











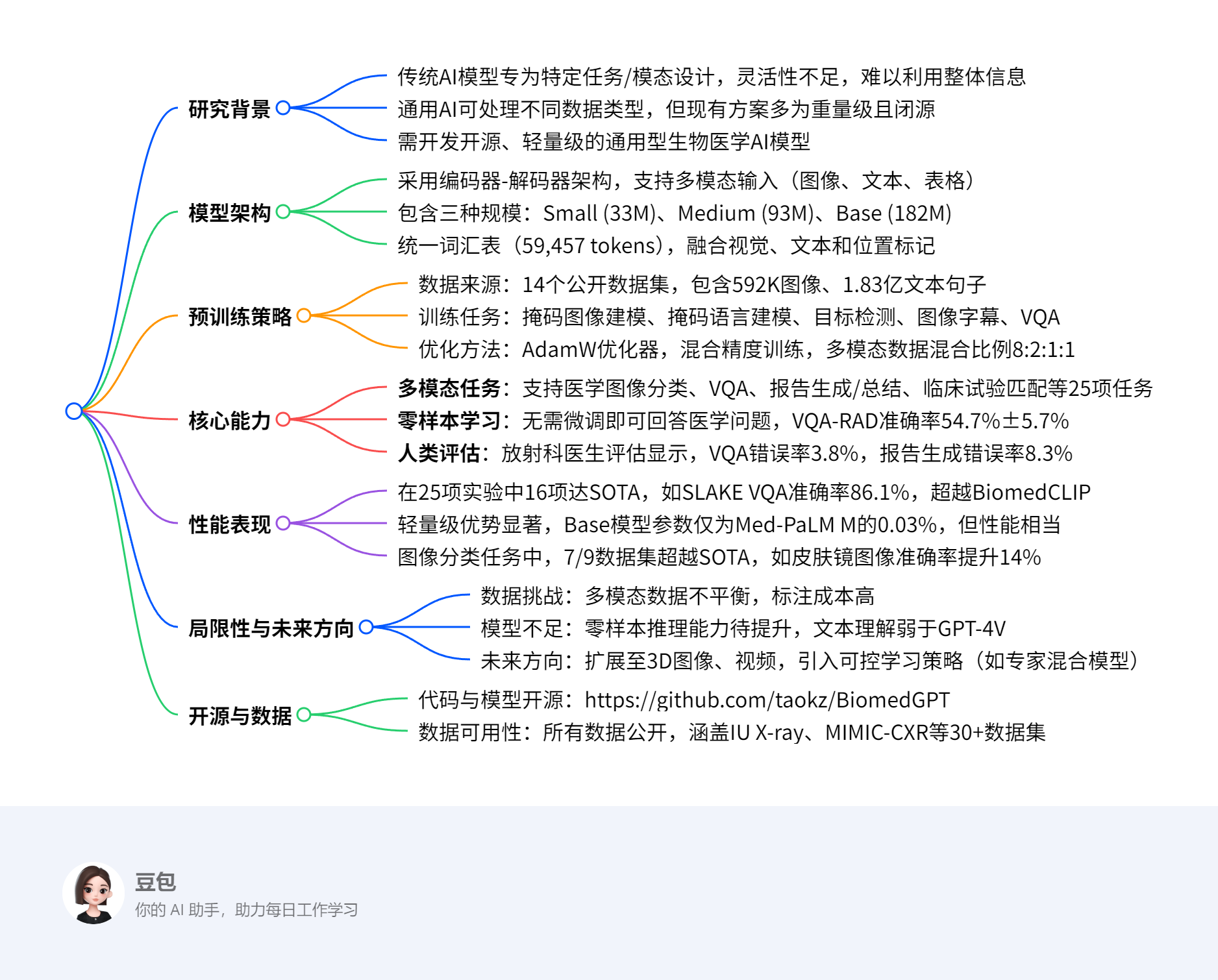
BiomedGPT:用于多生物医学任务的通用视觉 - 语言基础模型
Kai Zhang1, Rong Zhou1, Eashan Adhikarla1, Zhiling Yan1, Yixin Liu1, Jun Yu1, Zhengliang Liu2, Xun Chen3, Brian D. Davison1, Hui Ren4, Jing Huang5,6, Chen Chen7, Yuyin Zhou8, Sunyang Fu9, Wei Liu10, Tianming Liu2, Xiang Li4*, Yong Chen5,11,12,13, Lifang He1*, James Zou14,15, Quanzheng Li4, Hongfang Liu9, and Lichao Sun1*
1 计算机科学与工程系,利哈伊大学,宾夕法尼亚州,美国
2 计算机学院,佐治亚大学,佐治亚州,美国
3 三星美国研究院,加利福尼亚州,美国
4 放射科,马萨诸塞州总医院和哈佛医学院,马萨诸塞州,美国
5 生物统计学、流行病学与信息学系,宾夕法尼亚大学,宾夕法尼亚州,美国
6 政策实验室,费城儿童医院,宾夕法尼亚州,美国
7 计算机视觉研究中心,中佛罗里达大学,佛罗里达州,美国
8 计算机科学与工程系,加州大学圣克鲁兹分校,加利福尼亚州,美国
9 麦克威廉姆斯生物医学信息学院,德克萨斯大学健康科学中心休斯顿分校,德克萨斯州,美国
10 放射肿瘤科,梅奥诊所,亚利桑那州,美国
11 健康人工智能与证据合成中心(CHASE),宾夕法尼亚大学,宾夕法尼亚州,美国
12 宾夕法尼亚大学生物医学信息研究所(IBI),宾夕法尼亚州,美国
13 伦纳德・戴维斯卫生经济研究所,宾夕法尼亚州,美国
14 生物医学数据科学系,斯坦福大学医学院,加利福尼亚州,美国
15 计算机科学系,斯坦福大学,加利福尼亚州,美国
数据可用性
本研究中的所有数据均公开可用,可从以下来源获取:IU X-ray 和 PEIR GROSS(GitHub - nlpaueb/bioCaption: Diagnostic Captioning)、MedICat(GitHub - allenai/medicat: Dataset of medical images, captions, subfigure-subcaption annotations, and inline textual references)、PathVQA(https://github.com/UCSD-AI4H/PathVQA)、SLAKE 1.0(https://www.medvqa.com/slake/)、DeepLesion(https://nihcc.app.box.com/v/DeepLesion)、OIA-DDR(GitHub - nkicsl/OIA: Ophthalmic Image Analysis Dataset)、CheXpert-v1.0-small(CheXpert_v1.0_small | Kaggle)、CytoImageNet(CytoImageNet | Kaggle)、ISIC 2020(https://challenge2020.isic-archive.com)、Retinal Fundus(https://www.kaggle.com/c/diabeticretinopathy-detection)、MIMIC-III Clinic Notes(Clinical Admission Notes from MIMIC-III Dataset | Papers With Code)、NCBI BioNLP(BioNLP Corpus - NIH)、PubMed 摘要源自 BLUE 基准(GitHub - ncbi-nlp/BLUE_Benchmark: BLUE benchmark consists of five different biomedicine text-mining tasks with ten corpora.)、VQA-RAD(OSF | Visual Question Answering in Radiology (VQA-RAD))、CBIS-DDSM(CBIS-DDSM: Breast Cancer Image Dataset | Kaggle)、SZ-CXR 和 MC-CXR 可通过(http://archive.nlm.nih.gov/repos/chestImages.php)联系获取、MIMIC-CXR(MIMIC-CXR-JPG - chest radiographs with structured labels v2.1.0)、MedNLI(MedNLI - A Natural Language Inference Dataset For The Clinical Domain v1.0.0)、TREC2022(2022 TREC Clinical Trials Track)、SEER(https://seer.cancer.gov)、MIMIC-III(MIMIC-III Clinical Database v1.4)、HealthcareMagic(https://github.com/UCSD-AI4H/Medical-Dialogue-System)、MeQSum(https://huggingface.co/datasets/sumedh/MeQSum)、MedMNIST v2(https://medmnist.com)、ROCO(GitHub - razorx89/roco-dataset: Radiology Objects in COntext (ROCO): A Multimodal Image Dataset)、用于零样本预测的 RSNA 肺炎检测挑战赛(2018)随机抽样子集(RSNA Pneumonia Detection Challenge (2018) | RSNA)。MedMNIST-Raw 基于多个来源整理,包括 NCT-CRC-HE-100K(结肠病理)(100,000 histological images of human colorectal cancer and healthy tissue)、HAM10000(皮肤镜检查)(GitHub - ptschandl/HAM10000_dataset: Tools for workup of the HAM10000 dataset)、OCT & Chest X-ray(Large Dataset of Labeled Optical Coherence Tomography (OCT) and Chest X-Ray Images - Mendeley Data)、乳房超声(https://scholar.cu.edu.eg/Dataset_BUSI.zip)、血细胞显微镜(A dataset for microscopic peripheral blood cell images for development of automatic recognition systems - Mendeley Data)、肝脏肿瘤分割基准(LiTS)(CodaLab - Competition)。用于人类评估的 VQA 数据源自 Medical-Diff-VQA(https://physionet.org/content/medical-diffvqa/1.0.0/),排除涉及差异的问题,因为这些问题需要双图像输入。用于人类评估的报告生成和总结样本从 MIMIC-CXR 中提取。本文中使用的指令遵循数据源自 PubMed(https://pubmed.ncbi.nlm.nih.gov),遵循 LLaVA-Med(LLaVA-Med/download_data.sh at main · microsoft/LLaVA-Med · GitHub)的方法,并与 PathVQA 和 SLAKE 的训练集结合。我们还在扩展数据表 2 中提供了主要数据集的更多详细信息。
代码可用性
预训练和微调模型以及用于训练、推理和数据预处理的源代码可在GitHub - taokz/BiomedGPT: BiomedGPT: A Generalist Vision-Language Foundation Model for Diverse Biomedical TasksBiomedGPT: A Generalist Vision-Language Foundation Model for Diverse Biomedical Tasks - taokz/BiomedGPT![]() https://github.com/taokz/BiomedGPT获取。
https://github.com/taokz/BiomedGPT获取。
摘要
传统生物医学人工智能(AI)模型专为特定任务或模态设计,在实际部署中灵活性有限,且难以利用整体信息。通用 AI 因其在解释不同数据类型和为多样化需求生成定制输出方面的多功能性,有望解决这些局限性。
然而,现有的生物医学通用 AI 解决方案通常对研究人员、从业者和患者来说是重量级且闭源的。在此,我们提出 BiomedGPT,这是首个开源且轻量级的视觉 - 语言基础模型,设计为能够执行各种生物医学任务的通用模型。
BiomedGPT 在 25 项实验中的 16 项中取得了最先进的结果,同时保持了计算友好的模型规模。我们还进行了人类评估,以评估 BiomedGPT 在放射学视觉问答、报告生成和总结方面的能力。
BiomedGPT 在问答中表现出强大的预测能力,错误率低至 3.8%;在撰写复杂放射学报告时表现令人满意,错误率为 8.3%;在总结能力方面具有竞争力,偏好得分与人类专家几乎相当。我们的方法表明,使用多样化数据进行有效训练可以开发出更实用的生物医学 AI,以改善诊断和工作流程效率。
引言
人工智能(AI)技术,尤其是基于 Transformer 的基础模型,已在解决广泛的生物医学任务中展现出强大能力,包括放射学解读、临床信息总结和精确疾病诊断 [1]。然而,当今大多数生物医学模型作为专家系统,专为特定任务和模态定制 [2]。
这种专业化在模型部署中带来了重大挑战,尤其是在人们对使用 AI 进行精准医疗和以患者为中心的护理的兴趣日益增长的背景下,这些应用需要整合和分析多样化的数据类型和患者特定细节 [3,4]。
此外,AI 在狭窄学科中的过度专业化往往无法提供必要的综合见解,以在实际场景中协助人类医生,因为在实际场景中信息流动可能缓慢且零散 [2,5]。通用生物医学 AI 通过创建能够跨不同任务通用且足够稳健以有效处理各种医疗数据复杂性的模型,有望克服这些局限性 [2,6]。`
通用基础模型的出现 [7,8] 为生物医学通用 AI 的发展提供了一个有前景的原型。这些先进模型将不同的数据集(无论其模态、任务或领域如何)序列化为统一的标记序列,然后使用 Transformer 神经网络进行处理 [9]。
与主要设计用于处理文本数据的大型语言模型 [10,11] 不同,通用模型可以同时处理文本和视觉信息。这一能力对于复杂的生物医学应用至关重要,因为在这些应用中,临床文本和放射成像等不同数据类型的整合对于准确分析和决策至关重要。
此外,通用模型表现出令人印象深刻的多任务处理能力,通过减少维护众多专注于狭窄领域的专家模型的需求,显著简化了 AI 系统的部署和管理。
结果
基于大型多样化数据集的预训练

图1:BiomedGPT可处理多样化模态并执行多用途任务。(a) BiomedGPT主要聚焦于视觉和文本输入,但也可通过序列化处理表格数据。(b) BiomedGPT支持的下游视觉-语言任务示例展示了其多功能性。通过轻量级、任务特定的微调,可纳入额外任务以满足更多临床需求。(c) 与BiomedGPT相关的临床应用案例示例包括输入可能包含图像和文本或纯文本的任务,模型通过生成回答(“A”)来响应查询(“Q”)。得益于其统一的框架设计和对生物医学数据的全面预训练,BiomedGPT具有高度适应性,可应用于各种下游任务。
左侧(Multimodal Data 及下方任务示例)
-
Multimodal Data(多模态数据):呈现 BiomedGPT 可处理的数据类型,涵盖图像(如 MRI、X-ray 等)和文本(如 Publications、EHRs 等),体现模型对多样化生物医学数据的兼容性。
-
任务示例:
-
Pathology/Radiology VQA(病理 / 放射学视觉问答):以病理切片、胸部 X 光图像为输入,围绕图像关联的医学问题问答,测试模型图像理解与医学知识结合能力。
-
Report Generation(报告生成):输入胸部 X 光图像,模型生成包含医学发现的报告,辅助医生高效产出诊断文档。
-
Mortality Prediction(死亡率预测):结合患者文本病历,模型预测出院前患者结局,展现文本数据处理与临床预测应用。
-
Treatment Suggestion(治疗建议):依据患者表格化医疗数据,模型给出放疗、化疗等治疗方案建议,体现对结构化数据的利用。
-
Clinical Trial Matching(临床试验匹配):对比患者病历与试验详情,判断患者是否符合试验入组条件,助力临床研究受试者筛选。
-
右侧(b 部分及任务示例)
-
b 部分(任务分类轮盘):将 BiomedGPT 支持任务分类展示,包含文本理解(如 Clinical Matching)、文本总结(如 Summarization)、视觉问答(如 Pathology/Radiology VQA )、图像分类(如 Disease Diagnosis )等,清晰呈现模型多任务覆盖范围,说明其可在不同生物医学场景发挥作用。
-
任务示例:
-
Disease Diagnosis(疾病诊断):输入乳腺超声图像,模型判断疾病类型(如乳腺癌),是图像分类在诊断场景的应用。
-
Lesion Detection(病变检测):依据皮肤图像,识别病变类型(如黑色素瘤 ),辅助皮肤疾病诊断。
-
Conversation Summarization(对话总结):针对医患对话文本,模型提炼对话要点,简化信息,方便医疗记录与回顾。
-
Report Summarization(报告总结):输入医学报告文本,模型生成简洁总结,提炼关键医疗信息 。
-
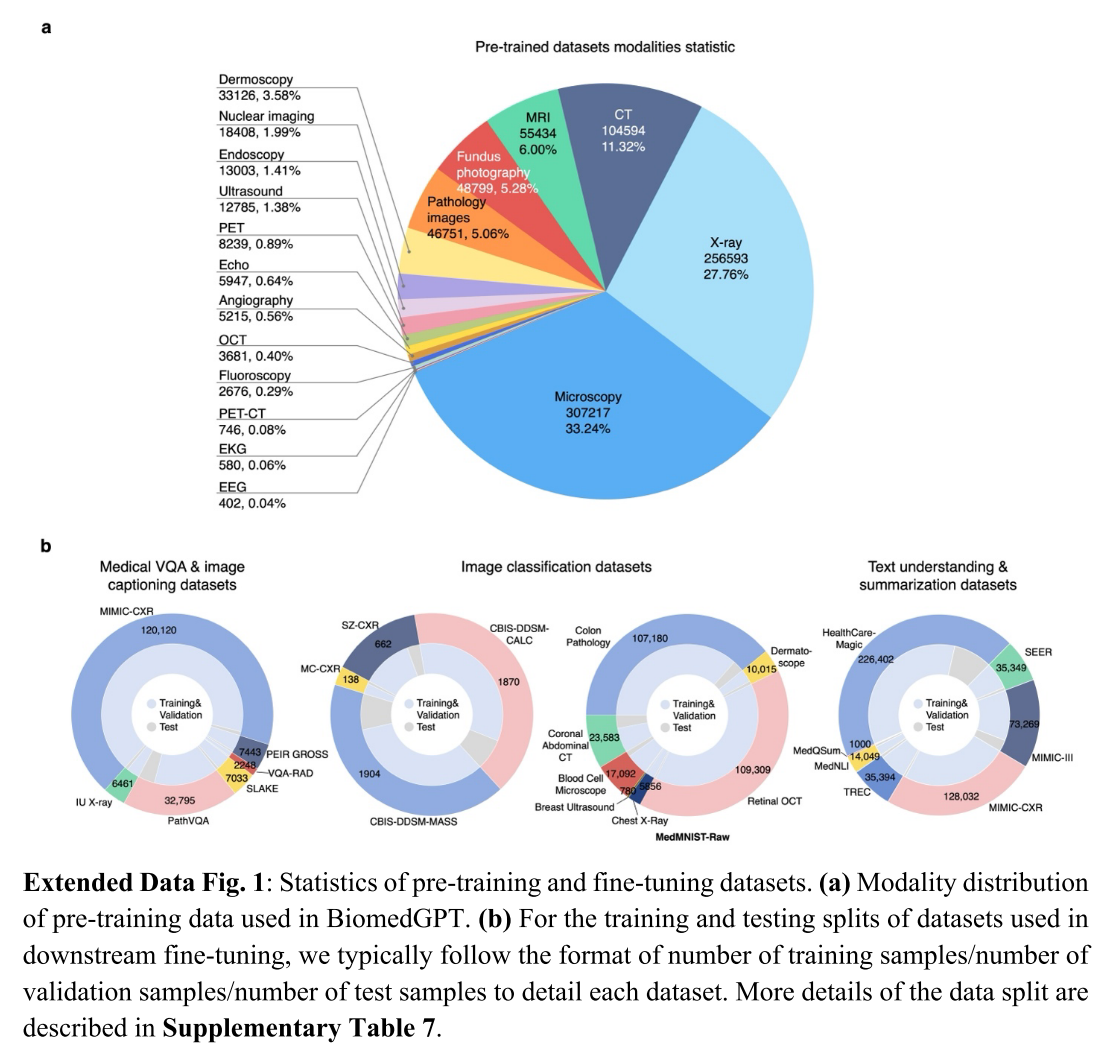
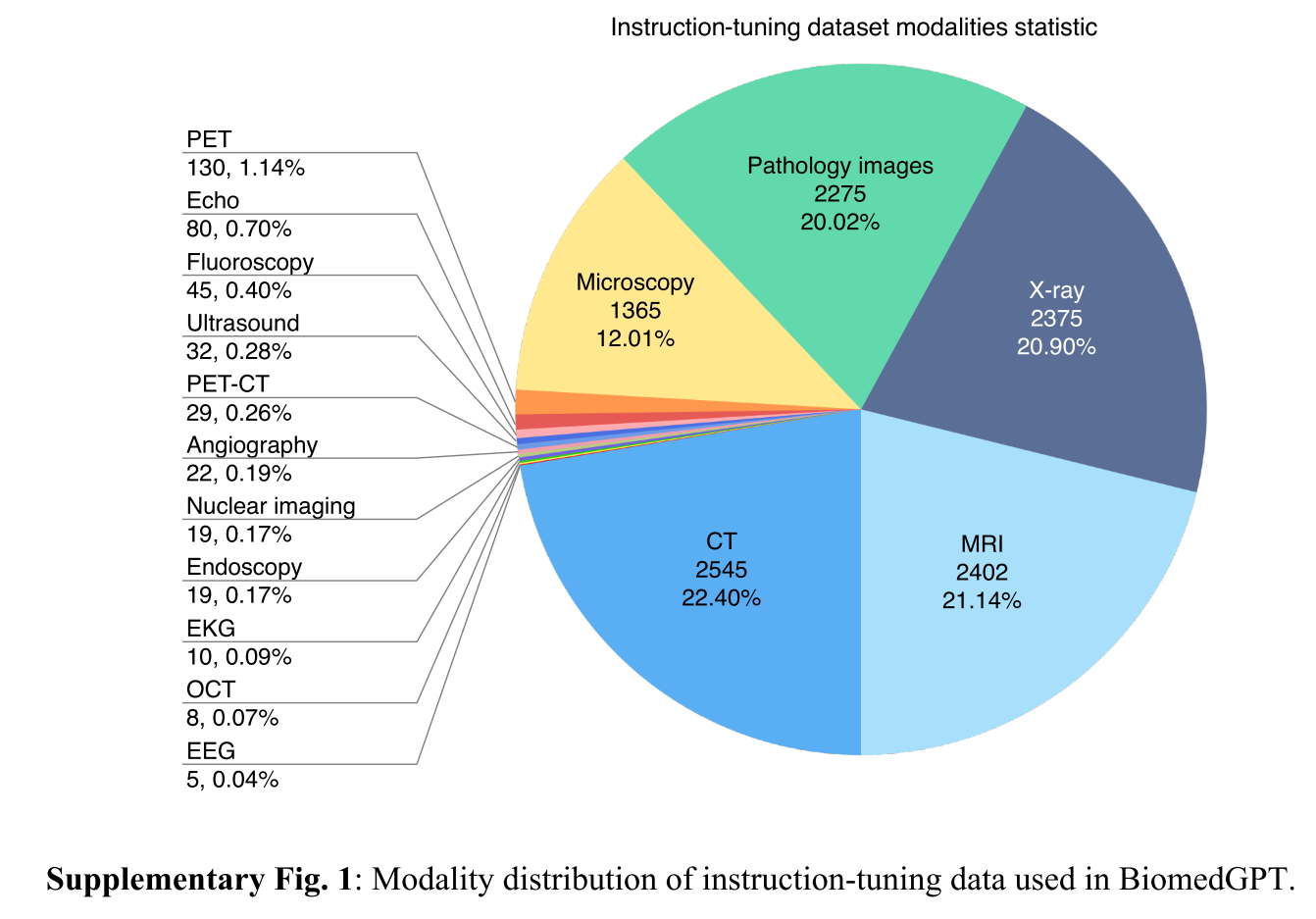
BiomedGPT 利用包括掩码建模和监督学习在内的预训练技术,旨在通过学习跨多样任务的海量数据来建立稳健且通用的数据表示(扩展数据表 3)。为了最大限度地提高 BiomedGPT 的泛化能力,我们从 14 个免费可用的数据集中获取数据,确保模态的多样性(图 1a,图 2c-d 和扩展数据图 1a)。
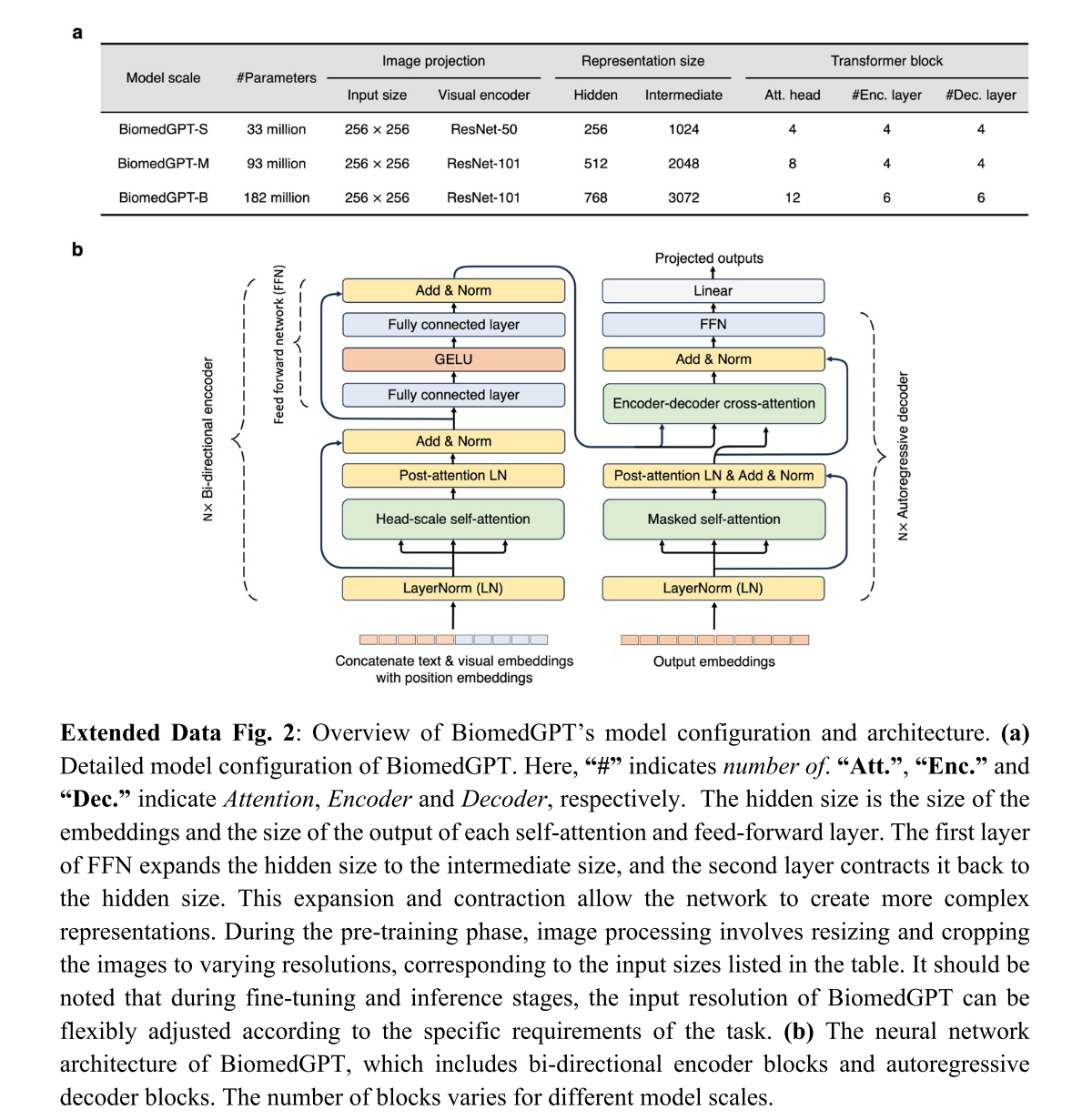
此外,为了研究 BiomedGPT 在不同规模下的表现,我们专门引入了三种版本的模型:BiomedGPT-S、BiomedGPT-M 和 BiomedGPT-B,分别对应小型、中型和基础型(图 2a 和扩展数据图 2-3)。
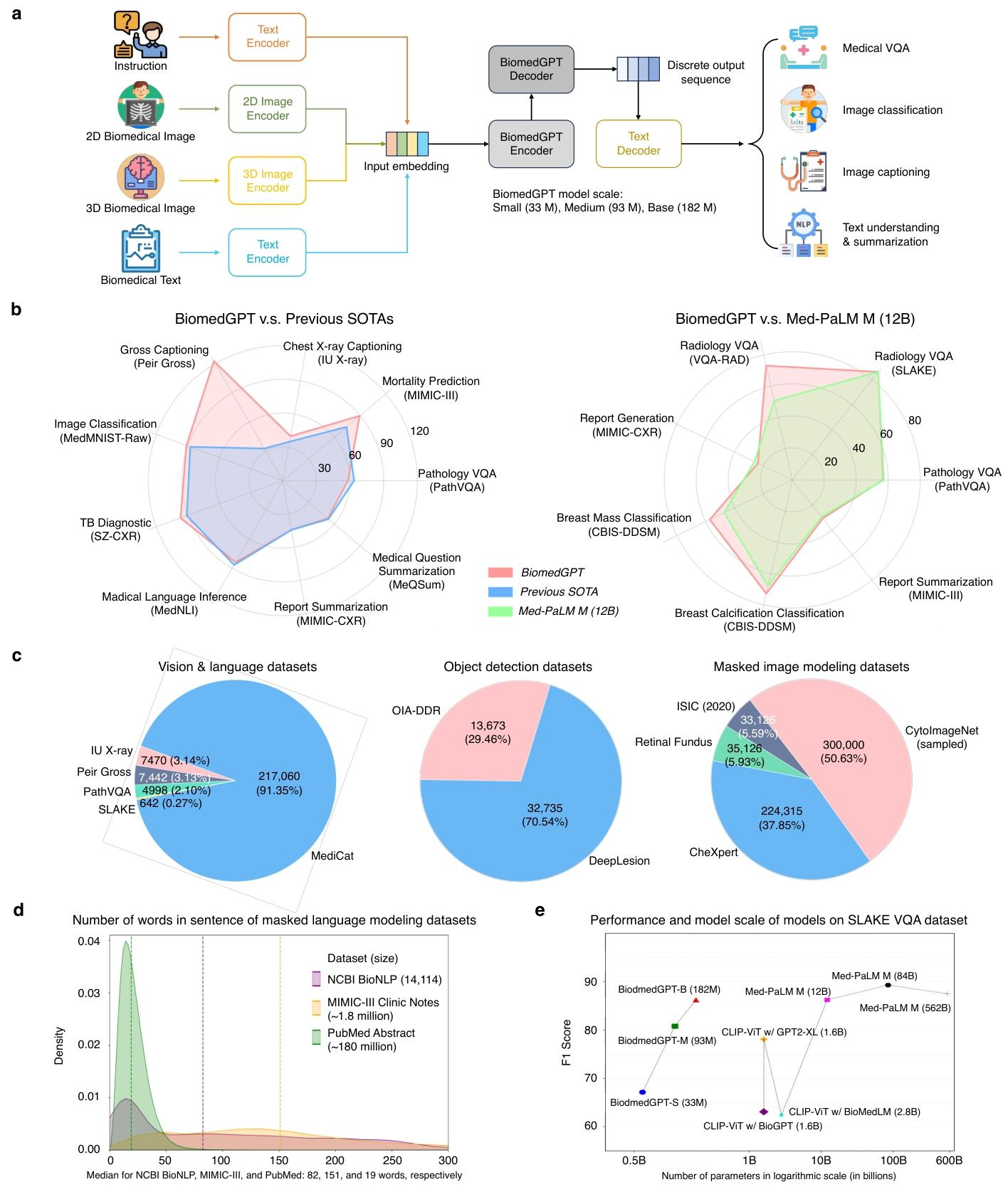
图 2:BiomedGPT 概述:工作流程、性能和预训练数据集。(a) BiomedGPT 处理多模态输入并执行各种下游任务的图形说明。每个任务的预期输出形式是通过向模型输入特定指令来确定的。(b) 对比性能分析:该图将 BiomedGPT 的成果与先前的最先进(SOTA)结果以及 Med - PaLM M(12B)进行对比。评估指标包括:图像分类、医学语言推理和视觉问答(VQA)的准确率(与 SOTA 结果对比);图像字幕的 CIDEr 指标;文本总结的 ROUGE - L 指标;视觉问答的加权 F1 分数(与 Med - PaLM M 对比);以及乳腺肿块相关的 F1 - macro 指标钙化分类(同样与 Med - PaLM M 进行对比)。(c) 预训练数据集的分布情况,包括作为视觉与语言数据集的图像字幕和视觉问答(VQA)数据集、目标检测数据集,以及用于掩码图像建模的纯图像数据集。(d) 纯文本预训练数据集中每句话单词数量的密度图。(e) 与规模相关的性能对比:BiomedGPT 在 SLAKE 视觉问答数据集上表现出更优性能,即便其参数数量明显少于同类模型 。
下游任务的微调
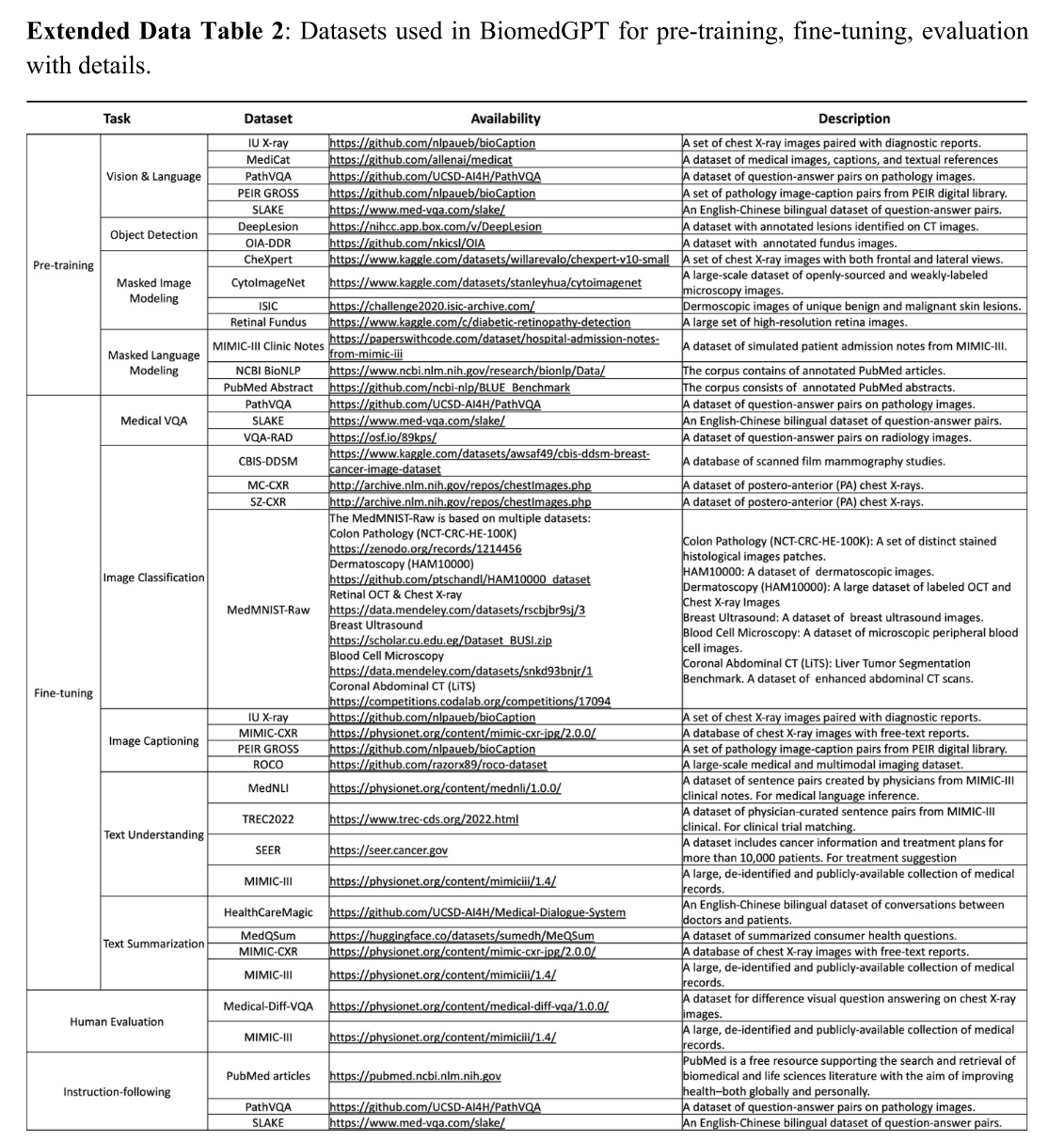
多任务处理是通用 AI 的基础。遵循先前的生物医学研究 [14,15,16] 并追求足够有效的性能,我们主要选择对模型进行微调以适应各种生物医学任务(图 1b 和图 1c)。我们选择下游任务的依据是它们在现实世界中的应用潜力:医学图像分类通常有助于疾病诊断和病变识别;文本理解和总结可以简化临床操作,例如减轻医生记录撰写的负担。此外,图像字幕和视觉问答(VQA)为未来的医疗聊天机器人奠定了基础,解决了普通语言可能存在歧义但医学术语对大多数人来说难以理解的挑战。本文中使用的下游数据集的完整统计数据见扩展数据图 1b。
BiomedGPT 轻量但在多模态任务中具有竞争力
我们在两个主要的多模态任务(VQA 和图像字幕)上对 BiomedGPT 进行了微调,每个任务使用三个下游数据集。VQA 数据集包括涵盖五种不同解剖结构的放射学数据(VQA-RAD [17] 和 SLAKE [18]),以及捕捉身体和组织特定细节的病理学数据(PathVQA [19])。
对于字幕任务,我们纳入了胸部 X 光数据集(IU X-ray [20] 和 MIMIC-CXR [21])以及来自 PEIR GROSS [22] 的临床照片。为了进行比较,我们将 BiomedGPT 与每个数据集的领先模型进行了基准测试 [15,23,24,25]。
我们通过将生成的答案与真实答案进行比较来评估模型的 VQA 性能。我们的 BiomedGPT 模型的整体准确性详见扩展数据表 1。
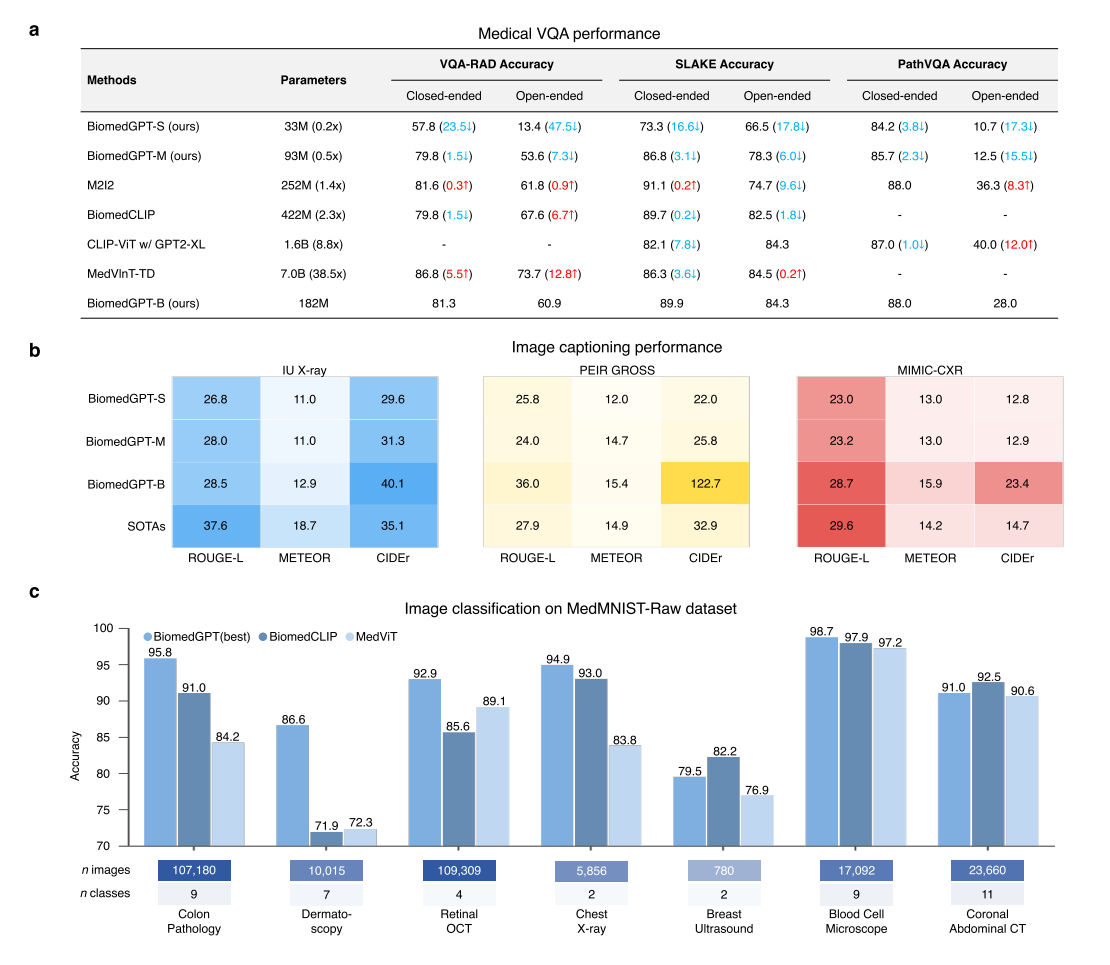
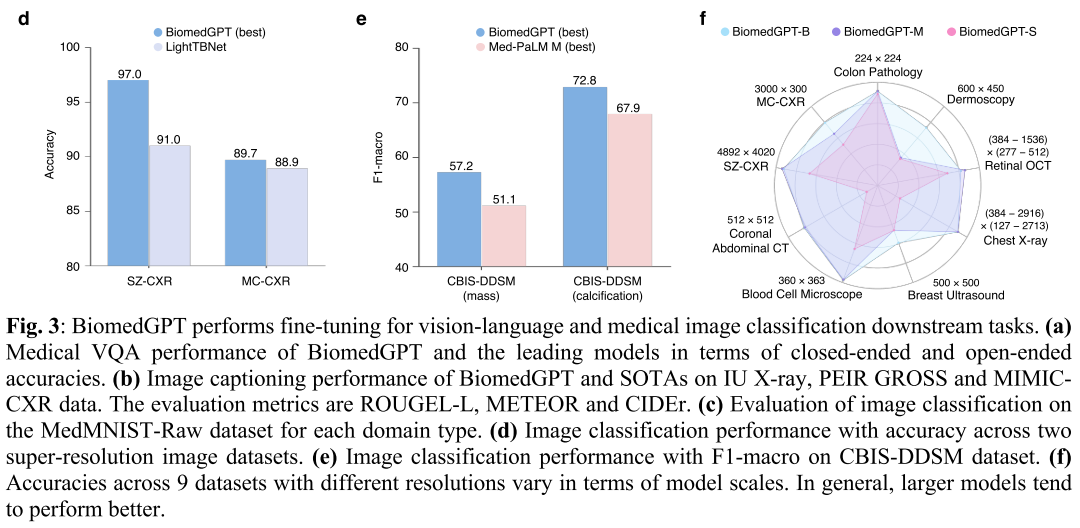 图 3:BiomedGPT 针对视觉 - 语言和医学图像分类下游任务开展微调。(a) BiomedGPT 与领先模型在医学视觉问答(VQA)任务上的表现,对比了封闭式和开放式问题的准确率。(b) BiomedGPT 与现有最优模型(SOTAs)在 IU X 射线、PEIR GROSS 和 MIMIC - CXR 数据集上的图像字幕生成表现,评估指标为 ROUGE - L、METEOR 和 CIDEr 。(c) 在 MedMNIST - Raw 数据集上,针对不同领域类型的图像分类评估。(d) 在两个超分辨率图像数据集上,以准确率衡量的图像分类表现。(e) 在 CBIS - DDSM 数据集上,以 F1 - macro 指标衡量的图像分类表现。(f) 不同规模的模型在 9 个不同分辨率数据集上的准确率情况,总体而言,规模更大的模型往往表现更优 。
图 3:BiomedGPT 针对视觉 - 语言和医学图像分类下游任务开展微调。(a) BiomedGPT 与领先模型在医学视觉问答(VQA)任务上的表现,对比了封闭式和开放式问题的准确率。(b) BiomedGPT 与现有最优模型(SOTAs)在 IU X 射线、PEIR GROSS 和 MIMIC - CXR 数据集上的图像字幕生成表现,评估指标为 ROUGE - L、METEOR 和 CIDEr 。(c) 在 MedMNIST - Raw 数据集上,针对不同领域类型的图像分类评估。(d) 在两个超分辨率图像数据集上,以准确率衡量的图像分类表现。(e) 在 CBIS - DDSM 数据集上,以 F1 - macro 指标衡量的图像分类表现。(f) 不同规模的模型在 9 个不同分辨率数据集上的准确率情况,总体而言,规模更大的模型往往表现更优 。
图表 (b):图像字幕生成任务表现(Image captioning performance)
聚焦 BiomedGPT 不同规模(S/M/B)与现有最优模型(SOTAs),在 IU X-ray、PEIR GROSS、MIMIC-CXR 三个数据集上的对比,用 ROUGE-L、METEOR、CIDEr 指标衡量生成文本与参考文本的匹配度:
感觉这里的几个评价指标可以借用一下:
-
指标含义:
-
ROUGE-L:基于最长公共子序列,衡量文本摘要 / 字幕的召回率;
-
METEOR:综合精确率、召回率,评估语义匹配度;
-
CIDEr:侧重 n-gram 匹配,突出图像描述的准确性。
-
-
关键结论:
-
BiomedGPT-B(基础规模)在 PEIR GROSS 数据集的 CIDEr 指标达 122.7,大幅超越其他模型,说明其生成的字幕与参考文本语义契合度极高;
-
整体趋势:模型规模越大(S→M→B),字幕生成质量越高,尤其 CIDEr 指标提升显著,体现大模型在语言生成任务的优势。
-
图表 (c):MedMNIST-Raw 数据集图像分类(Image classification on MedMNIST-Raw dataset)
对比 BiomedGPT(最优版本)、BiomedCLIP、MedViT 三种模型,在 结肠病理、皮肤镜、视网膜 OCT 等 7 类医学图像分类任务的准确率:
-
数据维度:
-
横轴:不同医学领域(如 Colon Pathology、Dermoscopy 等),标注了数据集样本量(n images)和类别数(n classes);
-
纵轴:分类准确率(Accuracy)。
-
-
关键结论:
-
BiomedGPT 在多数领域(如 Colon Pathology、Retinal OCT)准确率领先,结肠病理任务达 95.8%,说明其对医学图像特征的提取和分类能力更优;
-
小样本场景(如 Breast Ultrasound,仅 780 张图像)中,BiomedGPT 仍保持竞争力(82.2%),体现模型鲁棒性。
-
图表 (d):超分辨率图像数据集分类表现(SZ-CXR、MC-CXR)
对比 BiomedGPT(最优)、LightTBNet 在 深圳胸部 X 光(SZ-CXR)、蒙哥马利县胸部 X 光(MC-CXR) 数据集的分类准确率:
-
核心发现:
-
BiomedGPT 在 SZ-CXR 达 97.0%,MC-CXR 达 89.7%,均显著高于 LightTBNet,说明其对胸部 X 光图像的疾病特征识别更精准。
-
图表 (e):CBIS-DDSM 数据集分类表现(F1-macro 指标)
对比 BiomedGPT(最优)、Med-PaLM M 在 乳腺肿块(mass)、钙化(calcification) 分类任务的 F1-macro 得分(综合精确率、召回率的指标):
-
关键结论:
-
BiomedGPT 在乳腺肿块分类达 72.8%,钙化分类达 67.9%,优于 Med-PaLM M,体现其在乳腺疾病图像分类的优势。
-
图表 (f):不同分辨率数据集的规模 - 性能关联(模型尺度对比)
用雷达图展示 BiomedGPT 不同规模(B/M/S)在 9 类不同分辨率医学图像数据集的准确率表现:
-
数据维度:
-
雷达轴:涵盖 Colon Pathology(256×256)、Dermoscopy(600×450)等不同分辨率、不同领域的数据集;
-
颜色:BiomedGPT-B(基础规模,紫色)、M(中型,粉色)、S(小型,浅紫)。
-
-
关键结论:
-
模型规模越大(B>M>S),在多数数据集的准确率越高,尤其大分辨率任务(如 SZ-CXR,4892×4020)优势明显;
-
小模型(S)在部分小分辨率任务(如 Breast Ultrasound,500×500)表现接近大模型,说明分辨率与模型规模需适配。
-
整体结论
这组图表从图像字幕生成(自然语言与图像的关联)和医学图像分类(纯图像特征识别)两个维度,验证了 BiomedGPT 的多任务能力:
-
大模型规模(B 版)在语义生成(字幕)和特征分类(图像)中均表现更优;
-
对比现有 SOTA 模型,BiomedGPT 在医学图像任务中准确率、语义匹配度更突出,尤其适配复杂、多模态的生物医学场景。
值得注意的是,BiomedGPT 在 SLAKE 数据集上实现了 86.1% 的整体准确率,超过了之前由 BiomedCLIP [15] 设定的 85.4% 的最先进性能。此外,我们剖析了 “封闭式” 和 “开放式” 问答对的准确性(图 3a)。
我们的模型在封闭式问题上取得了令人鼓舞的准确率:PathVQA 上为 88.0%,比现有最先进模型 [25] 提高了 1.0%;在 SLAKE 数据集上,BiomedGPT-B 实现了 89.9% 的封闭式准确率,比 M2I2 模型 [23] 低 1.1%。
在开放式场景中,我们的模型表现出色,准确率为 84.3%,超过了 M2I2 的 74.7%。然而,对于 VQA-RAD 和 PathVQA 数据集,BiomedGPT 在开放式查询上的表现竞争力较弱,准确率分别为 60.9% 和 28.0%。
此外,我们将 BiomedGPT-B 与 Med-PaLM M(12B)进行了比较,使用论文中报告的加权 F1 分数。由于 Med-PaLM M 是闭源的,无法计算其他指标。值得注意的是,尽管 BiomedGPT-B 的规模小得多,但它取得了令人印象深刻的结果(图 2b)。
在 VQA-RAD 和 SLAKE 数据集上,BiomedGPT-B 的得分分别为 73.2% 和 85.2%,这意味着在 VQA-RAD 上显著提高了 22.5%,在 SLAKE 上略有提高 0.02%。此外,在 PathVQA 数据集上,BiomedGPT-B 的加权 F1 得分为 56.9%,仅比 Med-PaLM M 低 0.4%,而使用的模型参数少 98.5%。
对于图像字幕(图 3b),我们按照基线方法 [13,29,30,31,32,33],使用三个指标(ROUGE-L [26]、METEOR [27] 和 CIDEr [28])精心评估了机器生成文本的质量。这些评估指标有助于评估生成文本与医学专家撰写的参考文本之间的相似性和一致性,并且已显示出与医生评分者的一定一致性 [34]。
因此,在这些自然语言处理(NLP)指标上得分较高的模型可以被选为进一步人类评估的候选 [35]。在 PEIR GROSS 数据集上,我们的 BiomedGPT 模型超过了现有的最先进基准 [36],在 ROUGE-L 上提高了 8.1 个百分点,在 METEOR 上提高了 0.5 个百分点,在 CIDEr 指标上显著提高了 89.8 个点。
相反,在 IU X-ray 数据集上,BiomedGPT 实现了领先的 CIDEr 得分 40.1,比最先进模型 [31] 提高了 5.0 个点。在 MIMIC-CXR 数据集上,就 METEOR 而言,我们的模型得分为 15.9%,超过了之前由 [30] 设定的领先结果。
BiomedGPT 实现准确的医学图像分类
对于医学图像分类任务,我们按照 [37] 整理了七个包含七种模态的生物医学图像数据集,称为 MedMNIST-Raw:
(1)九种组织类型的结肠病理;
(2)七种典型色素性皮肤病变的皮肤镜图像;
(3)乳房超声(正常、良性和恶性);
(4)分为四种视网膜疾病类型的视网膜 OCT;
(5)用于肺炎与正常二元分类的胸部 X 光图像;
(6)展示八种正常细胞的血细胞显微镜图像;
(7)冠状位的 11 个腹部器官的 CT 图像。此外,我们在两个超分辨率肺部疾病数据集上测试了模型,特别关注样本有限的肺结核(TB):
(8)蒙哥马利县胸部 X 光集(MC-CXR),尺寸为 4020×4892 或 4892×4020 像素;
(9)深圳胸部 X 光集(SZ-CXR),尺寸约为 3000×3000 像素。为了与先前的工作保持一致,我们使用准确率进行评估。如图 3c-e 所示,BiomedGPT 在 5 个 epoch 的微调后,在 9 个生物医学图像分类数据集中的 7 个上超过了先前的最先进技术。
值得注意的是,在 SZ-CXR 和 MC-CXR 数据集(二元分类)上,BiomedGPT 的准确率分别为 97.0% 和 89.7%,比之前的领先模型 LightTBNet [39] 分别提高了 6.0% 和 0.8%(图 3d)。对于 MedMNIST-Raw,我们选择了生物医学成像分析中两种表现最佳的方法 MedViT(Large)[40] 和 BiomedCLIP [15] 作为基准与 BiomedGPT 进行比较。
对于 BiomedCLIP,我们添加了一个决策层并对整个模型进行了微调。BiomedGPT 在 MedMNIST-Raw 上取得了 7 个最佳准确率中的 5 个(图 3c),例如,在皮肤镜数据集上,BiomedGPT 比两个基线模型高出 14% 以上。平均而言,BiomedGPT 比 MedViT 和 BiomedCLIP 的性能分别提高了 6.1% 和 3.3%。
考虑到模型规模,可以明显看出 BiomedGPT 的性能随着规模的增大而提升(图 3f)。具体来说,在 MC-CXR 数据集上,小型模型的准确率为 75.9%,而中型模型的得分展示了 82.8%,比其小型对应模型高 6.9%,基础模型继续这一上升趋势,得分 89.7%,超过中型模型 6.9%。
然而,我们也观察到在几个数据集如 SZ-CXR 上的性能饱和。我们还测试了将图像调整为非常小尺寸的极端情况,发现性能饱和变得更加明显(补充表 1)。
此外,我们在 CBIS-DDSM 数据集 [41] 上针对 3 类病变水平的肿块分类和钙化分类,将我们的 BiomedGPT 与 Med-PaLM M 进行了基准测试。使用与 Med-PaLM M 一致的 F1-macro 作为评估指标,我们发现 BiomedGPT-B 优于所有版本的 Med-PaLM M(涵盖 12B、84B 和 584B 参数)(图 3e 和扩展数据图 4a)。这些发现突显了 BiomedGPT 令人印象深刻的效率和有效性,即使与更大规模的模型相比也是如此。
BiomedGPT 能够理解和总结临床文本
我们评估了 BiomedGPT 在理解和压缩复杂医疗叙事方面的熟练程度,这些叙事具有现实临床需求的潜力:
(1)使用 MedNLI 数据集 [42] 的医学自然语言推理,测试模型从提供的前提中推断假设的理解能力;
(2)基于监测、流行病学和最终结果(SEER)数据集 [43] 的放射治疗和化疗的治疗建议;
(3)基于入院记录的院内死亡率预测;
(4)识别适合个体患者的候选临床试验列表的临床试验匹配。此外,我们探索了 BiomedGPT 在医学文本总结中的表现,该任务应用于医患对话(MedQSum [44] 和 HealthCareMagic [45])以及放射学报告(MIMIC-CXR [21] 和 MIMIC-III [46])的数据集。
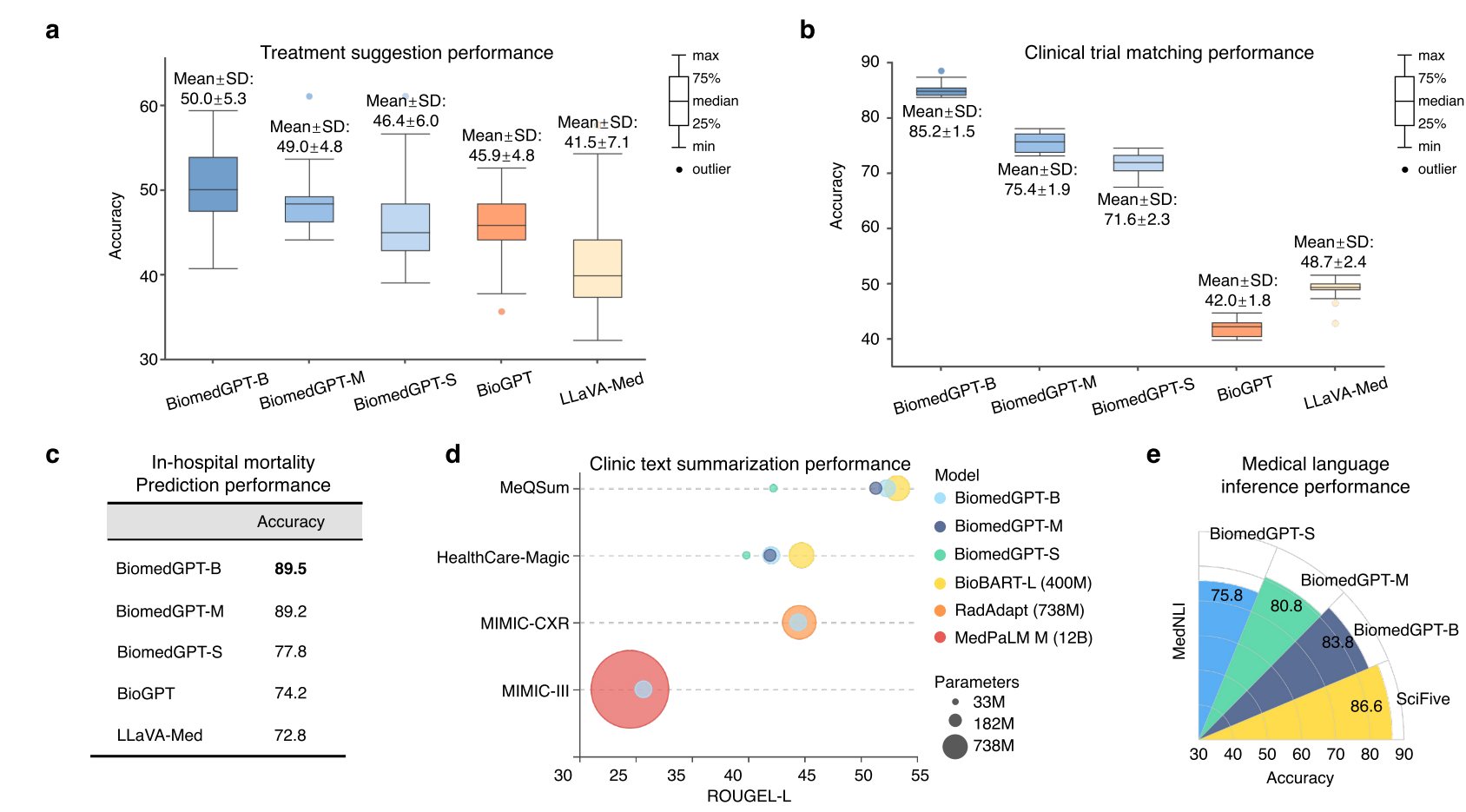
图4:BiomedGPT对临床文本理解和汇总进行了很少的期间转移学习,并通过零射传递学习产生了响应。 (a)使用10倍交叉验证(n = 4680)的精度评估治疗建议任务的模型。 (b)使用10倍交叉验证(n = 7079)从TREC 2022数据集中得出的患者试验匹配数据集的精度进行比较。 (c)三种生物膜变体和两个SOTA模型的精度,即Biogpt和Llava-Med,用于院内死亡率预测。 (d)在四个文本摘要数据集上,roogel-l就模型量表而言。 图例的大小代表参数的数量。 (e)MEDNLI数据集上的医学语言推断性能。 (f)零弹问题对准精度比较教学 - 二元格(基础,中等,小),生物膜,ofas(大,巨大),llava-med和gpt-4V。 我们提供了一个示例,说明生成的答案与问题之间的不匹配。 (g)VQA-RAD数据集上7个问题类型的平均零弹药精度。 (h)通过50个重复采样(n = 39),在VQA-RAD数据集上的总体零射击学习性能。
在 MedNLI 数据集的 3 类分类(蕴含、矛盾或中性)评估中,我们采用准确率作为评估指标,与先前的研究一致(图 4e)。值得注意的是,当与 SciFive-Large [16] 的 86.6% 准确率的最先进性能相比,我们的 BiomedGPT-B 仅使用 SciFive-Large 四分之一的参数,准确率仅小幅下降 2.8%。
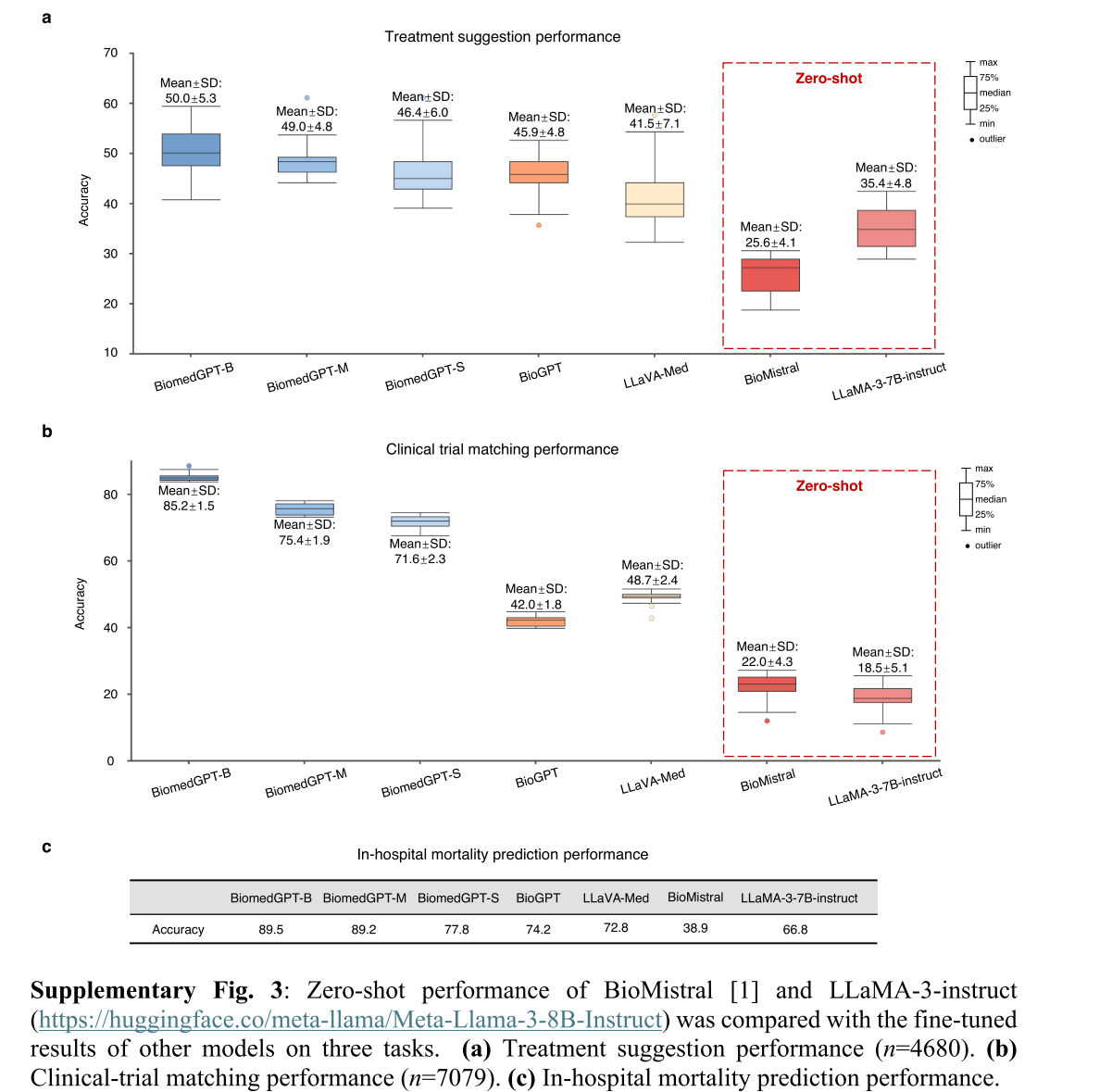
对于治疗建议任务,我们采用了数据来源工作 [47] 的预处理步骤。一个输出示例如:“建议使用束放射治疗,建议放射顺序应为术后。此外,确实应考虑化疗。” 为了评估三种变体在治疗建议中的有效性,我们采用了 10 折交叉验证方法,并将其与当前的开源最先进方法(包括 BioGPT [14] 和 LLaVA-Med(使用语言主干)[12])进行了比较,这些方法分别具有 3.47 亿和 70 亿参数,大约是 BiomedGPT-S 的 11 倍和 212 倍。
BiomedGPT-B 的平均准确率为 50.0%±5.3%,超过了 BioGPT 和 LLaVA-Med,它们的准确率分别为 45.9%±4.8% 和 41.5%±7.1%。考虑到六种放射治疗类型、七种放射顺序和两种化疗类型的复杂性 [49],这意味着随机猜测的准确率为 1.2%,BiomedGPT 和基线模型均显著高于该基线。
为了评估 BiomedGPT 在预测院内死亡率方面的表现,我们按照 [48] 使用从 MIMIC-III 数据库中提取的入院记录,并使用官方测试集。图 4c 展示了五个模型的预测准确率结果,表明所有三个版本的 BiomedGPT 均优于 BioGPT 和 LLaVA-Med。值得注意的是,BiomedGPT-B 的准确率比这两个基线提高了超过 15%。
对于临床试验匹配任务,我们从 TREC 2022 [49] 收集了一个数据集,分为三组:合格、无关和不合格。我们从每组中随机选择 80% 作为训练集,剩余 20% 作为测试集,并报告 10 次重复的平均结果。同样,所有三个版本的 BiomedGPT 均优于基线(图 4b)。特别是,BiomedGPT-B 的平均准确率为 85.2%±1.5%,显著超过了 BioGPT 和 LLaVA-Med,它们的准确率仅为 42.0%±1.8% 和 48.7%±2.4%。
在评估文本总结时,我们采用 ROUGE-L 指标来评估 BiomedGPT-B 在四个基准数据集上的表现(图 4d)。BiomedGPT-B 展示了其在 MedQSum 和 HealthCareMagic 数据集上总结医患对话的能力,ROUGE-L 得分分别为 52.3% 和 42%。
与具有 4 亿参数(是 BiomedGPT-B 的 2 倍以上)的领先模型 [32] 记录的 53.2% 和 44.7% 的 ROUGE-L 得分相比,BiomedGPT-B 仅显示出 0.9% 和 2.7% 的轻微性能下降。此外,在总结放射学报告(特别是从放射科医生的发现中生成印象)方面,BiomedGPT-B 在 MIMIC-CXR 数据集上的 ROUGE-L 得分为 44.4%,这一结果与最先进水平紧密一致,仅比最高分 44.5%[50] 落后 0.1%。
在 MIMIC-III 数据集上,BiomedGPT-B 的 ROUGE-L 得分为 30.7%,超过了 Med-PaLM M(12B)的 29.5%。
BiomedGPT 可对新数据进行零样本预测
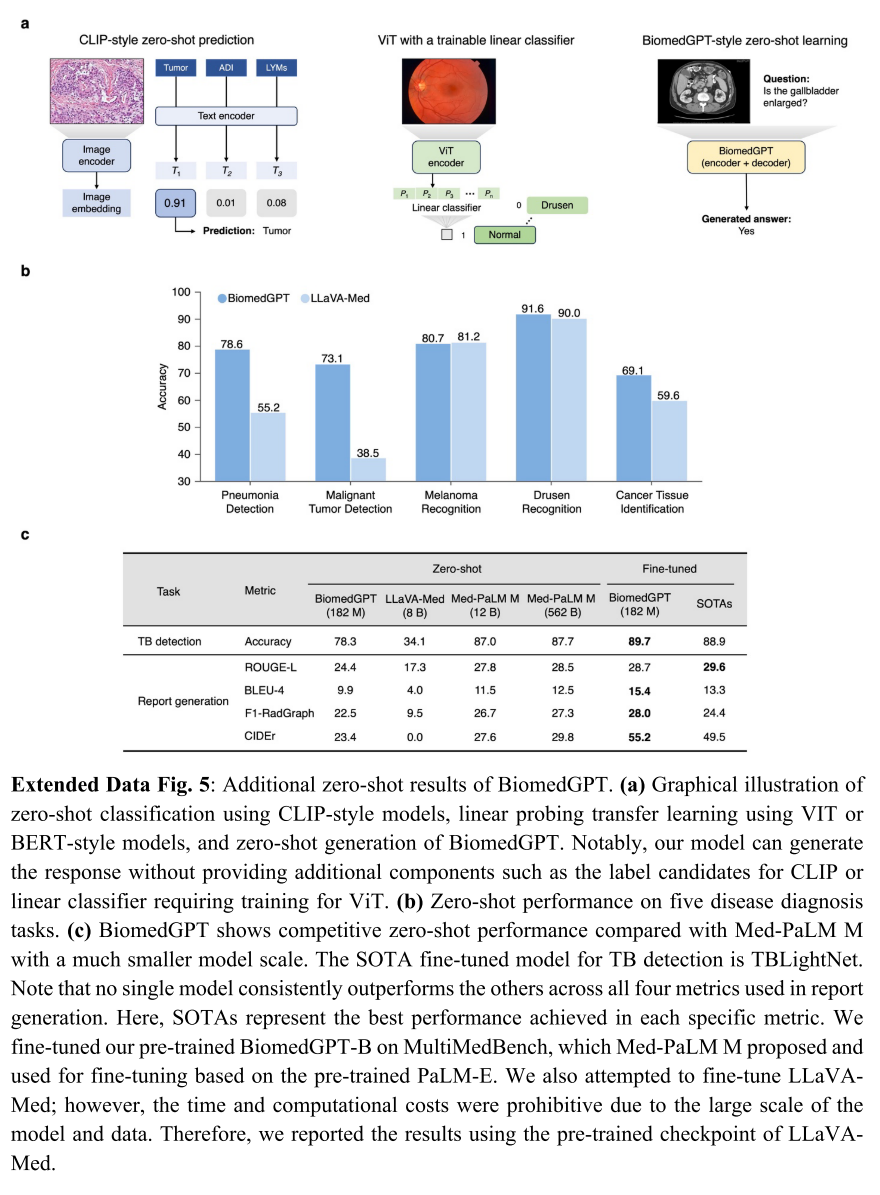
在我们的研究中,我们专注于评估 BiomedGPT 在 VQA 中的零样本能力,强调其无需重新训练即可大规模以自由形式回答生物医学问题的能力。这与早期的生物医学 AI 模型(如基于 BERT 或 ViT 的模型 [40])无法进行零样本预测或需要预定义答案的 CLIP 类模型 [15] 形成鲜明对比。
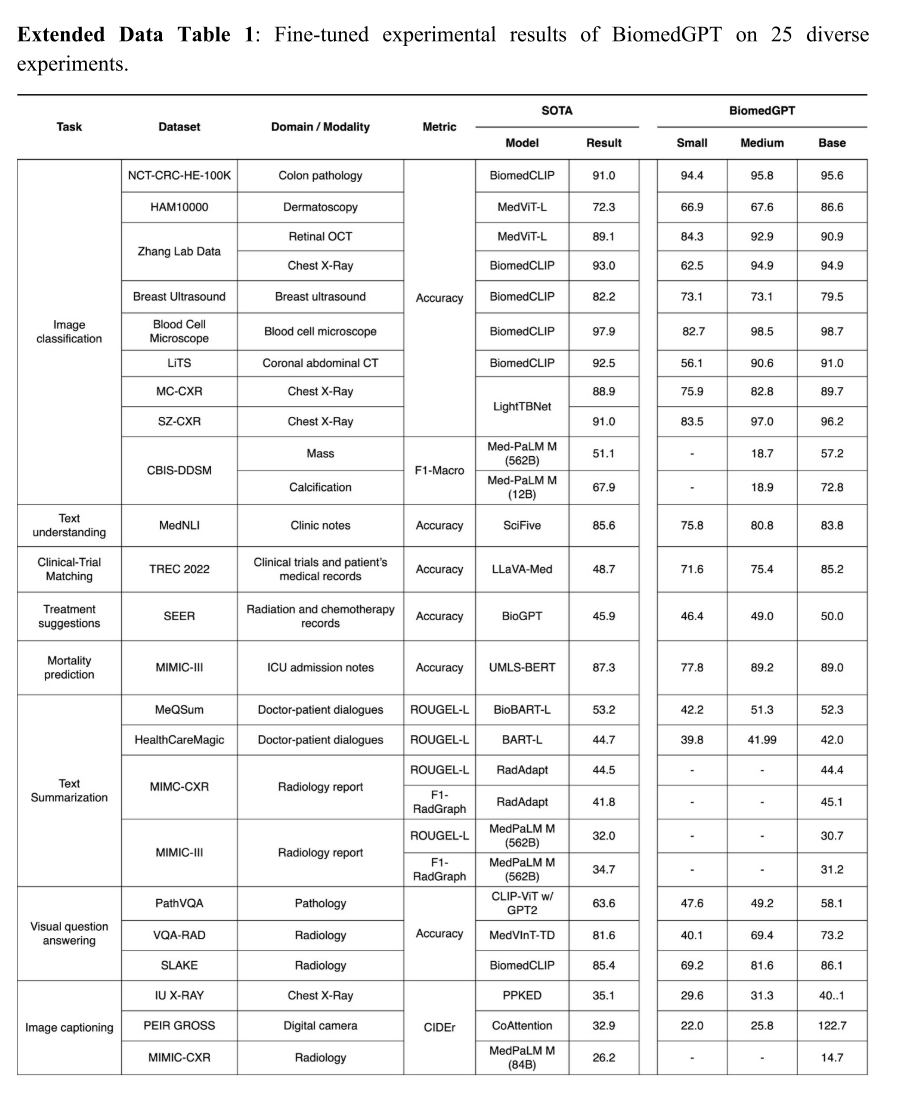
与这些模型不同,BiomedGPT 只需处理输入数据即可生成答案,为生物医学查询提供了更灵活和动态的 AI 驱动解决方案。除了医学 VQA,BiomedGPT 还在疾病诊断和 X 光报告生成中展示了零样本能力,性能与 Med-PaLM M 和 LLaVA-Med 相当(扩展数据图 5b-c)。
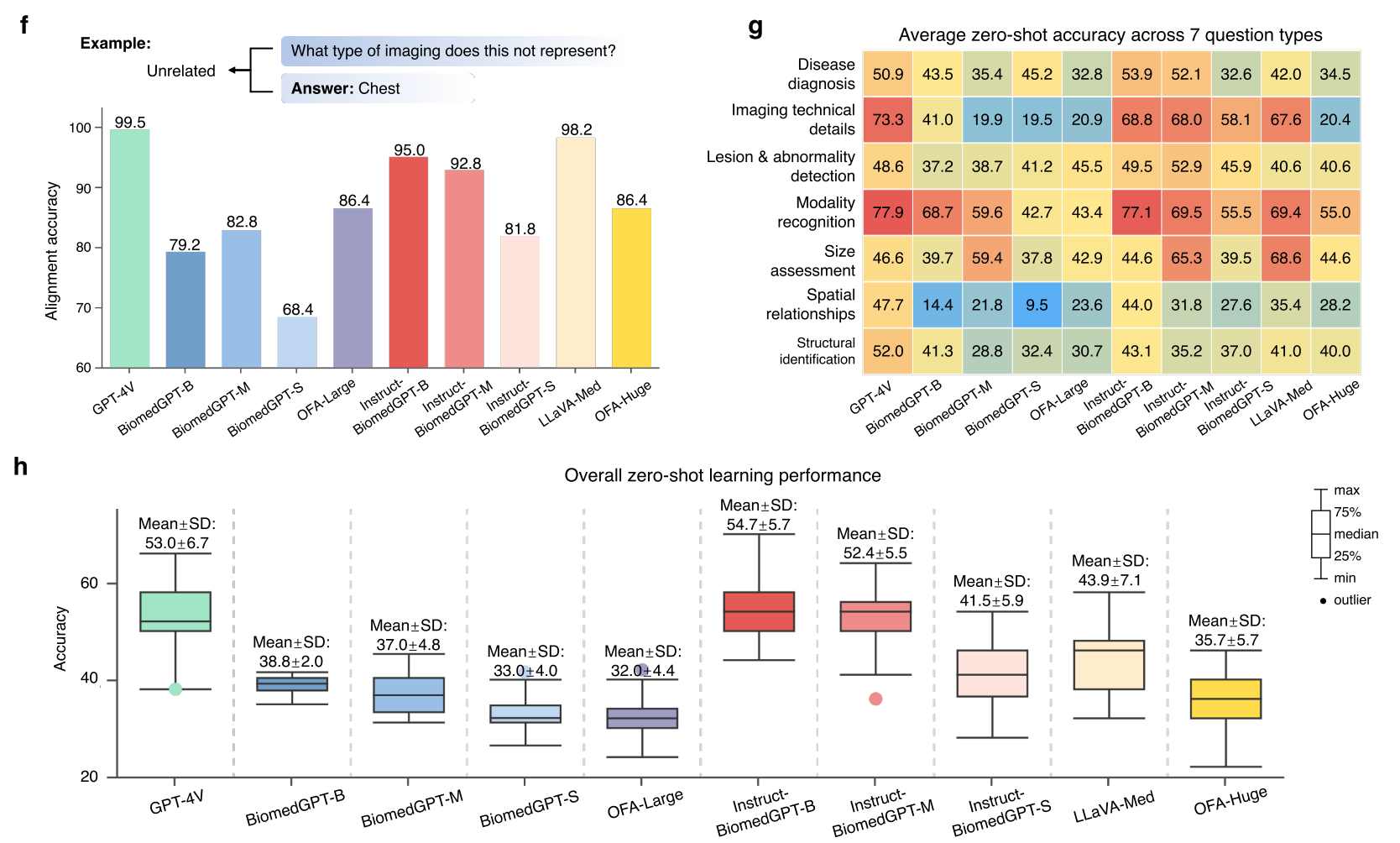
图4:BiomedGPT对临床文本理解和汇总进行了很少的期间转移学习,并通过零样本传递学习产生了响应。 (a)使用10倍交叉验证(n = 4680)的精度评估治疗建议任务的模型。 (b)使用10倍交叉验证(n = 7079)从TREC 2022数据集中得出的患者试验匹配数据集的精度进行比较。 (c)三种生物膜变体和两个SOTA模型的精度,即Biogpt和Llava-Med,用于院内死亡率预测。 (d)在四个文本摘要数据集上,roogel-l就模型量表而言。 图例的大小代表参数的数量。 (e)MEDNLI数据集上的医学语言推断性能。 (f)零样本问题对准精度比较教学 - 二元格(基础,中等,小),生物膜,ofas(大,巨大),llava-med和gpt-4V。 我们提供了一个示例,说明生成的答案与问题之间的不匹配。 (g)VQA-RAD数据集上7个问题类型的平均零弹药精度。 (h)通过50个重复采样(n = 39),在VQA-RAD数据集上的总体零样本学习性能。
我们通过 50 次随机抽样,在 VQA-RAD 数据集 [18](未包含在预训练数据中)上进行了评估。我们对 BiomedGPT 的性能评估集中在两个关键指标上:(1)模型提供正确答案的准确率;(2)其理解问题并以上下文相关方式响应的能力,衡量为对齐准确率。我们注意到,预训练模型的对齐准确率较低,表明对问题的理解不足(图 4f)。
为解决这一问题,我们通过使用指令调优数据进行微调开发了 Instruct-BiomedGPT(补充图 1)。我们在零样本设置下将该模型与当前最先进的模型(包括 GPT-4V [51]、LLaVA-Med(7B)[12]、OFA-Huge(930M)和 OFA-Large(470M)[52])就各种问题类型进行了评估(扩展数据表 4)。具体而言,Instruct-BiomedGPT-B 的零样本准确率为 54.7%±5.7%,超过了 GPT-4V 的 53.0%±6.7%(图 4h)。
尽管在理解医学问题方面有所改进,但两种模型均未达到临床可接受的性能。例如,当前表现最佳的医学视觉语言模型 LLaVA-Med 在疾病诊断和病变检测中的准确率分别仅为 42.0% 和 40.6%(图 4g)。尽管 Instruct-BiomedGPT-B 比 LLaVA-Med 提高了 10% 以上,但准确率仍低于 60%。这些结果凸显了诊断的复杂性以及视觉语言生物医学 AI 开发中持续微调的必要性。
关于对齐准确率,GPT-4V 和 LLaVA-Med 优于其他模型(图 4f)。具体而言,它们分别实现了 99.5%±1.1% 和 98.2%±2.0% 的令人印象深刻的分数,这可能归因于它们所基于的先进大型语言模型 [10,11]。
Instruct-BiomedGPT 与预训练的 BiomedGPT 之间对齐准确率的显著提升,体现了指令调优在增强模型准确遵循指令能力方面的有效性。例如,虽然 BiomedGPT-B 的平均对齐准确率为 79.2%,但 Instruct-BiomedGPT-B 达到了 95%。
针对放射学任务的 BiomedGPT 人类评估

图5:对VQA,文本摘要和字幕任务的人体评估。 (a)关于响应事实,遗漏和错误意义的三个任务的人类评估示例。 (b)放射学VQA的六个问题类别的三个模型之间的性能比较。 (c)放射学VQA的平均答案得分。 (d)生成的放射学报告中生物膜-B和生物gpt-M的误差和遗漏率。 (e)报告摘要的人类评估考虑了三个属性:完整性,正确性和潜在的伤害,并具有总体偏好。
为了评估 BiomedGPT 的临床适用性和部署挑战,我们通过放射科医生对模型生成的各种任务响应(包括放射学中的 VQA、报告生成和报告总结)进行评估,开展了一系列分析。图 5a 展示了对这三项任务的人类评估示例,涉及响应的事实性、遗漏和错误的重要性。详细的评估程序和性能分析如下:
放射学 VQA
为了临床评估 BiomedGPT 响应的正确性,我们从 MIMIC-Diff-VQA [53] 官方测试集的 16 张图像中随机选择了 52 个问答样本,涵盖六个类别(补充表 2):异常、存在、位置、类型、视图和严重程度。为了公平比较,我们收集了 BiomedGPT、微调后的 LLaVA-Med 和 GPT-4V(零样本)生成的答案。
生成的答案由 MGH 的资深放射科医生进行评分(图 5b-c)。答案被分类为正确、部分正确、错误或无关,并分别赋予 2、1、0 和 - 1 的分数。此外,原始放射学报告将提供给放射科医生作为参考,以促进更精确的评估。
BiomedGPT 在所有 52 个样本中平均得分为 1.75,总分为 91。相比之下,GPT-4V 和 LLaVA-Med 的平均得分分别为 1.17 和 1.4,总分分别为 61 和 73。在考虑问题类型时,BiomedGPT 在五个类别中的四个表现更优。
此外,尽管我们的放射科医生在 MIMIC-Diff-VQA 的采样金标中发现了一些错误,但我们基于这些标签在无差异问题的测试集上建立了基于精确匹配分数的比较。在此评估中,BiomedGPT-B 表现最佳(补充表 3)。
放射学报告生成
此任务的复杂性源于需要长格式输出,提供有关异常的存在、位置和严重程度等方面的详细描述。在本研究中,我们从 MIMIC-CXR 数据集 [21] 中随机选择了 30 个样本图像 - 报告对。我们应用 BiomedGPT-B 和 BiomedGPT-M 基于输入的胸部 X 光(CXR)图像生成放射学报告的 “发现” 部分。
放射科医生将通过以下几个方面评估生成文本的质量:首先,他们将识别与生成报告的不一致之处,例如错误的发现位置、错误的严重程度级别、对不存在视图的引用或对不存在的先前研究的提及。其次,放射科医生将确定生成报告中的错误是否显著,选项为 “显著”、“不显著” 或 “需要更多信息时为 N/A”。第三,他们将指出生成文本中的任何遗漏。最后,放射科医生将判断这些遗漏是否具有临床意义。
图5:对VQA,文本摘要和字幕任务的人体评估。 (a)关于响应事实,遗漏和错误意义的三个任务的人类评估示例。 (b)放射学VQA的六个问题类别的三个模型之间的性能比较。 (c)放射学VQA的平均答案得分。 (d)生成的放射学报告中生物膜-B和生物gpt-M的误差和遗漏率。 (e)报告摘要的人类评估考虑了三个属性:完整性,正确性和潜在的伤害,并具有总体偏好。
在这种评估中,我们专注于发现级指标,即生成文本将被拆分为单个发现。例如,报告 “提供的胸部正侧位视图。再次注意到心脏扩大伴轻度肺水肿。无大量积液或气胸。” 由三个不同的发现组成。为了清楚地展示生成发现的质量,我们量化了错误率和遗漏率(图 5d)。
在对 192 个生成发现的分析中,BiomedGPT-B 的 “显著错误” 率为 8.3%,而 BiomedGPT-M 的该率为 11.0%(排除一个需要更多信息以全面评估影响的案例)。这些比率与 MIMIC-CXR 上的人类观察者变异性相当,后者的错误率约为 6%[54]。
我们还报告了 “无害错误” 率,其中 BiomedGPT-B 和 BiomedGPT-M 分别为 5.2% 和 11.5%。我们的观察包括对参考报告中 254 个发现的分析,以计算遗漏率。BiomedGPT-B 和 BiomedGPT-M 的总遗漏率分别为 23.3% 和 23.5%。由于参考报告中描述的并非所有发现都是临床必需的,我们的分析主要集中在重大遗漏上,两种模型的重大遗漏率相似,分别为 7.0% 和 6.9%。
放射学报告总结
我们评估了 BiomedGPT-B 基于 MIMIC-CXR 数据 [21] 的发现生成的 100 个总结,以及相应参考报告的 “印象” 部分。我们的评估侧重于完整性、正确性以及由于任何遗漏或错误解释可能导致的潜在医疗不良影响(图 5a)。
完整性从 1(非常不完整)到 5(非常完整)进行评分,3 表示临界(中性)概括。准确性根据内容反映患者临床影响的程度进行评估,从 1(非常不正确)到 5(非常正确)。错误导致的潜在医疗不良影响根据其临床影响分为 “无伤害”、“轻度” 或 “严重”。最后,我们比较生成总结和参考总结哪一个更好地概括了所有临床相关信息,提供了 AI 生成总结与传统放射学报告在相关性、准确性和安全性方面的全面比较。
BiomedGPT 生成的总结通常表现出更高的完整性(图 5e),81.0% 的案例平均完整性得分(得分 > 3),比参考总结高 15.0%。此外,只有 5% 的 BiomedGPT 生成总结被认为不完整(得分 <3),而参考总结为 4%。尽管如此,BiomedGPT 的平均完整性得分为 3.9,略低于参考总结的 4.0,且无显著差异(p>0.05)。
BiomedGPT 还表现出更高的正确率,90.0% 的总结得分超过 3,而参考印象为 86.0%。Wilcoxon 秩和检验显示,BiomedGPT 与参考总结的平均正确率得分之间无显著差异(p>0.05),两者平均得分为 4.4(满分 5 分)。
此外,我们的分析发现,6.0% 的 BiomedGPT 生成总结包含医疗不良项,分类为 “轻度” 或 “严重”,这与参考印象中观察到的比率相同。这表明 BiomedGPT 生成的总结在医疗安全性方面与人类专家相当。
值得注意的是,参考印象中发现了一例 “严重” 不良影响,而 BiomedGPT 生成的总结中未发现此类案例。BiomedGPT 生成总结的总体评分与参考总结非常接近,偏好得分为 48% 的 BiomedGPT 和 52% 的参考总结(图 5e)。符号检验(p>0.05)表明,对两种系统无显著偏好,表明在提供医疗总结的质量和安全性方面表现相当。
讨论
在本研究中,我们已经表明,BiomedGPT 通过在统一的预训练框架中整合多样化的生物医学模态和任务,可以在视觉、语言和多模态领域实现具有竞争力的迁移学习性能。然而,实验结果也揭示了局限性,为潜在的改进提供了见解。
AI 的发展严重依赖高质量标注数据的可用性。这一要求在生物医学领域构成了独特挑战,因为数据标注昂贵、耗时且需要广泛的领域知识 [55]。因此,AI 研究人员经常诉诸公共数据集,这可能会影响数据质量。
在处理多模态生物医学数据集(尤其是图像 - 文本对)时,这些问题变得更加突出:(1)大多数现有数据集主要集中在放射学领域,导致模态严重不平衡;(2)与未标注或弱标注的生物医学图像以及来自 PubMed 或 PMC 的可访问生物医学文章相比,具有详细标注的图像数据规模仍然有限。在我们的研究中,我们考虑了多样化的模态并确保了足够的数据规模来训练高性能模型。随着更多生物医学数据的整理和开源,我们可以获得更好的视觉 - 语义映射(图 6)。
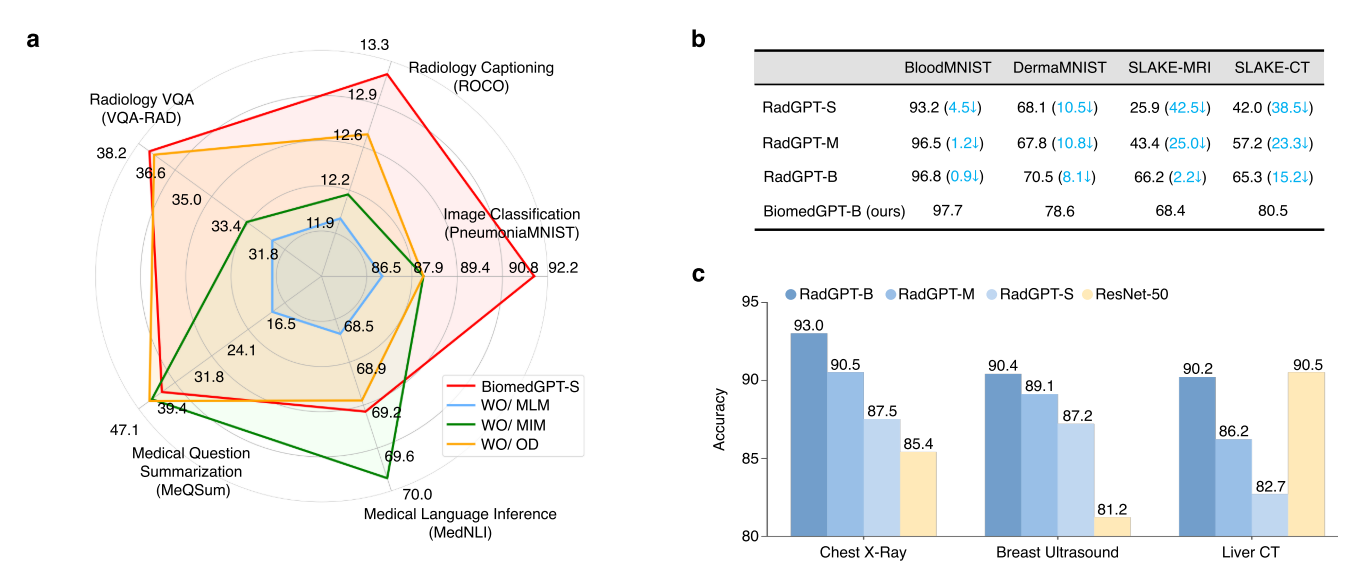
图6:消融研究的结果对培训数据集和任务多样性的影响以及Biomedgpt设计的图形演示。 (a)性能比较不包括特定任务。 这里使用的指标是放射学VQA的准确性,医学语言推断和图像分类,放射学字幕的苹果酒,Roogel-L用于医学问题摘要。 (b)在四个数据集中生物膜的跨域转移性。 RADGPT是生物膜的变体,但通过仅放射学数据进行了预训练。 此外,Slake-MRI和Slake-CT是SLAKE数据的模式特异性子集。 (c)生物膜在三种放射学模式/数据集中的内域转移性。 (d)描述用于培训和推断的生物膜中用于生物元素的统一词汇。 通过Pix2Seq和BPE分别对边界框和文本进行标记化。 有三种类型的令牌:位置令牌,文本令牌和图像令牌,诸如VQ-GAN等验证的标记器。 我们还显示了预处理中掩盖图像建模的图形插图,该图的旨在通过重建蒙版贴剂来学习表示形式。
评估生成文本的质量存在重大挑战。尽管 CIDEr 和 ROUGE-L 等指标可以衡量生成内容与金标准之间的一致性,并通常用于模型选择以进一步评估其临床适用性 [35],但确保这些输出的事实准确性仍然是一个问题。
为解决这一问题,最近的研究引入了 F1-RadGraph 分数 [56],该分数定性评估生成报告的事实正确性和完整性。然而,在病理学等其他领域,类似的评估指标尚不普遍。从放射学中开发的关注事实的指标 [58] 中获得灵感,我们预计这些领域将出现类似的指标,这将进一步增强我们衡量 AI 生成医疗内容在各个生物医学领域的事实完整性和整体质量的能力。
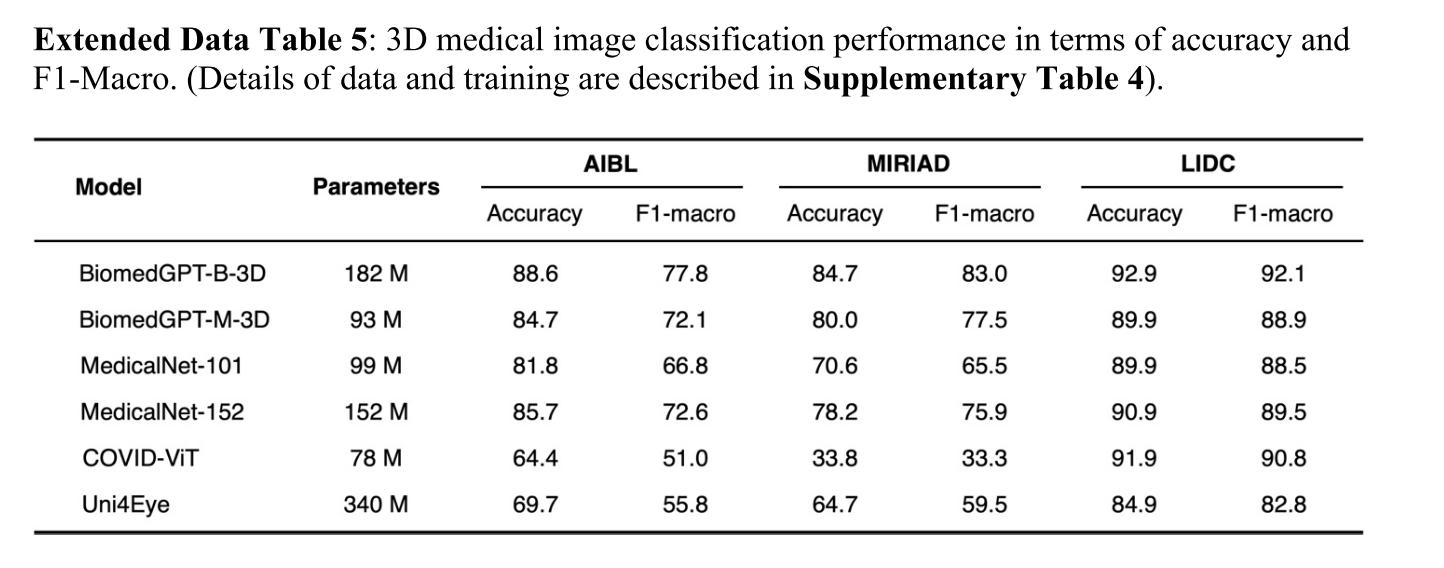
BiomedGPT 目前擅长处理图像和文本,有可能将其能力扩展到其他类型的生物医学数据,如视频和时间序列 / 序列数据。例如,我们通过将 3D 图像编码器引入框架,展示了将 BiomedGPT 扩展到处理 3D 图像的能力(扩展数据表 5 和补充表 4)。
然而,这些扩展引发了负迁移的担忧,即从额外模态中学习可能会无意中损害某些任务的性能。例如,我们的消融研究表明,在预训练期间排除图像数据可提高仅语言下游任务的性能(图 6a),突显了负迁移的风险。为缓解这一问题,我们建议探索可控学习策略,如专家混合模型(mixture of experts)[57]。
我们的综合分析(图 3a-b、图 3f、图 4a-e 和图 4h)表明,模型规模的增加与零样本预测和微调后的性能提升直接相关。然而,扩展带来了自身的挑战,特别是在微调效率、训练速度和内存需求方面。我们尝试通过探索提示调优来解决 BiomedGPT 的效率挑战,该方法在冻结模型的条件下添加小规模参数 [58]。然而,这种方法导致了显著的性能下降(扩展数据图 4b)。
我们的零样本迁移学习测试(图 4f-h)表明,BiomedGPT 的文本理解能力(尤其是与 GPT-4V 相比)尚未完全成熟。有两个主要因素导致这一限制:首先,尽管 BiomedGPT 的规模可扩展,但其当前规模(尤其是语言主干)受到可用资源的限制。
我们的初步观察表明,即使有 70 亿参数和有效的训练,在复杂的医疗应用中实现稳健的零样本上下文学习或文本理解仍然具有挑战性。然而,即使是像 BiomedGPT 这样的较小规模模型,微调也被证明是降低风险的有前途的方法(补充图 3)。其次,使用处理多种输入类型的单一编码器使不同模态表示的分离复杂化,需要更精细的训练策略。
方法
我们提出的 BiomedGPT 是一种基于 Transformer 的架构,专门为生物医学领域设计,建立在现有的通用数据统一模型的成功基础上。我们遵循统一模型的基本原则 [52]:1)模态不可知;2)任务不可知;3)模态和任务的全面性。通过将数据离散为补丁或标记,我们使用来自 ViT [59] 和语言模型 [10,11] 的思想实现输入 / 输出统一。
BiomedGPT 架构
预训练基础模型主要有三种架构:仅编码器、仅解码器和编码器 - 解码器。仅编码器模型(如 BERT 及其变体 [60])主要利用 Transformer 的编码器来学习输入数据的表示,在微调期间需要额外的模块(如分类头或任务特定解码器)。这种架构可能难以在截然不同的模态之间对齐输入和输出,限制了其在复杂零样本预测或生成任务中的能力。
相反,以 GPT [10] 为代表的仅解码器模型仅依赖 Transformer 的解码器来处理原始文本输入。尽管在基于文本的任务中表现出色,但其架构并非天生具备处理多种模态的能力,通常在学习跨不同数据类型的联合表示时面临挑战。
这可能会降低多模态任务的灵活性和性能,尤其是在生物医学应用中。因此,我们为 BiomedGPT 倡导编码器 - 解码器架构,该架构更擅长将各种模态映射到统一的语义表示空间,从而增强跨更广泛任务的处理能力。
BiomedGPT 采用类似 BERT 的编码器 [60] 处理损坏的文本和类似 GPT 的从左到右自回归解码器 [10]。所有这些模型都依赖于流行的多头注意力机制 Transformer(扩展数据图 3a),该机制允许模型联合关注来自不同表示子空间的信息 [61]。
为了提高预训练中的收敛效率和稳定性,我们在每个层中添加了三个归一化操作:后注意力层归一化(LN)[62]、后第一个前馈网络 LN 和自注意力内的头向缩放(扩展数据图 2b),遵循 [63]。为了编码位置信息,我们为文本和图像纳入了两组绝对位置嵌入。我们没有简单地将这些嵌入与标记和补丁嵌入相结合,而是实现了一种解耦方法来分离位置相关性(扩展数据图 3b),这可能会在注意力中引入不必要的随机性,并进一步限制模型的表达能力 [61]。
此外,我们还为文本纳入了 1D 相对位置偏差,为图像纳入了 2D 相对位置偏差(扩展数据图 3c),如先前的工作 [64,65] 所述。为了研究 BiomedGPT 在不同规模任务中的性能,我们明确设计了三种缩放模型,即 BiomedGPT-S(33M)、BiomedGPT-M(93M)和 BiomedGPT-B(182M)。每个模型的配置详见扩展数据图 2a。
输入 / 输出统一
为了处理多样化的模态而不依赖于任务特定的输出结构,我们使用从统一有限词汇表中提取的标记来表示它们(图 6d)。为此,我们分别利用冻结的图像量化 [66] 和对象描述符 [67] 来离散化目标侧的图像和对象。对于文本输出(包括对象标签和总结),我们使用 BPE 标记对其进行编码 [68]。
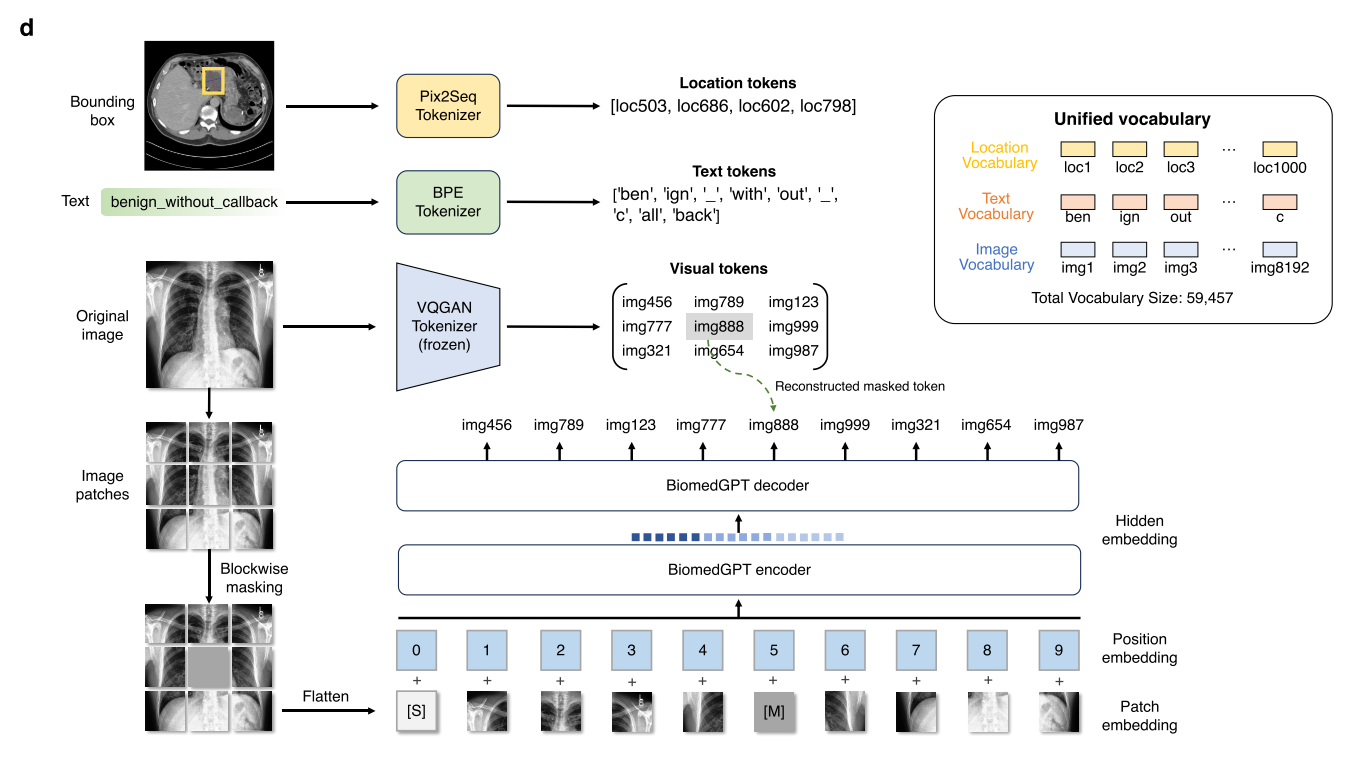
图6:消融研究的结果对培训数据集和任务多样性的影响以及Biomedgpt设计的图形演示。 (a)性能比较不包括特定任务。 这里使用的指标是放射学VQA的准确性,医学语言推断和图像分类,放射学字幕的苹果酒,Roogel-L用于医学问题摘要。 (b)在四个数据集中生物膜的跨域转移性。 RADGPT是生物膜的变体,但通过仅放射学数据进行了预训练。 此外,Slake-MRI和Slake-CT是SLAKE数据的模式特异性子集。 (c)生物膜在三种放射学模式/数据集中的内域转移性。 (d)描述用于培训和推断的生物膜中用于生物元素的统一词汇。 通过Pix2Seq和BPE分别对边界框和文本进行标记化。 有三种类型的令牌:位置令牌,文本令牌和图像令牌,诸如VQ-GAN等验证的标记器。 我们还显示了预处理中掩盖图像建模的图形插图,该图的旨在通过重建蒙版贴剂来学习表示形式。
具体而言,分辨率为 256×256 的图像被稀疏编码为 16×16 的序列,这与相应的补丁密切相关,可以有效减少图像表示的序列长度。图像中对象的边界框以整数格式的位置标记序列表示。我们在此为多模态输出的所有标记构建了一个统一的词汇表。总词汇表大小为 59457,包含 50265 个语言标记、1000 个位置标记和 8192 个视觉标记。
请注意,视觉标记的数量由 BiomedGPT 中使用的预训练 VQ-GAN 模型的变体决定,具体而言,我们使用了补丁大小为 8 且词汇表大小为 8192 的变体。在训练期间,我们为预训练随机子采样 196 个图像补丁。模型输入的最大长度截断设置为 512。
模态全面性的消融研究
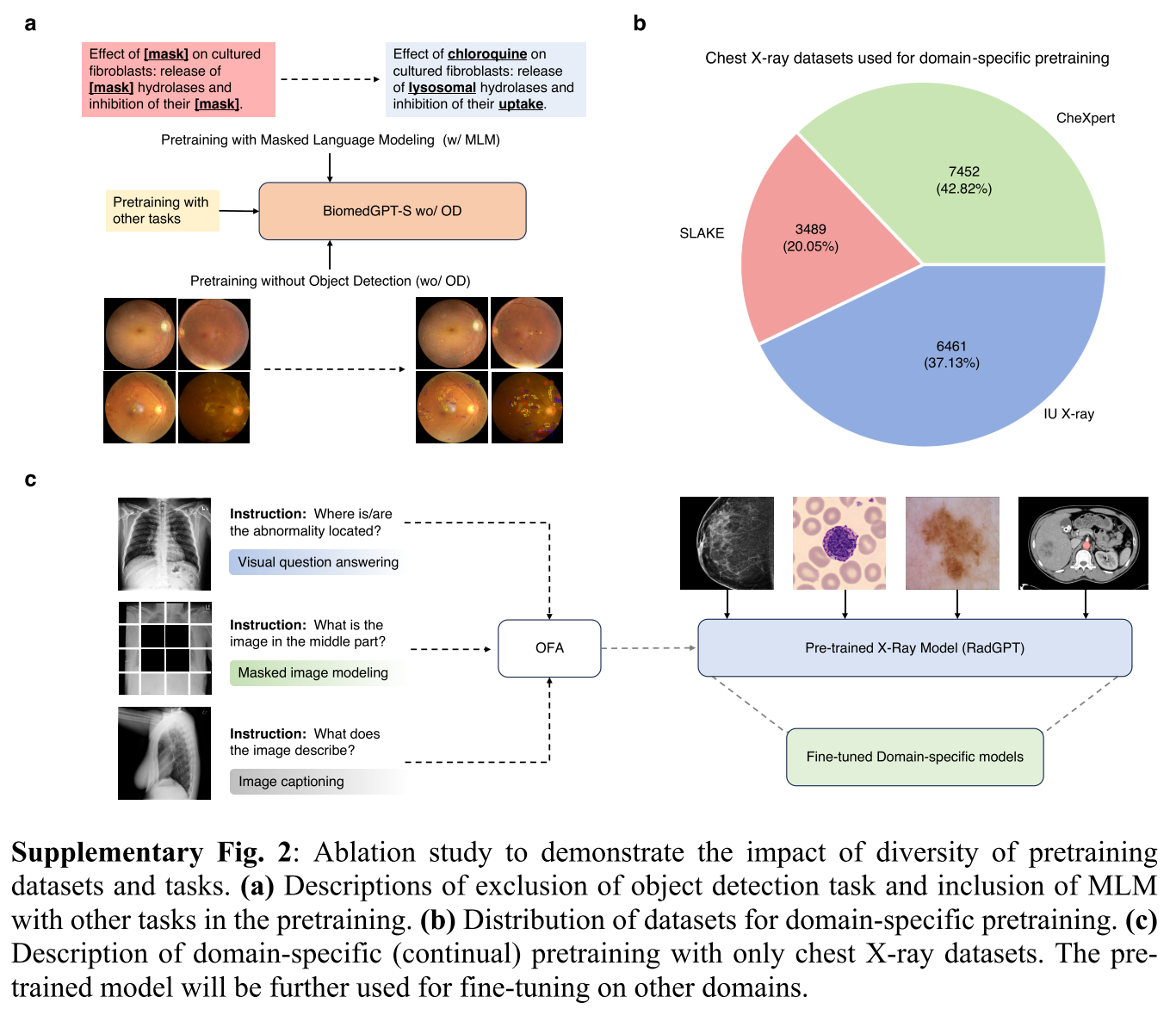
为了解决 “所提出的模型能否处理未见数据模态(如来自超声等新成像设备的图像)?” 的问题,我们调整了预训练和下游任务的数据集选择(补充图 2b)。具体而言,我们使用了 SLAKE 和 IU X-ray 数据集中的所有 3,489 和 6,461 个胸部 X 光图像 - 文本对。此外,为了简化,随机从 CheXpert 中选择了 7,452 张图像,同时在预训练期间为简化起见禁用了掩码语言建模和目标检测(补充图 2a)。在 X 射线模态上预训练的 BiomedGPT(称为 RadGPT {size})随后在与放射学相关的数据集上进行微调:胸部 X 光、乳房超声和肝脏 CT(冠状位)。作为比较基线,我们选择了从头开始在这三个数据集上训练的 ResNet-50 [69]。

图6:消融研究的结果对培训数据集和任务多样性的影响以及Biomedgpt设计的图形演示。 (a)性能比较不包括特定任务。 这里使用的指标是放射学VQA的准确性,医学语言推断和图像分类,放射学字幕的苹果酒,Roogel-L用于医学问题摘要。 (b)在四个数据集中生物膜的跨域转移性。 RADGPT是生物膜的变体,但通过仅放射学数据进行了预训练。 此外,Slake-MRI和Slake-CT是SLAKE数据的模式特异性子集。 (c)生物膜在三种放射学模式/数据集中的内域转移性。 (d)描述用于培训和推断的生物膜中用于生物元素的统一词汇。 通过Pix2Seq和BPE分别对边界框和文本进行标记化。 有三种类型的令牌:位置令牌,文本令牌和图像令牌,诸如VQ-GAN等验证的标记器。 我们还显示了预处理中掩盖图像建模的图形插图,该图的旨在通过重建蒙版贴剂来学习表示形式。
结果表明,BiomedGPT 具有令人印象深刻的域内可迁移性(图 6c),特别是 RadGPT-B 在胸部 X 光图像上的分类准确率达到 93.0%,比基线提高了 7.6%。然而,对于肝脏 CT 扫描,我们观察到需要扩大模型规模才能获得与基线相当的结果。这凸显了在预训练模型未学习到多样化医学知识的情况下,医学应用中的域适应挑战。
我们进一步探索了跨域可迁移性(图 6b)。具体来说,我们使用来自其他领域的数据集(如血细胞显微镜和皮肤镜检查)对上述预训练模型 RadGPT 进行图像分类微调。此外,我们从 SLAKE 中选择仅 MRI 和仅 CT 的图像 - 文本对,并进行 VQA 微调。与基准(使用所有模态预训练的原始 BiomedGPT-B)相比,结果以准确率衡量。
我们发现,尽管模型的跨模态迁移是可行的,但可能会出现显著的性能下降。例如,RadGPT-B 在 DermaMNIST 数据集(皮肤镜检查)和 SLAKE-CT VQA 数据集上的准确率分别比基线下降了 8.1% 和 15.2%。值得注意的是,与使用包含所有模态的预训练模型进行的先前微调相比,我们不得不将训练轮数加倍(100 vs. 50)。因此,我们得出结论,模态全面性对于通用生物医学 AI 模型促进高效知识迁移至关重要。
自然语言作为任务指令
多任务处理是统一通用模型的关键属性。遵循先前关于使用提示 / 指令学习的语言模型的文献 [10,70,71] 以及现有的统一框架以消除任务特定模块,我们使用手工制作的指令指定每个任务(VQA 除外,其完全由文本输入指定)。BiomedGPT 支持多种任务的抽象,包括纯视觉、纯文本和视觉 - 语言任务,以实现任务全面性。以下提供了预训练任务、微调 / 推理任务及其相应指令的详细信息。
预训练任务
我们在预训练中考虑了两个纯视觉任务:对于掩码图像建模(MIM)和图像填充,我们借鉴了分块掩码的思想 [72],让模型通过生成相应的代码来恢复中间部分的掩码补丁(见图 6d)。相应的指令是 “中间部分的图像是什么?”。对于目标检测,模型学习使用指令 “图像中的对象是什么?” 生成对象的边界框。
至于纯文本任务,我们采用常用的掩码语言建模(MLM),其逻辑与掩码图像建模类似,指令为 “‘{Text}’的完整文本是什么?”。选择了两种类型的多模态任务,包括使用指令 “图像描述了什么?” 的图像字幕和使用指令 “{Question}” 的 VQA。受 [73] 启发,为 BiomedGPT 添加目标检测(OD)预训练以增强视觉学习。预训练任务的混合被证明是有效的,尤其是在处理多模态输入时(图 6a)。
微调和下游任务
除了预训练中使用的图像字幕和 VQA 外,我们还涵盖了一个额外的纯视觉任务和两个额外的纯文本任务。具体来说,我们使用指令 “图像描述了什么?” 来区分图像分类。“‘{Text}’的摘要是什么?” 和 “文本 1‘{Text1}’能否推断出文本 2‘{Text2}’?” 分别用于文本总结和自然语言推理。值得注意的是,BiomedGPT 是可扩展的,允许为特定下游任务自定义指令(图 1c 和补充图 4-9)。
任务全面性的消融研究
为了深入理解各个预训练任务对下游性能的影响,我们进行了一项消融研究,在预训练期间排除纯图像或纯文本任务,然后在五个下游任务上对生成的模型进行微调。为确保公平比较,我们使用了预训练阶段未包含的下游数据集:(1)用于图像分类的 PneumoniaMNIST [36];(2)用于图像字幕的 ROCO(GitHub - razorx89/roco-dataset: Radiology Objects in COntext (ROCO): A Multimodal Image Dataset);(3)用于 VQA 的 VQA-RAD;(4)用于文本总结的 MeQSum;(5)用于文本理解的 MedNLI。此外,每个模型都在相同数据集上使用一致的训练收据进行微调。
由于计算资源有限,我们仅使用 BiomedGPT-S 进行了这项研究。简而言之,我们将未使用掩码图像建模的预训练、未使用掩码语言建模的预训练和未使用目标检测的预训练分别表示为 w/o MIM 和 w/o MLM。参考补充图 2c,我们使用了包含所有任务预训练的 BiomedGPT-S 模型作为基线。在这项消融研究中,我们观察到了几个经验现象(图 6a):
(1)排除 MIM 组件导致以图像为中心的任务和多模态任务(如图像分类和 VQA 准确率)的性能下降,而以文本为中心的任务则有所改善。这些结果表明,MIM 对于纯文本任务并非至关重要,这可能解释了这些领域的改进。
(2)在预训练期间排除 MLM 时,下游评估中所有任务的性能均下降,以文本为中心的任务受到显著影响。这些发现强调了 MLM 对于统一模型的重要性,即使是需要文本标记字典来生成标签的纯图像任务也是如此。
(3)在预训练期间排除目标检测导致图像分类和放射学字幕等任务的性能显著下降,但其他数据集的性能变化相对较小,这可能是由于目标检测样本数量有限以及与纯语言任务的弱连接。总之,我们的研究强调了预训练中任务多样性对于统一医疗 AI 的重要性。尽管排除特定于图像的任务可能有利于纯文本下游任务的性能,但多样化的任务体系对于维持单模态和多模态应用的泛化能力至关重要。
模型预训练
我们采用序列到序列(seq2seq)学习 [74],这是大型语言模型常用的方法,来训练我们的 BiomedGPT。形式上,假设我们给定一个标记序列\(x_{i,b}\)作为输入,其中\(i=1,\cdots,I\)索引数据样本中的标记,\(b=1,\cdots,B\)索引训练批次中的样本。设模型由参数 θ 参数化。
然后,我们通过最小化以下损失来自回归地训练模型:\(L_{\theta}\left(x_{1,1}, \cdots, x_{i, b}\right)=-\sum_{b=1}^{B} \log \prod_{i=1}^{I} p_{\theta}\left(x_{i, b} | x_{1, b}, \cdots, x_{i-1, b}\right)=-\sum_{b=1}^{B} \sum_{i=1}^{I} \log p_{\theta}\left(x_{i, b} | x_{<1, b}\right)\)
在 BiomedGPT 的上下文中,x 可以指预训练任务中的语言和视觉标记,包括子词、图像代码和位置标记。具体来说,子词由 BPE 标记器提取,在掩码语言建模任务中,我们将输入中 15% 的子词标记进行掩码,因为这些医学词汇显示出较高的重叠度。
对于目标检测任务,位置标记根据 Pix2Seq [67] 生成,以观察到的像素输入为条件。我们需要使用 VQGAN [68] 对生物医学图像进行量化的数据预处理,因为它们周围存在琐碎的语义(如黑色背景和不满足的输入大小)。因此,我们首先移除琐碎的背景并将图像裁剪到感兴趣对象的边界框,然后将裁剪后的图像调整为 256×256 大小,并将中心部分 128×128 分辨率的图像输入预训练的 VQ-GAN 以生成相应的稀疏图像代码,这些代码是掩码图像建模任务的目标输出。视觉 - 语言任务遵循相同的标记流程。请注意,对于微调,我们也应用 seq2seq 学习,但使用不同的数据集和任务。
为了预训练我们的 BiomedGPT,我们使用 AdamW [75] 优化器,超参数为\(\beta_{1}=0.9\),\(\beta_{2}=0.999\),\(\varepsilon=1e-8\)。峰值学习率设置为\(1e-4\),我们应用线性衰减调度器,热身比率为 0.01 以控制学习率。对于正则化,我们将 dropout 设置为 0.1,并使用 0.01 的权重衰减。为了增强训练过程,我们在编码器和解码器中应用随机深度,比率为 0.1(卷积块除外)。此外,我们采用多样化的方法在每个批次内混合所有预训练数据,包括多模态、纯文本、纯视觉和目标检测样本,混合比例为 8:2:1:1,以强调学习和增强视觉与语言之间的交互。此外,为了解决预训练数据中固有模态不平衡导致的潜在特征偏移,我们在每个预训练批次中采用模态采样策略以确保平衡。模型使用 10 块 NVIDIA A5000 GPU 进行预训练,并采用混合精度 [76]。具体来说,基础型、中型和小型模型分别耗时约 87 小时、32 小时和 9 小时。我们使用预训练的 OFA 模型 [52] 初始化 BiomedGPT,并使用我们整理的多模态生物医学数据集将其适配到生物医学领域。具体来说,我们从 OFA 的预训练检查点继续训练,通过掩码建模、目标检测和图像 - 文本匹配,使用多样化的模态数据来对齐生物医学概念(扩展数据表 3)。这种方法可以降低计算效率,因为继续训练整合了来自 OFA 的通用领域知识,包括对问答任务有益的语言理解能力。
模型微调和推理
微调作为一种迁移学习形式,涉及调整预训练模型的权重以适应新数据。预训练模型的微调实践是自然语言处理和计算机视觉中广泛认可且高效的方法,在医学 AI 中也有重要应用 [77,78]。与大多数需要添加和训练额外组件(如线性输出层或解码器)的先前生物医学模型不同,我们的 BiomedGPT 模型仅依赖现有结构的微调。此微调过程中使用的特定指令与预训练工作流程一致,从而保持模型适应的一致性和效率。我们观察到,在需要长上下文输出的任务(如图像字幕)中,模型性能受超参数(特别是波束搜索大小和输出长度约束)的影响(补充表 6)。这些发现为微调的超参数选择提供了依据,应基于训练集的数据统计(如目标文本的最大长度)(补充表 7)。对于具有官方划分的数据集,我们在模型评估期间选择在验证数据上获得最高指标的检查点进行推理(补充表 7)。对于缺乏官方划分的数据集,我们采用 K 折交叉验证,使用最后一个 epoch 的检查点进行推理,并报告均值和标准差。
与现有的大型语言模型和多模态模型 [28] 类似,我们在推理中使用波束搜索等解码策略来提高生成质量。然而,这种方法对分类任务构成挑战,包括不必要的整个词汇表搜索以及生成封闭标签集之外无效标签的可能性。为解决这些问题,我们应用了一种结合前缀树(也称为 trie)的波束搜索策略,限制候选标记的数量,从而实现更高效和准确的解码。扩展数据图 3d 展示了基于 trie 的波束搜索示例:在跨越 “Lipid” 和 “breakdown” 的路径中,BiomedGPT 在计算目标标记 “in” 的对数概率时,将所有无效标记(“mechanism” 和 “pathway”)的对数几率设置为\(-\infty\)。值得注意的是,基于 trie 的搜索也应用于微调阶段的验证阶段以加速(在我们的实验中速度提高约 16 倍)。
模型指令调优和零样本预测
指令调优旨在改善预训练 BiomedGPT 的问题理解能力。遵循 LLaVA-Med [12] 的数据整理方法,我们偏离了传统 VQA 在训练和推理期间通常使用预构建答案集的方法。相反,我们的指令调优方法采用开放词汇表设置,允许模型在训练和推理期间无需预定义答案集即可独立确定最适当的响应。
我们总结了每个零样本试验的实验设置如下。在 VQA-RAD 零样本实验(图 4)中,我们使用数据集中的原始问题作为提示或指令。对于疾病诊断零样本实验(扩展数据图 5b),我们采用通用提示模板:“给定图像,患者是否患有 < 疾病>?”。评估数据集基于 RSNA 肺炎检测挑战赛(2018)(RSNA Pneumonia Detection Challenge (2018) | RSNA)和 MedMNIST v2(224×224 图像)[36] 精心整理。在不同医学数据集上进行了具体评估:(1)肺炎检测从 RSNA 随机抽样 1,000 例,包括 548 例肺炎和 452 例正常病例;(2)恶性肿瘤检测使用 BreastMNIST 数据集,包含 114 例正常或良性病例和 42 例恶性病例;(3)黑色素瘤识别基于 DermaMNIST 的子集,包含 223 例阳性黑色素瘤病例;(4)玻璃膜疣识别使用 OCTMNIST 的子集,包含 250 例阳性玻璃膜疣病例;(5)癌组织识别在 PathMNIST 子集上进行评估,包括 1,233 例结直肠腺癌上皮病例、421 例癌相关基质病例、339 例 debris 病例和 741 例正常结肠黏膜病例。在使用双视图胸部 X 光(CXR)进行肺结核(TB)检测和报告生成中(扩展数据图 5c),我们复制了 Med-PaLM M 使用的实验设置和提示模板。此外,为确保与 Med-PaLM M 公平比较,我们在持续预训练期间纳入了包含单视图图像 - 字幕对的 MIMIC-CXR 训练集。对于报告生成,我们使用与 Med-PaLM M 一致的常用 NLP 指标。
此外,我们对两个经过指令调优的大型语言模型进行了初步零样本研究,旨在探索使用先进语言主干的上下文学习性能上限。我们考虑了将这些元素整合到 BiomedGPT 中以增强推理能力的潜力,但这些模型与微调模型相比存在显著差异(补充图 3)。这些发现表明,未来医学 AI 的学术研究应侧重于改善上下文学习能力和文本理解,这对于现实临床任务至关重要。
模型扩展
BiomedGPT 最初开发用于处理视觉(特别是 2D 图像)和文本数据,但其原型能力可扩展至涵盖其他任务和模态。例如,我们已将 BiomedGPT 扩展至包含 3D 医学成像分类(扩展数据表 5 和补充表 4),这涉及实现预训练和微调阶段,仅需在管道中集成预训练的 3D VQGAN 以对 3D 图像进行标记,并添加可学习的 3D 视觉编码器(图 2a)。为了进一步扩展模型能力(尤其是针对非文本生成任务如分割),引入额外解码器(如掩码解码器)是合适的。
计算硬件和软件
我们在研究中使用 Python(3.7.4 版)进行所有实验和分析,可使用以下开源库复现:预训练使用 10 块 24GB NVIDIA A5000 GPU,通过 PyTorch(1.8.1 版,CUDA 12.2)框架中的 DistributedDataParallel(DDP)实现多 GPU 训练,并使用序列到序列工具包 fairseq(1.0.0 版)。对于掩码图像建模,我们首先裁剪图像的中间部分,并基于预训练的 VQGAN 模型(heiBOX)将其转换为视觉标记序列。Pillow 库(9.0.1 版)用于读取图像,然后使用 Python 将其转换为 base64 字符串格式。Timm 库(0.6.12 版)、torchvision(0.9.1 版)和 opencv-python(4.6.0 版)用于训练期间的图像处理和加载。ftfy 库(6.0.3 版)用于修复文本处理和加载中可能损坏的 Unicode。Einops 库(0.6.0 版)用于建模中的张量操作。模型评估中,我们使用 pycocotools(2.0.4 版)和 pycocoevalcap(1.2 版)计算 ROUGE-L 和 CIDEr 等 NLP 指标,其他指标基于 torchmetrics(0.11.0 版)计算。Numpy(1.21.5 版)和 Pandas(1.3.5 版)用于数据收集、预处理和数据分析。
评估指标
加权 F1 分数
在本文中,我们采用多种评估指标全面评估 BiomedGPT 模型在不同任务中的能力。准确率是评估医学图像分类、VQA 和自然语言推理性能的主要指标。对于这些任务,考虑到类别不平衡,我们还使用 F1 分数,F1 分数是精确率和召回率的调和平均值:
\(F1 = \frac{2 \times \text{precision} \times \text{recall}}{\text{precision} + \text{recall}}\)
具体而言,为了与最先进方法方便比较,VQA 使用加权 F1 分数,该分数通过对每个类别的 F1 分数求平均计算,每个类别的分数根据其出现频率加权:\(\text{Weighted F1} = \sum_{i=1}^{N} \frac{n_i}{N} \times F1_i\) 其中\(n_i\)是类别i的
实例数量,N 是所有类别实例的总数,\(F1_i\) 是类别 i 的 F1 分数。此外,我们在 CBIS-DDSM 数据集的图像分类任务中应用宏平均 F1 分数(F1-macro),该分数通过独立计算每个类别的 F1 分数然后对所有类别取平均得出,不考虑类别不平衡,将每个类别视为同等重要:
\(\text{F1-macro} = \frac{1}{N} \times \sum_{i=1}^{N} F1_i\)
准确率和 F1 分数(加权或宏平均)越高,模型性能越好。
ROUGE-L
ROUGE-L [26] 用于评估图像字幕和文本总结任务中生成文本的质量,其全称为 “基于最长公共子序列的摘要评估召回导向工具”。给定候选文本 C 和参考文本 R,设 \(LCS(C, R)\) 为最长公共子序列的长度(通过动态规划确定),其表达式为:
\(\text{ROUGE-L} = \frac{(1+\beta^2) R_{\text{LCS}} P_{\text{LCS}}}{R_{\text{LCS}} + \beta^2 P_{\text{LCS}}}\)
其中 \(R_{\text{LCS}} = \frac{LCS(C, R)}{|R|}\),\(P_{\text{LCS}} = \frac{LCS(C, R)}{|C|}\),\(\beta = \frac{P_{\text{LCS}}}{R_{\text{LCS}}}\),\(|C|\) 和 \(|R|\) 分别表示候选文本和参考文本的长度。
较高的 ROUGE-L 分数意味着生成文本与参考文本共享更多相同的单词序列,通常表明在捕捉参考文本要点方面质量更好,这表明生成文本与所比较的参考摘要更相似,这在总结任务中通常是期望的。
METEOR
除了 ROUGE-L,我们还应用 METEOR [27] 和 CIDEr [28] 来更全面地评估字幕生成质量。具体而言,METEOR 全称为 “具有显式排序的翻译评估指标”,我们将精确率和召回率表示为
\(P = \frac{m}{|C|}\) 和 \(R = \frac{m}{|R|}\),
其中 m 是候选文本 C 和参考文本 R 中的共同单词数,\(|C|\) 和 \(|R|\) 分别为两者的单词数。METEOR 通过以下公式计算:
\(\text{METEOR} = (1 - p) \frac{PR}{\alpha P + (1 - \alpha) R}\)
其中 p 是惩罚因子,定义为 \(p = \gamma (\frac{ch}{m})^{\theta}\),ch 是块数(即连续有序的单词块),\(\alpha\)、\(\theta\)、\(\gamma\) 是根据不同数据集确定的超参数。
CIDEr
CIDEr 专门设计用于评估图像字幕的质量,全称为 “基于共识的图像描述评估”。CIDEr 分数基于 n-gram 匹配计算,同时考虑精确率(生成字幕中的 n-gram 出现在参考字幕中的比例)和召回率(参考字幕中的 n-gram 出现在生成字幕中的比例),并根据 n-gram 的显著性(描述图像的重要性)和稀有性(数据集中的罕见性)对其进行加权,这有助于强调捕捉图像最相关方面的重要性。
设 c 为候选字幕,S 为参考字幕集合,CIDEr 通过对不同长度的相似性求平均得到:
\(\text{CIDEr}_n(c, S) = \frac{1}{M} \sum_{i=1}^{M} \frac{g^n(c) \times g^n(S_i)}{\| g^n(c) \| \times \| g^n(S_i) \|}\)
其中 M 表示参考字幕的数量,\(g^n(\cdot)\) 表示基于 n-gram 的 TF-IDF 向量。较高的 CIDEr 分数表明生成的字幕更准确、更具描述性,与人类对图像内容的判断一致。CIDEr 的技术范围通常为 0 到 100,一般来说,人类字幕的得分往往接近 90 [28]。
拓展数据
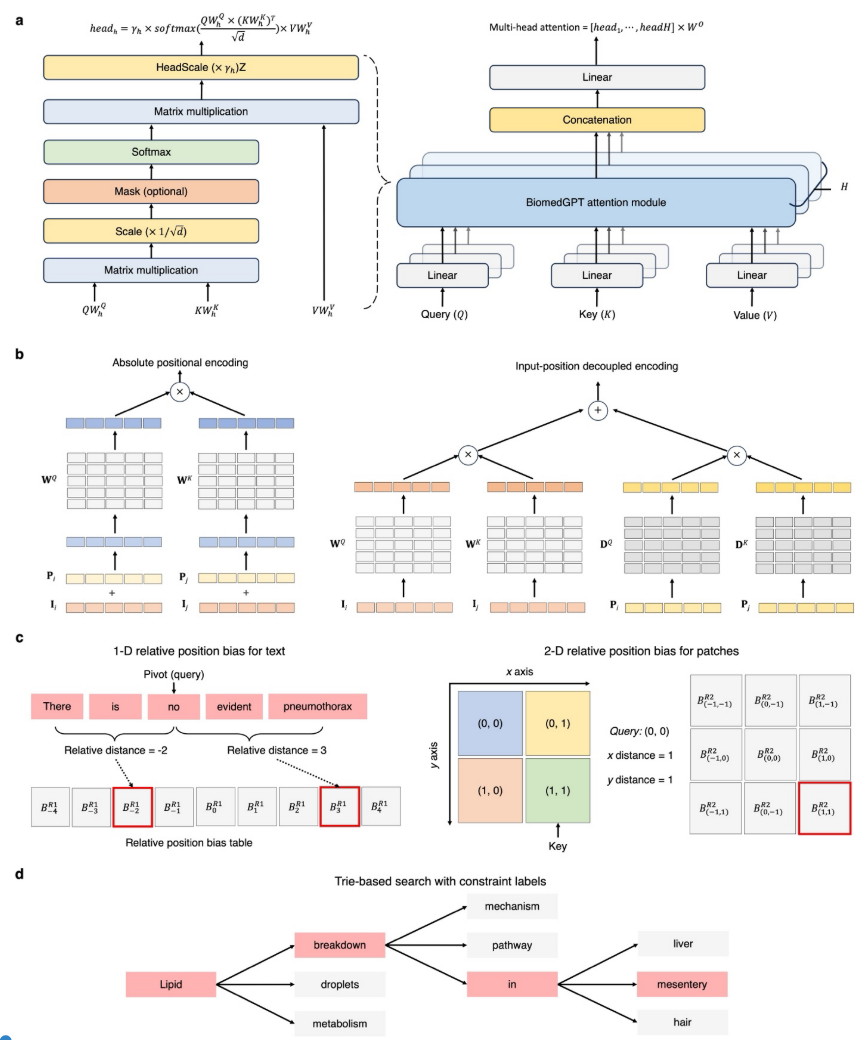
扩展数据图3:BiomedGPT中关键成分的图形图表。 (a)BiomedGPT中的头尺度多头注意模块。 在每个头部的输出投影之前,应用可训练的参数γ7。 (b)而不是添加绝对位置嵌入𝑃! 输入嵌入𝐼! (左),我们与不同的投影矩阵分别计算位置相关性和输入相关性

这种方法表示的目标框有什么好处吗?
你提供的内容里,像是用类似 <loc111><123><loc789><loc567> chest 这类形式来表示目标框,这可能是一种自定义的、用于特定场景(比如结合了文本描述与目标框标识)的目标框表示方式,以下从可能的设计意图角度,分析这类表示方法的好处:
一、结合语义与位置信息
从示例看,格式里既有类似 loc111 这类可能用于标识目标框在图像中位置的编码(也许对应坐标、区域索引等),又直接跟上了 “chest(胸部)”、“kidney(肾脏)” 这样的语义标签 。好处在于:
-
方便关联理解:能让使用该表示的系统、模型,在处理目标检测结果时,快速把目标框的位置信息和具体语义(检测到的是什么器官 / 物体)关联起来,无需额外去做复杂的映射匹配,尤其在医疗影像等对语义解读要求高的场景,有助于后续分析(比如基于这些信息做诊断辅助、报告生成 )。
-
简化流程:如果是在一个端到端的任务里(比如从图像输入到带着语义描述的目标框输出),这种格式可以在输出阶段就把位置和语义 “打包装好”,下游模块直接用,减少数据流转中拆分、再关联的步骤。
二、适配特定任务流程
如果是在生物医学图像相关的目标检测任务(像你内容里涉及到的医学影像场景,比如胸部 X 光、肾脏影像等检测 ),这样的表示有独特优势:
-
贴合领域需求:医疗影像分析中,不仅要知道目标框位置,更关键的是对应人体部位、病灶等语义。这种格式天然把二者融合,能直接为诊断报告撰写、病情分析等环节所用,医生 / 研发人员可以快速从结果里获取关键信息,不用再额外去解析位置编码对应的语义含义。
-
便于系统集成:要是构建医疗 AI 辅助诊断系统,不同模块(图像检测、报告生成、数据存储等)之间传递信息时,这种包含位置和语义的紧凑表示,能降低模块间数据交互、解析的复杂度,让系统更高效运转。
三、灵活可扩展
-
自定义拓展:这种格式是可以根据实际需求灵活调整的,比如后续要增加更多属性(像目标框对应的置信度、病灶的疑似程度等 ),可以在现有基础上继续拓展编码规则,把新信息也融入到这一串表示里,让一个 “目标框描述” 能承载更丰富内容,适配不断细化的任务需求。
-
适配多种模态交互:如果涉及到多模态(图像 + 文本问答、报告生成等 ),这种本身就结合了文本语义和图像位置的表示,能更好地在模态交互中传递关键信息,比如你示例里的 “What are the objects in the image?(图像里有什么目标物体? )” 问答场景,用这种格式可以直接给出带着语义和位置关联的结果,让问答更 “精准有用”。
当然,这种自定义格式也会有一些潜在问题,比如通用性差(换个系统、任务可能就不适用了 )、编码解码需要额外开发适配等,但单从你示例场景和设计思路看,在特定任务里,上述这些好处能让它很好地服务于目标框相关的信息传递与应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









