










University at Buffalo
摘要
多模态大型语言模型(LLMs)在各个领域取得了显著成功,但医学领域的研究主要集中在单模态图像上。与此同时,当前用于视频的通用领域多模态模型仍然缺乏理解手术视频并进行对话的能力。一个主要原因是手术领域缺乏相关数据集。
在本文中,我们创建了一个新的数据集 Surg-QA,由 102,000 个手术视频 - 指令对组成,是迄今为止同类数据集中最大的。为了构建该数据集,我们提出了一种新颖的两阶段问答生成管道,利用 LLM 从公开的手术讲座视频中以结构化方式学习手术知识。
该管道将生成过程分解为两个阶段,显著降低了任务复杂度,使我们能够使用更经济、本地部署的开源 LLM,而非付费的高级 LLM 服务。它还减轻了 LLM 在问答生成过程中的幻觉风险,从而提高了生成数据的整体质量。
我们进一步在 Surg-QA 数据集上训练了 LLaVA-Surg,这是一种新型的视觉 - 语言对话助手,能够回答关于手术视频的开放式问题,并对零样本手术视频问答任务进行了全面评估。结果表明,LLaVA-Surg 显著优于所有先前的通用领域模型,在回答关于手术视频的开放式问题时展现出卓越的多模态对话技能。我们将发布代码、模型和指令调整数据集。
1 引言
手术作为医学领域中具有丰富多模态信息的学科,与通常依赖静态图像(如磁共振成像和胸部 X 光片)的普通医学诊断有显著差异。手术过程的动态性及其复杂的动作序列和多阶段流程,无法通过单一图像完全捕捉或理解。
医学领域最近见证了大型语言模型(LLM)的重大影响,尤其是在医学问答领域。像 LLaVA-Med [11] 和 Med-PaLM [21] 这样的领域特定 LLM,与 PubMed [31] 等公开的医学问答数据融合后,可以协助解答生物医学图像相关的查询,并满足医学领域对安全性要求极高的需求。
此外,像 GPT [16] 这样的通用 LLM,尽管未明确针对医学领域进行调整,但在应用于某些特定临床知识领域时也展现出了巨大潜力和多功能性。然而,这些模型仍局限于处理单张图像,因此无法涉足视频模态至关重要的手术领域。
并行视频 - 文本数据集的可用性已被证明对以自监督方式预训练生成模型非常有用,如 Video-ChatGPT [15] 和 Video-LLaVA [12] 等对话式多模态 LLM,以及 Sora [4] 等文本到视频生成模型。
然而,获取手术视频 - 文本对比生物医学图像 - 文本对或通用领域视频 - 文本对更具挑战性,因为需要更昂贵的手术专业知识。
在这项工作中,我们介绍了用于手术的大型语言和视觉助手(LLaVA-Surg),这是首次尝试构建手术多模态对话助手。LLaVA-Surg 利用经过改编的 LLM,将 CLIP [18] 的视觉编码器与 Llama [23] 作为语言主干集成,并在生成的指令图像 - 文本对上进行微调。
我们的方法进一步调整了时空视频建模的设计,并在视频 - 指令数据上对模型进行微调,以捕捉视频数据中可用的时间动态和帧间一致性关系。
这项工作的一个基本贡献是引入了一种新颖的两阶段问答生成管道。该管道从广泛可用的手术讲座视频中提取手术知识,从而创建了 Surg-QA 数据集,该数据集包含超过 102K 个手术视频 - 指令对。每个对由一个视频及其对应的问答格式的指令内容组成。这个广泛且多样的数据集使 LLaVA-Surg 能够理解手术视频并参与关于手术视频的全面对话。
我们论文的主要贡献如下:
-
Surg-QA:据我们所知,我们引入了 Surg-QA,这是第一个大规模的手术视频指令调整数据集,包含从 2,201 个手术过程中的 44K 多个手术视频片段中提取的超过 102K 个手术视频问答对。我们还介绍了 Surg-QA 背后的新颖两步问答生成管道。该管道有效缓解了 LLM 幻觉问题,为大规模问答生成提供了一种经济高效的解决方案。
-
LLaVA-Surg:据我们所知,我们提出了 LLaVA-Surg,这是第一个能够对手术视频进行专家级理解并回答关于手术视频的开放式问题的视频对话模型。LLaVA-Surg 通过在 Surg-QA 上对通用领域视觉 - 语言模型进行微调,使用 8 个 A100 GPU 在 6 小时内完成训练。综合评估表明,LLaVA-Surg 在零样本手术视频问答任务中表现出色,优于先前的模型,并展现出强大的多模态对话技能。
-
开源:我们将公开发布手术视频指令调整数据集、模型以及用于数据生成和训练的代码,以推动手术领域的研究。
2 相关工作
手术视频问答(Surgical VQA)模型可以基于手术视频回答问题,并为执业外科医生和手术实习生提供帮助。早期的手术 VQA 方法主要是判别性的 [24,5,28],将任务视为分类问题,答案从预定义的集合中选择。
它们在识别手术步骤、器械和器官方面表现出色,但局限于封闭集预测,难以处理开放式问答。最近的发展转向了生成式方法 [20,2,19],这些方法可以生成自由形式的文本序列,但仅限于单轮对话,无法进行对话或回答后续问题。与这些模型不同,我们的 LLaVA-Surg 模型可以进行有意义的多轮对话,回答手术问题并提供全面的手术知识,以实现交互式学习体验。
用于生物医学图像对话的多模态 LLM代表了医学人工智能领域的重大进步。这些模型结合了文本和图像理解,使临床医生和 AI 系统之间能够进行更细致和上下文感知的交互。例如,LLaVA-Med 模型展示了多模态 LLM 解释和生成详细医学图像描述的潜力,从而辅助诊断和患者沟通 [11]。
此类模型的应用扩展到包括 VQA 在内的各种任务,它们可以基于医学图像和相关查询提供准确和相关的答案 [32,17]。这种多模态方法还增强了执行复杂推理和决策过程的能力,这在临床环境中至关重要 [13]。总的来说,这些发展凸显了多模态 LLM 在增强生物医学图像对话并最终改善患者护理结果方面的变革潜力 [7,10]。
用于视频对话的多模态 LLM通过集成通用领域的文本、图像和视频数据展示了巨大的潜力。早期作品如 FrozenBiLM [27] 展示了对齐视觉和语言模型以实现多模态理解的前景。最近的进展如 Video-LLaVA [12]、Video-ChatGPT [15] 和 ChatUniVi [9] 说明了在视频上下文中的实际应用,提供实时的、上下文感知的响应,改善了用户交互。
具体而言,Video-LLaVA 使用 Language-Bind 框架集成视觉和语言数据,增强了视频理解并生成连贯的、上下文相关的响应。Video-ChatGPT 擅长处理复杂的视频数据,提供详细的分析和响应。ChatUniVi 通过集成统一的视频和语言处理能力进一步拓展了边界,促进了更自然和交互式的视频对话。但它们对手术视频等领域特定视频的适用性尚未得到验证。
3 手术视频指令调整数据生成
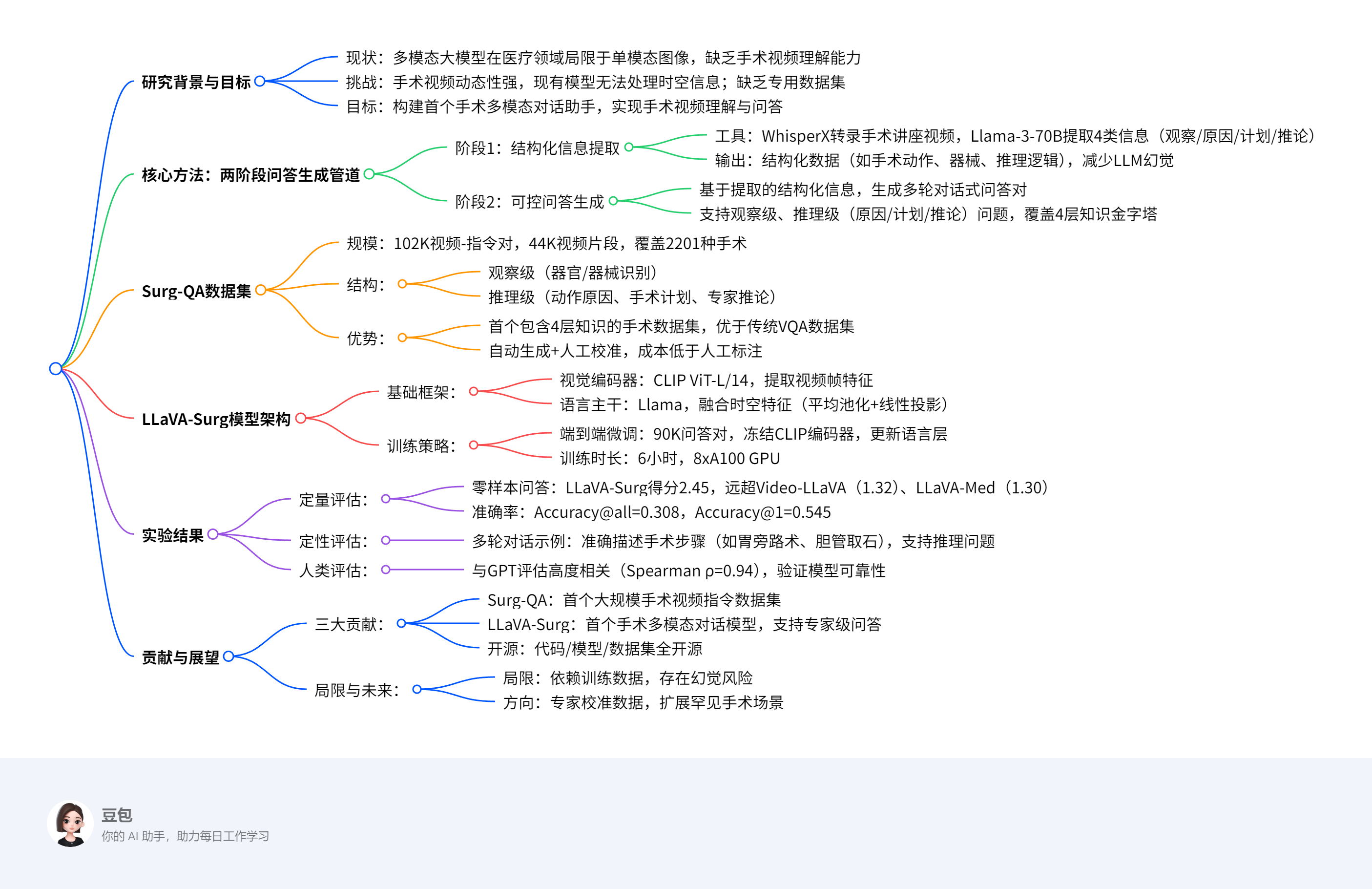
下面的这张图可以mark一下:

在手术领域,用于训练多模态 LLM 作为对话助手的专用数据集存在显著不足。如图 1 所示,手术领域的信息可以分为四个不同的层次:
(1)手术对象(如器官和器械)的基本识别,
(2)离散手术动作的识别,
(3)手术动作的高级推理,
(4)专家级的推论和规划。
然而,现有数据集 [2,30] 缺乏第 3 层和第 4 层的信息。为了解决这一问题,我们创建了 Surg-QA,这是第一个包含所有四个层次信息的手术指令调整数据集。该数据集由从手术讲座视频的结构化学习中获得的 100K 个视频 - 文本对和 2K 个专注于手术视觉概念对齐的对组成。
手术视频指令调整数据:对于手术视频\(x_v\)及其转录文本\(x_t\),我们通过两步法提示 Llama-3-70B [1] 创建一组只能通过提供视频才能回答的问题\(x_q\),旨在引导助手描述视频内容。因此,单轮指令调整示例可以表示为:\(\text{User} : X_q X_v < \text{STOP} > \backslash n \text{Assistant} : X_a < \text{STOP} > \backslash n\)
结构化手术视频学习:我们提出了一种利用 Llama-3-70B 模型处理手术视频讲座的两步提取 - 生成方法,如图 2 所示。
“原始视频 → 知识提炼 → 模型训练” ;LLaVA-Surg 模型 构建流程的核心示意图,展示 “结构化手术视频学习 + 视觉概念对齐” 双数据管道,支撑手术多模态对话助手的训练,可拆解为两大部分理解:
一、上方:Surg-QA(102K 数据)—— 结构化手术视频学习流程
聚焦 从手术讲座视频提取知识,生成问答数据,分三步:
-
视频与旁白处理(左侧):
-
输入是 “未剪辑的手术讲座视频(Untrimmed Surgical Lecture)”,先切割成短片段(Clip 1 - Clip N )。
-
用WhisperX工具,把讲座里专家的画外音(Voiceover)转成文字脚本(Transcript),实现 “语音转文本(STT)”。
-
-
结构化信息提取(中间):
用大模型从脚本里,按 4 类知识维度 提取关键信息:-
Observation(观察):手术里 “看到的事实”(如器官、器械、动作)。
-
Reason(原因):动作 / 现象的 “医学原理”(为啥这么操作)。
-
Plan(计划):手术 “下一步 / 整体流程规划”。
-
Deduction(推论):专家级 “经验判断、风险预判” 等。
这一步把文本 “变结构化”,既减少无关信息,也降低模型 “胡编(幻觉)” 风险。
-
-
问答数据生成(右侧):
基于提取的结构化信息,生成 多轮问答对,模拟真实对话:-
基础款:“Can you describe …?”(让模型描述视频内容)。
-
推理款:“Why is …?”(问原因)、“What’s the next …?”(问计划)、“What do you suggest …?”(问专家推论)。
这些问答对,就是训练模型 “理解手术视频 + 对话” 的核心数据。
-
二、下方:手术视觉概念对齐数据(2K 数据)—— 基础概念学习流程
聚焦 让模型掌握最基础的手术视觉概念,分三步:
-
输入数据(左侧):用公开手术数据集 CholecT50,提供标准化手术视频。
-
动作三元组提取(中间):从视频里,拆出 “手术动作三元组”:
-
Noun(名词):操作工具(如 “镊子”)、器官(如 “胆囊” )。
-
Verb(动词):具体动作(如 “切割”“缝合” )。
-
Target(对象):动作的作用对象(如 “血管”“组织” )。
-
-
生成对齐数据(右侧):让模型学习 “用文字描述视频”,比如生成 “Describe the surgical video.” 这类指令 - 回复对,帮模型练 “基础视觉 - 语言对齐”。
整体逻辑:“双数据 + 两阶段” 打造手术对话助手
-
数据层面:用 102K 复杂问答数据(教模型理解手术逻辑、推理) + 2K 基础对齐数据(教模型认工具 / 动作),覆盖 “基础观察 → 专家推理” 全知识层级。
-
流程层面:先 “结构化提取知识” 降本提效、减少幻觉,再 “生成问答” 训练模型对话能力,最终让 LLaVA-Surg 能看懂手术视频、回答开放问题,甚至模拟专家多轮对话。
具体来说,给定一个带有画外音的手术讲座视频\(x_v\),我们首先使用 WhisperX [3] 将手术讲座视频的语音内容转录为文本。
接下来,与之前的工作 [6,14,11] 直接提示 LLM 根据文本信息生成多轮问答不同,我们首先提示 LLM 以结构化方式从转录文本中提取关键信息,重点关注四个主要组件:如图 1 所示的观察\(I_o\)和相应的原因\(I_r\)、计划\(I_p\)和推论\(I_d\)。
视频的这种结构化表示通过仅提取与手术相关的信息来确保高质量数据,从而减少非手术片段或非信息性对话的噪音。此外,通过限制模型仅进行信息提取,它降低了 LLM 幻觉的风险 [8,11]。我们还手动策划了少量示例,以教授如何根据转录文本提取高质量信息。有关提示和少量示例,请参见附录 A.2。
一旦提取了信息,我们就可以通过提示 LLM 以可控的方式生成不同类型的问答对,将指令调整数据创建为多轮对话。例如,通过连接所有观察\((I_o^1, I_o^2, ..., I_o^T)\)(其中 T 是\(x_v\)的总观察数),我们提示 LLM 生成专注于手术讲座视觉内容的第一个问答对\([X_q^1, X_a^1]\)。
接下来,对于每个\([I_o, I_r]\)、\([I_o, I_p]\)和\([I_o, I_d]\)组合,我们提示 LLM 生成手术推理问答对\((X_q^2, X_a^2, ..., X_q^N, X_a^N)\)(其中 N 是问答对的总数)。通过堆叠问答对,我们可以创建多轮对话,其中第 t 轮的指令\(x_q^t\)定义为:\(X_q^t = \begin{cases} [X_q^1, X_v] \text{ 或 } [X_v, X_q^1], & t=1 \\ X_q^t, & t>1 \end{cases}\)
然后,我们可以构建多轮多模态指令调整数据:\(\begin{aligned} & \text{User} : X_q^1 X_v < \text{STOP} > \backslash n \text{Assistant} : X_a^1 < \text{STOP} > \backslash n \\ & \text{User} : X_q^2 < \text{STOP} > \backslash n \text{Assistant} : X_a^2 < \text{STOP} > \backslash n \ldots \end{aligned}\)

Figure 3: Comparison of instruction-tuning data generated by our two-stage approach (top) and the previous end-to-end approach (bottom). Both approaches were given the same video title and transcript. Our approach accurately extracted information from the transcript, generating correct question-answer pairs. In contrast, the conventional end-to-end approach produced incorrect question-answer pairs due to hallucination.
图3:通过我们的两阶段方法(顶部)和先前的端到端方法(底部)生成的指令调查数据的比较。 两种方法都获得了相同的视频标题和成绩单。 我们的方法准确地从成绩单中提取信息,生成正确的提问对。 相比之下,常规的端到端方法由于幻觉而产生了不正确的提问。
图 3 展示了一个指令调整数据的示例。相比之下,我们提供了使用相同信息通过之前的端到端方法 [11,14] 生成的对,之前的方法由于幻觉生成了错误的对。结构化信息提取的提示在附录 A.2 中提供。
手术视觉概念对齐:我们基于公开的手术数据集 CholecT50 创建了手术视觉概念对齐数据,该数据帮助模型识别基本的手术视觉概念,如器械、器官和动作。CholecT50 包括 50 个内窥镜视频,每个帧都标注有动作三元组:[器械,动词,目标],分别表示工具、动作和动作的对象或部位。
我们首先将视频分成 30-60 秒的片段。为了为每个视频片段生成简洁的描述,我们首先合并具有相同注释的连续帧,同时保留时间顺序。获得合并注释的序列后,我们使用该序列提示 Llama-3-70B 生成片段的描述。总共采样了 2,200 个视频 - 文本对,以创建如公式 1 所述的指令调整数据集。
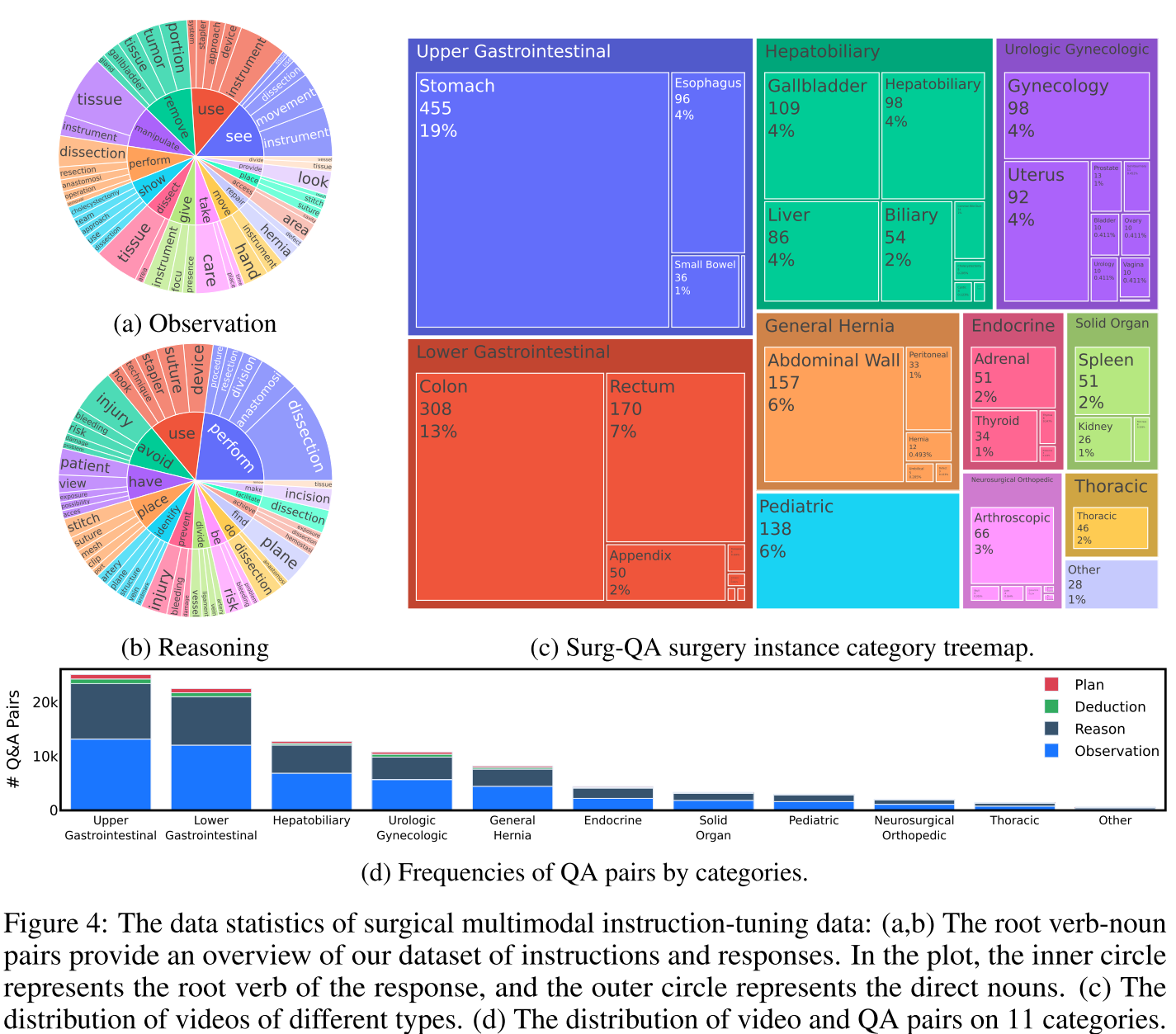
比较:如表 1 和表 2 所示,我们将 Surg-QA 与现有的通用领域 VQA 数据集和手术领域 VQA 数据集进行了比较。首先,关于 Surg-QA 是否足以训练多模态 LLM:表 1 显示,Surg-QA 规模庞大,拥有 44K 个视频和 102K 个问答对,可与通用领域 VQA 数据集相媲美。
| 通用 VQA 数据集 | 问答对生成方式 | 视频片段数 | 问答对数 | 平均时长 |
|---|---|---|---|---|
| MSVD-QA [26] | 自动 | 2K | 51K | 10 秒 |
| ActivityNet-QA [29] | 人工 | 6K | 60K | 180 秒 |
| MovieQA [22] | 人工 | 7K | 7K | 200 秒 |
| MSRVTT-QA [26] | 自动 | 10K | 244K | 15 秒 |
| VideoInstruct-100K [15] | 人工 & 自动 | – | 100K | - |
| Surg-QA(我们的) | 自动 | 44K | 102K | 20 秒 |
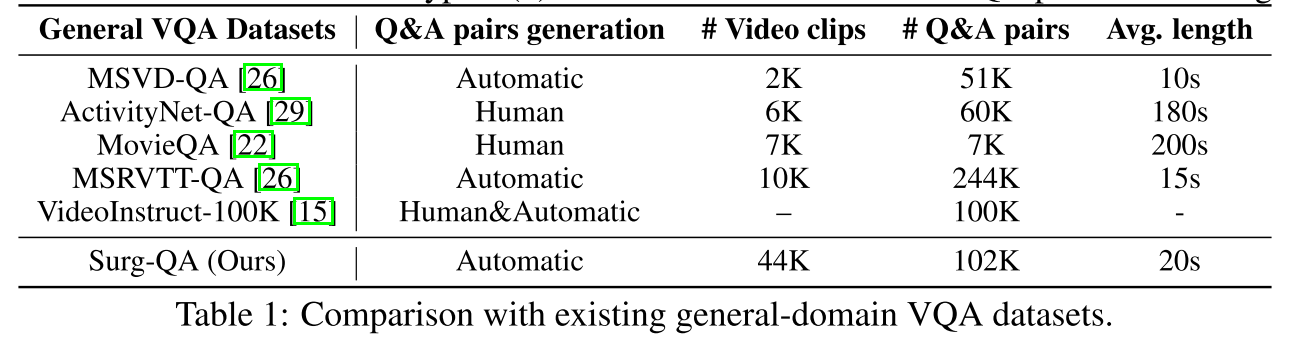
表 1 手术视频的问答对,而非基于帧的注释。它还整合了观察性和基于推理的知识,提供了对手术过程的全面理解。
其次,Surg-QA 超越了传统的手术领域 VQA 数据集。如表 2 所示,Surg-QA 包括更多的手术过程、更广泛的手术类型(图 4c),并提供基于视频的问答对,而非基于帧的注释。它还整合了观察性和基于推理的知识,提供了对手术过程的全面理解。
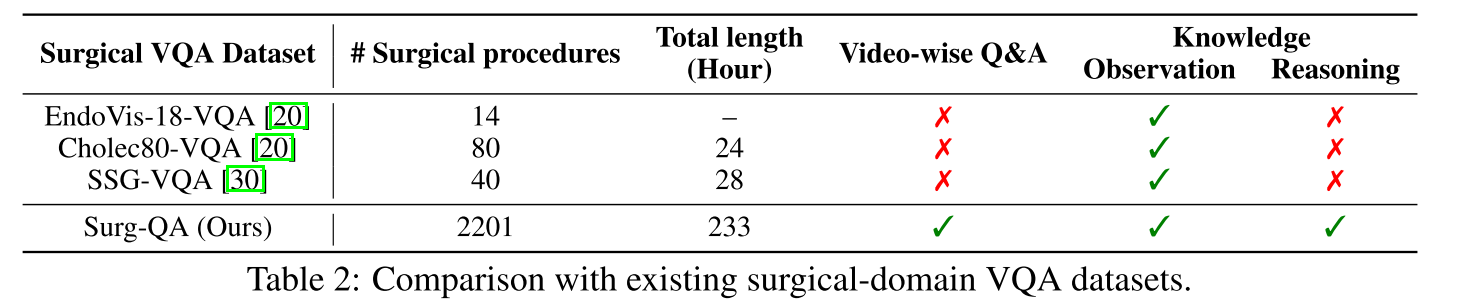
表 2:与现有手术领域 VQA 数据集的比较。
4 手术视觉指令调整
架构
LLaVA-Surg 是一个大型视觉 - 语言模型,旨在生成关于手术视频的有意义对话。它采用了 Video-ChatGPT [15] 的架构,这是一种通用领域的多模态对话模型。
给定一个视频,模型首先均匀采样 N 帧,并使用 CLIP ViT-L/14 [18] 计算每帧的帧级特征\(h \in \mathbb{R}^{N \times h \times w \times D}\),其中 D 是 CLIP 特征的隐藏维度,h 和 w 分别是视频的高度和宽度。
通过时间融合操作融合特征 h,其中时间特征\(t \in \mathbb{R}^{N \times D}\)通过沿时间维度的平均池化操作导出,空间特征\(s \in \mathbb{R}^{(h \times w) \times D}\)通过沿空间维度的相同平均池化操作导出。
通过连接 t 和 s,我们得到视频级特征\(f \in \mathbb{R}^{(N+h \times w) \times D}\),然后将其输入到一个线性投影层,该层将 f 连接到语言模型。
端到端指令调整
为了平衡第 1 到第 4 层的知识,我们将第 3 节中讨论的结构化手术视频学习数据和概念对齐数据相结合,得到 38K 个训练视频片段和 90K 个问答对。
这些对被转换为如公式 3 所述的指令遵循数据,数据包括简单呈现描述视频任务的指令,以及回答各种推理任务的任务。为了训练模型遵循各种指令并以对话方式完成任务,我们将 LLaVA-Surg 作为聊天机器人在对话数据上进行微调。在训练过程中,我们仅保留 CLIP 视觉编码器的权重,并微调其余参数。
5 实验
我们进行实验以研究两个关键组件:LLaVA-Surg 的性能和所生成的多模态手术指令调整数据的质量。我们的实验集中在两个评估设置上:(1)LLaVA-Surg 在手术视频问答中的表现如何,以及它与手术领域现有方法的比较如何?(2)GPT 评估框架与人类专家评估相比如何?
5.1 实现细节
数据
我们使用关键词 “intervention” 从 WebSurg 收集了 2,054 个手术过程,并使用关键词 “gallbladder” 收集了另外 97 个过程用于未来评估,总计 2,151 个过程。这些被随机分为 1,935 个过程的训练集和 216 个过程的测试集。
在我们的指令调整数据生成管道中,我们使用 “large-v2” 版本的 WhisperX [3] 转录手术讲座。如第 3 节所述,我们使用 Llama-3-70B-Instruct [1] 进行信息提取和数据生成(使用一个本地模型)。我们使用 “gpt-3.5-turbo-0125” 进行以下定量评估。
训练
我们使用 LLaVA-Med 作为预训练语言主干,并在 90K 个手术视频指令遵循数据上微调模型。我们使用 CLIP ViT-L/14 作为图像编码器,并使用 LLaVA-Med 的语言主干作为 LLaVA-Surg 的初始权重。我们更新将视频特征投影到 LLM 输入空间的线性层和语言主干,同时保持 CLIP 编码器冻结。
我们使用 2e-5 的学习率和 128 的总体批量大小对模型进行 5 个 epoch 的微调。我们的 7B 模型在 8 个 A100 40GB GPU 上训练大约需要 6 小时。对于其余超参数,我们遵循 [15] 中的设置。
5.2 定量评估
| 模型 | 分数(0-5) | Accuracy@all | Accuracy@1 |
|---|---|---|---|
| LLaVA-Med | 1.30 | 0.123 | 0.211 |
| Video-LLaVA | 1.32 | 0.129 | 0.224 |
| Video-ChatGPT | 1.04 | 0.098 | 0.172 |
| LLaVA-Surg(我们的) | 2.45 | 0.308 | 0.545 |
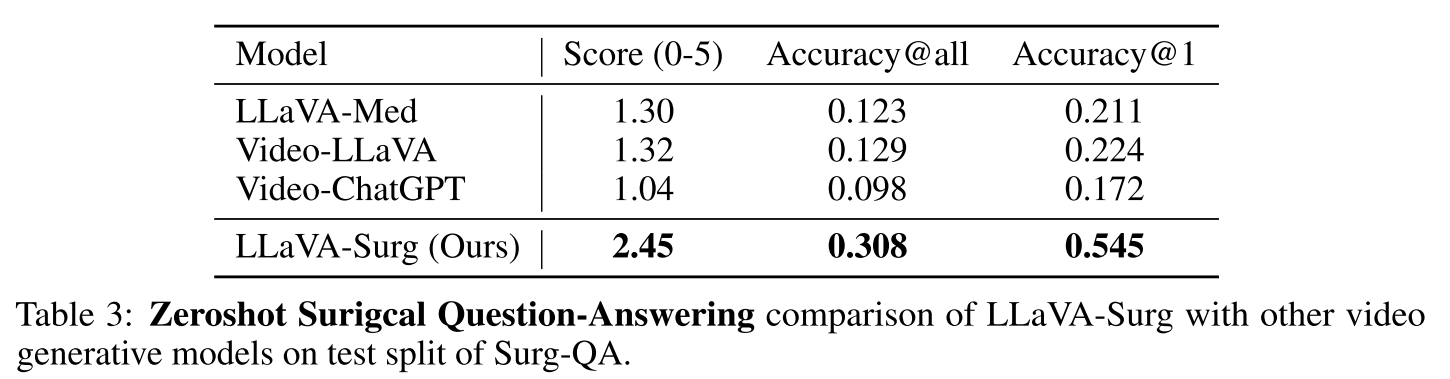
表 3:LLaVA-Surg 与其他视频生成模型在 Surg-QA 测试集上的零样本手术问答比较。
问答评估
我们对 Surg-QA 测试集进行了全面的定量评估,该测试集由 4,359 个开放式手术视频问答对组成。遵循最近使用 GPT 评估开放式问题的工作 [12,15,11],我们的评估使用 GPT-3.5-Turbo 进行评估,以评估模型回答手术视频问题的能力。
该评估过程测量模型生成的预测的准确性,并在 0 到 5 的范围内分配相对分数。我们在附录 A.2 中提供了用于评估的提示。在我们的评估过程中,GPT-3.5-Turbo 通过将模型的输出与数据集中的地面实况进行比较来对模型的输出进行评分。
每个输出根据其反映观察结果的准确性在 0 到 5 的范围内进行评分。这种方法使我们能够直接确定模型预测的准确性。为此,我们向 GPT 提供了第 3 节中提到的提取的观察结果,使其能够评估答案中包含的观察结果的正确性。
此外,GPT-3.5-Turbo 提供了详细的评论,突出显示了匹配和差异以供进一步参考。我们的结果如表 3 所示,其中我们提供了 GPT 评估分数。此外,我们计算了至少匹配一个观察结果时的准确性(accuracy@1)和测试集中所有观察结果的总体准确性(accuracy@all)。
为了对 LLaVA-Surg 进行基准测试,我们将其性能与其他重要模型(如 Video-LLaVA 和 Video-ChatGPT)进行了比较。尽管这些模型奠定了坚实的基础,但 LLaVA-Surg 在手术领域的表现优于它们,实现了最先进的(SOTA)性能。
我们还与 LLaVA-Med 进行了比较,LLaVA-Med 是生物医学图像领域仅支持单模态图像的 MLLM,我们将视频片段的第一帧输入模型,结果证明了视频模态对手术领域的重要性。这些结果表明,LLaVA-Surg 能够理解手术视频内容,并生成准确、上下文丰富的问题答案。
人类专家评估:为了验证 GPT 评估框架是否可以对模型的真实性能进行基准测试,一位人类专家(外科医生)也对部分实验结果进行了评估。外科医生仅根据他对手术视频的理解,为 LLaVA-Surg 的回答分配 0 到 5 的分数。
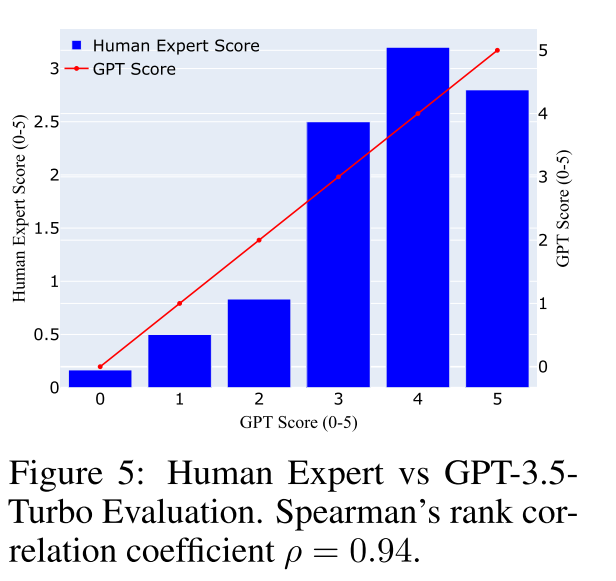
我们还向他提供了用于 GPT 评估的提示作为参考。具体来说,我们从 GPT 评估结果中为每个分数随机采样了一部分数据,总共 41 个视频 - 文本对,然后将这些样本与人类专家为每个分数给出的平均分数进行比较。
我们在图 5 中报告了人类专家评估和 GPT 评估之间的比较结果。图中显示,人类专家和 GPT 分配的分数之间存在很强的相关性。评分模式的相似性表明,GPT 评估框架与人类专家判断有效对齐,并为评估提供了更具可扩展性的解决方案。完整的人类评估结果和评论见补充材料。
5.3 定性评估

我们对模型在各种开放式手术视频问答任务上进行了广泛评估。表 4 说明了一个涉及胃旁路手术的示例。LLaVA-Surg 准确地将该过程识别为胃旁路手术,注意到使用了缝合线和闭合操作。它正确回答了随后关于使用不可吸收单丝缝合线闭合彼得森间隙的问题。然而,LLaVA-Med 未能正确描述视频,也未能回答后续问题。我们在附录 C 中提供了更多示例。
6 结论
在本文中,我们介绍了 Surg-QA,一个由 102K 个视频 - 文本对组成的手术视频指令调整数据集。Surg-QA 主要通过经济高效的两阶段问答生成管道生成,该管道通过 LLM 有效减少了问答生成过程中的幻觉。
然后,我们在 Surg-QA 上训练了手术视频领域的多模态 LLM LLaVA-Surg。LLaVA-Surg 在理解手术视频和参与手术视频对话方面显示出巨大潜力,在我们的综合评估中优于以前的多模态 LLM。
虽然 LLaVA-Surg 在手术视频领域与现有方法相比表现出色,但我们注意到 LLaVA-Surg 受到幻觉的限制。未来的工作旨在邀请专家审查 Surg-QA 中生成的样本,以提高 LLaVA-Surg 的准确性和可靠性。
手术视频问答示例

| 用户 | 你能描述一下手术视频吗? |
|---|---|
| LLaVA-Surg | 手术视频似乎展示的是腹腔镜 Roux-en-Y 胃旁路手术。在视频中,我们看到外科医生正在进行缝合,这表明该过程可能处于后期阶段,可能是在空肠造口术或胃空肠造口术的闭合过程中。摄像机提供了手术部位的清晰视图,使我们能够观察到器械和外科医生的手在完成旁路手术时的复杂动作。 |
| 用户 | 在此过程中,彼得森间隙是如何闭合的? |
| LLaVA-Surg | 彼得森间隙使用不可吸收的单丝缝合线闭合。 |
| 用户 | 你能描述一下手术视频吗? |
| LLaVA-Med | 该图像是显示大体正常阑尾外观的手术视频。这意味着阑尾看起来正常且未受阻,肉眼可见。该视频提供了手术过程中阑尾外观的视觉表示。 |
| 用户 | 在此过程中,彼得森间隙是如何闭合的? |
| 人类专家 | 这似乎是一种用于减肥的旁路手术。可见小肠和肠系膜,以及腹腔镜持针器、针和单丝缝合线。外科医生正在闭合彼得森间隙,该间隙是在解剖和创建小肠吻合术后形成的,使用连续缝合以防止内疝并发症。 |
| 用户 | 在此过程中,彼得森间隙是如何闭合的? |
| 人类专家 | 在这个片段中,彼得森间隙用连续单丝缝合线闭合。 |
| 用户 | 你能描述一下手术视频吗? |
| Llama-3-70B(仅语言) | 该手术视频似乎展示了一种复杂的减肥手术,特别是胃旁路手术。在视频中,我们看到外科医生仔细闭合特定区域,可能是为了防止内部疝,并使用荷包缝合技术固定组织。 |
表 4:手术视频问答示例比较。我们提供了仅基于提取的信息和视频标题的纯语言 Llama-3-70B 生成的地面实况答案作为参考。这些答案被视为模型性能的上限。
附录1
Videos Available in https://websurg.com/, we provide the corresponding URL to each of the question-answer pair.
附录2

Prompt for question-answer generation for observation The prompt used to generate instruction
data that describes a surgical video is in Figure 7.
Prompt for question-answer generation for reasoning The prompt used to generate instruction
data for a variety of reasoning tasks is in Figure 8.
Prompt for GPT evaluation The prompt used to generate the evaluation results discussed in 5.2
is in Figure 9.
B More Discussions of LLaVA-Surg
Limitations of LLaVA-Surg The limitations of LLaVA-Surg include (1) hallucination, where it
may produce inaccurate but confident responses due to the lack of alignment with human preferences,
(2) Its performance depends on the surgery procedures seen in SurgQA, with results varying widely
based on the surgery type. Additionally, since the data source Surg-QA, derived from WebSurg,
includes many rare cases, LLaVA-Surg’s responses may lack universality and may not apply to a
broader range of clinical situations, (3) LLaVA-Surg might exhibit bias because of existing biases

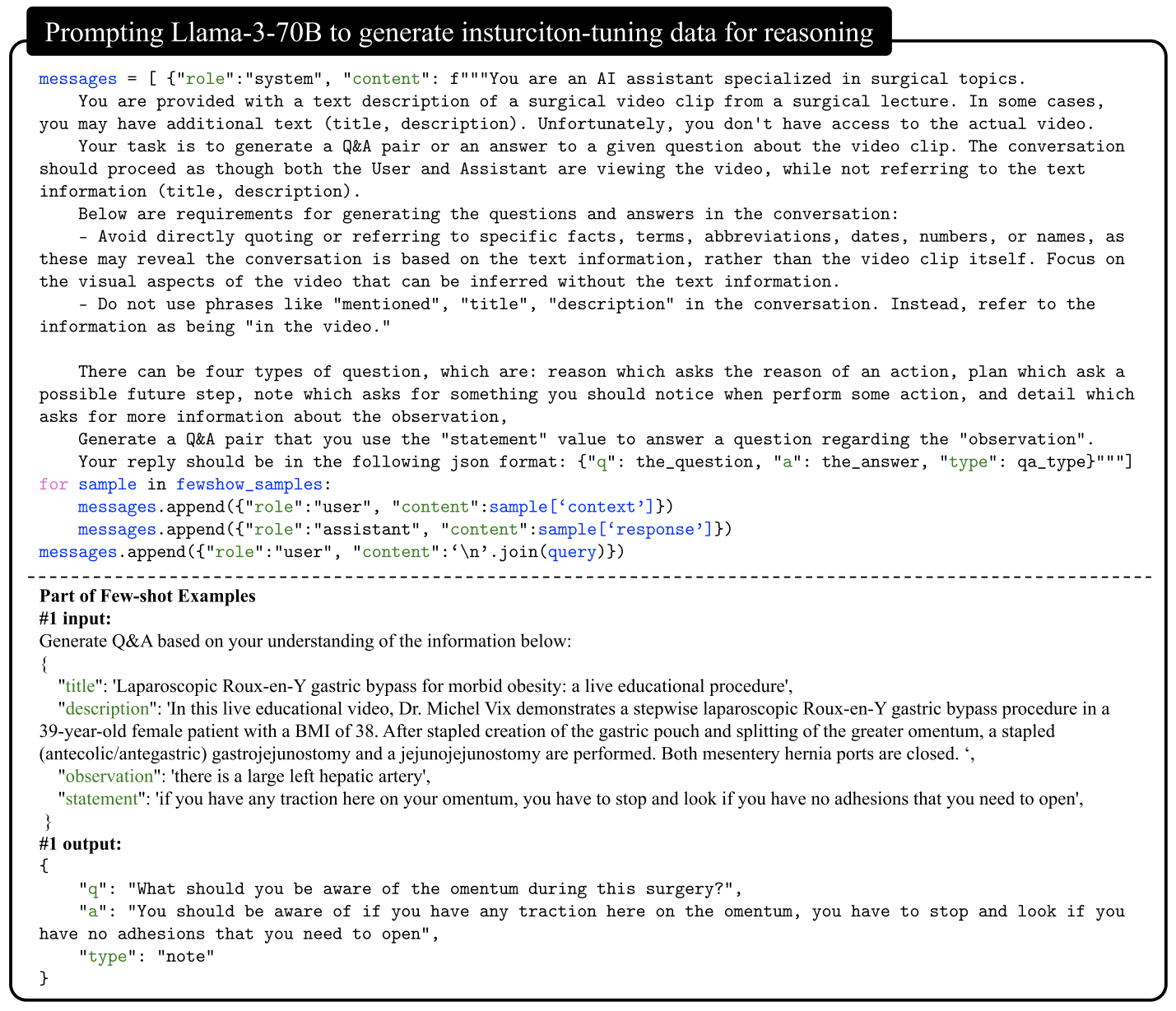 Figure 8: messages we use to prompt Llama-3-70B to generate instruction-tuning data for reasoning. query provides a title, video description, observation, and statement to form a reasoning question-answer pair.
Figure 8: messages we use to prompt Llama-3-70B to generate instruction-tuning data for reasoning. query provides a title, video description, observation, and statement to form a reasoning question-answer pair.
present in surgical videos and training data, and (4) LLaVA-Surg may be weak in the general domains of question-answering compared to other models. The potential negative societal impact of deploying LLaVA-Surg arises if its outputs are not carefully cross-referenced with verified medical knowledge.

 更多示例
更多示例





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









