










发表时间 :2024年10月3日
Qwen2-VL:提升视觉语言模型在任意分辨率下对世界的感知能力
摘要
我们提出了 Qwen2-VL 系列,这是对先前 Qwen-VL 模型的高级升级,重新定义了视觉处理中传统的预定分辨率方法。Qwen2-VL 引入了原生动态分辨率机制,使模型能够将不同分辨率的图像动态处理为不同数量的视觉标记。
这种方法使模型能够生成更高效、准确的视觉表示,紧密贴合人类感知过程。模型还集成了多模态旋转位置嵌入(M-RoPE),促进文本、图像和视频的位置信息有效融合。我们采用统一范式处理图像和视频,增强了模型的视觉感知能力。
为探索大型多模态模型的潜力,Qwen2-VL 研究了大型视觉语言模型(LVLMs)的规模法则。通过扩展模型规模(参数版本为 20 亿、80 亿和 720 亿)和训练数据量,Qwen2-VL 系列实现了极具竞争力的性能。值得注意的是,Qwen2-VL-72B 模型在各种多模态基准测试中取得了与 GPT-4o 和 Claude3.5Sonnet 等领先模型相当的结果,超越了其他通用模型。
1 引言
在人工智能领域,大型视觉语言模型(LVLMs)是一项重大突破,它建立在传统大型语言模型强大的文本处理能力之上。这些先进模型现在具备解释和分析更广泛数据的能力,包括图像、音频和视频。能力的扩展使 LVLMs 成为解决各种现实挑战的不可或缺的工具。
LVLMs 因其将广泛而复杂的知识浓缩为功能表示的独特能力,正在为更全面的认知系统铺平道路。通过集成不同的数据形式,LVLMs 旨在更紧密地模仿人类感知和与环境互动的细致方式,使这些模型能够更准确地呈现我们与环境互动和感知的方式。
大型视觉语言模型(LVLMs)的最新进展(Li 等人,2023c;Liu 等人,2023b;Dai 等人,2023;Zhu 等人,2023;Huang 等人,2023a;Bai 等人,2023b;Liu 等人,2023a;Wang 等人,2023b;OpenAI.,2023;Team 等人,2023)在短时间内取得了显著改进。这些模型(OpenAI,2023;Touvron 等人,2023a,b;Chiang 等人,2023;Bai 等人,2023a)通常遵循 “视觉编码器→跨模态连接器→LLM” 的通用方法。
这种设置与作为主要训练方法的下一个标记预测以及高质量数据集的可用性(Liu 等人,2023a;Zhang 等人,2023;Chen 等人,2023b;Li 等人,2023b)共同推动了大部分进展。其他因素,如更大的模型架构(Alayrac 等人,2022)、更高分辨率的图像(Li 等人,2023a,d)以及专家混合模型(MoE)(Wang 等人,2023b;Ye 等人,2023b)、模型集成(Lin 等人,2023)和视觉与文本模态之间更复杂的连接器(Ye 等人,2023a)等先进技术,也在增强 LVLMs 有效处理复杂视觉和文本信息的能力方面发挥了关键作用。
然而,当前的大型视觉语言模型(LVLMs)通常受限于固定的图像输入尺寸。标准 LVLMs 将输入图像编码为固定分辨率(如 224×224),通常通过对图像进行下采样或上采样(Zhu 等人,2023;Huang 等人,2023a),或采用先缩放后填充的方法(Liu 等人,2023b,a)。
尽管这种 “一刀切” 的策略能够处理一致分辨率的图像,但它也限制了模型捕捉不同尺度信息的能力,尤其导致高分辨率图像中细节信息的显著丢失。因此,此类模型无法像人类视觉那样对尺度和细节具有同等的敏感度来感知视觉信息。
此外,大多数 LVLMs 依赖静态、冻结的 CLIP 式(Radford 等人,2021)视觉编码器,这引发了关于此类预训练模型生成的视觉表示是否足够的担忧,尤其是在复杂推理任务和处理图像内复杂细节时。最近的工作(Bai 等人,2023b;Ye 等人,2023a)已尝试通过在 LVLM 训练过程中对视觉 Transformer(ViT)进行微调来解决这些限制,这已显示出改进的结果。
为了进一步增强模型对不同分辨率的适应性,我们在 LVLM 训练过程中引入了动态分辨率训练。具体而言,我们在 ViT 中采用了二维旋转位置嵌入(RoPE),从而使模型能够更好地捕捉不同空间尺度的信息。
对于本质上是帧序列的视频内容,许多现有模型继续将其视为独立的模态。然而,理解视频中所呈现的现实的动态本质,对于旨在掌握现实世界复杂性的模型至关重要。与本质上是一维的文本不同,现实世界环境存在于三维空间中。
当前模型中一维位置嵌入的使用严重限制了它们有效建模三维空间和时间动态的能力。为了弥合这一差距,我们开发了多模态旋转位置嵌入(M-RoPE),它采用独立组件来表示时间和空间信息。这使模型能够自然地理解动态内容,如视频或流数据,提高其理解和与世界互动的能力。
此外,与大型语言模型(LLMs)的规模扩展相比,当前 LVLMs 在探索训练数据和模型参数规模影响方面仍处于早期阶段。LVLMs 规模法则的探索 —— 模型和数据规模的增加如何影响性能 —— 仍然是一个开放且有前景的研究领域。
在这项工作中,我们介绍了 Qwen 家族大型视觉语言模型的最新成员:Qwen2-VL 系列,该系列包含三个开放权重模型,总参数分别为 20 亿、80 亿和 720 亿。如图 1 所示,Qwen2-VL 的关键进展包括:
- 跨各种分辨率和宽高比的最先进理解能力:Qwen2-VL 在视觉基准测试中实现了领先性能,包括 DocVQA、InfoVQA、RealWorldQA、MTVQA、MathVista 等。
- 长时视频(20 分钟以上)理解能力:Qwen2-VL 能够理解超过 20 分钟的视频,增强了其执行高质量基于视频的问答、对话、内容创作等能力。
- 用于设备操作的强大代理能力:凭借先进的推理和决策能力,Qwen2-VL 可以与手机、机器人等设备集成,基于视觉输入和文本指令实现自主操作。
- 多语言支持:为服务全球用户,除英语和中文外,Qwen2-VL 现在支持图像内的多语言上下文理解,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。

2 方法
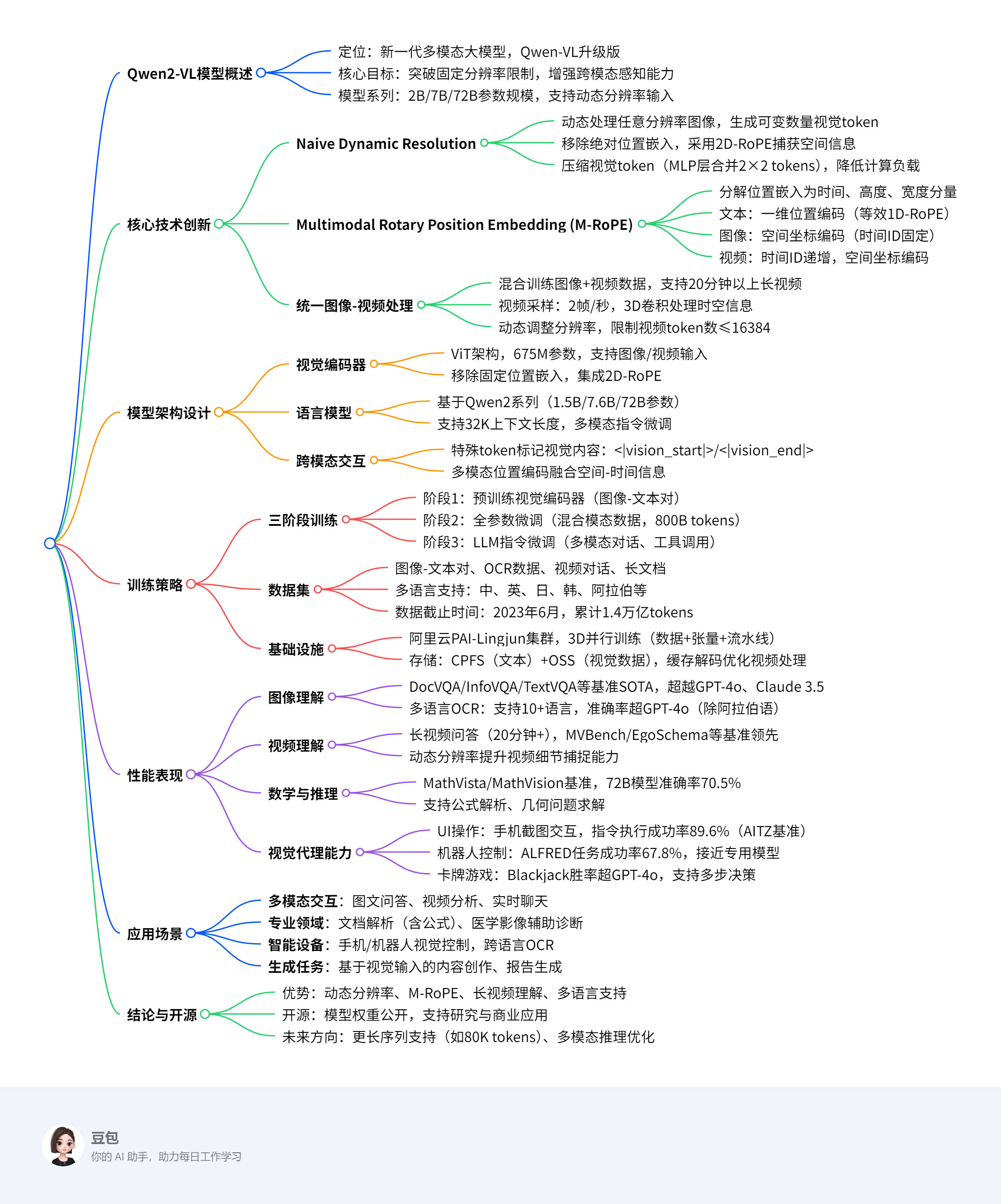
Qwen2-VL 系列包含 3 种规模的模型,即 Qwen2-VL-2B、Qwen2-VL-7B 和 Qwen2-VL-72B。表 1 列出了超参数和重要信息。值得注意的是,Qwen2-VL 在不同规模的 LLM 中采用了 6.75 亿参数的 ViT,确保 ViT 的计算负载无论 LLM 的规模如何都保持恒定。
2.1 模型架构
图 2 展示了 Qwen2-VL 的完整结构。我们保留了 Qwen-VL(Bai 等人,2023b)框架,该框架集成了视觉编码器和语言模型。为了适应各种规模,我们实现了一个约 6.75 亿参数的视觉 Transformer(ViT)(Dosovitskiy 等人,2021),擅长处理图像和视频输入。

Qwen2 - VL 多模态模型 的架构示意图,关键看 视觉编码器(Vision Encoder) 与 QwenLM 解码器(QwenLM Decoder) 如何协作:
一、核心流程逻辑
模型遵循 “多模态输入→编码转换→融合理解→输出” 路径,用 视觉编码器提取图像 / 视频特征,再经 QwenLM 解码器做文本交互(问答、内容生成等),实现跨模态理解。
二、模块拆解与功能
1. 输入层:多模态 “原材料”
-
Picture 1:高分辨率网页文档(宽 1092、高 8204 ),编码后转为 11427 个 tokens,代表复杂图文内容(如博客、长文档 )。
-
Picture 2:低分辨率小图(宽 224、高 28 ),编码为 8 个 tokens,体现对微小视觉元素的处理(如图标、小图 )。
-
Picture 3:常规风景图(宽 1260、高 700 ),编码为 1125 个 tokens,覆盖日常图像场景。
-
Video 1:16 秒视频(宽 644、高 336 ),编码为 2208 个 tokens,展示对动态视频的支持(提取帧序列特征 )。
2. 视觉编码器(Vision Encoder)
-
核心作用:接收 “Native Resolution Input(原生分辨率输入)”,直接处理不同分辨率的原始图像 / 视频,无需统一缩放,最大程度保留细节(比如 Picture 1 的长文档、Video 1 的动态帧 )。
-
关键能力:把多模态数据转化为模型能理解的 tokens 序列,是实现 “动态分辨率处理” 的核心(不同输入分辨率对应不同 tokens 数量 )。
3. QwenLM 解码器(QwenLM Decoder)
-
核心作用:接收视觉编码器输出的 tokens 流,融合图像 / 视频特征与文本能力,完成问答、内容生成等任务(比如识别 Picture 3 风景、理解 Video 1 动态内容 )。
-
协作逻辑:视觉编码器负责 “感知多模态”,QwenLM 解码器负责 “语言理解与输出”,共同实现跨模态交互。
在语言处理方面,我们选择了更强大的 Qwen2(Yang 等人,2024)系列语言模型。为了进一步增强模型有效感知和理解视频中视觉信息的能力,我们引入了几个关键升级:
原生动态分辨率
Qwen2-VL 的一个关键架构改进是引入了原生动态分辨率支持(Dehghani 等人,2024)。与 Qwen-VL 不同,Qwen2-VL 现在可以处理任何分辨率的图像,将其动态转换为可变数量的视觉标记。
为了支持此功能,我们对 ViT 进行了修改,移除了原有的绝对位置嵌入,并引入了 2D-RoPE(Su 等人,2024;Su,2021)来捕捉图像的二维位置信息。在推理阶段,不同分辨率的图像被打包成单个序列,通过控制打包长度来限制 GPU 内存使用。
此外,为了减少每个图像的视觉标记数量,在 ViT 之后使用一个简单的 MLP 层将相邻的 2×2 标记压缩为单个标记,并在压缩后的视觉标记的开头和结尾放置特殊的 <|vision_start|> 和 <|vision_end|> 标记。因此,使用 patch_size=14 的 ViT 编码的 224×224 分辨率的图像,在进入 LLM 之前将被压缩为 66 个标记。
多模态旋转位置嵌入(M-RoPE)

多模态旋转位置嵌入(Multimodal Rotary Position Embedding,M-RoPE) 的原理展示,用于理解模型如何处理视频这类多模态数据中的时空位置信息,核心看 “时间(Time)、高度(Height)、宽度(Width)” 三维位置编码逻辑:
一、核心概念:M-RoPE 解决啥问题?
在多模态模型(比如处理视频、图像 + 文本)中,需要给 图像 / 视频的像素、文本的 token 编码 “位置信息”,让模型理解元素的空间(高、宽)和时间(帧顺序)关系。
M-RoPE 的关键是:把位置拆成 “时间、高度、宽度” 三个维度,用统一方式编码图像、视频、文本的位置,让模型更好融合多模态信息。
二、模块拆解与逻辑
1. 左侧:视频帧的三维位置编码(Position ids)
-
对象:以 “柴犬视频帧” 为例,展示视频不同帧、不同像素的位置怎么编码。
-
三维坐标:每个像素 / 帧的位置用
(Time, Height, Width)表示:-
Time(时间):视频的帧序号(图中是 0、1、2 三帧 )。
-
Height(高度):帧内像素的行位置(比如 0、1、2 行 )。
-
Width(宽度):帧内像素的列位置(比如 0、1、2、3 列 )。
-
-
作用:给视频里的每个像素 / 帧分配唯一三维坐标,让模型理解 “哪些像素在同一帧、同一行 / 列,以及帧的先后顺序”。
2. 中间:文本与位置编码的关联
-
文本:“This video features a dog, specifically a Shiba ……” 这段描述视频的文本,每个词也需要位置编码。
-
位置映射:文本的每个 token(比如 “dog”“Shiba” )对应一组位置编码(图中
(4,4,4)、(5,5,5)等 ),和视频的三维位置编码 统一格式,方便模型融合图文信息。
3. 右侧:多模态旋转位置嵌入(Multimodal Rotary Position Embedding)
-
核心逻辑:把 “时间、高度、宽度” 三个维度的位置信息,通过旋转嵌入(Rotary Position Embedding)的方式,转化为模型能理解的向量(蓝色方块序列 )。
-
优势:让图像 / 视频的空间位置(高、宽)和时间顺序(帧),与文本的序列位置统一编码,增强多模态数据的融合能力(比如让模型知道 “视频第 2 帧的像素” 和 “文本第 5 个词” 的位置关联 )。
三、设计意义
M-RoPE 是为解决 “多模态数据位置编码不统一” 问题而生:
-
图像 / 视频有 “高、宽、时间” 三维位置,文本只有一维序列位置,直接拼接会冲突。
-
M-RoPE 通过拆分维度、统一旋转嵌入,让模型能同时理解 视频的时空结构 和 文本的语义顺序,提升多模态任务(视频问答、图文生成 )的效果。
(如何理解旋转位置?)另一个关键架构增强是多模态旋转位置嵌入(M-RoPE)的创新。与 LLMs 中传统的 1D-RoPE(仅限于编码一维位置信息)不同,M-RoPE 通过将原始旋转嵌入分解为时间、高度和宽度三个分量,有效建模多模态输入的位置信息。对于文本输入,这些分量使用相同的位置 ID,使 M-RoPE 在功能上等同于 1D-RoPE(Su,2024)。
处理图像时,每个视觉标记的时间 ID 保持恒定,而高度和宽度分量根据标记在图像中的位置分配不同的 ID。对于被视为帧序列的视频,时间 ID 随每个帧递增,而高度和宽度分量遵循与图像相同的 ID 分配模式。
在模型输入包含多种模态的情况下,每种模态的位置编号通过将前一模态的最大位置 ID 加 1 来初始化。M-RoPE 的示意图如图 3 所示。M-RoPE 不仅增强了位置信息的建模,还减少了图像和视频的位置 ID 值,使模型在推理时能够外推到更长的序列。
先从最基础的 文本一维 RoPE 入手,理解旋转的数学本质。
对于文本中的第 i 个 token,它的位置编码是通过 “向量旋转” 实现的。假设 token 的向量表示为 x(维度为 d,通常是偶数,比如 4096 ),RoPE 对 x 的前半部分和后半部分做如下操作:
\(\begin{split} \text{Rot}(x, \theta_i) &= \begin{bmatrix} x_0 \cos\theta_i - x_1 \sin\theta_i \\ x_0 \sin\theta_i + x_1 \cos\theta_i \\ \vdots \\ x_{d-2} \cos\theta_i - x_{d-1} \sin\theta_i \\ x_{d-2} \sin\theta_i + x_{d-1} \cos\theta_i \end{bmatrix} \\ \theta_i &= \frac{i}{10000^{2k/d}} \quad (k=0,1,\dots,d/2-1) \end{split}\)
-
大白话拆解:
-
把 token 向量
x按维度拆成两两一组((x0,x1), (x2,x3), ...)。 -
对每组向量,用 旋转矩阵(\(\begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix}\) )进行旋转,旋转角度 \(\theta_i\) 与位置
i相关(位置越靠后,角度越大 )。 -
这样,每个位置
i的 token 向量都会被 “旋转” 一个特定角度,相对位置可以通过角度差体现(比如位置i和j的角度差是 \(\theta_i - \theta_j\) )。
-
二、多模态扩展(M-RoPE)的公式逻辑
在多模态场景(如图中的视频 + 文本),M-RoPE 需要编码 三维位置(时间 Time、高度 Height、宽度 Width),公式会扩展为 “每个维度独立旋转,再融合”。
假设视频中某一帧的某像素位置是 (t, h, w)(t = 时间,h = 高度,w = 宽度 ),M-RoPE 对这三个维度分别计算旋转角度,再将它们的旋转效果 叠加 到 token 向量上。
简化版公式逻辑:
-
时间维度(t):计算角度 \(\theta_t = \text{RoPE\_func}(t)\),对向量做时间相关的旋转。
-
高度维度(h):计算角度 \(\theta_h = \text{RoPE\_func}(h)\),对向量做高度相关的旋转。
-
宽度维度(w):计算角度 \(\theta_w = \text{RoPE\_func}(w)\),对向量做宽度相关的旋转。
-
最终旋转:将三个维度的旋转矩阵 按顺序作用 到 token 向量上,得到融合三维位置的编码。
三、“旋转” 在图中的体现(为什么图里看不到公式)
图里的 “Position ids: (t, h, w)” 和 “Multimodal Rotary Position Embedding” 其实是 公式的可视化映射:
-
图中的
(0,0,0), (0,0,1), ...对应公式里的位置(t, h, w)。 -
右侧的蓝色方块序列,对应公式里 “旋转后的向量表示”(每个方块代表旋转后的向量维度 )。
-
中间的文本 token 位置编码
(4,4,4), (5,5,5)...,对应文本位置与多模态位置的 统一旋转编码逻辑(文本位置可视为(t=0, h=0, w=i),i 是词序 )。
统一图像和视频理解
Qwen2-VL 采用混合训练方案,同时包含图像和视频数据,确保在图像理解和视频 comprehension 方面的熟练程度。为了尽可能完整地保留视频信息,我们以每秒两帧的速度对每个视频进行采样。
此外,我们集成了深度为 2 的 3D 卷积(Carreira 和 Zisserman,2017)来处理视频输入,使模型能够处理 3D 管而不是 2D 补丁,从而能够在不增加序列长度的情况下处理更多视频帧(Arnab 等人,2021)。
为了保持一致性,每个图像被视为两个相同的帧。为了平衡长视频处理的计算需求与整体训练效率,我们动态调整每个视频帧的分辨率,将每个视频的标记总数限制为 16384。这种训练方法在模型理解长视频的能力和训练效率之间取得了平衡。
2.2 训练
遵循 Qwen-VL(Bai 等人,2023b),我们采用三阶段训练方法。在第一阶段,我们专注于仅训练视觉 Transformer(ViT)组件,利用庞大的图像 - 文本对语料库来增强大型语言模型(LLM)内的语义理解。
在第二阶段,我们解冻所有参数,并使用更广泛的数据进行训练,以进行更全面的学习。在最后阶段,我们锁定 ViT 参数,并使用指令数据集对 LLM 进行独家微调。该模型在多样化的数据集上进行预训练,包括图像 - 文本对、光学字符识别(OCR)数据、交错的图像 - 文本文章、视觉问答数据集、视频对话和图像知识数据集。
我们的数据源主要包括清理后的网页、开源数据集和合成数据。我们的数据知识截止日期为 2023 年 6 月。这种多样化的数据组成有助于开发强大的多模态理解能力。
在初始预训练阶段,Qwen2-VL 接触了约 6000 亿个标记的语料库。Qwen2-VL 的 LLM 组件使用 Qwen2(Yang 等人,2024)的参数进行初始化,而 Qwen2-VL 的视觉编码器使用从 DFN 派生的 ViT 进行初始化。
然而,原始 DFN 的 ViT(Fang 等人,2023)中的固定位置嵌入被 RoPE-2D 取代。此预训练阶段主要侧重于学习图像 - 文本关系、通过 OCR 识别图像内的文本内容以及图像分类任务。这种基础训练有助于模型发展对核心视觉 - 文本相关性和对齐的稳健理解。
第二阶段预训练标志着一个重要的进展,涉及额外的 8000 亿个与图像相关的标记数据。此阶段引入了更高数量的混合图像 - 文本内容,促进对视觉和文本信息之间相互作用的更细致理解。视觉问答数据集的纳入细化了模型回答与图像相关查询的能力。
此外,多任务数据集的纳入对于开发模型同时处理多样化任务的能力至关重要,这是处理复杂现实世界数据集时的一项至关重要的技能。同时,纯文本数据在维持和提升模型的语言能力方面继续发挥关键作用。
在整个预训练阶段,Qwen2-VL 处理了累计 1.4 万亿个标记。具体而言,这些标记不仅包括文本标记,还包括图像标记。
然而,在训练过程中,我们仅对文本标记提供监督。接触广泛多样的语言和视觉场景确保模型深入理解视觉和文本信息之间的复杂关系,从而为各种多模态任务奠定坚实基础。
在指令微调阶段,我们采用 ChatML(Openai,2024)格式来构建指令遵循数据。该数据集不仅包括纯基于文本的对话数据,还包括多模态对话数据。多模态组件包括图像问答、文档解析、多图像比较、视频理解、视频流对话和基于代理的交互。
我们全面的数据构建方法旨在增强模型理解和执行各种模态下广泛指令的能力。通过纳入多样化的数据类型,我们寻求开发一种更通用、更强大的语言模型,除了传统的基于文本的交互外,还能够处理复杂的多模态任务。
2.2.1 数据格式
与 Qwen-VL 一致,Qwen2-VL 也使用特殊标记来区分视觉和文本输入。在图像特征序列的开头和结尾插入标记 <|vision_start|> 和 <|vision_end|>,以划定图像内容。
在对话格式方面,我们使用 ChatML 格式构建指令调优数据集,其中每个交互的陈述用两个特殊标记(<|im_start|> 和 <|im_end|>)标记,以促进对话终止。蓝色标记的部分表示受监督的部分。

Visual Grounding. 为了赋予模型具有Visual Grounding功能,在[0,1000)内将边界盒坐标归一化,并表示为“(xtop左,ytop左),(xbottom右,ybottom右)”。 令牌<| box_start |>和<| box_end |>用于划定边界框文本。 要准确地将边界框与其文本描述链接,我们介绍了令牌<| Object_ref_start |>和<| Object_ref_end |>指示边界框引用的内容,从而允许模型有效地解释和生成特定区域的精确描述。

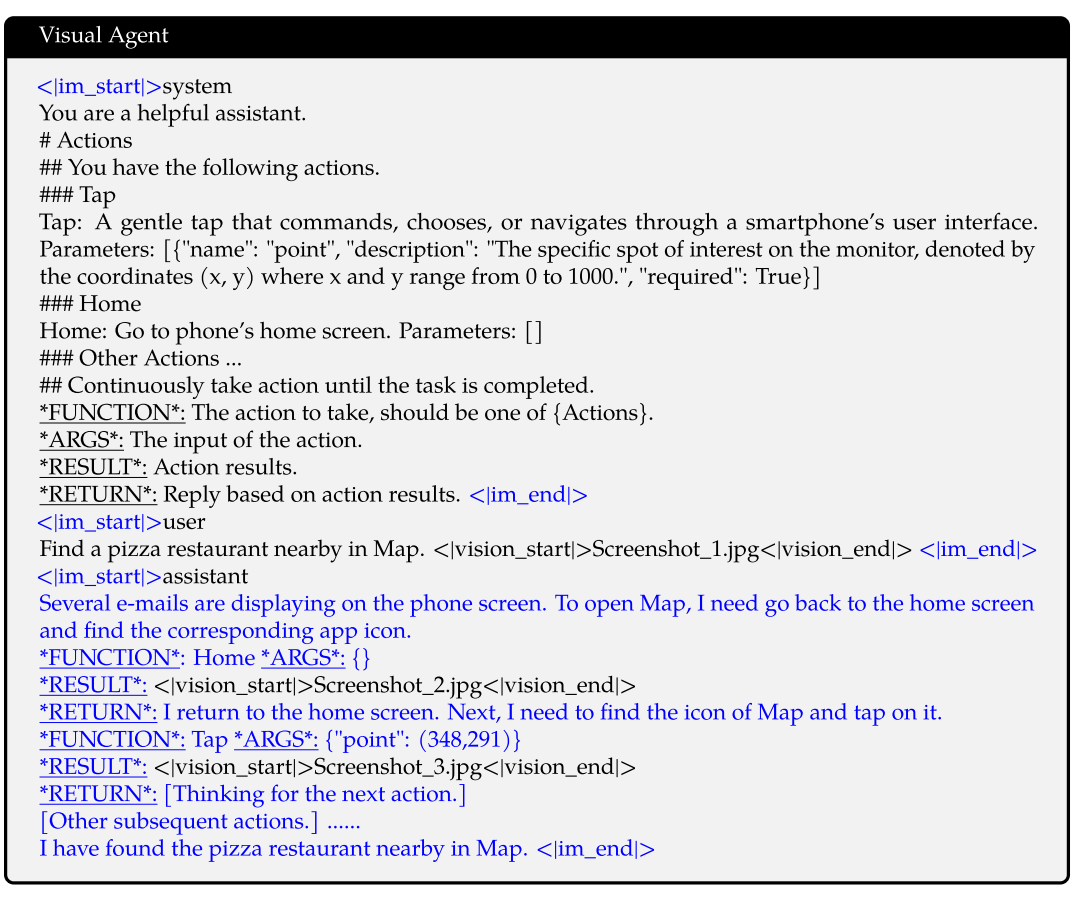
Visual Agent。 为了将QWEN2-VL作为通用Visual Agent开发,我们将各种代理任务(例如UI操作,机器人控制,游戏和导航)作为顺序决策问题,使QWEN2-VL能够通过多步操作执行来完成任务。 对于每个任务,我们首先为功能调用(QWEN Team,2024)定义一组允许的操作和关键字模式(下划线)。 然后,QWEN2-VL分析观测值,执行推理和计划,执行选定的操作并与环境进行交互以获取新的观察结果。 该周期重复迭代,直到任务成功完成为止。 通过集成各种工具并利用大型视觉语言模型(LVLM)的视觉感知能力,Qwen2-VL能够迭代执行涉及现实世界视觉交互的日益复杂的任务。
2.3 多模态模型基础设施
Qwen2-VL 模型在阿里云的 PAI-Lingjun 智能计算服务(AlibabaCloud,2024c)上进行训练,该服务具有可扩展计算、自动恢复和掉队检测功能。
存储
我们使用阿里云的超高速 CPFS(云并行文件存储)(Alibaba-Cloud,2024a)构建 Qwen2-VL 预训练和后训练的存储系统。我们将文本数据和视觉数据存储解耦。我们简单地将文本数据存储在 CPFS 上,并使用 mmap 进行高效访问。
对于视觉数据,我们使用阿里云的 OSS(对象存储服务)(Alibaba-Cloud,2024b)进行持久存储。在训练期间,我们通过 OSS 的 python 客户端并发访问视觉数据,并调整并发和重试参数以避免达到 QPS(每秒查询数)限制。我们还发现视频数据解码是一个主要瓶颈,尤其是对于长视频。在尝试开源(FFmpeg-Developers,2024)和内部软件失败后,我们选择了缓存解码技术。检查点将每个 GPU 的优化器和模型状态保存在 CPFS 上。
并行性
我们使用三维并行性,结合数据并行性(DP)(Li 等人,2020)、张量并行性(TP)(Krizhevsky 等人,2012;Shoeybi 等人,2019)和流水线并行性(PP)(Huang 等人,2019;Narayanan 等人,2021;Lamy-Poirier,2023)来扩展 Qwen2-VL 模型训练。我们还利用 deepspeed 的 zero-1 冗余优化器(Rajbhandari 等人,2020)对状态进行分片以节省内存。
采用具有选择性检查点激活(Chen 等人,2016)的序列并行性(SP)(Korthikanti 等人,2023)来减少内存使用。启用 TP 训练时,我们始终将视觉编码器和大型语言模型一起分片,但由于视觉合并器的参数相对较少,不进行分片。
我们发现,由于卷积运算符的非确定性行为,TP 训练会导致不同的模型共享权重。我们通过对共享权重进行离线归约来解决此问题,从而避免额外的全归约通信步骤。这种方法对性能的影响微乎其微。我们对 Qwen2-VL 72B 训练采用 1F1B PP(Narayanan 等人,2021)。
我们将视觉编码器、视觉适配器和几个 LLM 的解码器层组合成一个阶段,并均匀分割剩余的解码器层。请注意,每个数据点的视觉和文本序列长度是动态的。我们在启动 1F1B 过程之前广播动态序列长度,并使用批处理索引访问形状信息。我们还实现了交错 1F1B PP(Narayanan 等人,2021),但发现它比标准 1F1B 设置慢。
软件
我们使用 PyTorch(Paszke 等人,2019;Ansel 等人,2024)2.1.2 版本和 CUDA 11.8(Nvidia,2024b)进行训练。此外,我们在视觉编码器和 LLM 中利用 flash-attention(Dao 等人,2022;Dao,2024;Shah 等人,2024)进行高效训练。
我们还利用融合运算符(Nvidia,2024a),如 LayerNorm(Ba 等人)RMSNORM(Zhang和Sennrich,2019年)和Adam(Loshchilov and Hutter,2019年)。 除此之外,我们还利用培训过程中矩阵乘法期间的沟通和计算的重叠。
3 实验
在本节中,我们首先通过对各种视觉基准进行对比分析来评估模型的性能,展示我们方法的优势。随后,我们对特定能力进行详细检查,包括一般视觉感知、文档理解、图像中的多语言识别、视频理解和代理能力。最后,我们进行消融研究以调查我们方法的几个关键组件的影响。
3.1 与最先进模型的比较
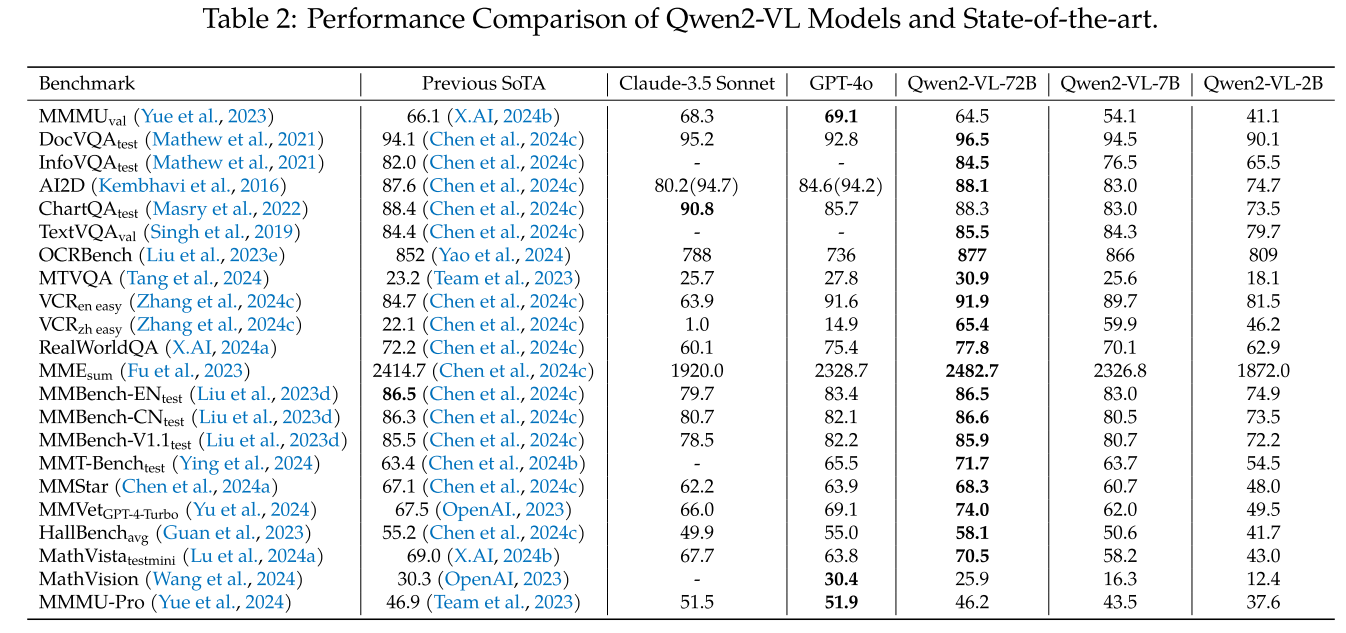
我们通过各种视觉基准、视频任务和基于代理的评估来评估模型的视觉能力。Qwen2-VL 在相同规模下表现出极具竞争力的性能,实现了新的最先进(SoTA)结果。总体而言,我们的 72B 模型在大多数评估指标上始终提供顶级性能,甚至经常超越 GPT-4o(OpenAI,2024)和 Claude 3.5-Sonnet(Anthropic,2024)等闭源模型。
值得注意的是,它在文档理解任务中表现出显著优势。然而,在 MMMU(Yue 等人,2023)基准测试中,我们的模型仍在一定程度上落后于 GPT-4o,这表明 Qwen2-VL-72B 在处理更复杂和具有挑战性的问题集时仍有改进空间。
3.2 定量结果
在本节中,我们对 Qwen2-VL 系列在一系列数据集上进行了广泛评估,全面了解了模型在各个方面的能力。
3.2.1 一般视觉问答
为了严格评估我们模型在一般视觉问答任务中的能力,我们在各种最先进的基准上进行了广泛评估:RealWorldQA(X.AI,2024a)、MMStar(Chen 等人,2024a)、MMVet(Yu 等人,2024)、MMT-Bench(Ying 等人,2024)、MMBench(Liu 等人,2023d)、MMbench-1.1(Liu 等人,2023d)、MME(Fu 等人,2023)和 HallusionBench(Guan 等人,2023)。

Qwen2-VL 系列在这些基准上表现出色,72B 模型始终达到或超过最先进的结果,而 7B 和 2B 变体也表现出强大的能力。在评估现实世界空间理解的 RealWorldQA 上,Qwen2-VL-72B 取得了 77.8 分,超过了之前的最先进水平(72.2)和强大的基线如 GPT-4o(75.4),从而展示了对物理环境的卓越理解。
对于 MMStar,这是一个通过视觉不可或缺的样本评估真正多模态能力的基准,Qwen2-VL-72B 达到 68.3,超过了之前的最佳值 67.1,突出了其在整合视觉和文本信息方面的熟练程度。在 MMVet 上,该基准通过 16 个复杂的多模态任务评估核心视觉语言能力的整合,Qwen2-VL-72B 取得了显著的 74.0 分,显著优于包括 GPT-4V(67.5)在内的强大竞争对手,展示了其在解决多样化多模态挑战方面的多功能性。
在 MMT-Bench 评估中,该评估通过多模态理解中的 32 个核心元任务和 162 个子任务评估高级推理和指令遵循能力,Qwen2-VL-72B 取得 71.7 分,明显超过之前的最佳值(63.4),展示了其在应用专业知识和执行刻意的视觉识别、定位、推理和规划方面的实力。
在评估 20 个维度的细粒度能力的 MMBench 上,Qwen2-VL-72B 表现强劲,英语测试集得分为 86.5,与最先进水平持平,中文测试集得分为 86.6,树立了新的基准。对于 MME,该基准衡量 14 个子任务的广泛感知和认知能力,Qwen2-VL-72B 累计得分 2482.7,显著超过之前的最佳值(2414.7),强调了其在视觉感知和高级认知任务中的先进能力。
这些全面的结果强调了 Qwen2-VL 系列在一般视觉问答任务中的卓越熟练程度。这些模型在现实世界空间理解、真正的多模态整合、复杂推理、指令遵循以及广泛的感知和认知任务中展示了先进的能力。
在各种基准测试中的持续卓越表现,尤其是 72B 模型的出色结果,使 Qwen2-VL 系列成为视觉问答领域的领先解决方案。我们的模型在处理视觉不可或缺的任务、整合核心视觉语言能力以及展示跨不同多模态场景的专业知识方面表现出色,从基本感知任务到复杂推理和规划。
这项详尽的评估突出了 Qwen2-VL 系列在应对最先进的多模态基准测试所带来的多方面挑战时的多功能性和有效性,从而为大型视觉语言模型设定了新标准。
3.2.2 文档和图表阅读
我们在 DocVQA(Mathew 等人,2021)、ChartQA(Masry 等人,2022)、InfoVQA(Mathew 等人,2021)、TextVQA(Singh 等人,2019)、AI2D(Kembhavi 等人,2016)数据集上测试了我们模型的 OCR 和文档及图表理解能力。DocVQA/InfoVQA/ChartQA 数据集侧重于模型理解文档 / 高分辨率信息图表 / 图表中文本的能力,而 TextVQA 数据集则考察理解自然图像中文本的能力。
OCRBench 数据集是一个混合任务数据集,除了基于文本的 VQA 外,还侧重于数学公式解析和信息提取。AI2D 数据集侧重于包含文本的科学图表的多项选择题。此外,我们还在 OCRBench(Liu 等人,2023e)上测试了我们模型的 OCR 和公式识别能力,并在 MTVQA(Tang 等人,2024)数据集上测试了我们模型的多语言 OCR 能力。
实验结果表明,我们的模型在多个指标上达到了 SoTA 水平,包括 DocVQA、InfoVQA、TextVQA 和 OCRBench,表明我们的模型对多个领域图像中的文本内容具有良好的理解。
3.2.3 多语言文本识别和理解
特别是,我们的模型在多语言 OCR 方面超越了所有现有的通用 LVLMs。我们的模型不仅在公开可用的 MTVQA 数据集上优于现有 LVLMs(包括 GPT-4o、Claude 3.5 Sonnet 等专有模型),而且在内部基准测试中,除阿拉伯语外,所有外语的表现均优于 GPT-4o(表 3)。

3.2.4 数学推理
我们在 MathVista(Lu 等人,2024a)和 MathVision(Wang 等人,2024)数据集上进行了实验,以评估数学推理能力。MathVista 是一个全面的基准测试,包含 6,141 个不同的数学和视觉任务示例。MathVision 数据集包含 3,040 个来自实际数学竞赛的视觉上下文中的数学问题,涵盖 16 个数学学科,难度分为五个级别。
这些挑战凸显了 LVLMs 表现出强大的视觉理解、深刻的数学理解和良好的逻辑推理技能的必要性。Qwen2-VL 系列在 MathVista 上表现出卓越的性能,达到 70.5 分,超过了其他 LVLMs。此外,它在 MathVision 上以 25.9 分创下了新的开源基准。
3.2.5 指称表达理解
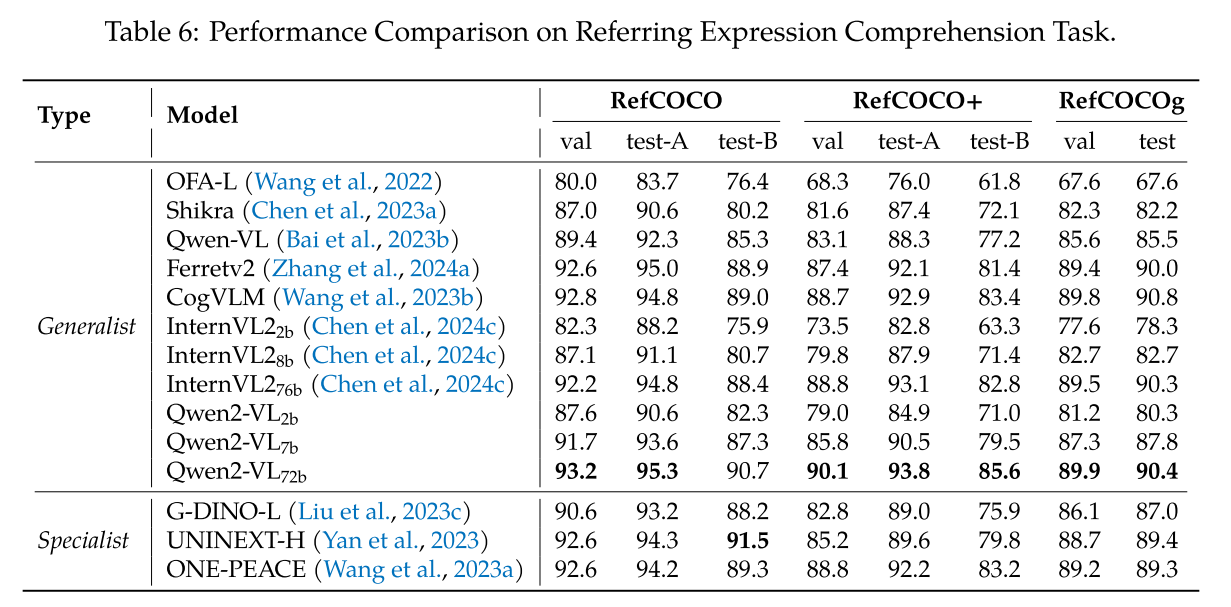
关于视觉定位任务,我们在 RefCOCO、RefCOCO + 和 RefCOCOg 数据集(Kazemzadeh 等人,2014;Mao 等人,2016)上评估了 Qwen2-VL。如表 6 所示,结果表明 Qwen2-VL 在通用模型中取得了顶级结果。得益于更合理的结构设计,Qwen2-VL 能够感知高分辨率图像中的细节,导致比 Qwen-VL 有显著改进。这些模型相比通用和专用模型的优越性凸显了它们在推进视觉定位领域的潜力及其在需要精确视觉理解的现实世界任务中的实施能力。
3.2.6 视频理解
我们在各种视频理解任务上评估了我们的模型,相关基准涵盖从几秒的短视频到长达一小时的长视频。表 4 展示了 Qwen2-VL 和基线模型的性能。总体而言,Qwen2-VL 在 2B、7B 和 72B 规模上均表现出强劲的结果,Qwen2-VL-72B 在 MVBench(Li 等人,2024)、PerceptionTest(Patraucean 等人,2024)和 EgoSchema(Mangalam 等人,2023)上实现了最佳性能。
这展示了 Qwen2-VL 在视频理解任务中的卓越能力,并且扩展 Qwen2-VL 会产生显著的改进。对于具有挑战性的 Video-MME 基准(Fu 等人,2024),其中包括长达一小时的视频,值得注意的是,我们在评估期间将每个视频提取的最大帧数限制为 768,这可能会影响较长视频的性能。未来的工作将侧重于扩展 Qwen2-VL 以支持更长的序列,从而适应更长的视频。
3.2.7 视觉代理
Qwen2-VL 首先评估了通过函数调用与环境交互的能力,然后评估了通过多轮交互完成复杂顺序决策任务的能力。该实现基于 Qwen-Agent 框架(Qwen Team,2024)。
函数调用
与 LLMs 中的函数调用(Yan 等人,2024;Srinivasan 等人,2023;Chen 等人,2023c)不同,LVLMs 中的函数调用通常涉及从视觉线索中提取信息。由于缺乏评估 LVLMs 函数调用能力的公共基准,我们构建了内部评估数据集。
为了构建评估数据集,我们进行了以下步骤(Chen 等人,2023c):场景分类、图像收集、图像内容提取和问题 / 函数 / 参数生成。首先,我们根据不同的视觉应用将场景分类。随后,我们从互联网上下载并精心挑选了每个类别的高质量、有代表性的图像。
此后,利用先进的 LVLM(Bai 等人,2023b),我们分析每个图像以提取关键视觉元素和文本信息。最后,根据图像的内容信息,我们使用先进的 LLM(Yang 等人,2024)生成一系列需要特定函数回答的问题,以及指定这些函数调用所需的输入参数。
与 LLMs 中的函数调用评估方法(Yan 等人,2024)类似,我们设计了两个指标来评估函数选择的准确性和参数输入的正确性。具体而言,类型匹配(TM)计算为模型成功调用正确函数的次数与尝试的调用总数的比率。精确匹配(EM)对于每个函数调用,我们检查传递给函数的参数是否与图像内容信息中记录的参数完全匹配,计算该正确率。
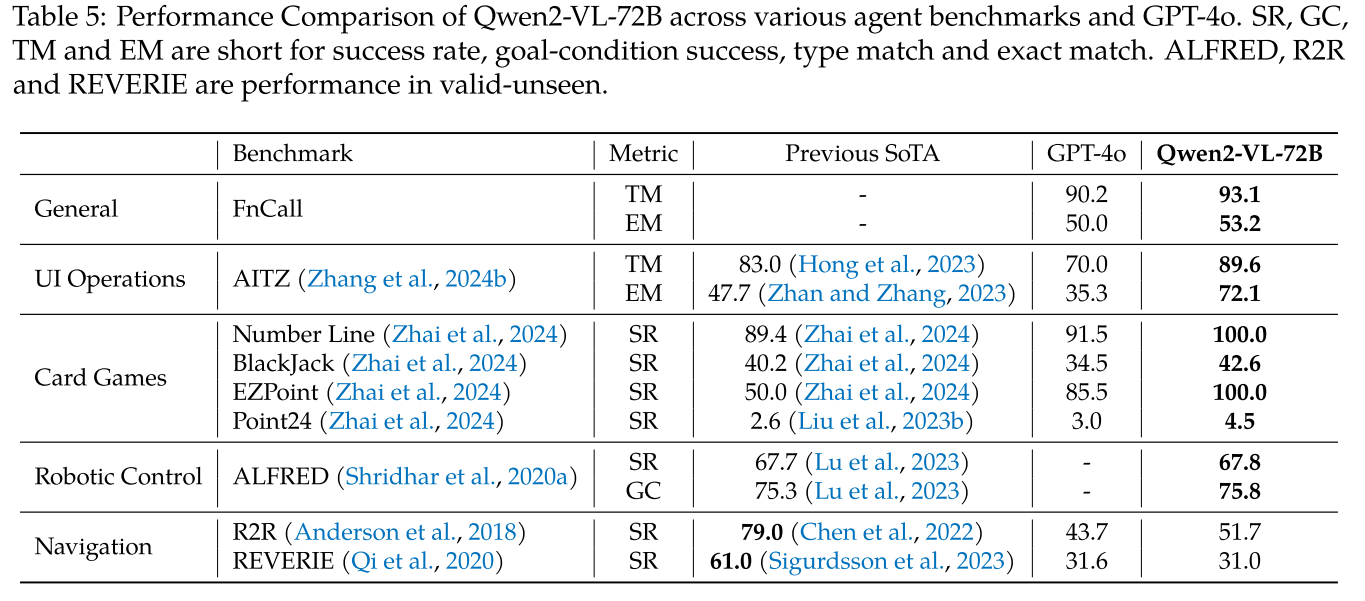
如表 5 所示,Qwen2-VL 在类型匹配(93.1 vs. 90.2)和精确匹配(53.2 vs. 50.0)方面对 GPT-4o 的性能证实了 Qwen2-VL 在函数调用能力方面的有效性,从而突出了其通过外部工具集成实现应用扩展的巨大潜力。
评估结果表明,GPT-4o 表现不佳,主要有两个因素:在出现不确定性的情况下,GPT-4o 表现出保守的方法,避免使用外部工具。GPT-4o 的光学字符识别(OCR)能力不如 Qwen2-VL,尤其是在汉字方面。
UI 操作 / 游戏 / 机器人 / 导航
为了评估 Qwen2-VL 处理一般复杂任务的能力,我们在多个 VL 代理任务上进行了评估,包括移动操作(Zhang 等人,2024b;Rawles 等人,2024b;Lu 等人,2024b;Rawles 等人,2024a)、机器人控制(Kolve 等人,2017;Shridhar 等人,2020a;Inoue 和 Ohashi,2022;Lu 等人,2023;Jiang 等人,2022;Huang 等人,2023b)、卡牌游戏(Zhai 等人,2024)和视觉语言导航(Anderson 等人,2018;Qi 等人,2020)。由于这些任务需要多个动作来完成任务,我们通过 Qwen2-VL 支持的 32K 上下文长度保持历史记录(观察、动作),然后在每个动作后附加新的观察图像,从而能够对后续步骤进行持续推理。
UI 操作
我们使用 AITZ 任务(Zhang 等人,2024b)评估 Qwen2-VL,该任务从 AITW(Rawles 等人,2024b)构建了一个核心清洁测试集。根据手机的常见操作模式,我们为 Qwen2-VL 定义了点击、输入和滑动(Rawles 等人,2024b)等动作,以与屏幕上的图标交互以完成任务。例如,当 Qwen2-VL 被要求通过谷歌地图查找附近的披萨餐厅时,它应该在搜索词中输入 “pizza”,滑动选择合适的餐厅,并点击相应的链接。按照 AITZ 设置,我们报告类型匹配(点击、输入或滑动的正确性)和精确匹配(点击位置、输入文本或滑动方向的正确性)。在 UI 上的接地能力支持下,Qwen2-VL 超越了 GPT-4 和之前的 SoTA(Zhang 等人,2024b;Zhan 和 Zhang,2023)。
机器人控制
我们在 AI2THOR(Kolve 等人,2017)中的 ALFRED 任务(Shridhar 等人,2020a)上评估 Qwen2-VL。该任务要求代理执行复杂的家务任务,如烤面包和切苹果准备饭菜。为了在虚拟环境中工作,我们将高级动作(GotoLocation、Pickup、PutDown、Open、Close、Clean、Heat、Cool、Slice)(Shridhar 等人,2020b)定义为动作集。此外,代理需要定位要操作的对象(例如,只有识别出苹果才能拿起苹果)。为了提高操作的准确性,我们集成了 SAM(Kirillov 等人,2023)。ALFRED 任务报告任务成功率(SR)(例如,准备晚餐)和子目标完成指标(GC)(例如,面包是否烤好或苹果是否切好)。Qwen2-VL 在 valid-unseen 集上略微优于之前的专用模型 ThinkBot(Lu 等人,2023)。
卡牌游戏
我们利用 RL4VLM(Zhai 等人,2024)的卡牌游戏环境来评估 Qwen2-VL 在一系列卡牌游戏中的表现:Number Line、BlackJack、EZPoint 和 Point24。每个游戏都呈现不同的挑战:(1)使用 + 1 或 - 1 操作达到目标数字,(2)抽牌或停牌与庄家竞争,(3)应用基本算术运算达到总数 12,以及(4)使用算术运算达到总数 24。我们报告任务的成功率。它们不仅评估代理能力,还需要强大的 OCR 技能来识别这些卡牌并了解游戏进程。Qwen2-VL 在所有任务中表现出色。
视觉语言导航
我们使用 R2R(Anderson 等人,2018)和 REVERIE(Qi 等人,2020)在视觉和语言导航(VLN)任务上评估 Qwen2-VL。在 VLN 中,模型必须根据指令、当前观察自主确定下一个位置。
我们报告 VLM 到达预定目的地的成功率(SR)。Qwen2-VL 的性能与 GPT-4o 相当,但两个模型均明显落后于当前的专用 VLN 模型(Chen 等人,2022;Sigurdsson 等人,2023)。
我们将此差距归因于模型从多个图像生成的不完整和非结构化地图信息。在三维环境中准确建模地图和位置仍然是多模态模型的主要挑战。
3.3 消融研究
在本节中,我们对图像动态分辨率、M-RoPE 和模型规模进行了消融研究。这些实验旨在深入了解这些关键组件对我们模型性能的影响。
3.3.1 动态分辨率
如表 7 所示,我们比较了动态分辨率和固定分辨率之间的性能。对于固定分辨率,我们调整图像大小以确保输入到模型的图像标记数量恒定,而不是调整为特定的高度和宽度,因为这会扭曲原始宽高比。
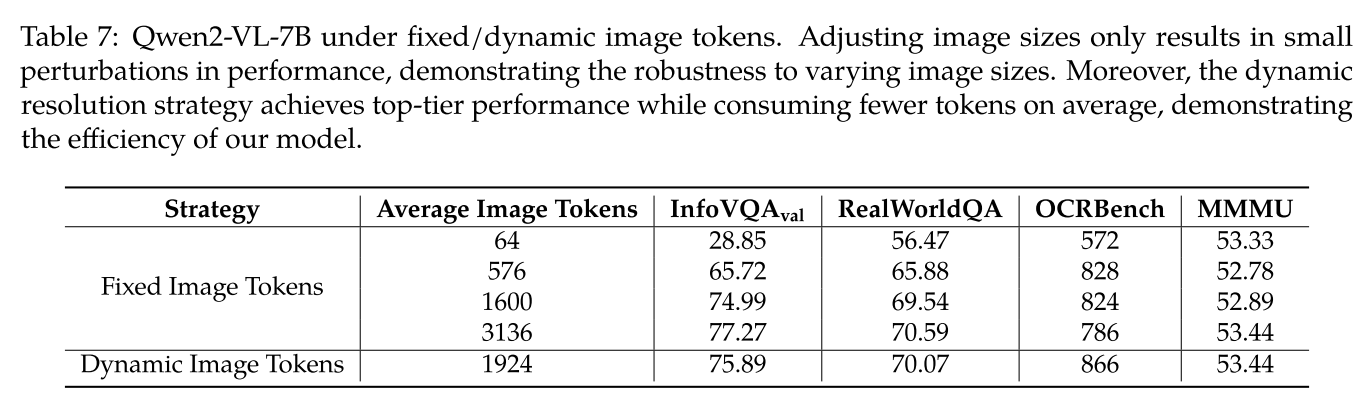
对于动态分辨率,我们仅设置 min_pixels=100×28×28 和 max_pixels=16384×28×28,允许图像标记的数量主要取决于图像的原生分辨率。可以观察到,调整图像大小仅导致性能的小扰动,表明模型对不同图像大小的鲁棒性。此外,动态分辨率方法效率更高。我们可以观察到,没有单一的固定分辨率在所有基准测试中实现最佳性能。相比之下,动态分辨率方法在平均消耗更少标记的同时始终实现顶级性能。
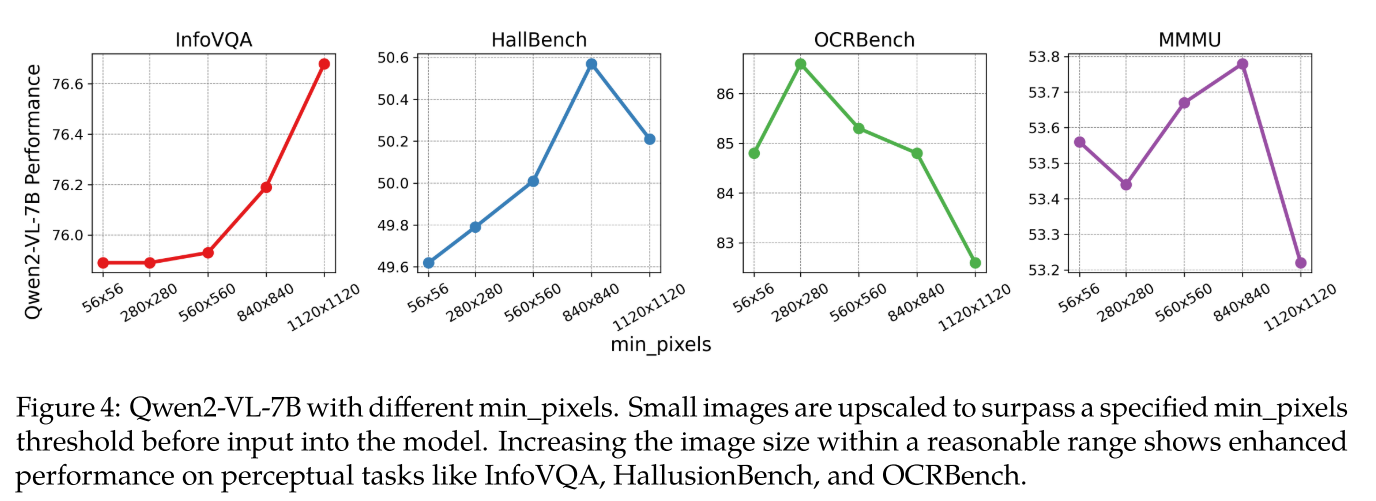
此外,我们观察到仅增加图像大小并不总是导致性能提升。为不同的图像选择合适的分辨率更为重要。如图 4 详细所示,我们将小图像放大到超过指定的 min_pixels 阈值。对放大图像的评估显示,在 InfoVQA、HallusionBench 和 OCRBench 等感知任务上性能增强。我们将这些收益归因于计算负载的增加。
然而,对于 OCRBench,过高的 min_pixels 值会导致性能严重下降。这可能是因为 OCRBench 包含许多极小的图像,过度放大导致这些图像偏离训练数据分布,变成分布外样本。相比之下,增加 min_pixels 对 MMMU 基准的影响可以忽略不计。我们假设 MMMU 的性能瓶颈与模型的推理能力而非图像分辨率更相关。
3.3.2 M-RoPE

在本小节中,我们展示了 M-RoPE 的有效性。首先,我们在各种下游任务上验证了其能力。我们采用 Qwen2-1.5B 和 ViT-L 作为主干,并报告预训练模型的结果。如表 8 所示,与 1D-RoPE 相比,使用 M-RoPE 在下游任务中实现了更好的性能,尤其是在视频基准测试中。此外,我们在视频 - MME 中等长度视频上评估了 M-RoPE 的长度外推能力。
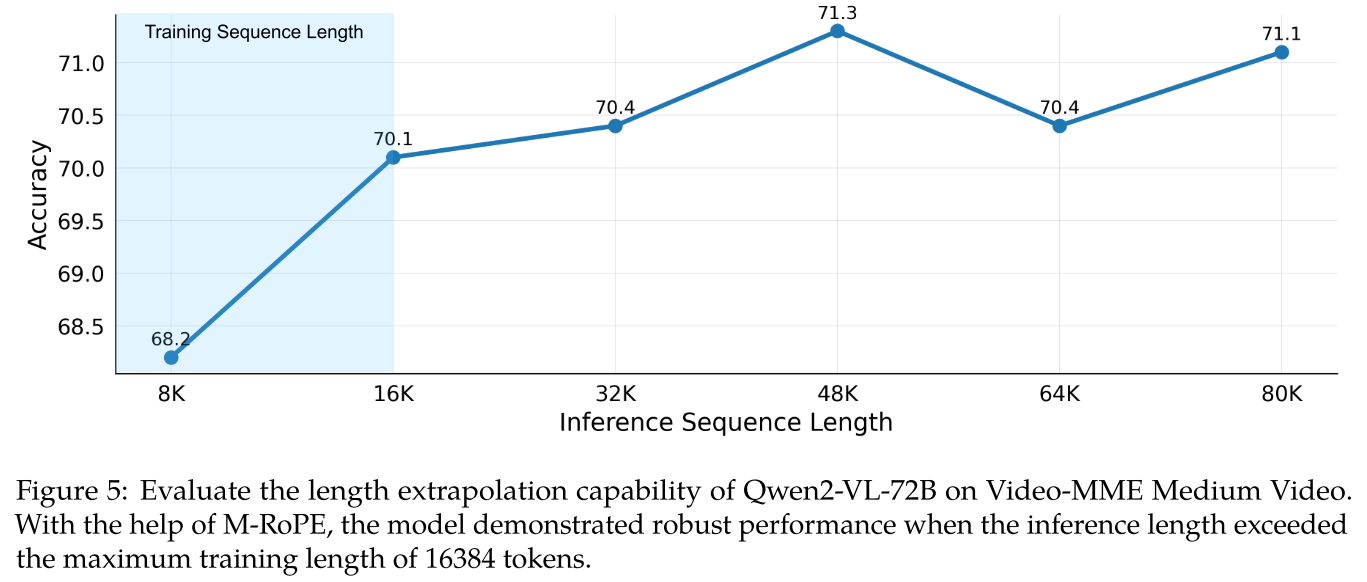
图 5 展示了 Qwen2-VL-72B 在不同推理长度下的性能。借助 M-RoPE,模型在各种推理长度下均表现出稳健的结果。值得注意的是,尽管训练期间每个视频的最大标记数限制为 16K,但模型在最大推理长度为 80K 标记时仍表现出色。
3.3.3 模型规模
我们评估了不同规模模型在多个能力维度上的性能。具体而言,我们将这些维度分为复杂的大学水平问题解决、数学能力、文档和表格理解、一般场景问答以及视频理解。模型的整体能力通过每个维度相关基准的平均得分来评估。
特别是,我们使用 MMMU(Yue 等人,2023)基准代表大学水平的问题解决能力,而 MathVista(Lu 等人,2024a)和 MathVision(Wang 等人,2024)的平均得分作为数学能力的指标。对于一般场景问答,我们计算 RealWorldQA(X.AI,2024a)、MMBench-V1.1(Liu 等人,2023d)、MMT-Bench(Ying 等人,2024)、HallBench(Guan 等人,2023)、MMVet(Yu 等人,2024)和 MMStar(Chen 等人,2024a)基准的平均得分。
文档和表格理解能力通过 DocVQA(Mathew 等人,2021)、InfoVQA(Mathew 等人,2021)、ChartQA(Masry 等人,2022)、TextVQA(Singh 等人,2019)、OCRBench(Liu 等人,2023e)和 MTVQA(Tang 等人,2024)等基准的平均得分反映。最后,视频理解能力通过 MVBench(Li 等人,2024)、PerceptionTest(Patraucean 等人,2024)、EgoSchema(Mangalam 等人,2023)和 Video-MME(Fu 等人,2024)的平均得分来衡量。
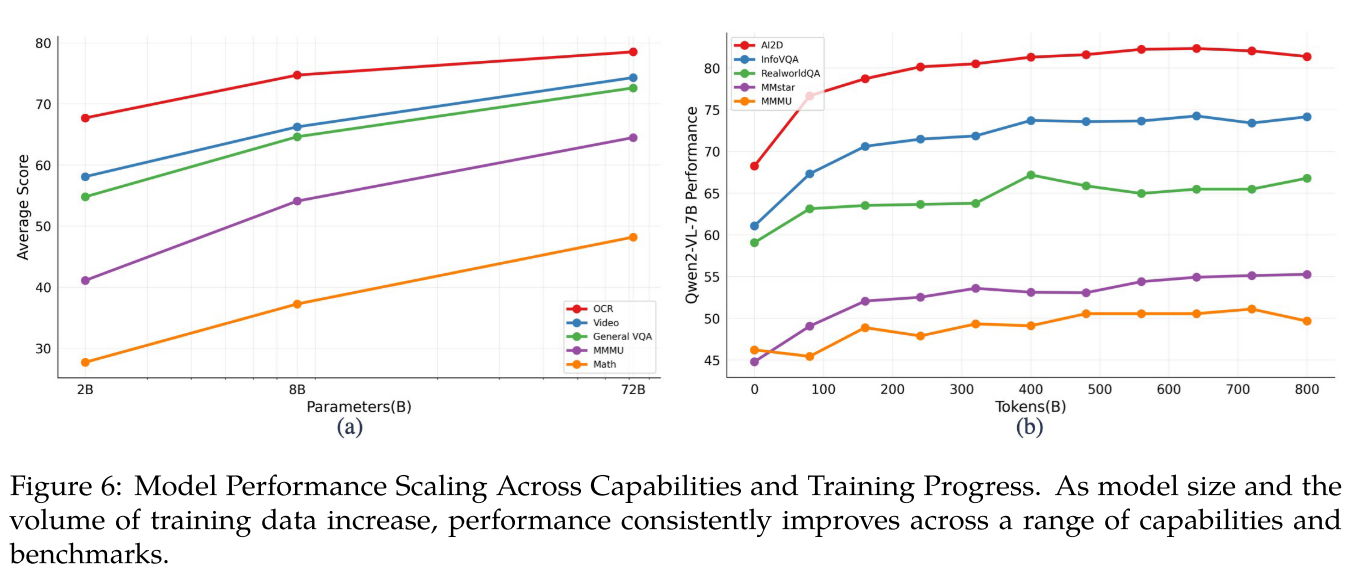
如图 6 (a) 所示,随着模型规模的增大,性能持续提升,尤其是数学能力与模型参数数量呈正相关。另一方面,对于光学字符识别(OCR)相关任务,即使是较小规模的模型也表现出较强的性能。
如图 6 (b) 所示,我们可视化了 Qwen2-VL-7B 在第二阶段预训练期间模型性能与训练标记数量之间的关系。随着训练标记数量的增加,模型性能有所提升;然而,视觉问答(VQA)任务的性能表现出一定的波动。相比之下,对于涉及理解图像中文本和图形信息的任务,如 AI2D(Kembhavi 等人,2016)和 InfoVQA(Mathew 等人,2021),随着训练数据的增加,模型性能呈现稳步提升。
4 结论
我们提出了 Qwen2-VL 系列,这是一组多功能的大型视觉语言模型,包括三个开放权重模型,总参数分别为 20 亿、80 亿和 720 亿。Qwen2-VL 在一系列多模态场景中与 GPT-4o 和 Claude3.5-Sonnet 等顶级模型性能相当,超越了所有其他开放权重 LVLM 模型。
Qwen2-VL 系列引入了原生动态分辨率和多模态旋转位置嵌入(M-RoPE),以有效融合跨模态信息,并能够理解超过 20 分钟的视频。凭借先进的推理和决策能力,Qwen2-VL 可以与手机、机器人等设备集成。此外,Qwen2-VL 现在支持理解图像中的多语言文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
我们已公开 Qwen2-VL 模型权重,使研究人员和开发人员能够在各种应用和研究项目中充分发挥其潜力。我们致力于通过这些努力推动人工智能技术的发展,并增强其对社会的有益影响。
附录 A:模型能力和定性示例
在本节中,我们展示 Qwen2-VL 的一些实际应用示例。
A.1 通用聊天和 OCR
Qwen2-VL 模型现在更擅长准确描述和识别图像中的复杂信息,并提供详细的背景信息和回答相关问题。此外,Qwen2-VL 模型的文本处理能力显著提升,尤其是在识别图像中的中文和英文文本方面。

多物体识别 图 7:当呈现不同颜色的立方体图像时,模型识别它们的布局和每个立方体的颜色。 模型响应:图像显示一堆带有数字的彩色块。以下是从上到下每个块的颜色和数字:
- 顶行(单个块):蓝色,数字 9
- 第二行(两个块):浅蓝色,数字 7;绿色,数字 8
- 第三行(三个块):紫色,数字 4;粉红色,数字 5;浅绿色,数字 6
- 底行(四个块):红色,数字 0;橙色,数字 1;黄色,数字 2;浅绿色,数字 3

植物识别 图 8:模型在识别照片中的花卉方面表现出熟练能力。 用户查询:这是什么花? 模型响应:图片中的花是勿忘我(Myosotis)。这些小巧精致的花朵以其鲜艳的颜色而闻名,通常为蓝色、粉红色或白色,常因其迷人的外观被用于花束和花园中。


带有密集公式的文档解析 图 9:基于视觉刺激的多语言文学写作。 用户查询:将图像中的内容转换为 Markdown 模型响应:(具体公式转换内容见原文附录,此处略)
A.2 信息提取和视觉推理
Qwen2-VL 模型的一个显著进步是其增强的视觉推理能力。这一进步使模型能够解释和理解复杂的表示形式,如流程图、图表和其他符号系统。
数学问题解决 图 14:模型在解决数学问题方面表现出熟练能力。图像来源:Lu 等人(2021) 问题:在等腰三角形 ABC 中,求 AC 的长度 模型响应:由于三角形 ABC 是等腰三角形,我们知道 AC=BC。因此,我们可以将 AC 和 BC 的表达式设为相等并解方程:\(4x + 1 = 5x - 0.5\) 两边减去 4x,得到:\(1 = x - 0.5\) 两边加上 0.5,得到:\(x = 1.5\) 现在我们知道 x 的值,可以将其代入 AC 的表达式中求其长度:\(AC = 4x + 1 = 4×1.5 + 1 = 7\) 因此,AC 的长度为 7。
算法问题解决 图 16:模型在解决算法问题方面表现出熟练能力。 问题:在网页中解决 “矩阵中的蛇” 算法问题 模型响应:(具体 Python 代码实现见原文附录,此处略)
A.3 视频理解
多轮视频聊天 图 22:模型在识别多轮视频聊天方面表现出熟练能力。 用户查询:请详细描述视频内容 模型响应:视频开头是一名男子对着镜头讲话,随后切换到一群人坐在控制室里。镜头随后切换到两名男子在空间站内漂浮,他们似乎在对着镜头讲话。这两名男子看起来像是宇航员,穿着太空服。空间站内充满了各种设备和机械,镜头平移展示了空间站的不同区域。男子继续对着镜头讲话,似乎在讨论他们的任务和正在执行的各种任务。总体而言,这段视频提供了对太空探索世界和宇航员日常生活的迷人一瞥。
A.4 视觉代理能力
定位任意目标 图 24:我们的模型能够定位图像中的特定元素,例如准确识别红色汽车。 模型响应:<|object_ref_start|> 红色汽车 <|object_ref_end|><|box_start|>(701,531),(869,675)<|box_end|>
UI 操作代理 图 30:Qwen2-VL 作为代理,理解与 UI 操作相关的查询,利用系统消息中预定义的动作,逐步完成任务。 用户任务:圣地亚哥有什么好餐厅? 模型响应:(详细步骤见原文附录,涉及点击、输入、滑动等 UI 操作)

















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









