD V80 FPGA上实现的FlightVGM,针对INT8/FP16量化的VGMs,将PCP提高了3.26倍,超过了仅使用FP16的DSP原生设计。
-
我们提出了一个动态-静态结合的自适应调度方法,用于挑战3。通过引入权重预加载和基于优先级的调度机制,FlightVGM将整体利用率提高了2.75倍,与现有的静态和动态调度方法相比,调度开销可以忽略不计。我们在多个VGMs(Latte-1和Open-Sora 1.2)上的结果表明,与NVIDIA 3090 GPU相比,FlightVGM在性能上提高了1.30倍,在能效上提高了4.49倍。FlightVGM进一步实现了与SOTA定制加速器相比平均2.84倍的性能提升。
2. 背景和观察
2.1 基础知识
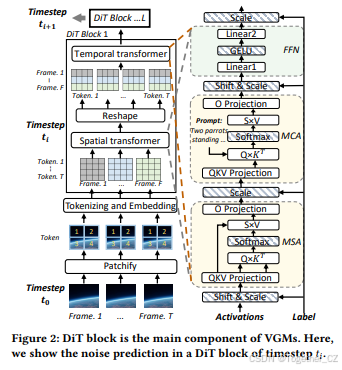
扩散模型可以将噪声帧恢复为由特定提示描述的清晰帧,通过在多个时间步内逐步预测高斯噪声并去噪。当前先进的VGMs大多使用**扩散变换器(DiT)**作为骨干网络来实现噪声预测,这是因为DiT结构在生成长时长和高分辨率视频方面具有很强的可扩展性。VGMs主要由许多级联的DiT块组成,每个块包括一个空间变换器和一个时间变换器。空间和时间变换器都有三种主要网络:多头自注意力(MSA)、多头交叉注意力(MCA)和前馈网络(FFN)。如图2所示,我们以Open-Sora 1.2模型为例

2.2 基于DiT的VGM压缩方法
2.2.1 激活稀疏化
最近的研究主要关注视频理解,但未能充分利用视频生成中的相似性。InterArch提出了一种粗粒度的帧间稀疏化方法,用于减少冗余信息。CMC提出了一种利用GPU视频处理单元CODEC预测帧间冗余信息的方法。然而,InterArch和CMC主要从单一的时间维度压缩计算,因此对VGMs的加速有限。
2.2.2 混合精度量化
由于在模型准确性和成本节省之间取得了良好的平衡,几项研究对基于DiT的VGMs进行了混合精度量化。例如,ViDiT-Q方法在DiT块内实现了INT8精度,同时将注意力图计算和其他模块保持在FP16精度。ViDiT-Q采用对称均匀方法进行INT8量化。然而,当前的混合精度量化方法在FPGA上效果不佳。这是因为FPGA的DSP只能在运行时配置为FP16或INT8精度。因此,这种限制导致在FPGA上直接部署混合精度量化方法时PCP降低。例如,支持混合精度的V80 FPGA的INT8 PCP仅为其最大硬件PCP的66.67%(因为1/3的DSP被配置为浮点单元)。
3. 设计方法概述
3.1 FlightVGM概述
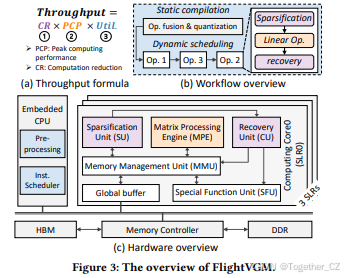
FlightVGM的目标是在FPGA上实现高效VGM推理的高吞吐量。我们旨在通过全栈解决方案优化计算减少(CR)、峰值计算性能(PCP)和计算利用率(Util.),如图3(a)所示的吞吐量公式所指导。具体而言:
(1) 减少计算成本:FlightVGM通过利用时空相似性动态修剪激活(图中紫色部分的定制稀疏化单元和恢复单元),以实现低开销的在线稀疏化。
(2) 提升PCP:FlightVGM在矩阵处理引擎(图中橙色部分)中实现了浮点-定点混合精度DSP58扩展架构(第5节详细介绍),为VGMs中的INT8和FP16计算提供了足够的性能。
(3) 提高计算利用率:FlightVGM采用了两级稀疏感知调度(第6节详细介绍,图中蓝色部分)。静态编译实现了操作融合和权重量化,而动态调度则根据稀疏化结果调整操作的执行顺序,以最大化利用率。
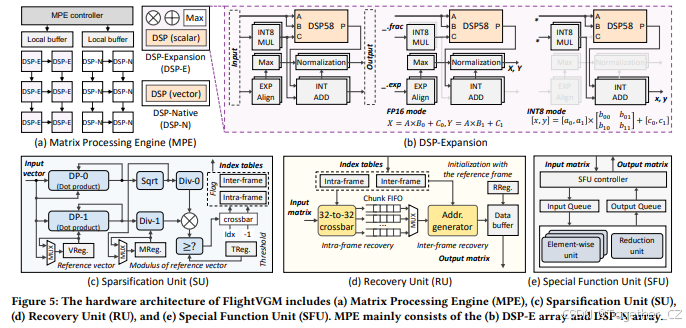
3.2 硬件架构概述
如图3(c)所示,FlightVGM的整体硬件架构由三个部分组成:嵌入式CPU、片外存储器和片上执行部分。片上执行部分包括三个计算核心,每个核心对应一个超级逻辑区域(SLR),并包含稀疏化单元(SU)、矩阵处理引擎(MPE)、恢复单元(RU)和特殊功能单元(SFU)。SU利用帧间和帧内的相似性实现激活稀疏化和计算减少。MPE包含支持FP16-INT8混合精度的异构DSP阵列,用于高效执行压缩后的矩阵乘法。RU根据SU生成的索引表恢复输出激活。SFU支持非线性操作(例如softmax、层归一化和GELU)。存储管理单元(MMU)负责全局缓冲区与计算单元之间的数据传输。嵌入式CPU(例如V80 FPGA上的双核A72处理器)负责在线指令调度以实现工作负载平衡。片外存储器部分主要由存储控制器、高带宽存储器(HBM)和DDR组成。
4. 时空激活稀疏化
4.1 稀疏化方法

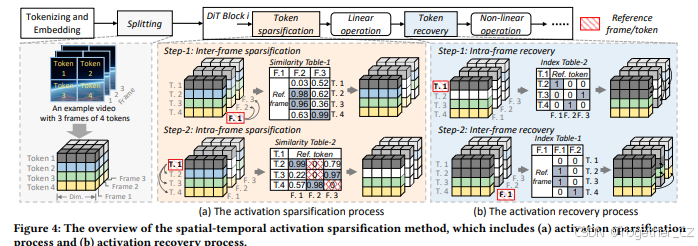
4.1.1 激活稀疏化
激活稀疏化包括两个步骤:帧间稀疏化和帧内稀疏化。对于帧间稀疏化,我们首先将输入激活分为每组连续 G 帧的组。对于每组,我们选择一帧作为参考帧。对于组中剩余的帧,我们将它们的token与参考帧的token一一配对,并计算它们的相似性。如果相似性超过阈值,则可以用参考帧上token的计算结果替换该token。

4.1.2 激活恢复
对于线性操作(例如QKVO投影和FFN),我们可以使用剩余的激活执行必要的计算,从而减少计算量。然而,对于某些非线性操作和 A×![]() 操作,我们需要恢复整个激活以确保正确性。如图4(b)所示,与激活稀疏化相对应,激活恢复过程也包括两个步骤:帧内恢复和帧间恢复。根据稀疏化过程中获得的索引表,我们获得激活恢复的相应地址关系。通过将参考token复制到相应地址,我们获得完整的输出激活。
操作,我们需要恢复整个激活以确保正确性。如图4(b)所示,与激活稀疏化相对应,激活恢复过程也包括两个步骤:帧内恢复和帧间恢复。根据稀疏化过程中获得的索引表,我们获得激活恢复的相应地址关系。通过将参考token复制到相应地址,我们获得完整的输出激活。
4.2 操作分析


4.3 硬件单元
4.3.1 矩阵处理引擎
矩阵处理引擎(MPE)高效计算线性操作、A×![]() 和移位&缩放操作。如图5(a)所示,MPE主要由MPE控制器、本地缓冲区和两个DSP阵列组成。MPE控制器根据指令驱动DSP阵列执行相应计算,一些可复用的数据将暂时存储在本地缓冲区中。DSP阵列有两种主要类型:DSP-E(DSP扩展)和DSP-N(DSP原生)。DSP-N基于原生DSP58,配置为向量定点ALU模式,可以同时支持三个INT8乘积累加(MAC)操作。如图5(b)所示,DSP-E在DSP58的基础上增加了额外的电路。DSP-E可以配置为INT8模式和FP16模式,分别支持四个INT8 MAC或两个FP16 MAC。DSP-E可以重用DSP58、INT8乘法器和INT加法器,以最大化硬件效率。我们将在第5.2节中详细介绍DSP-E。
和移位&缩放操作。如图5(a)所示,MPE主要由MPE控制器、本地缓冲区和两个DSP阵列组成。MPE控制器根据指令驱动DSP阵列执行相应计算,一些可复用的数据将暂时存储在本地缓冲区中。DSP阵列有两种主要类型:DSP-E(DSP扩展)和DSP-N(DSP原生)。DSP-N基于原生DSP58,配置为向量定点ALU模式,可以同时支持三个INT8乘积累加(MAC)操作。如图5(b)所示,DSP-E在DSP58的基础上增加了额外的电路。DSP-E可以配置为INT8模式和FP16模式,分别支持四个INT8 MAC或两个FP16 MAC。DSP-E可以重用DSP58、INT8乘法器和INT加法器,以最大化硬件效率。我们将在第5.2节中详细介绍DSP-E。
4.3.2 稀疏化单元

4.3.3 恢复单元
恢复单元(RU)的主要功能是根据索引表恢复计算结果,以避免后续计算中的错误。如图5(d)所示,RU主要由两部分组成:帧内恢复和帧间恢复。首先,RU将参考帧的激活存储在RReg中。在恢复每帧的激活之前,RU使用RReg初始化数据缓冲区。在帧内恢复阶段,RU根据帧内索引表中的信息,通过交叉开关将输入激活分配和多播到相应的块FIFO中,并暂时存储在其中。在帧间恢复阶段,RU中的地址生成器根据帧间索引表中的信息,从块FIFO中选择相应的数据,并将其写入数据缓冲区。最后,当一帧完全恢复后,RU将数据缓冲区中的结果输出。
4.3.4 特殊功能单元
特殊功能单元(SFU)处理VGMs中的非线性操作,除了矩阵乘法之外,包括softmax、层归一化等。这些操作主要包括逐元素操作和归约操作。如图5(e)所示,SFU主要由多个逐元素单元和一个归约单元组成,它们以流水线的方式执行。例如,在MSA/MCA计算中,我们在矩阵乘法操作和非线性操作的向量级别上实现了并行化。
5. 混合精度DSP58架构
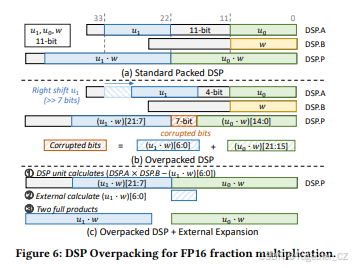
5.1 FP16过打包设计

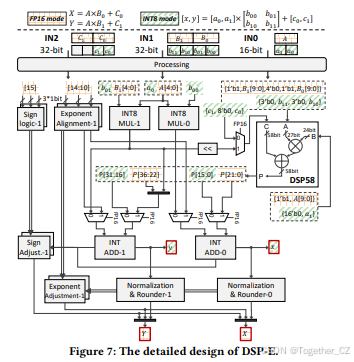
5.2 DSP58-E架构
我们提出了DSP-Expansion(DSP-E),这是一种基于DSP58的创新FP16-INT8混合精度硬件架构。如图7所示,DSP-E允许在运行时进行配置,并且可以支持两个FP16 MAC或四个INT8 MAC。我们的关键见解是使用额外的乘法器解决一个DSP58计算两个分数乘法时的数据混淆问题,这些乘法器也可以在INT8模式下重用。具体来说,我们启用标量配置的DSP58,并添加一些可配置的电路设计以提供更高的计算性能。除了DSP58外,DSP-E还包括两个INT8乘法器、两个INT加法器以及一些用于浮点加法的模块。在FP16模式下,DSP58计算这两个MAC的分数乘法,并减去INT8乘法器的结果以获得中间结果

6. 动态-静态自适应调度
6.1 概述
图8(a)展示了FlightVGM的执行流程。首先,我们提供了一个用户友好的编程接口,以满足模型描述的需求。用户可以轻松地描述自定义模型,并将权重映射到特定模块。随后,编译器将模型转换为高级中间表示(IR),描述模型的结构信息。在模型优化和静态编译过程中,高级IR被转换为可执行IR。模型优化主要包括两个步骤:操作融合和量化。我们在可组合层对之间执行操作融合,并获得带有量化参数的IR。在静态编译中,我们将压缩阈值与特定操作关联,并初始化预测的最早完成时间(EFT)。
6.2 指令集架构
如图8(e)所示,FlightVGM的指令集架构(ISA)由三种类型组成:存储管理(ST、LD、MOVE)、计算(MM、SF)和张量处理(TS、TLT)。每个操作的执行分为三个阶段:权重预加载(WL)、计算(COM)和张量处理(TP)。编译器生成三种指令序列以控制上述任务。WL指令序列是LD → (MOVE),包括两个阶段:权重加载和片上权重移动。这里,带括号的指令是可选的。COM指令序列是(LD) → MM/SF → TLT → (ST),完成耗时的计算任务和数据恢复。TP指令序列是(LD) → TS → TLT → (ST),执行激活稀疏化,并将压缩后的张量转换为MPE可用的密集矩阵格式。
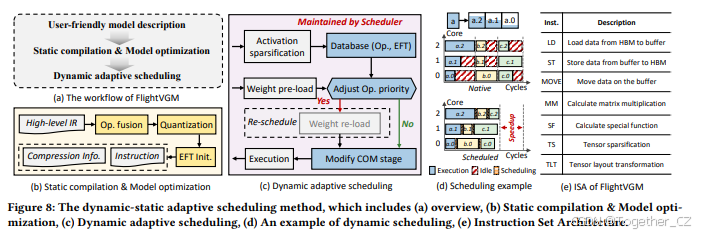
6.3 动态自适应调度
如图8(c)所示,我们提出了动态自适应调度方法,根据实际工作负载简单调整操作的执行顺序,以提高计算利用率。由于VGMs是计算密集型的,动态-静态自适应调度带来的延迟收益超过了潜在的额外内存访问开销,有效解决了在线稀疏化带来的调度挑战。我们认为具有更高实际EFT的操作具有更高的调度优先级[56]。如果实际EFT不可用,则根据预测的EFT进行排序。调度器维护一个由操作类型、预测EFT和实际EFT组成的数据库。它根据激活稀疏化结果实时调整操作的优先级。如图8(d)所示,与原生映射相比,动态调度可以显著提高计算利用率。调度器的策略包括:(1) 尽早预加载权重,以重叠WL和COM阶段;(2) 优先执行优先级更高的操作,并将它们分配给最早可用的计算核心。在当前操作(记为ACOM)的COM阶段之前,ACOM的实际EFT可能尚未确定。调度器根据预测的EFT(静态信息)执行ACOM的WL阶段。随着输入激活的TP完成,调度器获得ACOM的实际EFT。如果由于实际EFT较短导致ACOM的优先级发生变化,调度器进入重新调度阶段,并执行新优先级操作的WL阶段。最后,基于调度结果,动态调度器修改指令序列,指导核心完成调度操作的COM阶段。
7. 评估
7.1 评估设置
7.1.1 模型和数据集
我们在两个先进的基于DiT的VGMs上评估FlightVGM,分别是Latte-1[43]和Open-Sora 1.2[72]。Latte-1主要在人类动作视频数据集上进行训练,是首次探索在视频生成任务中使用DiT的模型。Open-Sora 1.2是一个广泛使用的开源模型,能够生成任意宽高比的高分辨率视频。我们在UCF-101[54]数据集(一个通用的人类动作姿态视频数据集)上评估这些模型,并使用[14, 15]中的演示提示。
7.1.2 评估指标
我们使用两个代表性指标评估VGMs的准确性:CLIPSIM[62]和VBench[37],这些指标在以往的研究[34, 48, 73, 75]中也被使用。我们还使用CLIPSIM衡量提示与视频的一致性[3, 4],并使用VBench评估生成视频的整体质量。
7.1.3 基线
表1展示了与评估相关的硬件平台参数。我们选择了三个代表性基线:通用硬件、基于Transformer的FPGA加速器和基于DiT的ASIC加速器。
(1) 通用硬件基线:我们选择NVIDIA 3090 GPU[2]作为通用硬件基线。我们在FP16精度下运行原始VGMs以获得实际执行时间,并使用NVIDIA的系统管理界面(nvidia-smi)[1]评估功耗。
(2) 基于Transformer的FPGA加速器:我们选择了两项最先进的研究,HiSpMV[47]和FlightLLM[66],它们均在AMD Alveo U280 FPGA[7]上实现。我们考虑了相同的激活稀疏化和混合精度优化。HiSpMV和FlightLLM的硬件参数和功耗数据在它们的论文中提供。
(3) 基于DiT的ASIC加速器:我们选择了几项最先进的研究,包括InterArch[59]和CMC[53]。为了公平比较,我们对它们的稀疏化方法进行了对齐,并调整了硬件参数配置以匹配FlightVGM,包括PCP、内存带宽和片上缓冲区容量。它们的功耗也相应进行了缩放。对于(2)和(3),由于它们不支持最新的Latte-1和Open-Sora 1.2模型,我们构建了一个周期精确的性能模拟器来评估它们的性能。模拟器的结果与它们的原始数据之间的差距小于6%。
7.1.4 FPGA实现
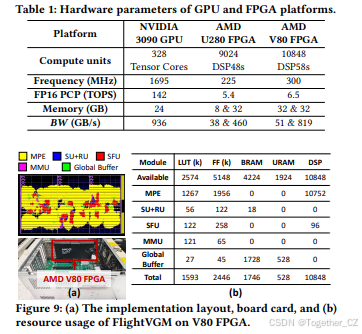
我们在AMD V80 FPGA[9]上实现了FlightVGM。每个SLR对应一个计算核心,它们在嵌入式CPU的控制下执行计算任务。V80 FPGA配备了32GB HBM,带宽为819GB/s,以及32GB DDR内存,带宽为32GB/s。FlightVGM在300MHz频率下实现了等效的INT8 PCP为20.3TOPS,FP16 PCP为2.8TOPS。图9展示了FlightVGM在V80 FPGA上的实现布局、板卡和资源使用情况。FPGA的延迟来自实际运行结果。我们使用ami_tool[10]测量功耗。
7.2 模型准确性评估
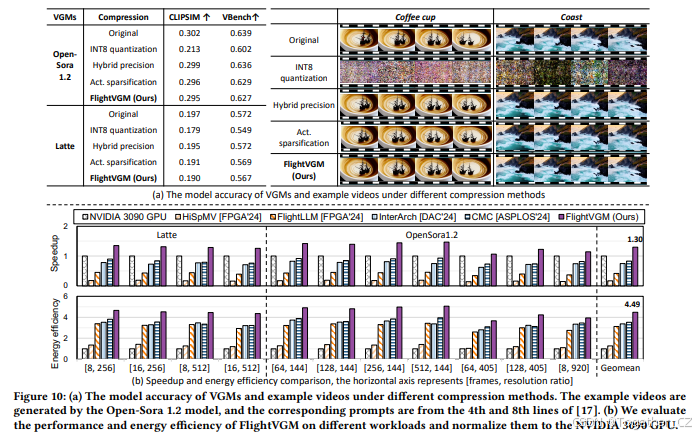
我们在图10(a)中展示了不同压缩方法下的VGMs模型准确性和示例视频。我们以原始密集模型的FP16精度为基线,FlightVGM包括混合精度量化和激活稀疏化。对于混合精度方法,我们在DiT块中的所有线性层进行量化,并将注意力图计算和DiT外的模块(例如嵌入层)保持在FP16精度。我们还对所有层进行INT8量化的比较。对于激活稀疏化,我们采用QKV/O投影的阈值为0.95/0.98,FFN的阈值为0.92。借助高效的硬件架构,我们实现了3.17倍的端到端加速。与基线相比,FlightVGM的模型准确性几乎相同(平均仅损失0.008),而INT8量化平均损失为0.042。如图10(a)右上角所示,我们测试了上述不同压缩方法的实际视频生成。我们发现FlightVGM生成的视频质量几乎与原始模型相同。
7.3 性能评估
我们在图10中比较了FlightVGM与NVIDIA 3090 GPU和当前最先进的加速器在Latte-1和Open-Sora 1.2模型上的速度提升和能效。总体而言,与最先进的加速器相比,FlightVGM平均实现了2.84倍的速度提升和1.71倍的能效提升。
7.3.1 与GPU的性能比较
对于NVIDIA 3090 GPU,V80 FPGA在FP16精度下的计算性能差距超过21倍。然而,基于V80 FPGA实现的FlightVGM仍然超过了GPU,包括性能和能效。这是因为FPGA能够充分利用VGM的固有稀疏性和混合精度来实现加速,而GPU由于其硬件架构的限制难以实现加速。与NVIDIA 3090 GPU相比,FlightVGM在性能上实现了1.30倍的提升,在能效上实现了4.49倍的提升。
7.3.2 与最先进的加速器的性能比较
对于基于DiT的加速器,我们在PCP和内存带宽方面对硬件参数进行了对齐,以进行公平比较。如图10(b)所示,与InterArch/CMC相比,FlightVGM分别实现了1.74/1.56倍的速度提升和1.33/1.27倍的能效提升。对于InterArch和CMC,FlightVGM通过更高效的压缩算法和混合精度量化进一步降低了计算成本,从而实现了更好的性能。对于基于Transformer的FPGA加速器,我们考虑了它们在论文中报告的稀疏支持。与HiSpMV相比,FlightVGM实现了7.69倍的速度提升和3.52倍的能效提升。这是因为HiSpMV由于其低并行性,无法有效处理VGM中的大量矩阵乘法。与FlightLLM相比,FlightVGM实现了3.12倍的速度提升和1.43倍的能效提升。这是因为FlightLLM无法有效支持在线稀疏化,并且缺乏计算性能优化。
7.4 消融研究和讨论
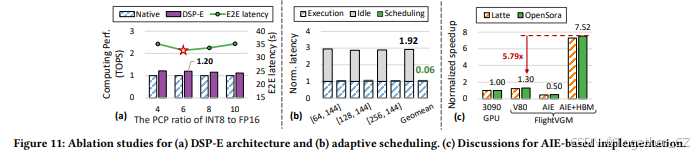
7.4.1 DSP-E架构的效果
我们在相同的硬件资源约束下,比较了使用DSP-E设计与不使用DSP-E设计的硬件计算性能。如图11(a)所示,与原生设计(即不使用DSP-E)相比,DSP-E有效地将计算性能提高了1.20倍。我们还发现,不同的计算性能比例对端到端延迟有显著影响。具体来说,如果比例过高或过低,端到端延迟很容易受到INT8/FP16计算性能的限制。因此,当选择比例为6时,这是由VGM的结构决定的最佳点。考虑到混合精度带来的优势,与仅使用浮点计算性能相比,我们可以将整体等效计算性能提高3.26倍。
7.4.2 自适应调度的效果
如图11(b)所示,我们在引入自适应调度之前和之后比较了延迟及其分解,并根据有效执行时间进行了归一化。由于在线稀疏化后工作负载不平衡,PE的平均空闲率为65.8%。我们通过自适应调度消除了浪费,引入的额外开销可以忽略不计。自适应调度实现了平均2.75倍的PE利用率提升。
7.4.3 关于基于AIE的FPGA的讨论
还有一些FPGA配备了AIE(AI引擎),以实现更高的计算性能,例如AMD VEK280 FPGA[8]和用于SSR[74]的VCK190 FPGA。我们还在图11(c)中比较了基于AIE的FlightVGM与NVIDIA 3090 GPU。VEK280 FPGA提供了228 TOPS的INT8计算性能,但其内存带宽仅为86.7 GB/s。与基于V80的FlightVGM相比,由于低内存带宽,基于AIE的FlightVGM无法有效加速VGM。此外,如果现有的AIE-based FPGA配备了HBM,FlightVGM(AIE+HBM)可以在Open-Sora 1.2模型上进一步实现5.79倍的加速。



















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











