






本文提出了一种名为 OmniTrack 的全景多目标跟踪(MOT)框架,专门针对全景图像中的独特挑战,如几何失真、分辨率损失和光照不一致等问题。该框架通过以下三个核心组件实现了在大视场和快速传感器运动场景下的高效跟踪:
-
轨迹管理模块(Tracklets Management):通过缓存和管理目标轨迹数据,为检测模块提供时间先验信息,增强检测的一致性和稳定性。
-
FlexiTrack 实例:利用目标的历史轨迹信息,快速定位和关联目标,减少在大视场中的搜索空间,提高跟踪效率。
-
CircularStatE 模块:通过减轻几何失真和增强光照一致性,提高特征的可靠性和稳定性,从而提升跟踪性能。
此外,作者还引入了一个新的全景多目标跟踪数据集 QuadTrack,该数据集由安装在四足机器人上的全景相机收集,包含复杂的运动动态和多样化的真实世界场景,为全景MOT研究提供了新的基准。
主要贡献
-
提出了一种新的全景多目标跟踪框架 OmniTrack,统一了基于检测的跟踪(TBD)和端到端(E2E)跟踪范式,通过反馈机制减少大视场中的不确定性。
-
引入了 QuadTrack 数据集,填补了现有数据集在动态、非线性运动场景中的空白,为全景MOT研究提供了新的挑战。
-
在公共JRDB数据集和QuadTrack数据集上的实验表明,OmniTrack在多目标跟踪任务中达到了最先进的性能,分别实现了26.92%和23.45%的HOTA分数。
限制与未来工作
尽管OmniTrack在全景图像跟踪领域表现出色,但仍存在一些限制,例如在目标严重遮挡时可能出现轨迹丢失。未来的工作可以考虑通过多传感器融合(如点云深度信息)来减轻遮挡问题,将2D跟踪扩展到3D跟踪,或探索人机协作感知以增强情境意识。
OmniTrack通过其创新的反馈机制和关键组件,显著提升了全景多目标跟踪的性能,特别是在处理复杂运动和大视场场景时。QuadTrack数据集的引入为全景多目标跟踪研究提供了新的基准,推动了该领域的发展。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
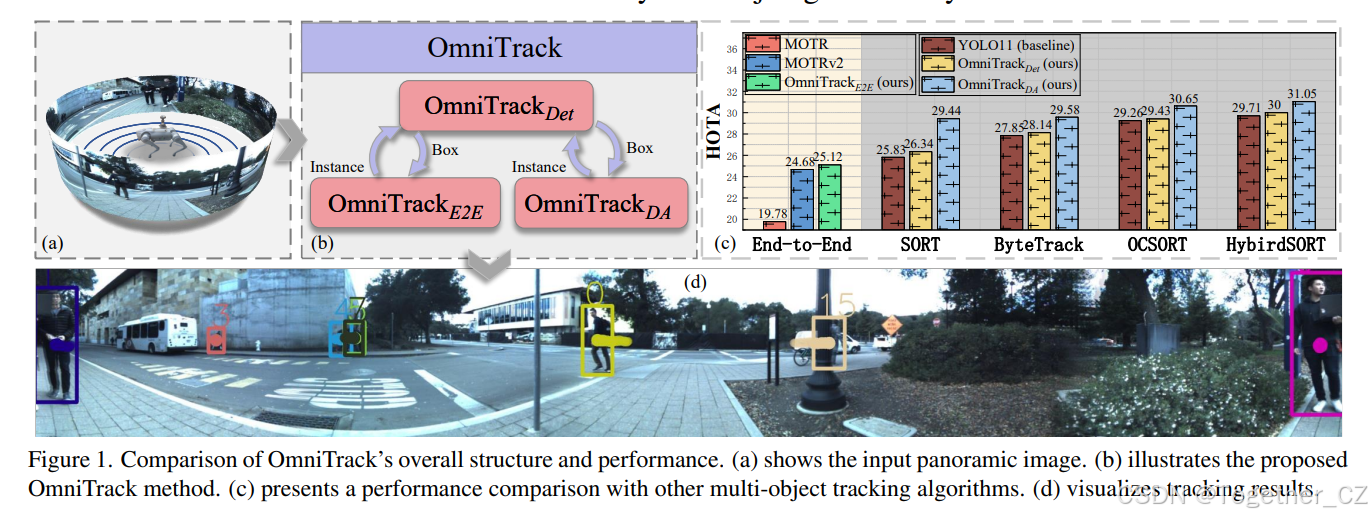
图1. OmniTrack的整体结构和性能比较。(a)显示输入的全景图像。(b)说明提出的OmniTrack方法。(c)展示与其他多目标跟踪算法的性能比较。(d)可视化跟踪结果。
摘要
全景图像以其360°视场角提供了全面的空间信息,有助于多目标跟踪(MOT)捕捉周围物体的空间和时间关系。然而,大多数MOT算法是为有限视场的针孔图像设计的,在全景设置中效果不佳。此外,全景图像失真,如分辨率损失、几何变形和不均匀光照,阻碍了现有MOT方法的直接应用,导致性能显著下降。为解决这些挑战,我们提出了OmniTrack,一个全景多目标跟踪框架,结合了轨迹管理以引入时间线索、FlexiTrack实例用于目标定位和关联,以及CircularStatE模块以减轻图像和几何失真。这种集成使得即使在传感器快速运动的情况下,也能在大视场场景中进行跟踪。为缓解全景MOT数据集的缺乏,我们引入了QuadTrack数据集——一个由四足机器人收集的全景数据集,包含宽视场、剧烈运动和复杂环境等多样化挑战。在公共JRDB数据集和新引入的QuadTrack基准上的广泛实验表明,所提出的框架达到了最先进的性能。OmniTrack在JRDB上实现了26.92%的HOTA分数,比现有方法提高了3.43%;在QuadTrack上进一步实现了23.45%,超过了基线6.81%。
1. 引言
全景相机以其360°视场角能够捕捉全面的周围信息,在自动驾驶、机器人导航和人机交互等领域具有重要意义。对于四足机器人等小型移动机器人来说,全景相机具有特别的优势,允许在一个紧凑的设置中实现完整的环境感知,如图1(a)所示。尽管多目标跟踪(MOT)取得了进展,但全景MOT仍处于探索阶段。现有的MOT算法是为针孔相机开发的,在全景设置中由于分辨率损失、几何失真以及展开时的不均匀颜色和亮度分布等固有问题而难以应用(图1(d))。这些挑战常常导致针孔相机算法在全景图像上的性能下降,限制了其在全景场景感知中的有效性。为解决这些挑战,开发能够在全景图像中进行全景感知的MOT算法是一个亟待解决的问题。为此,本文首次提出了OmniTrack,一个专门针对360°全景图像的全景多目标跟踪框架。OmniTrack统一了两种主流的MOT范式——基于检测的跟踪(TBD)和端到端(E2E)跟踪,并引入了一种反馈机制,有效减少了大视场和快速传感器运动中的不确定性,实现了快速准确的目标定位和关联。该框架由三个核心组件组成:CircularStatE模块、FlexiTrack实例和轨迹管理。CircularStatE模块旨在减轻广角失真,增强光照和颜色的一致性。FlexiTrack实例利用目标的时间连续性,引导感知模块专注于大视场中的关键区域,帮助进行定位和关联。这种方法有助于减轻超宽视场中目标定位的困难。轨迹管理模块收集和管理轨迹数据,为FlexiTrack实例提供先验知识。通过这些组件,OmniTrack统一了两种MOT范式:在轨迹管理中禁用数据关联,得到一个端到端的跟踪器OmniTrackE2E,而启用关联则得到一个TBD风格的跟踪器OmniTrackDA。通过采用相同的数据关联策略,如图1(c)所示,OmniTrackDA框架实现了显著更强的性能。禁用FlexiTrack实例和轨迹管理将系统简化为一个全景目标检测器OmniTrackDet,如图1(b)所示。此外,为支持全景MOT研究,我们开发了QuadTrack,一个由安装在四足机器人上的360°×70°全景相机收集的数据集。这个移动平台的仿生步态引入了现实的复杂运动特征,挑战现有的MOT算法。该数据集在两个城市的五个校园中收集,包含19,200张图像,涵盖了各种动态的真实世界场景。与使用静态或线性移动平台的典型MOT数据集相比,QuadTrack为评估大视场场景中快速非线性传感器运动的MOT性能提供了一个新的基准。简而言之,我们的工作做出了以下贡献:
-
为解决全景多目标跟踪的空白,我们提出了OmniTrack,一个新颖的框架,统一了E2E和TBD跟踪范式。这种方法减少了大视场场景中的不确定性和增强了感知与关联性能。
-
我们提出了QuadTrack,一个具有复杂运动动态的新全景MOT数据集,为宽视场多目标跟踪提供了一个具有挑战性的基准。
-
在JRDB和QuadTrack数据集上的广泛实验表明OmniTrack的优越性能,在JRDB上实现了26.92%的HOTA,在QuadTrack测试集上实现了23.45%,推动了全景MOT的最新水平。
2. 相关工作
全景场景理解。全景感知能够在单次拍摄中实现对360°场景的整体理解。主要领域包括全景场景分割、全景估计、全景布局估计、全景生成和全景流估计等。研究人员通常将全景图展开为等矩形投影或多面体投影,以适应为有限视场数据设计的算法。他们还应用可变形卷积技术来处理高纬度区域的严重失真。最近,研究人员认识到全景图像在跟踪方面的优势,特别是其能够持续观察目标,而不会出现有限视场设置中的视野外问题。Jiang等人提出了一种500FPS的全向跟踪系统,使用三轴主动视觉机制在复杂环境中捕捉快速移动的目标。360VOT基准被引入用于全向目标跟踪,专注于球形失真和目标定位挑战。Huang等人提出了360Loc用于全向定位,通过从360°数据生成低视场查询帧来解决跨设备挑战。另一项工作由Xu等人引入,扩展了视场角(eBFoV)表示以减轻全景视频中的球形失真。与以往方法不同,这项工作首次探索了具有极大挑战性的大视场和剧烈运动的全景跟踪,用于移动机器人,例如旨在增强机器人对其周围物体的时空理解。多目标跟踪。目标跟踪主要遵循两种范式:基于检测的跟踪(TBD)和端到端(E2E)。其中,TBD目前是最流行的范式之一,其框架遵循SORT的设计原则。首先,使用检测网络定位目标的边界框,然后根据目标的历史轨迹预测其当前位置,并将预测结果与检测结果进行关联。许多后续工作改进了这种方法:DeepSORT引入了一个ReID模型,将外观信息纳入关联中,ByteTrack设计了一种基于置信度的分阶段关联策略。其他方法引入了运动补偿模块以减轻相机运动,OC-SORT优化了运动估计模块。此外,E2E方法也在不断发展。TrackFormer和MOTR提出了基于变换器的端到端跟踪方法。最近的改进提高了检测器性能,并在遮挡场景中提高了数据关联的准确性。与现有方法不同,这些方法专注于具有线性传感器运动的窄视场针孔相机数据,而我们则解决了宽视场场景中的MOT挑战,解决了几何失真和复杂运动等问题。
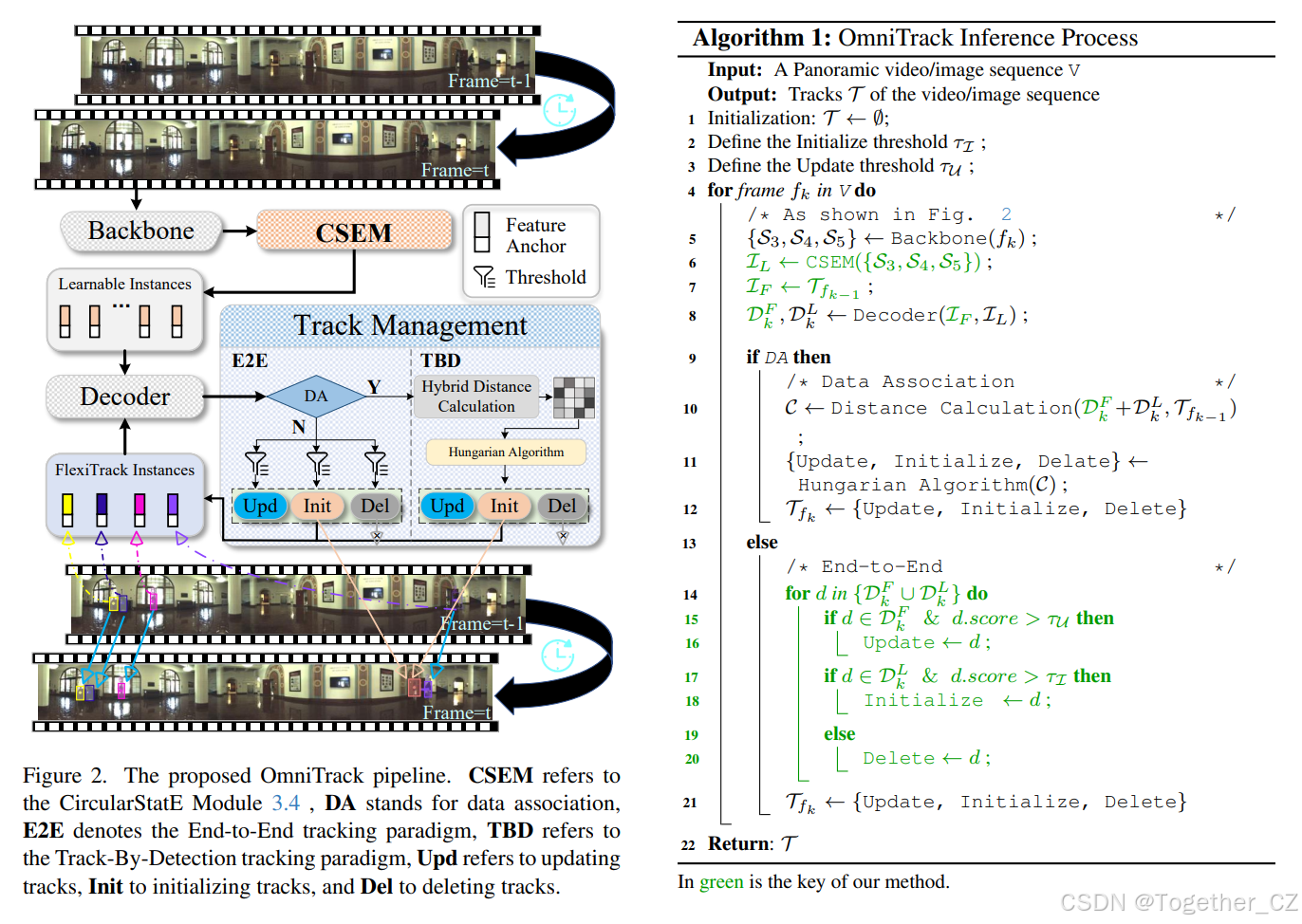
3. OmniTrack:提出的框架
在本节中,我们介绍OmniTrack,一个全景多目标跟踪框架,专门解决宽视场图像中的独特挑战,包括广泛的搜索空间、几何失真、分辨率损失和光照不一致。OmniTrack设计了一个反馈机制,通过将轨迹信息反馈回检测器,迭代细化检测,增强大视场场景中跟踪的稳定性(第3.1节)。具体来说,为解决这些挑战,我们提出了三个关键组件:
-
轨迹管理(第3.2节):管理目标轨迹的生命周期,并为感知模块提供时间先验。
-
FlexiTrack实例(第3.3节):利用时间上下文快速定位和关联全景视图中的目标。
-
CircularStatE模块(第3.4节):减轻几何失真,提高宽视场中的一致性,增强特征的可靠性。
3.1. 反馈机制
OmniTrack框架如图2所示,与传统MOT方法不同,后者将目标检测和数据关联分开。OmniTrack引入了一个反馈机制,通过将轨迹信息反馈回检测器,迭代细化检测,增强大视场跟踪的稳定性。在传统MOT中,检测和关联是解耦的,导致每帧的检测H(xt)独立计算:
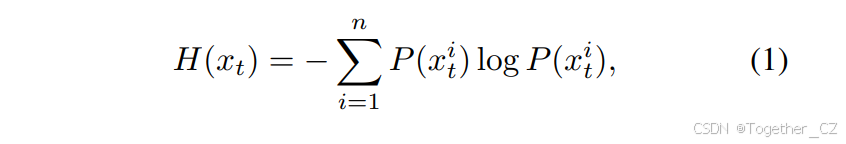
其中xit表示第t帧中第i个目标的位置,P(xit)为概率分布。全局关联熵H({yt})取决于所有帧中目标位置的联合概率分布:
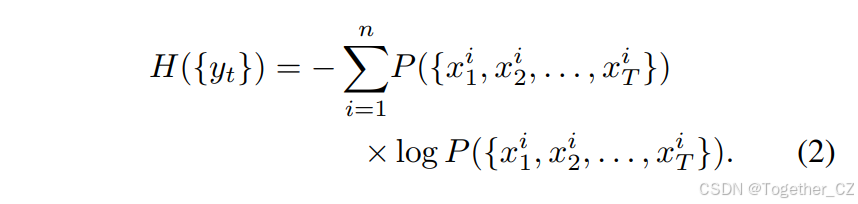
所有帧的累积熵,考虑独立匹配,可以表示为:
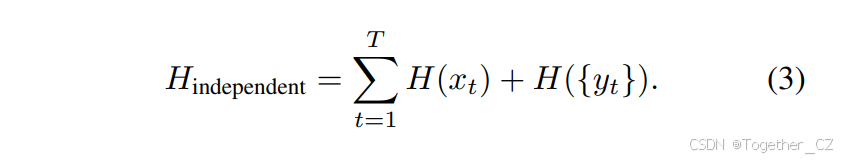
相比之下,OmniTrack的反馈机制允许第t−1帧的检测结果为第t帧提供信息,减少每帧的不确定性。具体来说,给定前一帧的反馈yt−1,第t帧的条件熵为:
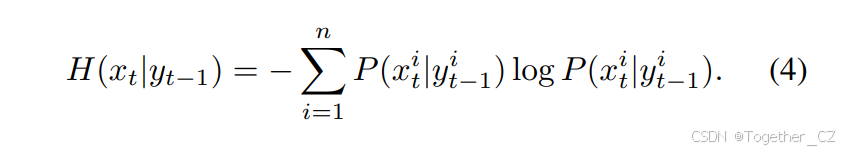
总熵变为:
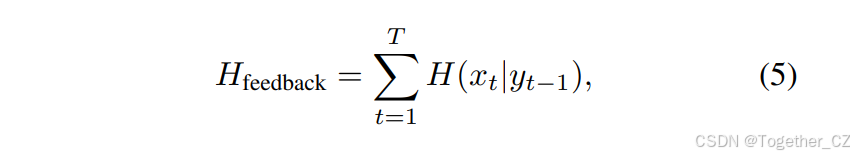
其中Hfeedback<Hindependent,表明随着时间的推移不确定性减少。这种反馈驱动的方法因此增强了大视场场景中跟踪的稳定性。
3.2. 轨迹管理
为了减少目标定位和关联中的不确定性,同时引入时间信息,OmniTrack引入了一个轨迹管理模块。在训练期间,该模块缓存置信度分数超过阈值τ的实例的时间数据,为后续帧中的检测一致性提供历史上下文。在推理期间,轨迹管理负责轨迹生命周期管理,通过更新、删除或初始化实例,基于它们的置信度分数。在没有数据关联的情况下,轨迹直接管理,形成OmniTrackE2E(算法1,第14-21行)。当启用数据关联时,轨迹管理利用基于TBD的方法增强跟踪,称为OmniTrackDA(算法1,第10-12行)。
3.3. FlexiTrack实例
如公式(2)所示,全局关联熵在宽视场条件下显著较高,使得关联任务具有挑战性。受人类跟踪行为的启发,这种行为基于过去的运动专注于可能的区域,我们通过利用其历史轨迹估计目标的当前位置。这种方法避免了在整个视场范围内进行全局搜索,这在大规模感知任务中特别有益。基于这一见解,我们引入了FlexiTrack实例。每个FlexiTrack实例与可学习实例共享解码器网络结构,由一个特征向量X∈R128和一个锚点Y∈R128组成,如图2所示。通过共享解码器,FlexiTrack实例可以无缝适应各种MOT范式,增强灵活性,并允许在不同方法之间进行集成,而无需额外修改。为了增强鲁棒性,在训练期间向特征向量和锚点添加噪声,最小化对历史数据的依赖并提高泛化能力:
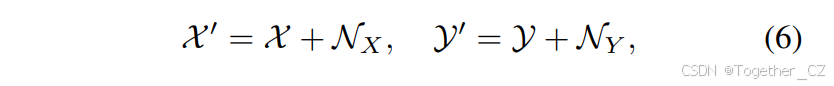
其中NX和NY分别表示添加到特征向量和锚点的噪声分量。为了初始化所有FlexiTrack实例,设IF为初始实例集,N为轨迹总数。每个实例IF由一个特征向量Xi和一个锚点Yi组成,如下所示:

X′i∈RdX和Y′i∈RdY分别是第i条轨迹的特征向量和锚点,其中dX=dY=128表示它们各自的维度。这使得IF能够继承轨迹信息,引导感知模块快速定位目标并建立时间关联。
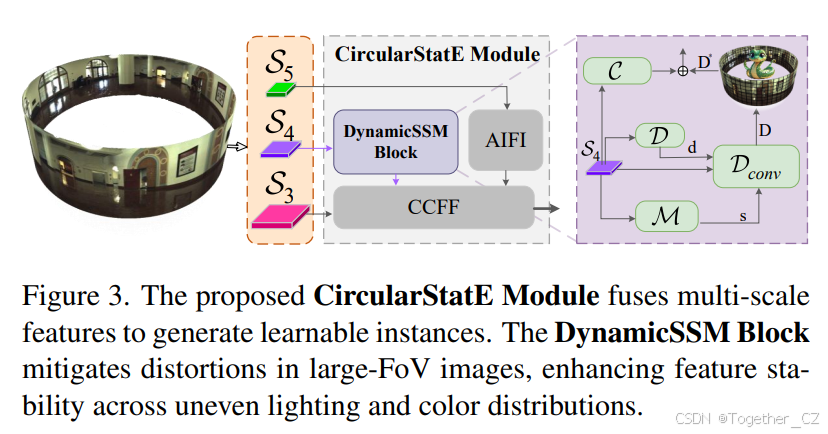
3.4. CircularStatE模块
全景图像提供了极宽的视场,能够捕捉360°场景。然而,这不可避免地引入了实际高动态范围场景中的几何失真以及颜色和亮度的不一致问题。为解决这些挑战,本文提出了CircularStatE模块,该模块减轻失真并提高图像特征的一致性,从而增强感知模型的性能。CircularStatE模块的核心是DynamicSSM块,负责减轻失真并细化特征图。操作分为以下步骤:失真和尺度计算。第一步是从输入特征图S4中计算失真和尺度信息:
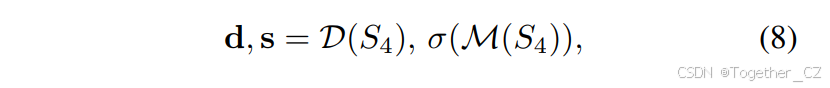
其中,d和s分别表示失真和尺度,它们的维度均为RB×C×W×H。减轻失真。为了纠正失真,我们应用动态卷积Dconv来细化特征图。操作可以表示为:
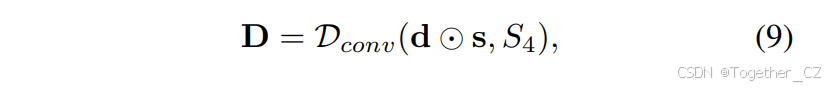
其中符号⊙表示哈达玛积,确保有效地整合尺度调整。提高一致性。在失真校正之后,应用状态空间模型(SSM)来增强全景图像中的光照和颜色一致性。此步骤的输入是前一阶段的输出,记为D∈RB×C×W×H,可以表示为:
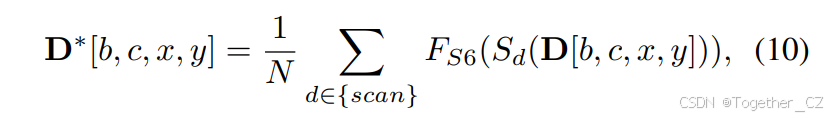
其中N表示扫描次数,Sd表示扫描函数,FS6是S6块的变换函数。特征融合。最后,将动态卷积分支和残差分支的输出进行融合。融合模块F将细化后的特征图D∗与经过CNN操作C(S4)处理的S4版本相结合,得到最终的输出特征图F:
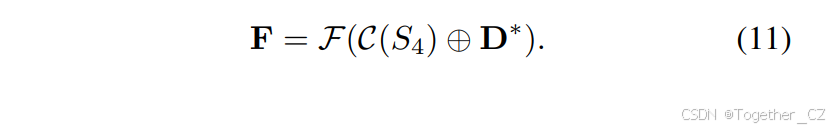
⊕表示特征融合操作,结合两个分支的细节,以获得最佳的特征表示。
4. QuadTrack:动态360°MOT数据集
大多数现有的MOT数据集是使用针孔相机拍摄的,其特点是视场狭窄且传感器运动线性。然而,当宽视场捕获设备即使有轻微运动时,整个场景也可能发生剧烈变化,给目标跟踪带来重大挑战。QuadTrack通过提供一个专门设计用于测试MOT算法在动态非线性运动条件下的基准来解决这一挑战。它使评估算法在全景非均匀运动中跟踪目标的鲁棒性成为可能。
4.1. 数据集收集与挑战
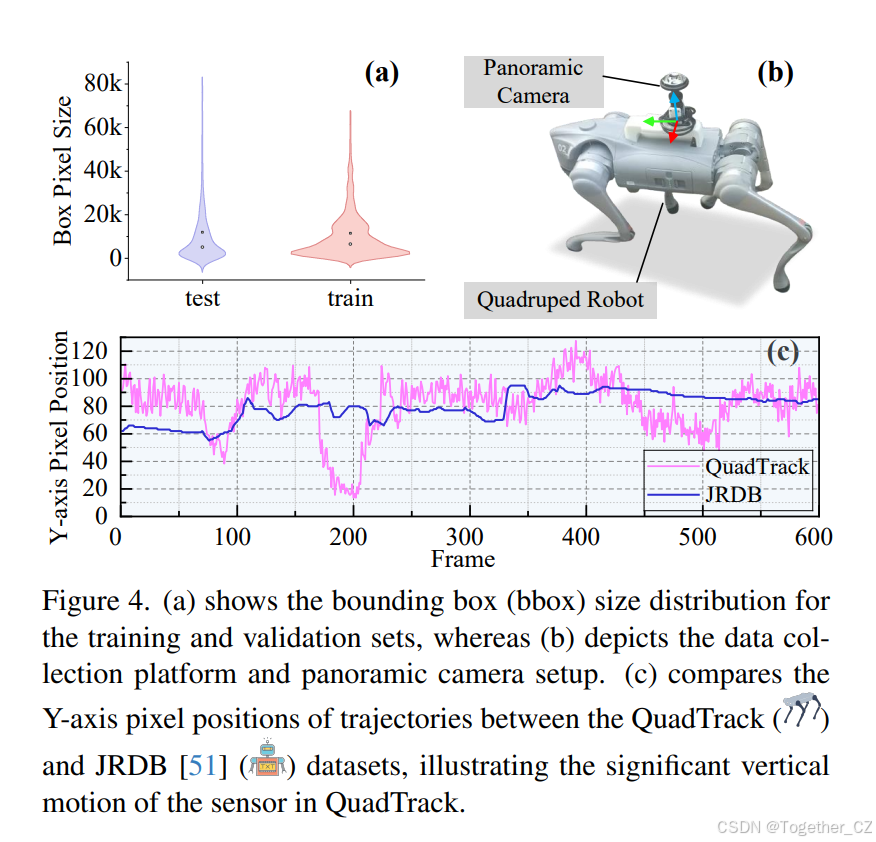
为了获取具有宽视场和复杂运动动态的数据集,我们使用四足机器人作为数据收集平台。选择该平台是因为其仿生步态模仿了四足动物的自然运动模式,由于其固有的复杂性和可变性,为运动跟踪带来了额外的挑战。机器人尺寸为70cm×31cm×40cm,最大有效载荷为7kg。它可以跨越高达15cm的垂直障碍物和高达30°的斜坡,使其在日常环境中具有高度的机动性。凭借12个关节电机,机器人可以以高达2.5m/s的速度复制逼真的行走动作。对于感知,我们使用了一个全景环形镜头(PAL)相机来捕捉360°×70°视场角的宽角场景。该相机的像素尺寸为3.45µm×3.45µm,有效像素为500万,并支持最大输出分辨率为2448×2048像素,帧率为40.5FPS。安装在四足机器人上(见图4(b)),该相机确保了无遮挡的最佳视野。使用该平台,我们在两个城市的五个校园中进行了户外数据收集,捕捉了多样化环境中的数据。由于四足机器人的仿生步态,所收集的全景图像自然表现出沿Y轴的特征抖动(见图4(c))。与JRDB数据集相比,我们的QuadTrack数据集引入了更复杂的运动挑战。此外,数据还面临诸如视场宽导致的曝光不均匀、颜色不一致以及由于移动物体与背景之间的相对位移迅速增加而加剧的运动模糊等挑战。更多细节可在补充材料中找到。
4.2. 数据分布与比较分析
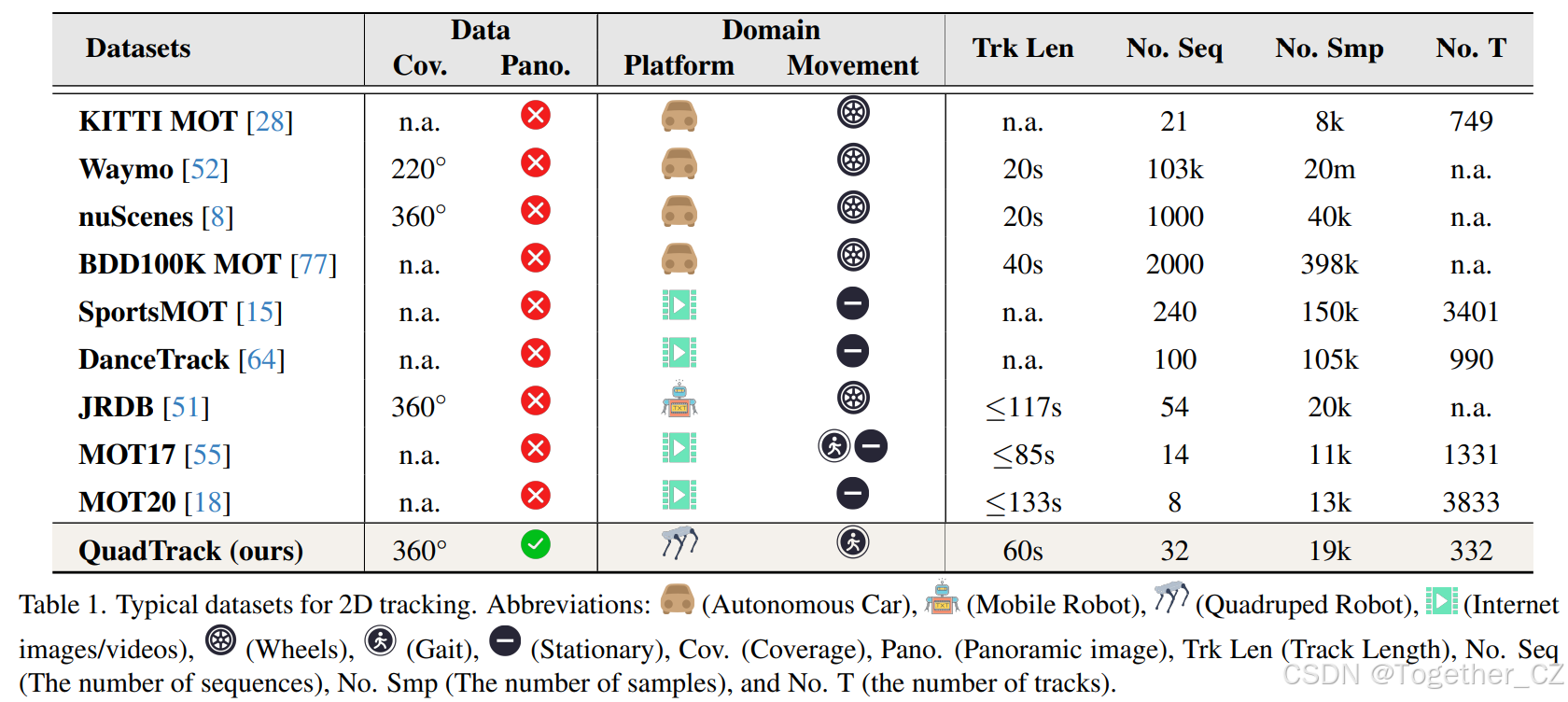
与现有的全景MOT数据集不同,QuadTrack是第一个使用单个360°全景相机拍摄的数据集。与传统MOT数据集相比,QuadTrack具有更宽的视场(360°×70°),如表1所示。与自动驾驶数据集不同,QuadTrack融入了复杂的仿生步态运动。此外,与基于互联网的数据集不同,QuadTrack旨在更好地反映真实世界的应用场景。尽管许多现有数据集包含较短的视频序列,但QuadTrack强调长期跟踪,每个视频持续60秒。为了进一步挑战数据关联,我们将数据集下采样至10FPS,每个序列包含600帧,分布在32个序列中。总共,QuadTrack包含19,200帧和189,876个边界框。如图4(a)所示,训练集和测试集的分布是一致的,确保了对MOT方法的可靠和平衡评估。这种数据集之间分布的一致性减少了潜在的偏差,并允许在不同条件下更准确地比较模型性能。图4(c)中描绘的轨迹突出了在宽视场条件下多目标跟踪的复杂性。值得注意的是,与JRDB相比,沿Y轴的运动显著更为剧烈,这进一步复杂化了跟踪过程。
5. 实验
5.1. 实验设置
数据集。我们在两个数据集上进行实验:JRDB和QuadTrack。JRDB是一个为拥挤人类环境设计的全景数据集,包含10个训练序列、7个验证序列和27个测试序列。该数据集中的全景图像是使用配备五个针孔相机的轮式移动机器人拍摄的。它包括室内和室外场景,以显著的遮挡和小目标的存在为特征。此外,一些目标相对于机器人有快速的相对运动,这对于MOT算法来说是一个重大挑战。关于QuadTrack数据集的详细信息在第4节中进行了阐述。
评估指标。我们使用CLEAR指标,包括MOTA、假正例(FP)、假负例(FN)等,结合IDF1、OPSA和HOTA,从多个维度全面评估跟踪性能。MOTA强调检测器性能,而IDF1评估跟踪器保持一致身份的能力。相比之下,HOTA整合了关联精度和定位精度,成为评估跟踪算法的一个越来越重要的指标。
实现细节。为了公平比较各种MOT算法,我们在JRDB数据集上重新训练了模型。对于端到端(E2E)算法,我们在JRDB上使用源代码中的默认参数进行训练。对于基于TBD范式的MOT算法,我们选择了先进的YOLO11-X作为基线检测器进行训练。此外,OmniTrackDet是通过在训练OmniTrack模型后屏蔽轨迹管理模块并保存检测结果获得的。使用AdamW优化器,学习率设置为10−5。更多实验细节请参考补充材料。
5.2. 与最新技术的比较
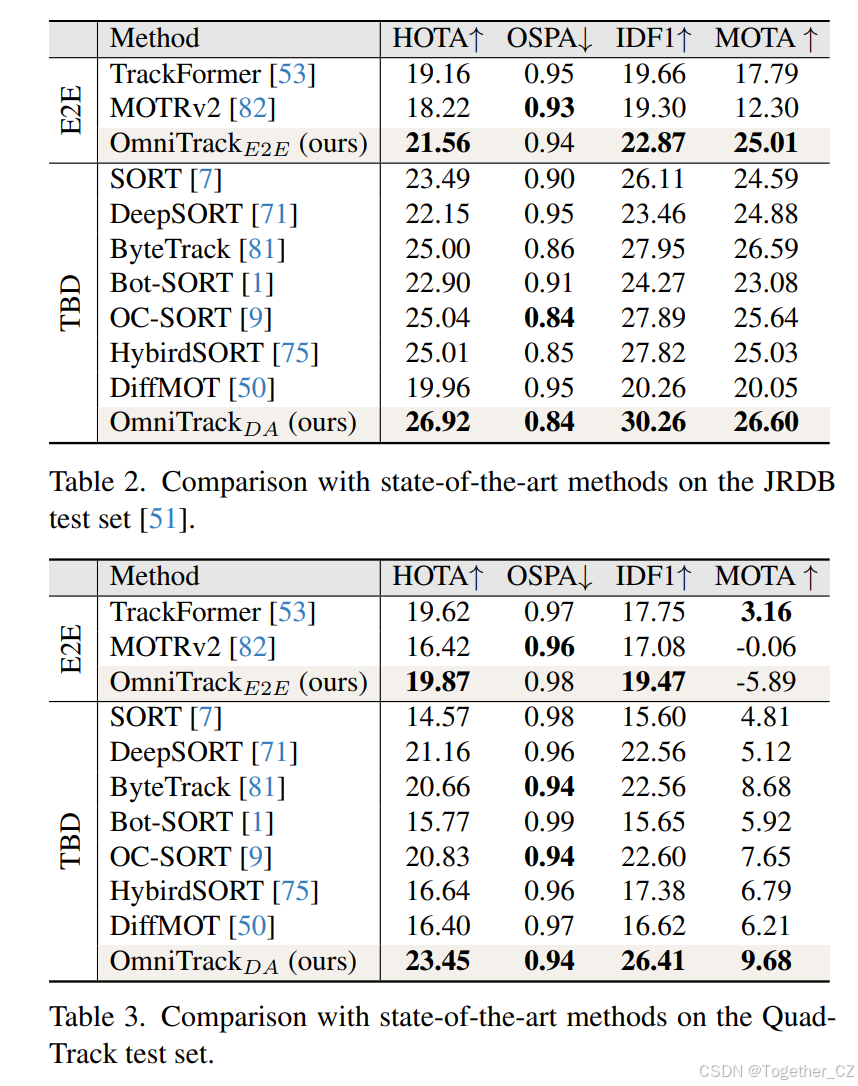
在JRDB测试集上的跟踪。在表2中,我们将OmniTrack与JRDB测试集上的最新方法进行了比较。首先,我们的方法在所有跟踪指标上均显著优于现有算法,无论是与端到端还是TBD范式相比。具体来说,在端到端框架内,OmniTrack实现了21.56%的HOTA和22.87%的IDF1,分别比当前最先进的方法MOTRv2高出3.34%和3.57%。此外,在TBD范式下,即使在相同的检测器条件下,OmniTrack也比最先进的HybirdSORT高出1.91%的HOTA和2.44%的IDF1,显示出其卓越的性能。
在QuadTrack测试集上的跟踪。在表3中,我们展示了OmniTrack与QuadTrack测试集上最新方法的比较。该数据集特别具有挑战性,其特点是视场宽且传感器运动快速非线性,这为传统MOT算法引入了显著的复杂性。尽管面临这些挑战,我们的方法仍然优于现有方法,在E2E组中实现了最高的HOTA分数19.87%,在TBD组中实现了23.45%。
5.3. 范式比较
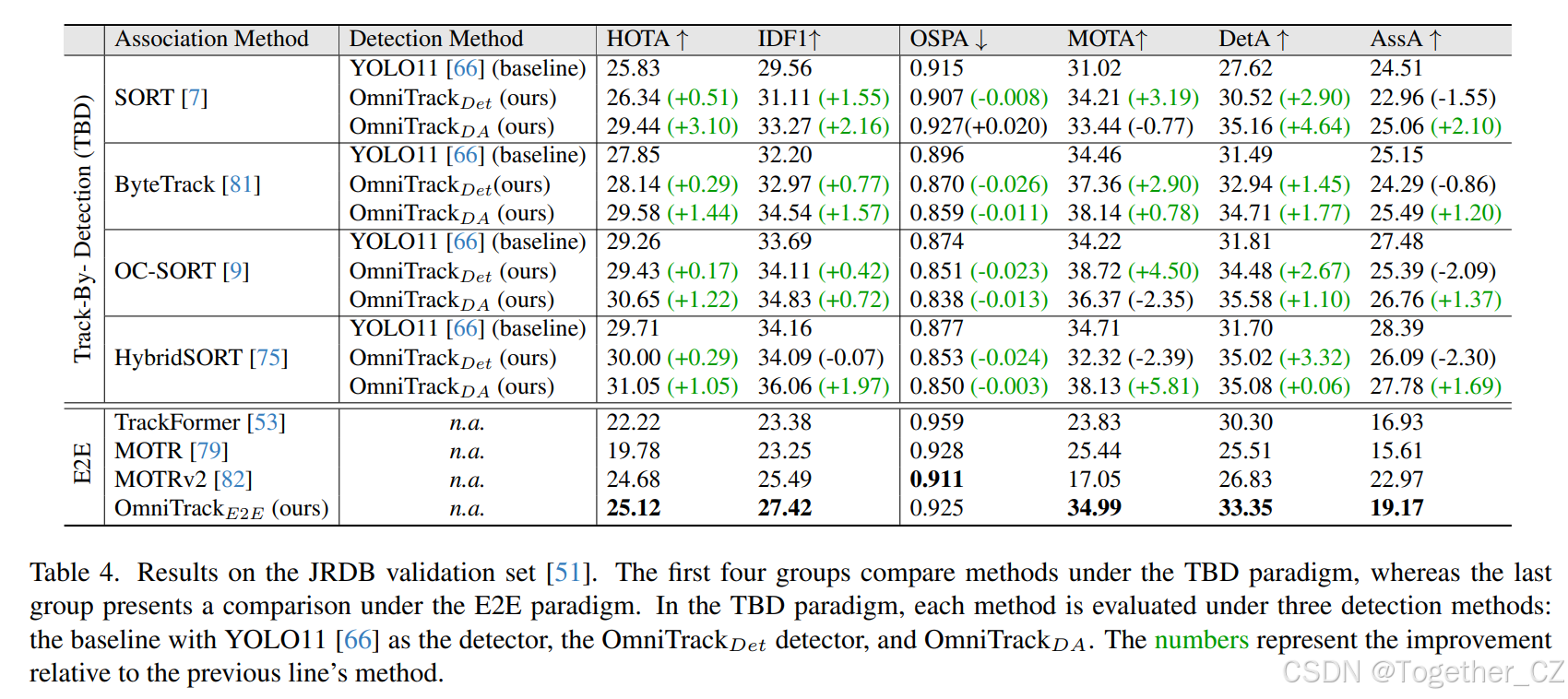
基线。为了进一步验证OmniTrack的优势,我们在TBD和E2E范式下进行了比较,如表4所示。在TBD范式下,我们评估了几种基线跟踪算法。每种跟踪方法都在三种不同的检测设置下进行了比较:使用YOLO11-X作为基线检测器,OmniTrackDet作为检测器(代表传统TBD跟踪,其中检测和跟踪是独立的),以及OmniTrackDA,具有TBD跟踪的反馈机制。在E2E范式下,我们使用MOTR作为基线进行比较。

结果。在相同的跟踪方法中,OmniTrackDet始终优于YOLO11-X,平均HOTA提高了0.2%,IDF1提高了0.6%。这突显了OmniTrackDet优于YOLO11-X的卓越性能。此外,当比较OmniTrackDet与OmniTrackDA时,后者在HOTA上平均提高了1.7%,在IDF1上提高了1.4%,证明了反馈机制(第3.1节)的有效性。在E2E范式下,OmniTrackE2E取得了最佳结果,HOTA为25.12%,IDF1为27.42%。
5.4. 消融研究
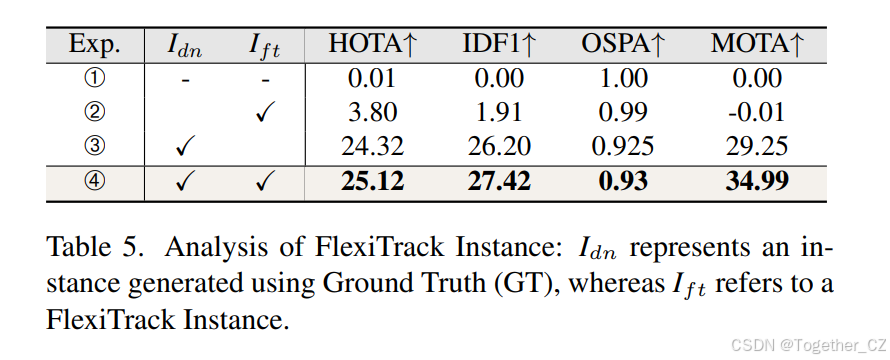
FlexiTrack实例的分析。表5比较了在训练阶段有无噪声实例和FlexiTrack实例的实验。实验1和实验2表明,FlexiTrack实例对于实现跟踪目标至关重要。在实验3中,我们观察到从Ground Truth(GT)生成的噪声实例显著提高了HOTA分数,提供了更强的指导。实验3和实验4进一步表明,在使用噪声实例之后引入FlexiTrack实例可以进一步提高HOTA分数。
CircularStatE模块的分析。在表6中,我们评估了CircularStatE中的DynamicSSM的有效性,并将其与其他常见设计(如全连接层和卷积层)进行了比较。实验1、实验2和实验3的结果清楚地表明了DynamicSSM的优势。实验4、实验5和实验6进一步表明,将DynamicSSM应用于S4可以获得最佳性能。这是因为S4既包含语义信息又包含纹理信息,这使得DynamicSSM更容易提取失真和颜色细节,从而有助于校准。
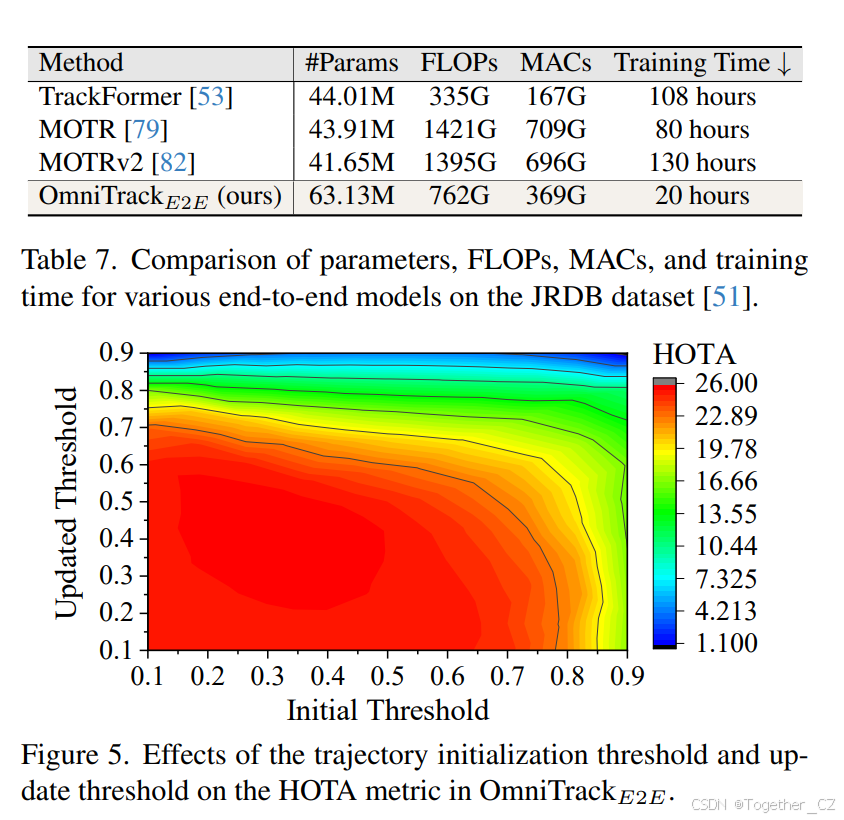
初始化和更新阈值的分析。在OmniTrackE2E中,我们分析了轨迹初始化阈值和更新阈值对跟踪性能的影响。如图5所示,在0.1到0.7的范围内,初始化阈值和更新阈值均实现了超过25%的HOTA分数。这表明OmniTrackE2E对阈值变化具有鲁棒性,无需微调即可实现最佳结果。
端到端模型训练的比较。在表7中,我们将OmniTrackE2E的参数数量和训练时间与现有的端到端方法进行了比较。我们的方法在JRDB数据集上的训练速度比其他端到端方法快四倍以上。这是通过使用FlexiTrack实例实现身份关联,显著简化了关联组件的模型设计,并缓解了端到端模型训练的挑战。
6. 结论
本文提出了OmniTrack,这是一个专门针对全景图像的多目标跟踪框架,有效解决了几何失真、分辨率低和光照不一致等关键问题。OmniTrack的核心是一个反馈机制,该机制减少了大视场跟踪中的不确定性。该框架结合了轨迹管理以实现时间稳定性,FlexiTrack实例用于快速定位和关联,以及CircularStatE模块以减轻失真并提高视觉一致性。此外,我们提出了QuadTrack,这是一个使用四足机器人收集的跨校园多目标跟踪数据集,以支持动态运动场景。这个具有挑战性的数据集旨在推动机器人全景感知领域的研究。实验验证了OmniTrack在公共JRDB和建立的QuadTrack数据集上实现了最先进的性能,证明了其在处理全景跟踪任务方面的有效性。限制。尽管OmniTrack表现出色,但我们的方法目前仅限于2D全景跟踪,没有3D能力,限制了复杂场景中的深度感知。此外,该方法主要围绕移动机器人平台展开。未来的工作可以考虑扩展到3D全景MOT,或探索人机协作感知以增强情境意识。
7. QuadTrack数据集的标注
在建立的QuadTrack数据集的标注过程中,我们使用了CVAT,这是一个支持目标检测、目标跟踪和实例分割等任务的开源标注工具。CVAT提供本地和在线版本,为用户提供了高度的灵活性。在标注之前,我们对数据集进行了预处理,选择了具有代表性的场景,包括32个序列(seq),其中16个用于训练,16个用于测试。每个序列包含600帧,帧率约为10FPS,每个序列的持续时间约为60秒。此外,为了帮助标注者更好地进行语义理解和精确标注,我们将图像展开为2048×480的全景布局,通过等矩形投影实现。对于图像边界的边界框,我们确保了连续的跟踪,保证了周围环境中相同目标的唯一ID。最小边界框面积设置为800像素,任何小于该面积的目标都被忽略。QuadTrack数据集包括两种常见的目标类别:汽车和人。在标注过程完成后,通过过滤和交叉验证程序对最终的标注属性进行了彻底的审查和验证,以确保数据的准确性。在确保标注正确性之后,最终的标注属性被格式化为MOT标准。以下是Ground Truth的一个示例:
MOT格式
f id,t id,x,y,w,h,conf,cls,vis
data
1,1,733.67,281.66,34.78,106.81,1,1,1.0
1,2,557.87,268.05,24.36,128.58,1,1,1.0
1,3,382.33,316.41,110.61,61.49,1,2,1.0
1,4,000.00,301.35,35.02,82.89,1,2,1.0
1,5,1917.7,278.79,20.70,97.98,1,1,1.0
...对于数据集中属性的详细描述,请参考表8。这种标注格式是多目标跟踪(MOT)研究中常用的,为组织数据提供了一种结构化和标准化的方法。包含目标身份、边界框坐标和可见性状态等基本属性对于训练和评估动态真实世界环境中的跟踪模型至关重要。在图8中,展示了QuadTrack数据集的示例,展示了场景的多样性和标注的视觉呈现。
8. 额外的消融研究与分析
8.1. DynamicSSM块的进一步分析
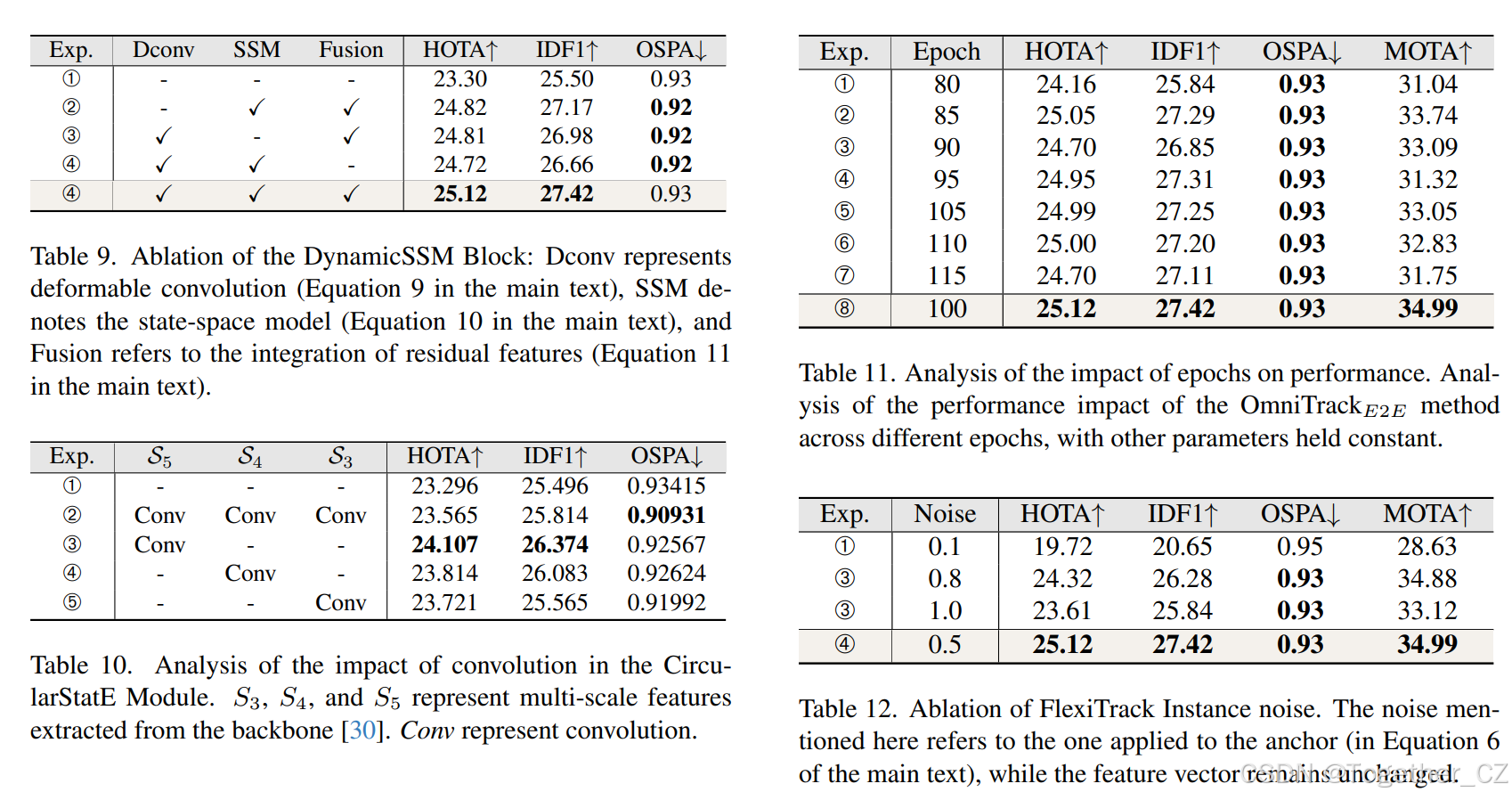
我们对DynamicSSM块的组成部分进行了更详细的讨论,如表9所示。DynamicSSM块由三个主要操作组成:(i)减轻失真,如主文中公式(9)所述;(ii)解决光照和颜色不一致性,如主文中公式(10)所述;(iii)增强特征表示,如主文中公式(11)所述。如表9所示,这三个操作各自都有助于性能提升,而它们的组合则实现了最佳的整体性能。实验1和实验3之间的比较表明,将DynamicSSM块中的所有三个操作整合在一起可以使HOTA整体提升1.82%。
8.2. CircularStatE模块的进一步分析
在CircularStatE模块中,我们设计了一个关键组件DynamicSSM块,以解决全景图像固有的失真和光照不一致性问题。与卷积网络相比,DynamicSSM块在处理这些问题时具有显著的性能优势。为了进一步探索卷积网络对多尺度特征的影响,我们进行了额外的实验,结果总结在表10中。结果表明,将卷积网络应用于S5尺度时,CircularStatE模块的性能最佳,HOTA分数达到了24.107%。
8.3. 超参数的进一步分析
训练周期的影响分析:我们进一步分析了不同训练周期对模型性能的影响。实验中,我们选择了相同的参数(即轨迹初始化阈值为0.55,轨迹更新阈值为0.45),在JRDB数据集的验证集上进行训练,并在每个周期结束时保存模型权重。实验结果如表11所示。从表中可以看出,不同的训练周期对最终的HOTA指标有明显的影响。当训练周期设置为100时,模型取得了最佳的HOTA值25.12%,其他周期的性能略低于此值。总体而言,OmniTrack在不同训练周期下表现出较强的鲁棒性和一致的性能。


图7. QuadTrack数据集存在几个显著的挑战。标记为(a)、(b)、(c)和(d)的图像展示了来自一个序列的连续帧80到84,右侧显示了相应的放大视图。在这些放大视图中,实线矩形框表示当前帧的真实标注(Ground Truth, GT),而虚线框则对应于前一帧的真实标注。其中一个显著的挑战是运动模糊,尤其在帧(b)的放大视图中表现得尤为明显,仿生步态给目标物体带来了显著的模糊。此外,相邻帧之间存在相当大的位置位移,这在帧(c)和(d)的放大视图中得到了展示。全景图像还存在固有的曝光问题,既显示出过曝区域,也有欠曝区域,如(a)所示。最后,全景图像所固有的连续性为跟踪任务带来了另一个关键因素。
FlexiTrack实例噪声的分析:FlexiTrack实例(见主文第3.3节)在大视场场景中协助检测模块快速定位目标并建立时间关联方面发挥着关键作用。其性能的一个关键方面是初始化阶段,运动噪声的选择对整体跟踪结果有显著影响。为了研究这一点,我们分析了不同运动噪声水平对FlexiTrack实例在JRDB验证集上的性能影响,结果如表12所示。从表中可以看出,不同的运动噪声水平对最终的HOTA分数有显著影响。特别是,当运动噪声值为0.5时,性能得到提升,跟踪精度显著提高。
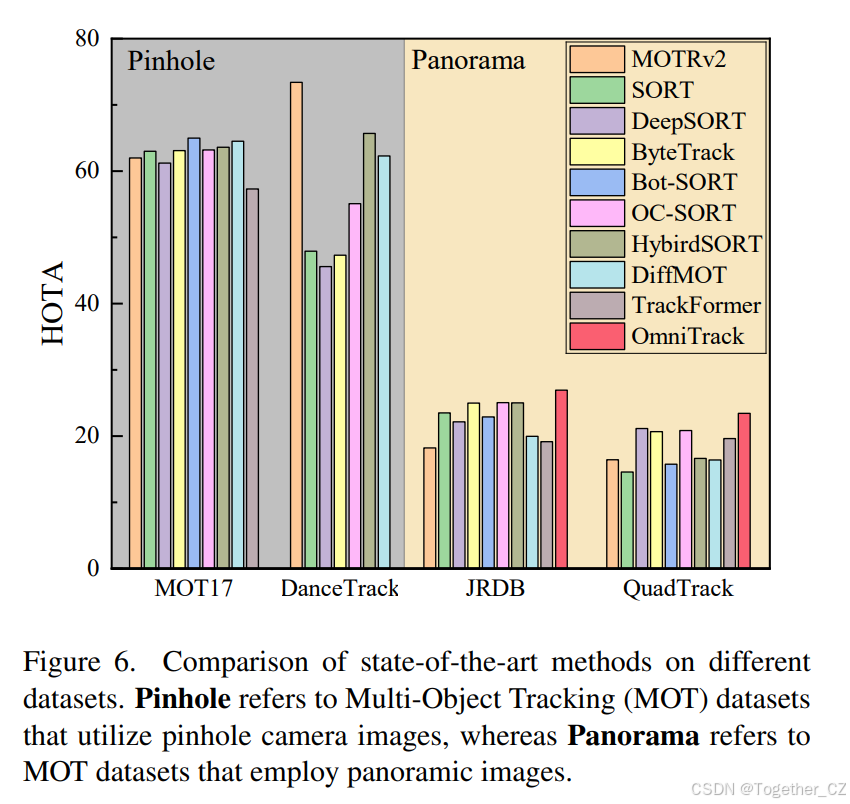
8.4. 多目标跟踪数据集的进一步分析
为了直观地评估现有最新方法在全景MOT数据集上的整体性能,我们将基于针孔相机的MOT17和DanceTrack数据集与全景数据集JRDB和QuadTrack进行了比较。如图6所示,MOTRv2在DanceTrack上实现了73.4%的HOTA,但在JRDB上仅为18.22%,下降了55.18%。同样,ByteTrack在MOT17上实现了63.1%的HOTA,但在QuadTrack上仅为20.66%,下降了42.44%。总体而言,全景数据集上的HOTA比针孔数据集低约30%。更重要的是,OmniTrack在两个全景数据集上的性能均显著优于现有最新方法,这标志着全景多目标跟踪领域的一个重大进步。
9. 最新方法的复现
由于在JRDB和QuadTrack数据集上缺乏现有最新方法的性能记录,本文中所有比较实验均为独立复现。在复现过程中,我们优先使用官方源代码,前提是代码可执行。参数选择基于原始论文中的建议,旨在实现最佳性能。
9.1. 端到端(E2E)范式的方法
TrackFormer:为了复现TrackFormer方法,我们使用了官方源代码,并将其应用于JRDB和QuadTrack数据集。我们的实现使用了Deformable DETR的COCO预训练权重,结合迭代边界框细化以提高跟踪精度。该模型在单个GPU上进行训练,批量大小为2。为了使模型适应JRDB和QuadTrack数据集,我们重新格式化了数据,以符合MOT20格式,这是多目标跟踪挑战中广泛使用的格式。训练进行了30个周期,初始学习率为2×10^-4,每10个周期衰减10倍,符合官方指南。所有其他参数保持不变,使用默认值。
MOTR:在复现MOTR方法时,我们发现在使用TrackFormer方法中最初使用的权重进行训练时遇到了挑战。因此,我们选择在JRDB数据集上使用MOT17数据集的预训练权重进行模型训练,该数据集专门用于多目标跟踪任务。该模型在单个GPU上进行微调,批量大小为1。为了使模型适应JRDB数据集,我们修改了数据格式以匹配DanceTrack格式。这种格式调整确保了与MOTR框架输入要求的兼容性。该模型训练了25个周期以确保模型收敛,初始学习率为2×10^-4。根据官方源代码和我们的经验,学习率每5个周期衰减10倍。所有其他参数保持默认值,符合官方指南。
MOTRv2:预训练权重与TrackFormer中使用的相同。该模型在单个GPU上进行训练,批量大小为1。为了使模型适应JRDB和QuadTrack数据集,我们将数据转换为DanceTrack格式。由于MOTRv2高度依赖于检测结果,我们在训练集中使用了真实检测结果以确保最佳跟踪性能。对于测试集,为了保持公平性,我们使用自己的检测器生成检测结果。该模型的训练周期为JRDB的15个周期和QuadTrack的25个周期,之后模型停止收敛。初始学习率设置为2×10^-4,每5个周期衰减10倍,与MOTR中的设置一致。所有其他参数保持默认值,如官方源代码中所指定。
9.2. 基于检测的跟踪(TBD)范式的方法
HybridSORT:在JRDB和QuadTrack数据集上复现HybridSORT方法时,我们使用了官方源代码。HybridSORT提供了两种变体:基于外观的版本和无外观的版本。在本文中进行的所有实验中,均使用了HybridSORT的无外观版本。对于参数选择,我们在JRDB和QuadTrack数据集上应用了相同的值:轨迹阈值设置为0.6,IoU阈值设置为0.15,与DanceTrack数据集中使用的设置一致。所有其他参数保持默认值,如官方实现中所指定。
SORT:作为一种开创性的TBD范式方法,SORT有多个实现版本。然而,由于原始源代码的年代久远,它已经被废弃。在本文中,我们选择基于HybridSORT的源代码复现SORT方法。对于JRDB和QuadTrack数据集,我们将轨迹阈值设置为0.6,IoU阈值设置为0.3,与DanceTrack数据集中使用的SORT方法的设置一致。所有其他参数保持默认值,符合官方指南。
DeepSORT:在本文的比较实验中,我们遇到了DeepSORT源代码库的兼容性问题,它与Torch模型不兼容,这给复现过程带来了困难。因此,我们选择使用HybridSORT的代码复现DeepSORT算法。需要注意的是,DeepSORT是一种基于外观的跟踪方法,理论上需要分别为JRDB和QuadTrack数据集训练外观模块。然而,由于缺乏关于如何训练外观权重的明确指导,我们使用了源代码中提供的预训练外观权重,具体是googlenet part8 all xavier ckpt 56.h5检查点。所有其他参数保持默认值,未进行修改。
ByteTrack和OC-SORT:在复现ByteTrack和OC-SORT时,我们选择使用它们的官方源代码,以确保一致性和准确性。所有参数设置直接取自官方演示配置,这些配置专门用于优化性能。这些设置统一应用于JRDB和QuadTrack数据集,以保持公平的比较。这种方法允许对这两个跟踪算法在我们的数据集上的性能进行可靠的评估,同时遵循原始实现指南。
BoT-SORT:BoT-SORT是一种集成多种技术的TBD范式跟踪器,包括使用外观特征。对于JRDB和QuadTrack数据集,我们使用fast-reid训练外观特征模型。所有其他参数保持不变,如原始BoT-SORT源代码中所指定,确保与默认配置的一致性。
9.3. YOLO11检测
在TBD范式的跟踪中,性能在很大程度上依赖于检测器的结果。我们选择了YOLO系列中性能最佳的YOLO11作为基线进行比较。为了增强感知能力,我们选择了参数最多的YOLO11系列模型YOLO11-X进行训练。训练配置包括100个周期,图像大小为960,批量大小为8,所有其他设置保持默认值。训练完成后,使用最佳检查点的模型权重(best.pt)对测试集中的图像进行推理。保留置信度得分大于阈值0.1的检测结果,并将其作为TBD范式跟踪器的输入。
10. 讨论
10.1. 社会影响力
OmniTrack框架有望通过改善全景环境下的多目标跟踪(MOT),增强自主系统的安全性和可靠性,这对于自动驾驶汽车和机器人等领域至关重要。其处理大视场同时减轻失真的能力,确保了在动态真实世界环境中的稳健性能。这些进步有潜力惠及众多行业,特别是在视觉障碍人士的导航、无人机辅助救援和危险物体检测等领域。此外,开发的QuadTrack数据集旨在填补高速传感器运动和大视场应用领域的空白。我们计划将数据集和相关代码公开,以加速全景多目标跟踪领域的发展,最终提升自动化系统在日常生活中的安全性、效率和包容性。然而,深度模型不可避免地会出现一些误检和漏检,其实际部署必须考虑深度神经网络的固有不确定性。此外,尽管该技术旨在用于良性应用,但存在被误用的微小风险,包括潜在的军事应用,且可能不适合隐私敏感环境。
10.2. 限制与未来工作
尽管OmniTrack在全景图像跟踪领域展现出强大的潜力,但仍存在一些限制。虽然在目标严重遮挡时不会出现ID混淆,但仍可能发生轨迹丢失。未来的研究可以专注于解决目标遮挡问题,一个有希望的解决方案是多传感器融合,例如整合点云深度信息以减轻遮挡。这种方法可以将2D跟踪扩展到3D跟踪。此外,采用多个协作并共享传感器信息的代理,可能会增强跟踪性能,最终减少由于遮挡导致的轨迹丢失,并提高系统的整体鲁棒性。
11. 可视化
我们在JRDB和QuadTrack数据集上可视化了最终的跟踪结果,如图9和图10所示。在这些图像中,红色箭头突出显示了轨迹丢失且未正确跟踪的实例,而黄色箭头指示身份混淆导致的ID切换。在图9中,对于JRDB数据集,我们观察到OmniTrack能够准确跟踪目标,即使在人数众多的场景中,也没有出现ID切换或轨迹丢失。相比之下,ByteTrack和SORT都出现了轨迹丢失,而OC-SORT则出现了多次ID切换。在图10中,对于QuadTrack数据集,前景中骑自行车者的跟踪保持完整,而OC-SORT、ByteTrack和SORT都在第247帧出现了轨迹丢失。这些例子证明了OmniTrack卓越的召回能力,进一步验证了我们的反馈机制和FlexiTrack实例在大视场场景中准确保持目标的有效性。

图8. 建立的QuadTrack数据集示例。QuadTrack数据集涵盖了各种场景,包括不同的校园、街道和低光照环境,并为每种场景提供了机器生成的标签。这些标注的场景展示了数据集的多样性和复杂性,为不同真实世界背景下多目标跟踪的挑战提供了见解。

图9. 在公共JRDB数据集上进行的可视化比较。该可视化比较了OmniTrack、SOTA、ByteTrack和OC-SORT方法在JRDB验证集上的性能。图中的红色箭头表示轨迹未正确跟踪的实例,导致跟踪丢失,而黄色箭头突出显示了轨迹ID混淆的情况,即发生了ID切换。

图10. 在建立的QuadTrack数据集上进行的可视化比较。该可视化比较了OmniTrack、SOTA、ByteTrack和OC-SORT方法在QuadTrack测试集上的性能。图中的红色箭头表示轨迹未正确跟踪的实例,导致跟踪丢失。



















 2554
2554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











